Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
In questo articolo viene illustrato come distribuire il modello MLflow in un endpoint online per l'inferenza in tempo reale. Quando si distribuisce il modello MLflow in un endpoint online, non è necessario specificare uno script di assegnazione dei punteggi o un ambiente. Questa condizione è conosciuta come Distribuzione senza codice.
Per la distribuzione senza codice, Azure Machine Learning:
- Installa dinamicamente i pacchetti Python elencati in un file conda.yaml. Di conseguenza, le dipendenze vengono installate durante il runtime del contenitore.
- Fornisce un'immagine di base MLflow o un ambiente curato che contiene gli elementi seguenti:
- Il pacchetto
azureml-inference-server-http - Il pacchetto
mlflow-skinny - Uno script di assegnazione dei punteggi per l'inferenza
- Il pacchetto
Prerequisites
Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Un account utente che possiede almeno uno dei ruoli di controllo degli accessi in base al ruolo di Azure (Azure RBAC) seguenti:
- Ruolo proprietario per l'area di lavoro di Azure Machine Learning
- Ruolo Collaboratore per l'area di lavoro di Azure Machine Learning
- Ruolo personalizzato con
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*autorizzazioni
Per altre informazioni, vedere Gestire l'accesso alle aree di lavoro di Azure Machine Learning.
Accesso ad Azure Machine Learning:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
Installare l'interfaccia della riga di comando di Azure e l'estensione di
mlnell'interfaccia della riga di comando di Azure. Per la procedura di installazione, vedere Installare e configurare l'interfaccia della riga di comando (v2).
Informazioni sull'esempio
L'esempio riportato in questo articolo illustra come distribuire un modello MLflow in un endpoint online per eseguire stime. Nell'esempio viene usato un modello MLflow basato sul set di dati diabetes. Questo set di dati contiene 10 variabili di base: età, sesso, indice di massa corporea, pressione sanguigna media e 6 misurazioni del siero del sangue ottenute da 442 pazienti diabete. Contiene anche la risposta di interesse, una misura quantitativa della progressione della malattia un anno dopo la data dei dati di base.
Il training del modello è stato eseguito usando un scikit-learn regressore. Tutta la pre-elaborazione richiesta viene inserita in un pacchetto come pipeline, quindi questo modello è una pipeline end-to-end che passa dai dati non elaborati alle stime.
Le informazioni contenute in questo articolo si basano sugli esempi di codice del repository azureml-examples. Se si clona il repository, è possibile eseguire i comandi in questo articolo in locale senza dover copiare o incollare file YAML e altri file. Usare i comandi seguenti per clonare il repository e passare alla cartella per il linguaggio di codifica:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Seguire la procedura in Jupyter Notebook
Per seguire i passaggi descritti in questo articolo, vedere il notebook Distribuire il modello MLflow in endpoint online nel repository di esempi.
Connettersi all'area di lavoro
Connettersi all'area di lavoro di Azure Machine Learning:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
az account set --subscription <subscription-ID>
az configure --defaults workspace=<workspace-name> group=<resource-group-name> location=<location>
Registrare il modello
È possibile distribuire solo i modelli registrati in endpoint online. I passaggi descritti in questo articolo usano un modello sottoposto a training per il set di dati Diabetes. In questo caso, è già disponibile una copia locale del modello nel repository clonato, quindi è sufficiente pubblicare il modello nel Registro di sistema nell'area di lavoro. È possibile ignorare questo passaggio se il modello da distribuire è già registrato.
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
MODEL_NAME='sklearn-diabetes'
az ml model create --name $MODEL_NAME --type "mlflow_model" --path "endpoints/online/ncd/sklearn-diabetes/model"

Cosa accade se il modello è stato registrato all'interno di un'esecuzione?
Se il modello è stato registrato all'interno di un esperimento, è possibile registrarlo direttamente.
Per registrare il modello, è necessario conoscerne la posizione di archiviazione:
- Se si usa la funzionalità MLflow
autolog, il percorso del modello dipende dal tipo di modello e dal framework. Controllare l'output del job per identificare il nome della cartella del modello. Questa cartella contiene un file denominato MLModel. - Se si usa il metodo
log_modelper registrare manualmente i modelli, si passa il percorso del modello come argomento a quel metodo. Ad esempio, se si usamlflow.sklearn.log_model(my_model, "classifier")per registrare il modello,classifierè il percorso in cui è archiviato il modello.
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
È possibile l'interfaccia della riga di comando di Azure Machine Learning v2 per creare un modello da un output del processo di training. Il codice seguente usa gli artefatti di un lavoro con ID $RUN_ID per registrare un modello intitolato $MODEL_NAME.
$MODEL_PATH è il percorso usato dal processo per archiviare il modello.
az ml model create --name $MODEL_NAME --path azureml://jobs/$RUN_ID/outputs/artifacts/$MODEL_PATH

Distribuire un modello di MLflow in un endpoint online
Usare il codice seguente per configurare il nome e la modalità di autenticazione dell'endpoint in cui si vuole distribuire il modello:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
Impostare un nome endpoint eseguendo il comando seguente.
YOUR_ENDPOINT_NAMESostituire prima con un nome univoco.export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Per configurare l'endpoint, creare un file YAML denominato create-endpoint.yaml contenente le righe seguenti:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json name: my-endpoint auth_mode: keyCreare l'endpoint:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/ncd/create-endpoint.yamlConfigurare la distribuzione. Una distribuzione è un set di risorse necessarie per ospitare il modello che esegue effettivamente l'inferenza.
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
Creare un file YAML denominato sklearn-deployment.yaml contenente le righe seguenti:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-deployment endpoint_name: my-endpoint model: name: mir-sample-sklearn-ncd-model version: 2 path: sklearn-diabetes/model type: mlflow_model instance_type: Standard_DS3_v2 instance_count: 1Note
La generazione automatica di
scoring_scripteenvironmentè supportata solo per la variante del modelloPyFunc. Per usare un modello diverso, vedere Personalizzare le distribuzioni del modello MLflow.Creare la distribuzione:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
az ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficaz ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficAssegnare tutto il traffico alla distribuzione. Finora, l'endpoint dispone di una distribuzione, ma il traffico non viene assegnato ad esso.
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
Questo passaggio non è necessario nell'interfaccia della riga di comando di Azure se si usa il
--all-trafficflag durante la creazione. Se è necessario modificare il traffico, è possibile usare ilaz ml online-endpoint update --trafficcomando . Per altre informazioni su come aggiornare il traffico, vedere Aggiornare progressivamente il traffico.Aggiornare la configurazione dell'endpoint:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
Questo passaggio non è necessario nell'interfaccia della riga di comando di Azure se si usa il
--all-trafficflag durante la creazione. Se è necessario modificare il traffico, è possibile usare ilaz ml online-endpoint update --trafficcomando . Per altre informazioni su come aggiornare il traffico, vedere Aggiornare progressivamente il traffico.


Richiamare l'endpoint
Quando la distribuzione è pronta, è possibile usarla per gestire le richieste. Un modo per testare la distribuzione consiste nell'usare la funzionalità di chiamata predefinita nel client di distribuzione. Nel repository di esempi il file sample-request-sklearn.json contiene il codice JSON seguente. È possibile usarlo come file di richiesta di esempio per la distribuzione.
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
Note
Questo file usa la input_data chiave anziché inputs, che viene usata da MLflow. Azure Machine Learning richiede un formato di input diverso per poter generare automaticamente i contratti Swagger per gli endpoint. Per altre informazioni sui formati di input previsti, vedere Distribuzione nel server predefinito MLflow e distribuzione nel server di inferenza di Azure Machine Learning.
Inviare una richiesta all'endpoint:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
La risposta dovrebbe essere simile al testo seguente:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
[
11633.100167144921,
8522.117402884991
]
Important
Per MLflow no-code-deployment, il test tramite endpoint locali non è attualmente supportato.
Personalizzare le distribuzioni del modello MLflow
Non è necessario specificare uno script di assegnazione dei punteggi nella definizione di distribuzione di un modello MLflow a un endpoint online. È tuttavia possibile specificare uno script di assegnazione dei punteggi se si vuole personalizzare il processo di inferenza.
In genere si vuole personalizzare la distribuzione del modello MLflow nei casi seguenti:
- Il modello non ha una versione
PyFunc. - È necessario personalizzare la modalità di esecuzione del modello. Ad esempio, è necessario usare
mlflow.<flavor>.load_model()per caricare il modello con una variante specifica. - È necessario eseguire la pre-elaborazione o la post-elaborazione nella routine di assegnazione dei punteggi, perché il modello non esegue questa elaborazione.
- L'output del modello non può essere rappresentato correttamente nei dati tabulari. Ad esempio, l'output è un tensore che rappresenta un'immagine.
Important
Se si specifica uno script di assegnazione dei punteggi per una distribuzione del modello MLflow, è necessario specificare anche l'ambiente in cui viene eseguita la distribuzione.
Distribuire uno script di assegnazione dei punteggi personalizzato
Per distribuire un modello MLflow che usa uno script di assegnazione dei punteggi personalizzato, seguire questa procedura nelle sezioni seguenti.
Identificare la cartella del modello
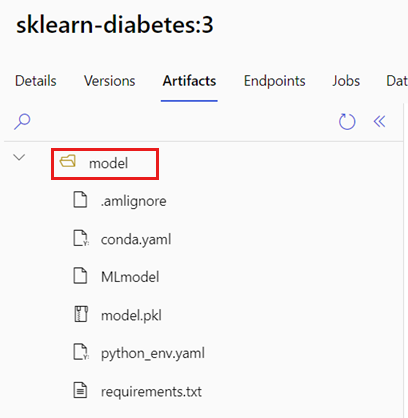
Identificare la cartella contenente il modello MLflow seguendo questa procedura:
Passare ad Azure Machine Learning Studio.
Passare alla sezione Modelli.
Selezionare il modello da distribuire e passare alla relativa scheda Artefatti.
Prendere nota della cartella visualizzata. Quando si registra un modello, specificare questa cartella.

Creare uno script di assegnazione del punteggio
Lo script di assegnazione dei punteggi seguente, score.py, fornisce un esempio di come eseguire l'inferenza con un modello MLflow. È possibile adattare questo script alle proprie esigenze o modificare una delle relative parti in modo da riflettere lo scenario. Si noti che il nome della cartella identificato in precedenza, model, è incluso nella init() funzione .
import logging
import os
import json
import mlflow
from io import StringIO
from mlflow.pyfunc.scoring_server import infer_and_parse_json_input, predictions_to_json
def init():
global model
global input_schema
# "model" is the path of the mlflow artifacts when the model was registered. For automl
# models, this is generally "mlflow-model".
model_path = os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model")
model = mlflow.pyfunc.load_model(model_path)
input_schema = model.metadata.get_input_schema()
def run(raw_data):
json_data = json.loads(raw_data)
if "input_data" not in json_data.keys():
raise Exception("Request must contain a top level key named 'input_data'")
serving_input = json.dumps(json_data["input_data"])
data = infer_and_parse_json_input(serving_input, input_schema)
predictions = model.predict(data)
result = StringIO()
predictions_to_json(predictions, result)
return result.getvalue()
Warning
Avviso MLflow 2.0: lo script di assegnazione dei punteggi di esempio funziona con MLflow 1.X e MLflow 2.X. Tuttavia, i formati di input e output previsti in tali versioni possono variare. Controllare la definizione dell'ambiente per visualizzare la versione di MLflow usata. MLflow 2.0 è supportato solo in Python 3.8 e versioni successive.
Crea un ambiente
Il passaggio successivo consiste nel creare un ambiente in cui è possibile eseguire lo script di assegnazione dei punteggi. Poiché il modello è un modello MLflow, i requisiti di conda vengono specificati anche nel pacchetto del modello. Per altre informazioni sui file inclusi in un modello MLflow, vedere Il formato MLmodel. Si compilerà quindi l'ambiente usando le dipendenze Conda dal file. È tuttavia necessario includere anche il azureml-inference-server-http pacchetto, necessario per le distribuzioni online in Azure Machine Learning.
È possibile creare un file di definizione conda denominato conda.yaml contenente le righe seguenti:
channels:
- conda-forge
dependencies:
- python=3.12
- pip
- pip:
- mlflow
- scikit-learn==1.7.0
- cloudpickle==3.1.1
- psutil==7.0.0
- pandas==2.3.0
- azureml-inference-server-http
name: mlflow-env
Note
La dependencies sezione di questo file conda include il azureml-inference-server-http pacchetto.
Usare questo file di dipendenze conda per creare l'ambiente:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
L'ambiente viene creato direttamente nella configurazione della distribuzione.
Creare la distribuzione
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
Nella cartella endpoints/online/ncd creare un file di configurazione della distribuzione, deployment.yml, che contiene le righe seguenti:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: sklearn-diabetes-custom
endpoint_name: my-endpoint
model: azureml:sklearn-diabetes@latest
environment:
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04
conda_file: sklearn-diabetes/environment/conda.yaml
code_configuration:
code: sklearn-diabetes/src
scoring_script: score.py
instance_type: Standard_F2s_v2
instance_count: 1
Creare la distribuzione:
az ml online-deployment create -f endpoints/online/ncd/deployment.yml


Gestire le richieste
Al termine della distribuzione, è pronto per gestire le richieste. Un modo per testare la distribuzione consiste nell'usare il invoke metodo con un file di richiesta di esempio, ad esempio il file seguente, sample-request-sklearn.json:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
Inviare una richiesta all'endpoint:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
La risposta dovrebbe essere simile al testo seguente:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
{
"predictions": [
1095.2797413413252,
1134.585328803727
]
}
Warning
Avviso MLflow 2.0: in MLflow 1.X la risposta non contiene la predictions chiave.
Pulire le risorse
Se l'endpoint non è più necessario, eliminare le risorse associate:
- Interfaccia della riga di comando di Azure
- Python (SDK di Azure Machine Learning)
- Python (MLflow SDK)
- Studio
az ml online-endpoint delete --name $ENDPOINT_NAME --yes