Creare ed eseguire pipeline di Machine Learning usando componenti l'interfaccia della riga di comando di Azure Machine Learning
SI APPLICA A:  estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
Questo articolo illustra come creare ed eseguire pipeline di Machine Learning usando l'interfaccia della riga di comando di Azure e i componenti. È possibile creare pipeline senza usare componenti, ma questi ultimi offrono la massima flessibilità e possibilità di riutilizzo. Le pipeline di Azure Machine Learning possono essere definite in YAML ed eseguite dall'interfaccia della riga di comando, create in Python o composte nella finestra di progettazione dello studio di Azure Machine Learning con un'interfaccia utente basata su trascinamento della selezione. Questo documento è incentrato sull'interfaccia della riga di comando.
Prerequisiti
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
Un'area di lavoro di Azure Machine Learning. Creare le risorse dell'area di lavoro.
Clonare il repository di esempi:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Letture preliminari consigliate
- Che cosa sono le pipeline di Azure Machine Learning?
- Che cos'è un componente di Azure Machine Learning?
Creare la prima pipeline con il componente
Per creare la prima pipeline con componenti, si userà un esempio. Obiettivo di questa sezione è introdurre pipeline e componenti in Azure Machine Learning con un esempio concreto.
Dalla directory cli/jobs/pipelines-with-components/basics del repository azureml-examples passare alla sottodirectory 3b_pipeline_with_data. In questa directory sono presenti tre tipi di file. Si tratta dei file che è necessario creare durante la creazione della propria pipeline.
pipeline.yml: questo file YAML consente di definire la pipeline di Machine Learning. Descrive come suddividere un'attività di Machine Learning completa in un flusso di lavoro con più passaggi. Se, ad esempio, si considera una semplice attività di Machine Learning sull'uso di dati cronologici per eseguire il training di un modello di previsione delle vendite, è possibile creare un flusso di lavoro sequenziale che include passaggi per l'elaborazione dati, il training del modello e la valutazione del modello. Ogni passaggio è un componente dotato di un'interfaccia ben definita e può essere sviluppato, testato e ottimizzato in modo indipendente. Il codice YAML della pipeline consente di definire anche le modalità con cui i passaggi figlio si connettono ad altri passaggi della pipeline. Ad esempio, durante il passaggio del training del modello viene generato un file di modello che viene quindi usato in un passaggio di valutazione del modello.
component.yml: questo file YAML consente di il componente. Include in un pacchetto le informazioni seguenti:
- Metadati: nome, nome visualizzato, versione, descrizione, tipo e così via. I metadati consentono di descrivere e gestire il componente.
- Interfaccia: input e output. Ad esempio, un componente di training del modello accetta come input i dati di training e il numero di periodi e genera come output un file di modello sottoposto a training. Dopo aver definito l'interfaccia, team diversi possono sviluppare e testare il componente in modo indipendente.
- Comando, codice e ambiente: comando, codice e ambiente usati per eseguire il componente. Il comando è il comando della shell per eseguire il componente. Il codice fa in genere riferimento a una directory del codice sorgente. L'ambiente può essere un ambiente di Azure Machine Learning (curato o creato dal cliente), un'immagine Docker o un ambiente Conda.
component_src: si tratta della directory del codice sorgente per un componente specifico. Contiene il codice sorgente che viene eseguito nel componente. È possibile usare il linguaggio preferito (Python, R e così via). Il codice deve essere eseguito da un comando della shell. Il codice sorgente può richiedere alcuni input dalla riga di comando della shell per controllare la modalità di esecuzione di questo passaggio. Ad esempio, un passaggio di training potrebbe accettare dati di training, velocità di apprendimento, numero di periodi per controllare il processo di training. L'argomento di un comando della shell viene usato per passare input e output al codice.
A questo punto si creerà una pipeline usando l'esempio 3b_pipeline_with_data. Il significato dettagliato di ogni file verrà illustrato nelle sezioni successive.
Per prima cosa, elencare le risorse di calcolo disponibili con il comando seguente:
az ml compute list
Se non è presente, creare un cluster denominato cpu-cluster eseguendo:
Nota
Ignorare questo passaggio per usare l'elaborazione serverless.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Creare ora un processo della pipeline definito nel file pipeline.yml con il comando seguente. La destinazione di calcolo viene indicata nel file pipeline.yml come azureml:cpu-cluster. Se la destinazione di calcolo usa un nome diverso, ricordarsi di aggiornarla nel file pipeline.yml.
az ml job create --file pipeline.yml
Si dovrebbe ricevere un dizionario JSON contenente informazioni sul processo della pipeline, tra cui:
| Chiave | Descrizione |
|---|---|
name |
Nome del processo basato su GUID. |
experiment_name |
Nome con cui verranno organizzati i processi in Studio. |
services.Studio.endpoint |
URL per il monitoraggio e la revisione del processo della pipeline. |
status |
Stato del processo. Sarà probabilmente Preparing a questo punto. |
Aprire l'URL di services.Studio.endpoint per accedere a una visualizzazione del grafo della pipeline.
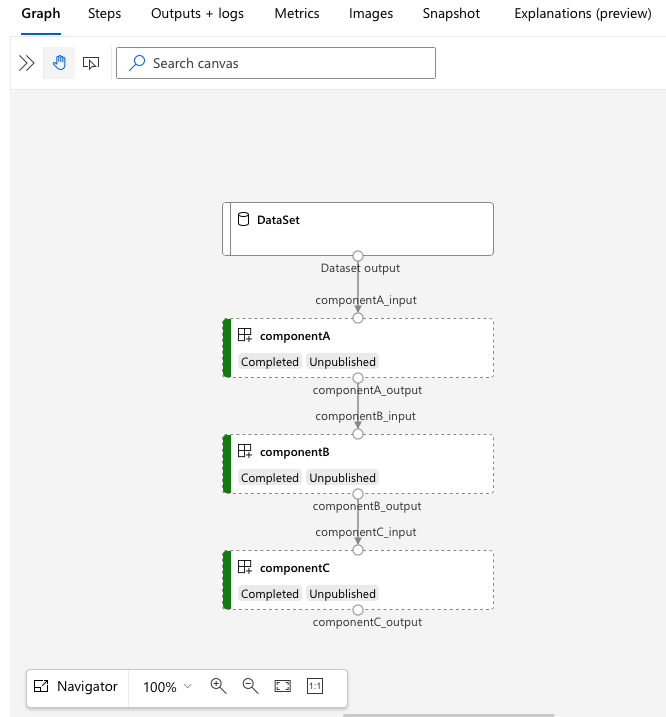
Informazioni sul codice YAML di definizione della pipeline
A questo punto, si esaminerà la definizione della pipeline nel file 3b_pipeline_with_data/pipeline.yml.
Nota
Per usare l'elaborazione serverless, sostituire default_compute: azureml:cpu-cluster con default_compute: azureml:serverless in questo file.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
La tabella descrive i campi più usati dello schema YAML della pipeline. Per altre informazioni, vedere lo schema YAML completo della pipeline.
| key | description |
|---|---|
| type | Obbligatorio. Il tipo di processo deve essere pipeline per i processi della pipeline. |
| display_name | Nome visualizzato del processo della pipeline nell'interfaccia utente di Studio. Modificabile nell'interfaccia utente di Studio. Non deve essere univoco in tutti i processi dell'area di lavoro. |
| jobs | Obbligatorio. Dizionario del set di singoli processi da eseguire come passaggi all'interno della pipeline. Questi processi sono considerati processi figlio del processo padre della pipeline. In questa versione i tipi di processo supportati nella pipeline sono command e sweep. |
| input | Dizionario di input per il processo della pipeline. La chiave è un nome per l'input nel contesto del processo e il valore è il valore di input. È possibile fare riferimento a questi input della pipeline negli input di un singolo processo di passaggio nella pipeline usando l'espressione ${{ parent.inputs.<input_name> }}. |
| outputs | Dizionario delle configurazioni di output del processo della pipeline. La chiave è un nome per l'output nel contesto del processo e il valore è la configurazione di output. È possibile fare riferimento a questi output della pipeline negli output di un singolo processo di passaggio nella pipeline usando l'espressione ${{ parents.outputs.<output_name> }} |
Nell'esempio 3b_pipeline_with_data è stata creata una pipeline con tre passaggi.
- I tre passaggi sono definiti in
jobs. Tutti e tre i tipi di passaggio sono processi di comando. La definizione di ogni passaggio si trova nel filecomponent.ymlcorrispondente. È possibile visualizzare i file YAML del componente nella directory 3b_pipeline_with_data. Il file componentA.yml verrà illustrato nella sezione successiva. - Questa pipeline presenta una dipendenza dai dati, che è comune nella maggior parte delle pipeline reali. Component_a accetta l'input dei dati dalla cartella locale in
./data(riga 17-20) e ne passa l'output a componentB (riga 29). È possibile fare riferimento all'output di component_a come${{parent.jobs.component_a.outputs.component_a_output}}. computedefinisce il calcolo predefinito per questa pipeline. Se un componente injobsdefinisce un calcolo diverso per questo componente, il sistema rispetta l'impostazione specifica del componente.

Leggere e scrivere dati nella pipeline
Uno scenario comune prevede operazioni di lettura e scrittura nella pipeline. In Azure Machine Learning si usa lo stesso schema per leggere e scrivere dati per tutti i tipi di processi (processo della pipeline, processo di comando e processo di sweeping). Di seguito sono riportati esempi di processi della pipeline relativi all'uso dei dati per scenari comuni.
- dati locali
- file Web con URL pubblico
- archivio dati e percorso di Azure Machine Learning
- asset di dati di Azure Machine Learning
Informazioni sul codice YAML di definizione del componente
Si esaminerà ora il file componentA.yml come esempio per comprendere il codice YAML della definizione.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
Nella tabella è descritto lo schema usato più di frequente per il codice YAML del componente. Per altre informazioni, vedere lo schema YAML completo del componente.
| key | description |
|---|---|
| name | Obbligatorio. Nome del componente. Deve essere univoco nell'area di lavoro di Azure Machine Learning. Deve iniziare con una lettera minuscola. Sono consentite lettere minuscole, numeri e caratteri di sottolineatura (_). La lunghezza massima consentita è di 255 caratteri. |
| display_name | Nome visualizzato del componente nell'interfaccia utente di Studio. Può essere non univoco all'interno dell'area di lavoro. |
| Comando | Obbligatorio. Comando da eseguire |
| codice | Percorso locale della directory del codice sorgente da caricare e usare per il componente. |
| dell'ambiente di | Obbligatorio. Ambiente usato per eseguire il componente. |
| input | Dizionario degli input del componente. La chiave è un nome per l'input nel contesto del componente e il valore è la definizione di input del componente. È possibile fare riferimento agli input nel comando usando l'espressione ${{ inputs.<input_name> }}. |
| outputs | Dizionario degli output del componente. La chiave è un nome per l'output nel contesto del componente e il valore è la definizione di output del componente. È possibile fare riferimento agli output nel comando usando l'espressione ${{ outputs.<output_name> }}. |
| is_deterministic | Indica se riutilizzare il risultato del processo precedente se gli input del componente non sono stati modificati. Il valore predefinito è true, noto anche come riutilizzo per impostazione predefinita. Lo scenario comune quando impostato è su false consiste nel forzare il ricaricamento dei dati da un'archiviazione nel cloud o un URL. |
Per l'esempio in 3b_pipeline_with_data/componentA.yml, componentA include un input di dati e un output di dati, che possono essere connessi ad altri passaggi nella pipeline padre. Tutti i file nella sezione code del componente YAML verranno caricati in Azure Machine Learning durante l'invio del processo della pipeline. In questo esempio verranno caricati i file in ./componentA_src (riga 16 in componentA.yml). È possibile visualizzare il codice sorgente caricato nell'interfaccia utente di Studio: selezionare due volte il passaggio ComponentA e passare alla scheda Snapshot, come illustrato nello screenshot seguente. È possibile notare che si tratta di uno script hello-world che esegue una semplice attività di stampa e scrive il valore di datetime corrente nel percorso componentA_output. Il componente accetta input e output tramite l'argomento della riga di comando e viene gestito in hello.py con argparse.

Input e output
L'input e l'output definiscono l'interfaccia di un componente. L'input e l'output possono essere un valore letterale (di tipo string, number, integer o boolean) oppure un oggetto contenente lo schema di input.
L'input dell'oggetto (di tipo uri_file, uri_folder, mltable, mlflow_model, custom_model) può connettersi ad altri passaggi del processo della pipeline padre e quindi passare dati/modello ad altri passaggi. Nel grafo della pipeline l'input del tipo di oggetto viene rappresentato come punto di connessione.
Gli input di valori letterali (string, number, integer, boolean) sono i parametri che è possibile passare al componente in fase di esecuzione. È possibile aggiungere il valore predefinito degli input di valori letterali nel campo default. Per il tipo number e integer è anche possibile aggiungere il valore minimo e massimo del valore accettato usando i campi min e max. Se il valore di input supera il valore minimo e massimo, la pipeline non riesce in fase di convalida. La convalida viene eseguita prima di inviare un processo della pipeline per risparmiare tempo. La convalida funziona per l'interfaccia della riga di comando, Python SDK e l'interfaccia utente della finestra di progettazione. Lo screenshot seguente mostra un esempio di convalida nell'interfaccia utente della finestra di progettazione. Analogamente, è possibile definire i valori consentiti nel campo enum.

Se si vuole aggiungere un input a un componente, ricordarsi di modificare tre posizioni:
- Campo
inputsnel codice YAML del componente - Campo
commandnel codice YAML del componente - Codice sorgente del componente per gestire l'input della riga di comando. È contrassegnato nella casella verde nello screenshot precedente.
Per altre informazioni sugli input e sugli output, vedere Gestire input e output di componente e pipeline.
Ambiente
L'ambiente definisce l'ambiente per l'esecuzione del componente. Può essere un ambiente di Azure Machine Learning (curato o registrato personalizzato), un'immagine Docker o un ambiente Conda. Vedere gli esempi seguenti.
- Asset di ambiente registrato di Azure Machine Learning. Viene usato come riferimento nel componente con la sintassi seguente
azureml:<environment-name>:<environment-version>. - Immagine Docker pubblica
- File Conda. Deve essere usato insieme a un'immagine di base.
Registrare il componente per il riutilizzo e la condivisione
Anche se alcuni componenti sono specifici di una particolare pipeline, il vero vantaggio dei componenti deriva dal riutilizzo e dalla condivisione. Registrare un componente nell'area di lavoro di Machine Learning per renderlo disponibile per il riutilizzo. I componenti registrati supportano il controllo delle versioni automatico. In questo modo è possibile aggiornare il componente, ma garantire il funzionamento delle pipeline che richiedono una versione precedente.
Nel repository azureml-examples passare alla directory cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components.
Per registrare un componente, usare il comando az ml component create:
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
Dopo aver eseguito questi comandi fino al completamento, è possibile visualizzare i componenti in Studio, in Asset -> Componenti:

Selezionare un componente. Vengono visualizzate informazioni dettagliate per ogni versione del componente.
Nella scheda Dettagli vengono visualizzate le informazioni di base del componente, ad esempio nome, autore, versione e così via. Vengono visualizzati campi modificabili per Tag e Descrizione. I tag possono essere usati per aggiungere parole chiave con ricerca rapida. Il campo della descrizione supporta la formattazione Markdown e deve essere usato per descrivere le funzionalità e l'uso di base del componente.
Nella scheda Processi viene visualizzata la cronologia di tutti i processi che usano questo componente.
Usare componenti registrati in un file YAML del processo della pipeline
Si userà ora 1b_e2e_registered_components per una demo relativa all'uso del componente registrato nel codice YAML della pipeline. Passare alla directory 1b_e2e_registered_components e aprire il file pipeline.yml. Le chiavi e i valori nei campi inputs e outputs sono simili a quelli già descritti. L'unica differenza significativa è il valore del campo component nelle voci di jobs.<JOB_NAME>.component. Il valore component è in formato azureml:<COMPONENT_NAME>:<COMPONENT_VERSION>. La definizione train-job, ad esempio, specifica la versione più recente del componente registrato my_train da usare:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Gestire i componenti
È possibile controllare i dettagli del componente e gestire il componente usando l'interfaccia della riga di comando (v2). Usare az ml component -h per ottenere istruzioni dettagliate sul comando del componente. Nella tabella seguente sono elencati tutti i comandi disponibili. Vedere altri esempi nelle informazioni di riferimento dell'interfaccia della riga di comando di Azure.
| commands | description |
|---|---|
az ml component create |
Crea un componente |
az ml component list |
Elenca i componenti in un'area di lavoro |
az ml component show |
Visualizza i dettagli di un componente |
az ml component update |
Aggiorna un componente. Solo alcuni campi (description, display_name) supportano l'aggiornamento |
az ml component archive |
Archivia un contenitore di componenti |
az ml component restore |
Ripristina un componente archiviato |