Creare ed eseguire pipeline di Machine Learning usando componenti con lo studio di Azure Machine Learning
SI APPLICA A:  estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
Questo articolo illustra come creare ed eseguire pipeline di Machine Learning usando lo studio di Azure Machine Learning e i Componenti. È possibile creare pipeline senza usare componenti, ma i componenti offrono una maggiore flessibilità e possibilità di riutilizzo. Le pipeline di Azure Machine Learning possono essere definite in YAML ed eseguite dall'interfaccia della riga di comando, create in Python o composte nella finestra di progettazione dello studio di Azure Machine Learning con un'interfaccia utente basata su trascinamento della selezione. Questo documento è incentrato sull'interfaccia utente della finestra di progettazione dello studio di Azure Machine Learning.
Prerequisiti
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
Un'area di lavoro di Azure Machine Learning. Creare risorse dell'area di lavoro.
Clonare il repository di esempi:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
Nota
La finestra di progettazione supporta due tipi di componenti, ovvero i componenti predefiniti classici (v1) e i componenti personalizzati (v2). Questi due tipi di componenti NON sono compatibili.
I componenti predefiniti classici forniscono componenti predefiniti principalmente per l'elaborazione dati e le attività di Machine Learning tradizionali come la regressione e la classificazione. I componenti predefiniti classici continuano a essere supportati, ma non avranno aggiunte di nuovi componenti. La distribuzione di componenti predefiniti classici (v1) non supporta inoltre gli endpoint online gestiti (v2).
I componenti personalizzati consentono di eseguire il wrapping del codice personalizzato come componente. Questa opzione supporta la condivisione di componenti tra aree di lavoro e la creazione semplice nelle interfacce di studio, interfaccia della riga di comando v2 e SDK v2.
Per i nuovi progetti, è consigliabile usare un componente personalizzato, che è compatibile con AzureML V2 e continuerà a ricevere nuovi aggiornamenti.
Questo articolo si applica ai componenti personalizzati.
Registrare il componente nell'area di lavoro
Per compilare la pipeline usando componenti nell'interfaccia utente, è prima di tutto necessario registrare i componenti nell'area di lavoro. È possibile usare l'interfaccia utente, l'interfaccia della riga di comando o l'SDK per registrare i componenti nell'area di lavoro, in modo da poter condividere e riutilizzare il componente all'interno dell'area di lavoro. I componenti registrati supportano il controllo delle versioni automatico in modo da consentire di aggiornare il componente, ma assicurare che le pipeline che richiedono una versione precedente continuino a funzionare.
L'esempio seguente usa l'interfaccia utente per registrare i componenti e i file di origine del componente si trovano nella directory cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components del repository azureml-examples. È prima di tutto necessario clonare il repository in locale.
- Nell'area di lavoro di Azure Machine Learning passare alla pagina Componenti e selezionare Nuovo componente. Verrà visualizzata una delle due pagine di stile.


Questo esempio usa train.yml nella directory. Il file YAML definisce il nome, il tipo, l'interfaccia, inclusi input e output, codice, ambiente e comando di questo componente. Il codice di questo componente train.py si trova nella cartella ./train_src, che descrive la logica di esecuzione di questo componente. Per altre informazioni sullo schema del componente, vedere le informazioni di riferimento sullo schema YAML del componente comando.
Nota
Quando si registrano i componenti nell'interfaccia utente, code definito nel file YAML del componente può puntare solo alla cartella corrente in cui si trova il file YAML o alle sottocartelle, il che significa che non è possibile specificare ../ per code perché l'interfaccia utente non è in grado di riconoscere la directory padre.
additional_includes può puntare solo alla cartella corrente o secondaria.
Attualmente, l'interfaccia utente supporta solo la registrazione dei componenti con tipo command.
- Selezionare Carica da Cartella e selezionare la cartella
1b_e2e_registered_componentsda cui eseguire il caricamento. Selezionaretrain.ymldall'elenco a discesa.

Selezionare Avanti nella parte inferiore. È possibile verificare i dettagli di questo componente. Dopo la verifica, selezionare Crea per completare il processo di registrazione.
Ripetere i passaggi precedenti per registrare il componente Score ed Eval usando anche
score.ymleeval.yml.Dopo aver registrato correttamente i tre componenti, è possibile visualizzare i componenti nell'interfaccia utente dello studio.

Creare una pipeline usando il componente registrato
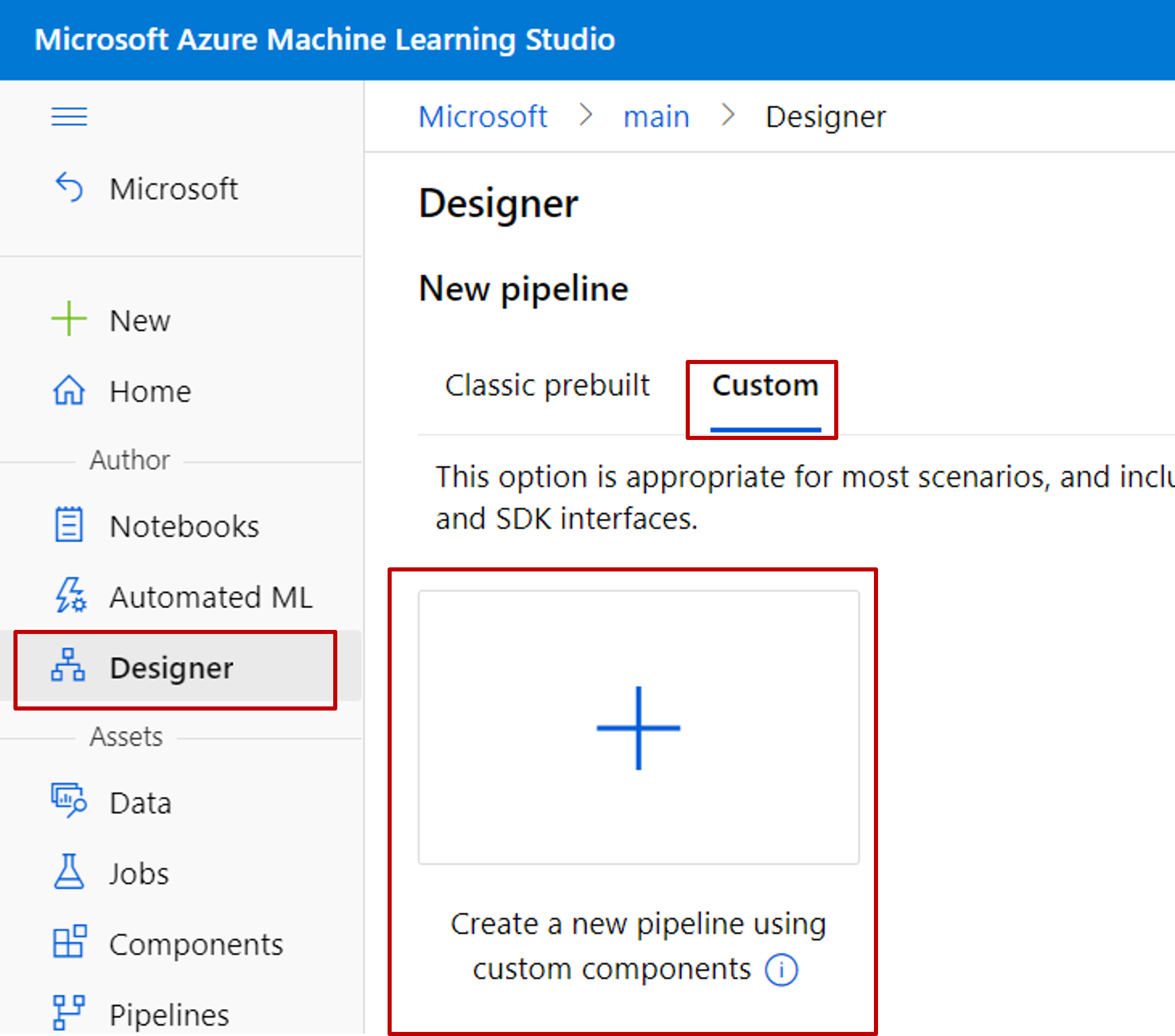
Creare una nuova pipeline nella finestra di progettazione. Ricordarsi di selezionare l'opzione Personalizzato.
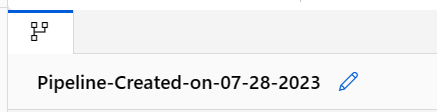
Assegnare alla pipeline un nome significativo selezionando l'icona a forma di matita accanto al nome generato automaticamente.
Nella libreria di asset della finestra di progettazione sono visualizzate le schede Dati, Modello e Componenti. Passare alla scheda Componenti. Vengono visualizzati i componenti registrati nella sezione precedente. Se sono presenti troppi componenti, è possibile eseguire una ricerca con il nome del componente.
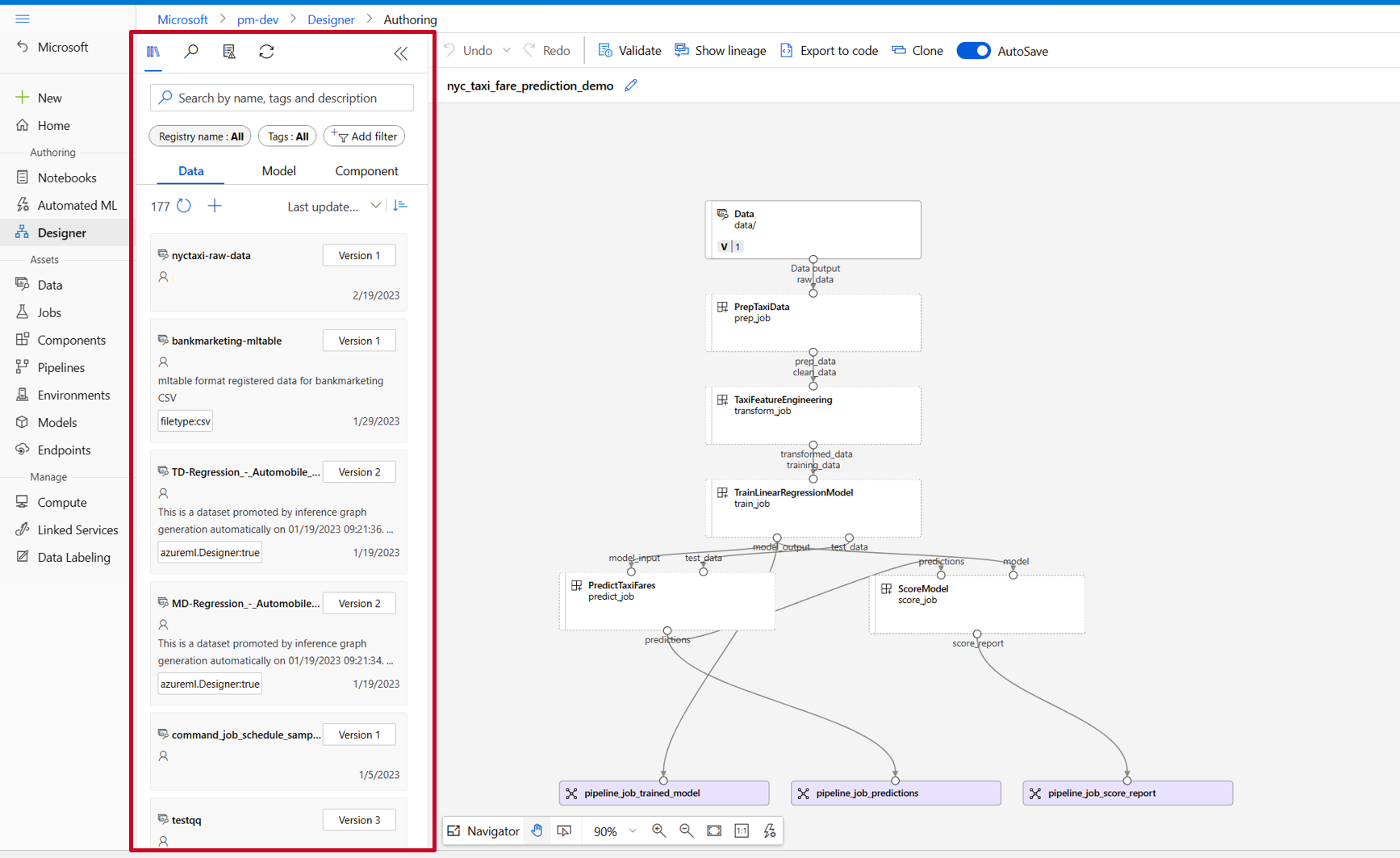
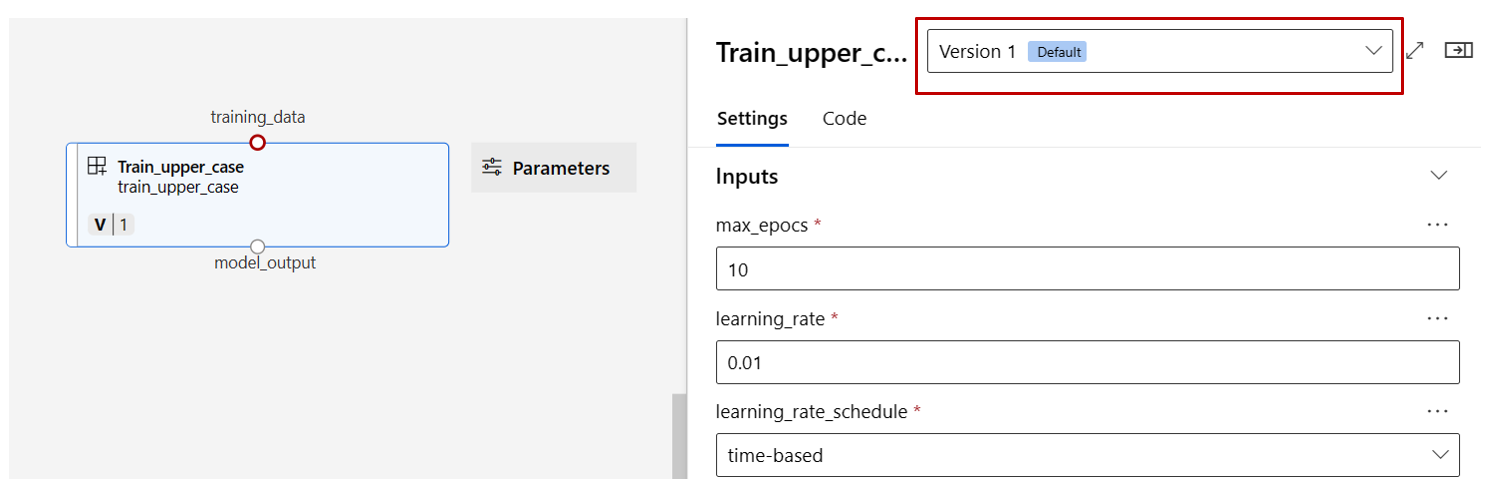
Trovare i componenti train, score ed eval registrati nella sezione precedente, quindi trascinarli nel canvas. Per impostazione predefinita, viene usata la versione predefinita del componente ed è possibile passare a una versione specifica nel riquadro destro del componente. Il riquadro destro del componente viene richiamato facendo doppio clic sul componente.
In questo esempio si useranno i dati di esempio disponibili in questo percorso. Registrare i dati nell'area di lavoro selezionando l'icona Aggiungi nella libreria di asset della finestra di progettazione-> scheda dati, impostare Tipo = Cartella (uri_folder) e quindi seguire la procedura guidata per registrare i dati. Il tipo di dati deve essere uri_folder per allinearsi alla definizione del componente train.

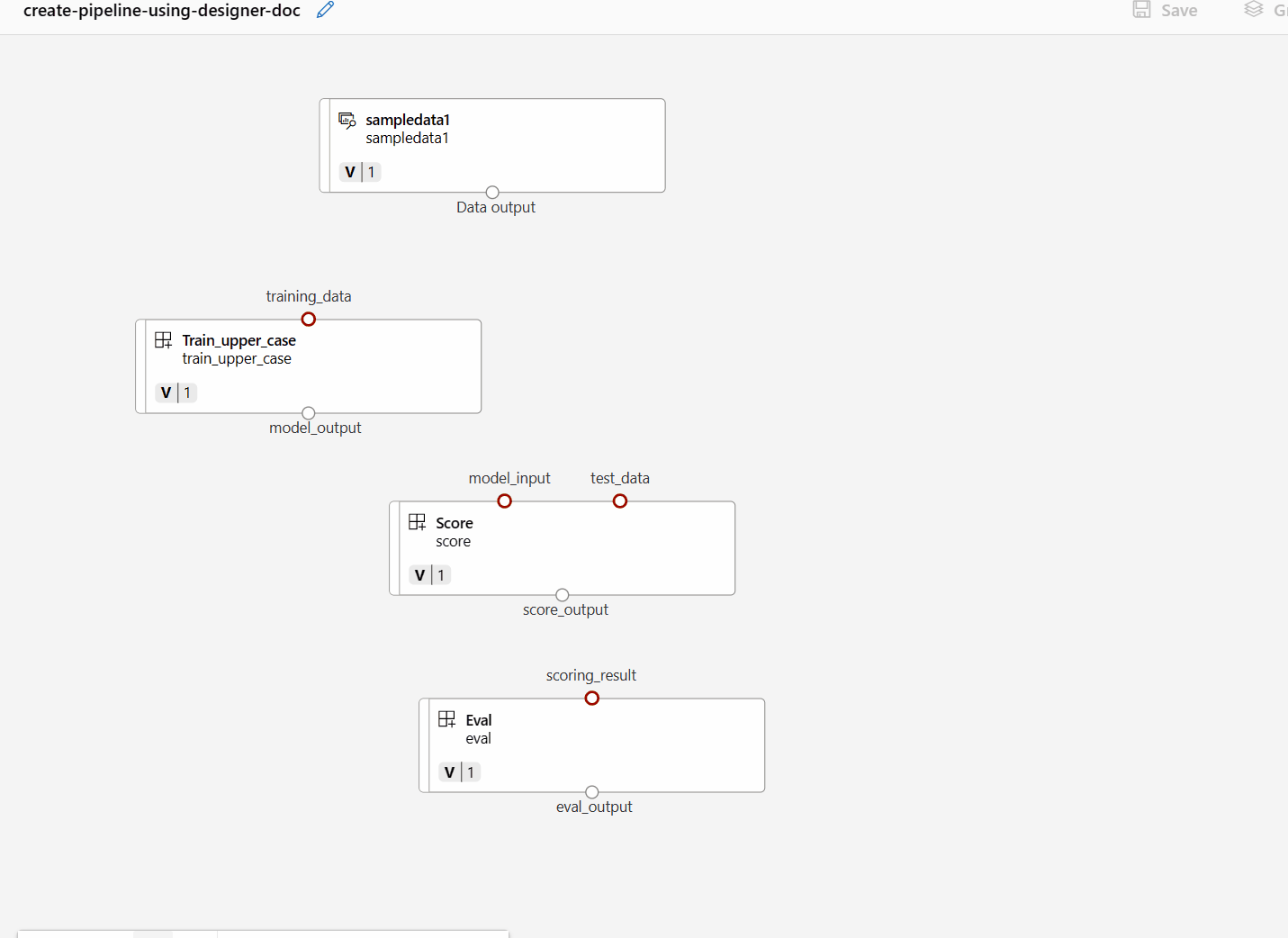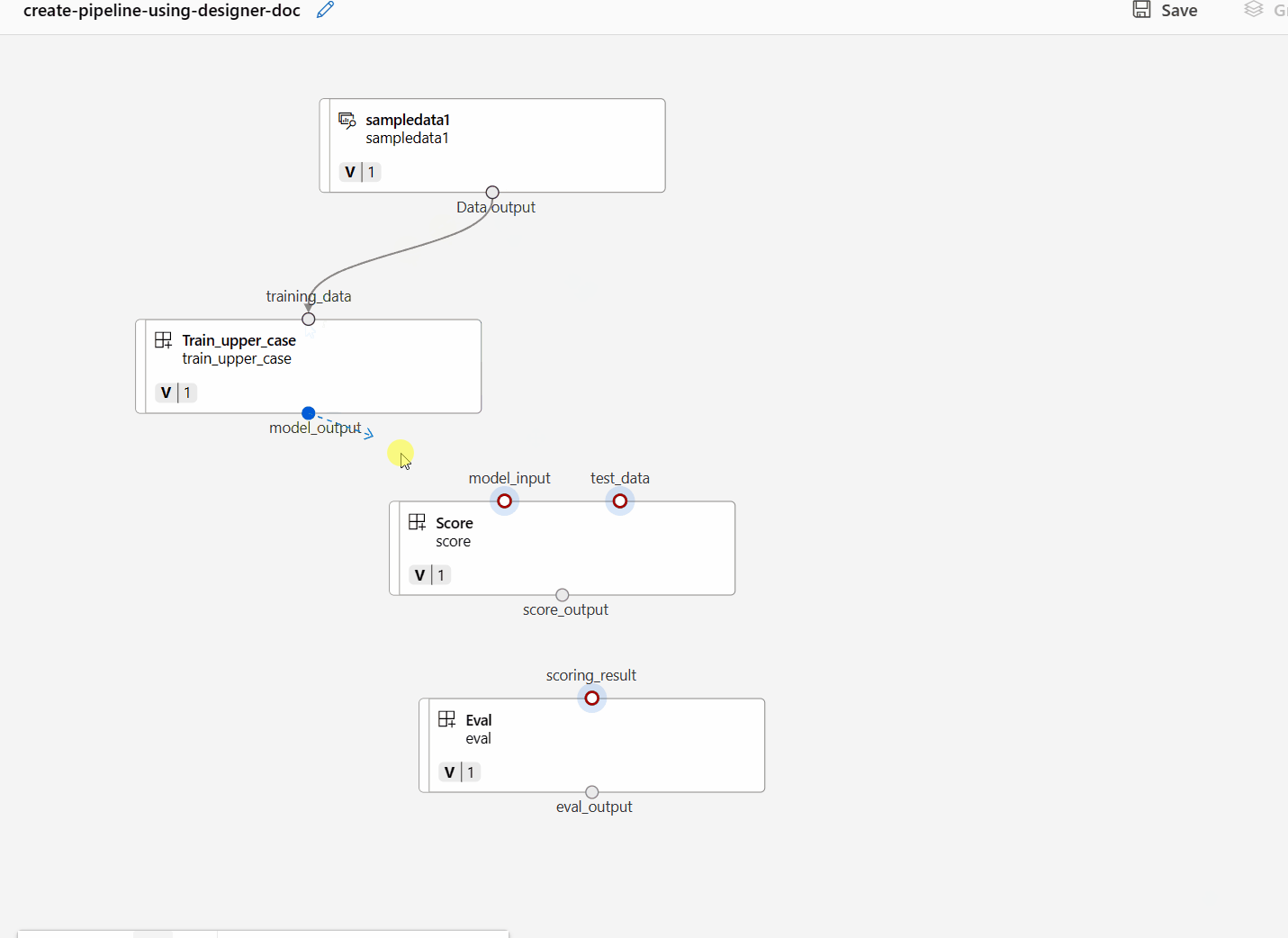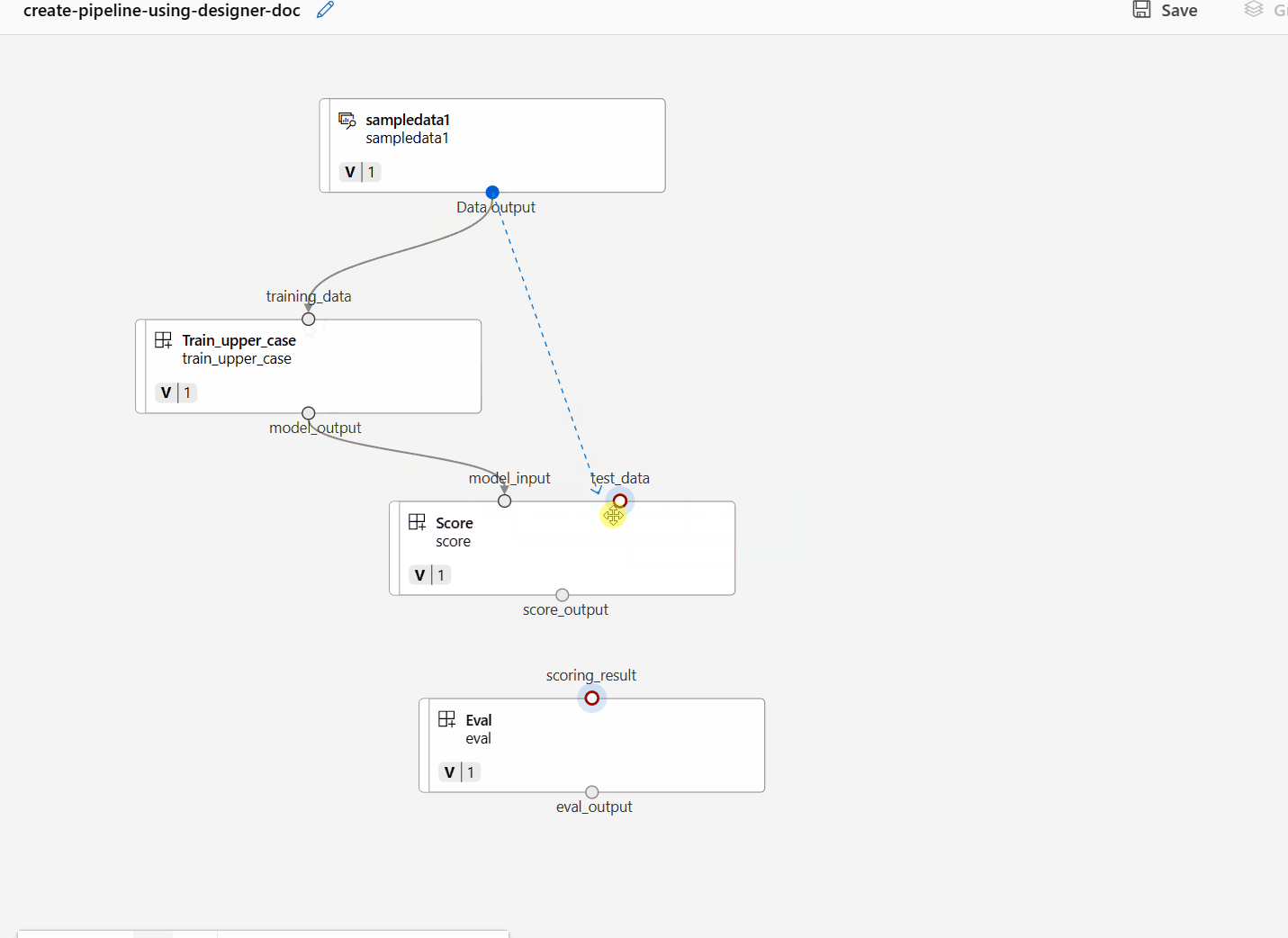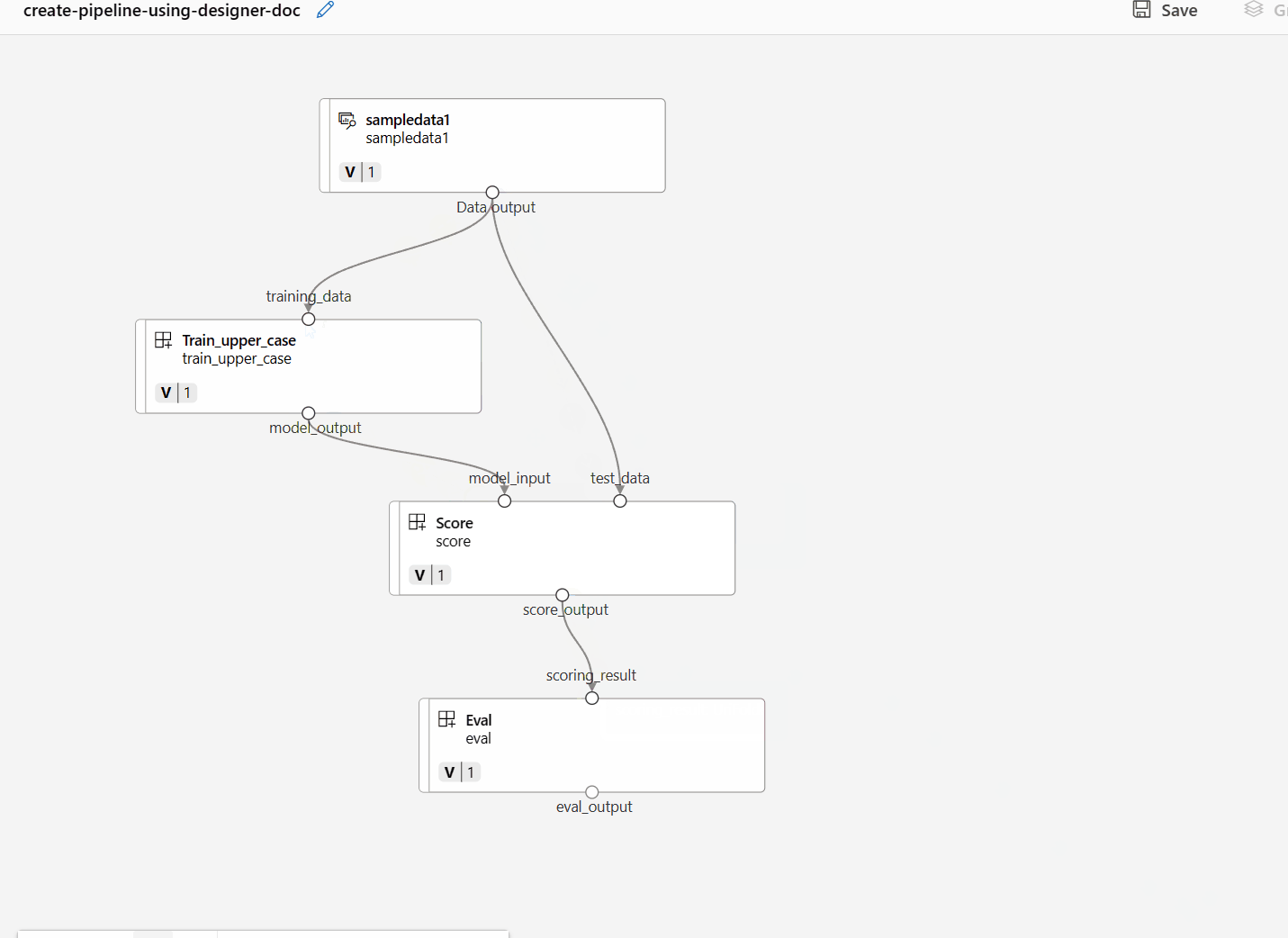
Trascinare quindi i dati nel canvas. L'aspetto della pipeline dovrebbe essere simile allo screenshot seguente.
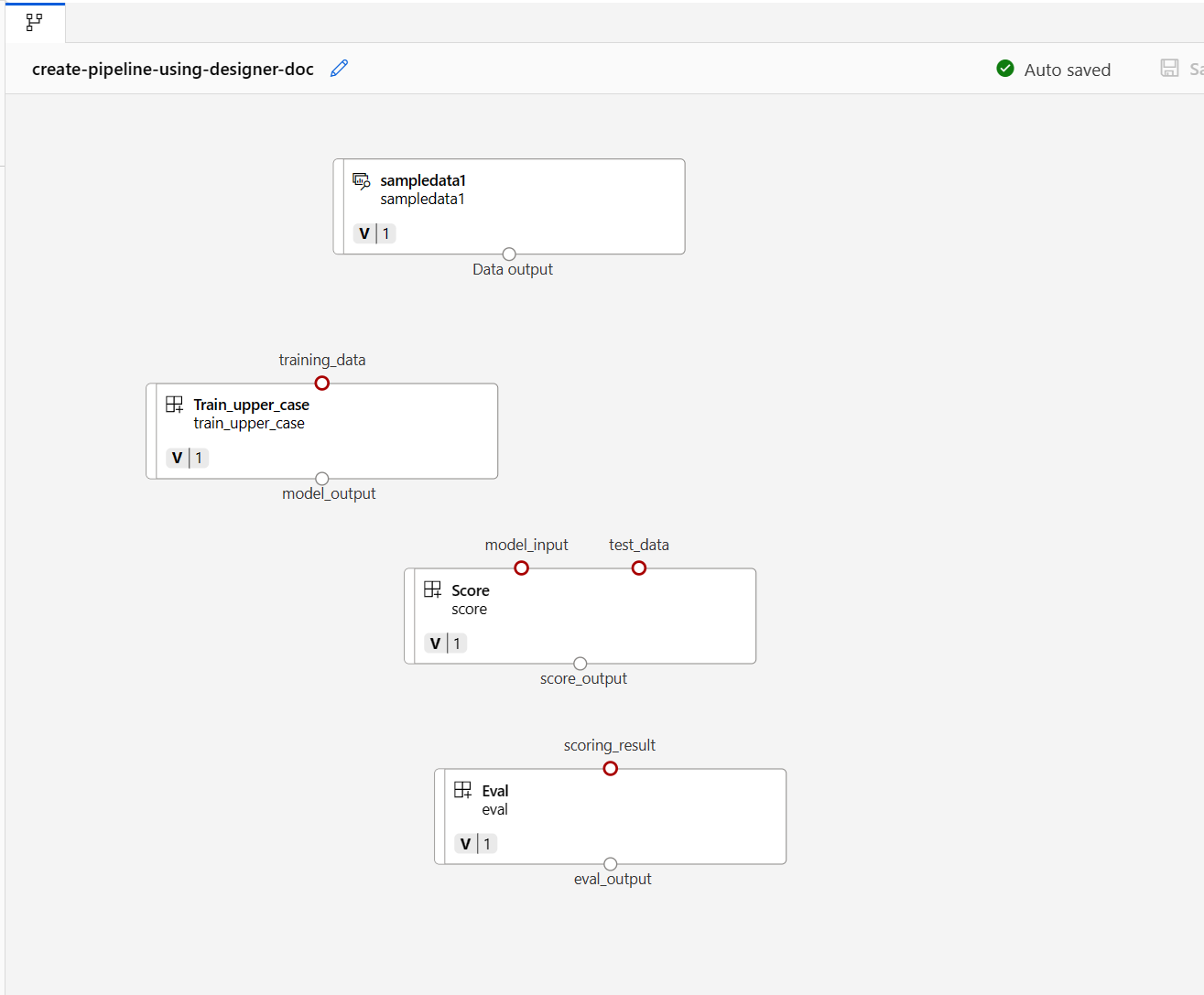
Connettere i dati e i componenti trascinando le connessioni nel canvas.
Fare doppio clic su un componente. Verrà visualizzato un riquadro destro in cui è possibile configurare il componente.
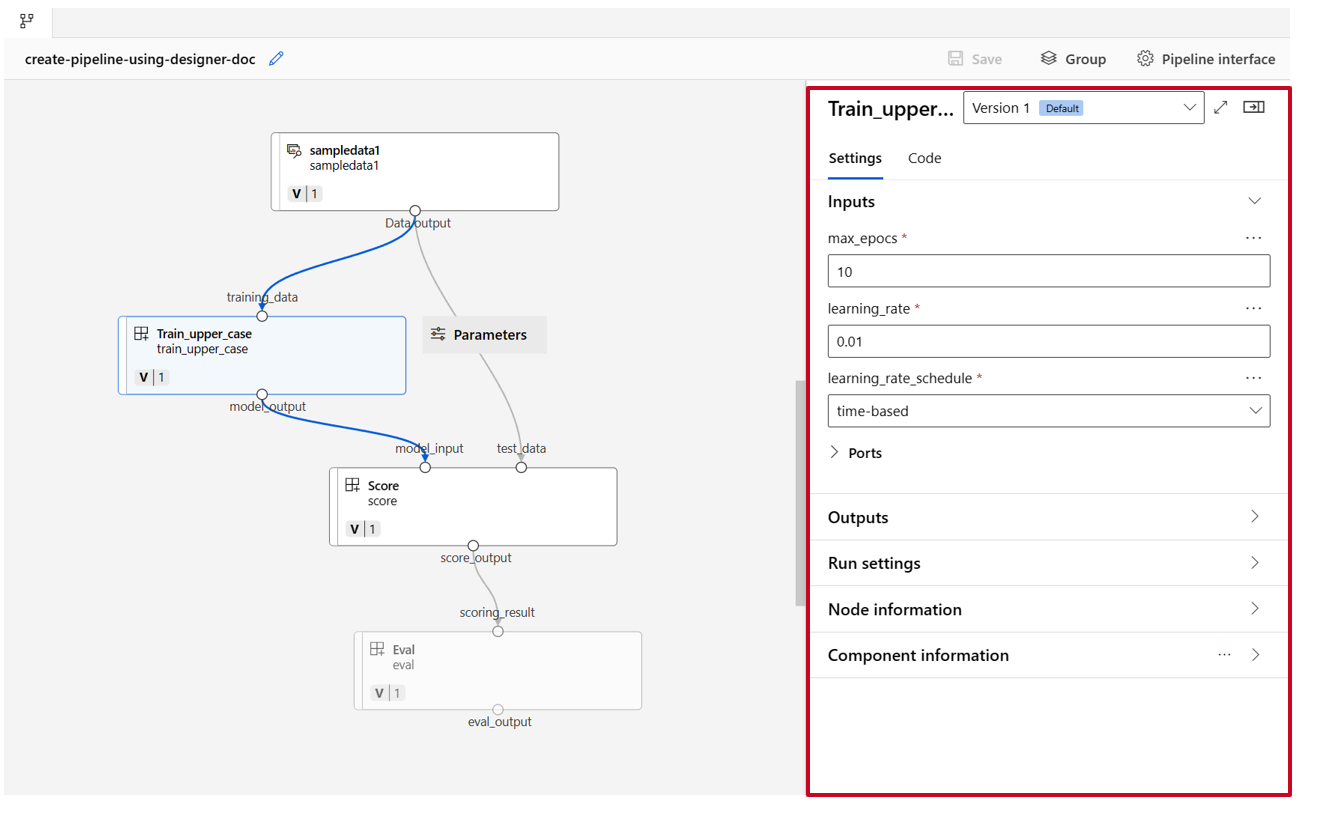
Per i componenti con input di tipo primitivo come numero, numero intero, stringa e booleano, è possibile modificare i valori di tali input nella sezione Input del riquadro dettagliato del componente.
È anche possibile modificare le impostazioni di output (dove archiviare l'output del componente) e le impostazioni di esecuzione (destinazione di calcolo per eseguire questo componente) nel riquadro destro.
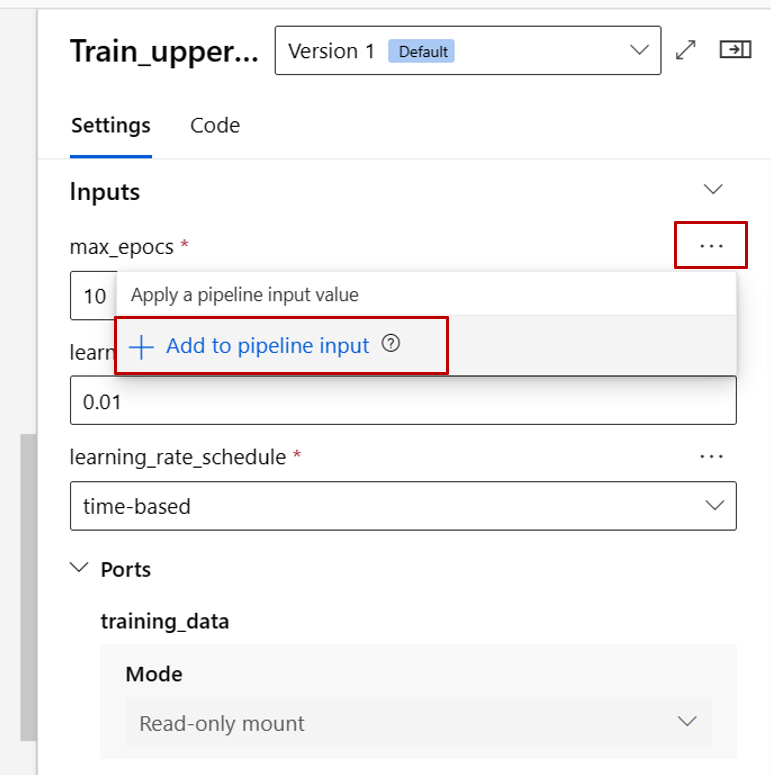
A questo punto, alzare di livello l'input max_epocs del componente train all'input a livello di pipeline. Ciò consente di assegnare un valore diverso a questo input ogni volta prima di inviare la pipeline.









Nota
I componenti personalizzati e i componenti predefiniti classici della finestra di progettazione non possono essere usati insieme.
Inviare la pipeline
Selezionare Configura e invia nell'angolo superiore destro per inviare la pipeline.

Verrà quindi visualizzata una procedura guidata dettagliata. Seguire la procedura guidata per inviare il processo della pipeline.

Nel passaggio Informazioni di base è possibile configurare l'esperimento, il nome visualizzato del processo, la descrizione del processo e così via.
Nel passaggio Input e output è possibile configurare gli input/output alzati al livello pipeline. Nel passaggio precedente l'input max_epocs del componente train è stato alzato di livello all'input della pipeline, quindi dovrebbe essere possibile visualizzare e assegnare valore a max_epocs qui.
In Impostazioni di runtimeè possibile configurare l'archivio dati predefinito e l'ambiente di calcolo predefinito della pipeline. Si tratta dell'archivio dati/ambiente di calcolo predefinito per tutti i componenti della pipeline. Si noti tuttavia che se si imposta un archivio dati o un ambiente di calcolo diverso per un componente in modo esplicito, il sistema rispetta l'impostazione del livello di componente. In caso contrario, usa il valore predefinito della pipeline.
Il passaggio Rivedi e invia è l'ultimo passaggio per esaminare tutte le configurazioni prima dell'invio. Se si invia la pipeline, la procedura guidata memorizza la configurazione dell'ultima volta.
Dopo aver inviato il processo della pipeline, nella parte superiore verrà visualizzato un messaggio con un collegamento al dettaglio del processo. È possibile selezionare questo collegamento per esaminare i dettagli del processo.

Specificare l'identità nel processo della pipeline
Quando si invia il processo della pipeline, è possibile specificare l'identità per accedere ai dati in Run settings. L'identità predefinita è AMLToken che non ha usato alcuna identità nel frattempo supportiamo sia UserIdentity che Managed. Per UserIdentity, l'identità del mittente del processo viene usata per accedere ai dati di input e scrivere il risultato nella cartella di output. Se si specifica Managed, il sistema userà l'identità gestita per accedere ai dati di input e scrivere il risultato nella cartella di output.

Passaggi successivi
- Usare questi notebook di Jupyter in GitHub per esplorare più in dettaglio le pipeline di Machine Learning
- Informazioni su come usare l'interfaccia della riga di comando v2 per creare pipeline usando i componenti.
- Informazioni su come usare l'SDK v2 per creare pipeline usando i componenti