Registrare e visualizzare metriche e file di log (v1)
SI APPLICA A:  Python SDK azureml v1
Python SDK azureml v1
Registrare le informazioni in tempo reale usando sia il pacchetto di registrazione Python predefinito che la funzionalità specifica di Azure Machine Learning Python SDK. È possibile registrare in locale e inviare i log all'area di lavoro nel portale.
I log consentono di diagnosticare gli errori e gli avvisi o di tenete traccia di metriche delle prestazioni come parametri e prestazioni modello. Questo articolo illustra come abilitare la registrazione negli scenari seguenti:
- Registrare le metriche di esecuzione
- Sessioni di training interattive
- Invio dei processi di training tramite ScriptRunConfig
- Impostazioni di
loggingnative di Python - Registrazione da origini aggiuntive
Suggerimento
Questo articolo illustra come monitorare il processo di training dei modelli. Per informazioni sul monitoraggio dell'utilizzo delle risorse e di eventi di Azure Machine Learning, come quote, esecuzioni di training o distribuzioni di modelli completate, vedere Monitoraggio di Azure Machine Learning.
Tipo di dati
È possibile registrare più tipi di dati, tra cui valori scalari, elenchi, tabelle, immagini, directory e altro ancora. Per altre informazioni e per esempi di codice Python per tipi di dati diversi, vedere la pagina di informazioni di riferimento sulla classe Run.
Registrazione delle metriche di esecuzione
Usare i metodi seguenti nelle API di registrazione per influenzare le visualizzazioni delle metriche. Si notino i limiti del servizio per queste metriche registrate.
| Valore registrato | Codice di esempio | Formato nel portale |
|---|---|---|
| Registra una matrice di valori numerici | run.log_list(name='Fibonacci', value=[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]) |
Grafico a linee a singola variabile |
| Registra un valore numerico singolo con lo stesso nome di metrica usato più volte (come in un ciclo for) | for i in tqdm(range(-10, 10)): run.log(name='Sigmoid', value=1 / (1 + np.exp(-i))) angle = i / 2.0 |
Grafico a linee a singola variabile |
| Registra più volte una riga con due colonne numeriche | run.log_row(name='Cosine Wave', angle=angle, cos=np.cos(angle)) sines['angle'].append(angle) sines['sine'].append(np.sin(angle)) |
Grafico a linee a due variabili |
| Registra una tabella con due colonne numeriche | run.log_table(name='Sine Wave', value=sines) |
Grafico a linee a due variabili |
| Registrare un'immagine | run.log_image(name='food', path='./breadpudding.jpg', plot=None, description='desert') |
Usare questo metodo per registrare un file di immagine o un tracciato matplotlib per l'esecuzione. Queste immagini saranno visibili e confrontabili nel record dell'esecuzione |
Registrazione con MLflow
È consigliabile registrare modelli, metriche e artefatti con MLflow perché è open source e supporta la modalità locale per la portabilità cloud. La tabella e gli esempi di codice seguenti illustrano come usare MLflow per registrare metriche e artefatti dalle esecuzioni di training. Altre informazioni sui metodi di registrazione e sui modelli di progettazione di MLflow.
Assicurarsi di installare i pacchetti pip mlflow e azureml-mlflow nell'area di lavoro.
pip install mlflow
pip install azureml-mlflow
Impostare l'URI di verifica di MLflow in modo che punti al back-end di Azure Machine Learning per assicurarsi che le metriche e gli artefatti vengano registrati nell'area di lavoro.
from azureml.core import Workspace
import mlflow
from mlflow.tracking import MlflowClient
ws = Workspace.from_config()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.create_experiment("mlflow-experiment")
mlflow.set_experiment("mlflow-experiment")
mlflow_run = mlflow.start_run()
| Valore registrato | Codice di esempio | Note |
|---|---|---|
| Registrare un valore numerico (int o float) | mlflow.log_metric('my_metric', 1) |
|
| Registrare un valore booleano | mlflow.log_metric('my_metric', 0) |
0 = vero, 1 = falso |
| Registrare una stringa | mlflow.log_text('foo', 'my_string') |
Registrato come artefatto |
| Registrare metriche numpy o oggetti immagine PIL | mlflow.log_image(img, 'figure.png') |
|
| Registrare un tracciato matlotlib o un file immagine | mlflow.log_figure(fig, "figure.png") |
Visualizzare le metriche di esecuzione tramite l'SDK
È possibile visualizzare le metriche relative a un modello sottoposto a training usando run.get_metrics().
from azureml.core import Run
run = Run.get_context()
run.log('metric-name', metric_value)
metrics = run.get_metrics()
# metrics is of type Dict[str, List[float]] mapping metric names
# to a list of the values for that metric in the given run.
metrics.get('metric-name')
# list of metrics in the order they were recorded
È anche possibile accedere alle informazioni sull'esecuzione usando MLflow tramite le proprietà dei dati e delle informazioni dell'oggetto esecuzione. Per altre informazioni, vedere la documentazione dell'oggetto MLflow.entities.Run.
Al termine dell'esecuzione, è possibile recuperarla usando MlFlowClient().
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
finished_mlflow_run = MlflowClient().get_run(mlflow_run.info.run_id)
È possibile visualizzare le metriche, i parametri e i tag per l'esecuzione nel campo dati dell'oggetto esecuzione.
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
Nota
Il dizionario delle metriche in mlflow.entities.Run.data.metrics restituisce solo il valore registrato più di recente per un determinato nome di metrica. Ad esempio, se si registrano in ordine 1, 2, 3 e quindi 4 in una metrica denominata sample_metric, nel dizionario delle metriche per sample_metric sarà presente solo 4.
Per ottenere la registrazione di tutte le metriche per un nome di metrica specifico, è possibile usare MlFlowClient.get_metric_history().
Visualizzare le metriche di esecuzione nell'interfaccia utente di Studio
È possibile esplorare i record delle esecuzioni completate, incluse le metriche registrate, in studio di Azure Machine Learning.
Passare alla scheda Esperimenti. Per visualizzare tutte le esecuzioni nell'area di lavoro per i vari esperimenti, selezionare la scheda Tutte le esecuzioni. È possibile eseguire il drill-down delle esecuzioni per esperimenti specifici applicando il filtro Esperimento nella barra dei menu in alto.
Per visualizzare un singolo esperimento, selezionare la scheda Tutti gli esperimenti. Nel dashboard di esecuzione dell'esperimento è possibile visualizzare le metriche e i log registrati per ogni esecuzione.
È anche possibile modificare la tabella dell'elenco di esecuzioni per selezionare più esecuzioni e visualizzare l'ultimo valore, il valore minimo o il valore massimo registrato per le esecuzioni. Personalizzare i grafici per confrontare i valori delle metriche registrate e le aggregazioni tra più esecuzioni. È possibile tracciare più metriche sull'asse y del grafico e personalizzare l'asse x per tracciare le metriche registrate.
Visualizzare e scaricare i file di log per un'esecuzione
I file di log sono una risorsa essenziale per il debug dei carichi di lavoro di Azure Machine Learning. Dopo aver inviato un processo di training, eseguire il drill-down di un'esecuzione specifica per visualizzare i log e gli output:
- Passare alla scheda Esperimenti.
- Selezionare il runID per un'esecuzione specifica.
- Selezionare Output e log nella parte superiore della pagina.
- Selezionare Scarica tutto per scaricare tutti i log in una cartella ZIP.
- È anche possibile scaricare singoli file di log scegliendo il file di log e selezionando Scarica
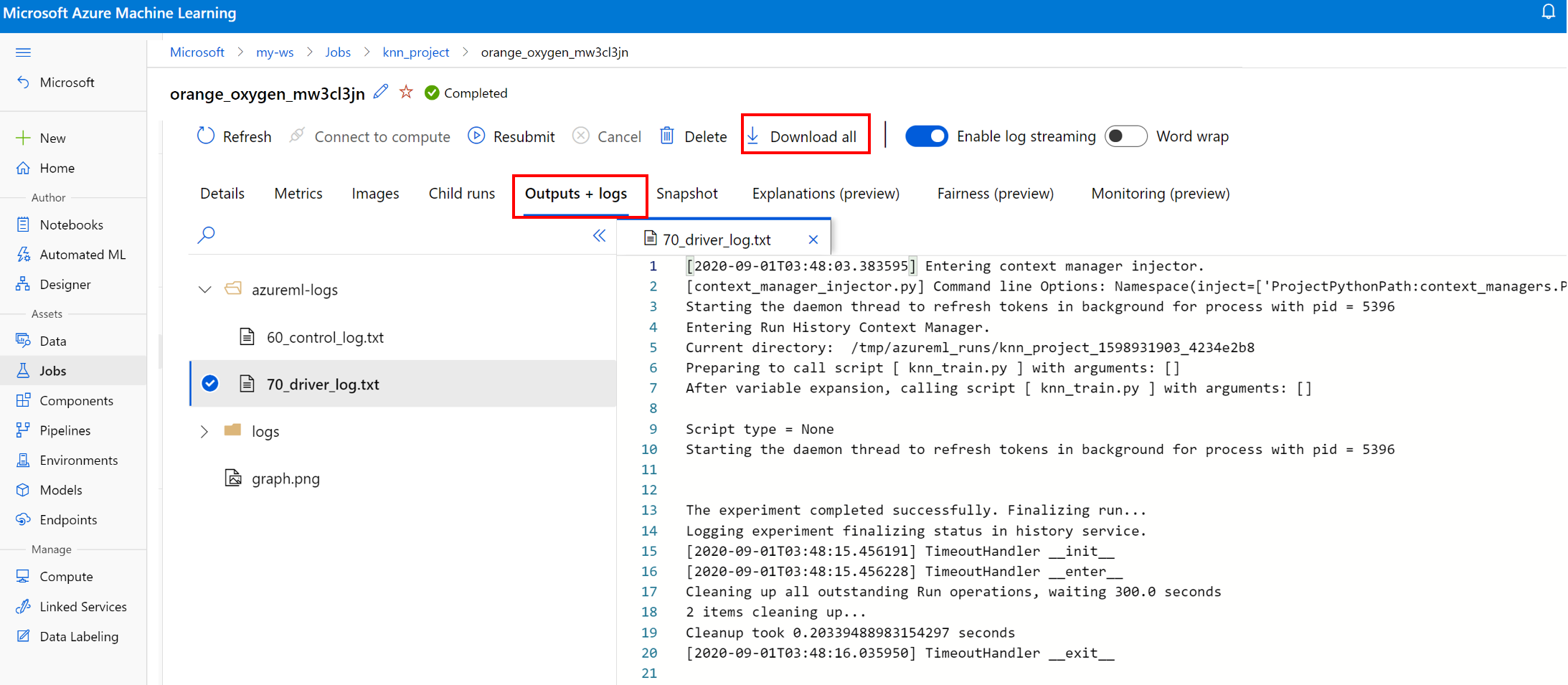
Cartella user_logs
Questa cartella contiene informazioni sui log generati dall'utente. Questa cartella è aperta per impostazione predefinita e viene selezionato il log std_log.txt. std_log.txt è la posizione in cui vengono visualizzati i log del codice (ad esempio, le istruzioni di stampa). Questo file contiene il log stdout e i log stderr dallo script di controllo e dallo script di training, uno per processo. Nella maggior parte dei casi, i log verranno monitorati qui.
Cartella system_logs
Questa cartella contiene i log generati da Azure Machine Learning e verrà chiusa per impostazione predefinita. I log generati dal sistema vengono raggruppati in cartelle diverse, in base alla fase del processo nel runtime.
Altre cartelle
Per il training dei processi nei cluster con più risorse di calcolo, sono presenti log per l'indirizzo IP di ogni nodo. La struttura per ogni nodo è identica a quella dei processi a nodo singolo. È disponibile un'ulteriore cartella di log per i log di esecuzione generale, stderr e stdout.
Azure Machine Learning registra le informazioni provenienti da varie origini durante il training, ad esempio AutoML o il contenitore Docker che esegue il processo di training. Molti di questi log non sono documentati. Se si verificano problemi e si contatta il supporto tecnico Microsoft, l'agente potrebbe essere in grado di utilizzare questi log durante la risoluzione dei problemi.
Sessione di registrazione interattiva
Le sessioni di registrazione interattive vengono in genere usate negli ambienti notebook. Il metodo Experiment.start_logging() avvia una sessione di registrazione interattiva. Le metriche registrate durante la sessione vengono aggiunte al record esecuzione nell'esperimento. Il metodo run.complete() termina le sessioni e contrassegna l'esecuzione come completata.
Log ScriptRun
Questa sezione illustra come aggiungere codice di registrazione all'interno delle esecuzioni create se la configurazione è stata eseguita con ScriptRunConfig. È possibile usare la classe ScriptRunConfig per incapsulare gli script e gli ambienti per esecuzioni ripetibili. È anche possibile usare questa opzione per mostrare un widget visuale di Jupyter Notebook per il monitoraggio.
Questo esempio esegue uno spostamento di parametri su valori alfa e acquisisce i risultati con il metodo run.log().
Creare uno script di training che include la logica di registrazione,
train.py.# Copyright (c) Microsoft. All rights reserved. # Licensed under the MIT license. from sklearn.datasets import load_diabetes from sklearn.linear_model import Ridge from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split from azureml.core.run import Run import os import numpy as np import mylib # sklearn.externals.joblib is removed in 0.23 try: from sklearn.externals import joblib except ImportError: import joblib os.makedirs('./outputs', exist_ok=True) X, y = load_diabetes(return_X_y=True) run = Run.get_context() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) data = {"train": {"X": X_train, "y": y_train}, "test": {"X": X_test, "y": y_test}} # list of numbers from 0.0 to 1.0 with a 0.05 interval alphas = mylib.get_alphas() for alpha in alphas: # Use Ridge algorithm to create a regression model reg = Ridge(alpha=alpha) reg.fit(data["train"]["X"], data["train"]["y"]) preds = reg.predict(data["test"]["X"]) mse = mean_squared_error(preds, data["test"]["y"]) run.log('alpha', alpha) run.log('mse', mse) model_file_name = 'ridge_{0:.2f}.pkl'.format(alpha) # save model in the outputs folder so it automatically get uploaded with open(model_file_name, "wb") as file: joblib.dump(value=reg, filename=os.path.join('./outputs/', model_file_name)) print('alpha is {0:.2f}, and mse is {1:0.2f}'.format(alpha, mse))Inviare lo script
train.pyper l'esecuzione in un ambiente gestito dall'utente. L'intera cartella di script viene inviata per il training.from azureml.core import ScriptRunConfig src = ScriptRunConfig(source_directory='./scripts', script='train.py', environment=user_managed_env)run = exp.submit(src)Il parametro
show_outputattiva la registrazione dettagliata, che consente di visualizzare i dettagli dal processo di training oltre a informazioni su tutte le risorse remote o le destinazioni di calcolo. Usare il codice seguente per attivare la registrazione dettagliata quando si invia l'esperimento.run = exp.submit(src, show_output=True)È anche possibile usare lo stesso parametro nella funzione
wait_for_completionall'esecuzione risultante.run.wait_for_completion(show_output=True)
Registrazione nativa di Python
Alcuni log nell'SDK possono contenere un errore che indica di impostare il livello di registrazione su DEBUG. Per impostare il livello di registrazione, aggiungere il codice seguente allo script.
import logging
logging.basicConfig(level=logging.DEBUG)
Altre soluzioni di registrazione
Azure Machine Learning può anche registrare le informazioni provenienti da altre origini durante il training, ad esempio le esecuzioni di Machine Learning automatizzato o i contenitori Docker che eseguono i processi. Questi log non sono documentati, ma se si verificano problemi e si contatta il supporto tecnico Microsoft, potrebbero risultare utili per la risoluzione.
Per informazioni sulla registrazione di metriche nella finestra di progettazione di Azure Machine Learning, vedere Come registrare le metriche nella finestra di progettazione
Notebook di esempio
I notebook seguenti illustrano i concetti descritti in questo articolo:
- how-to-use-azureml/training/train-on-local
- how-to-use-azureml/track-and-monitor-experiments/logging-api
Per informazioni su come eseguire i notebook, vedere l'articolo Esplorare Azure Machine Learning con notebook Jupyter.
Passaggi successivi
Per altre informazioni su come usare Azure Machine Learning, vedere questi articoli:
- Vedere un esempio di come registrare il modello migliore e distribuirlo nell'esercitazione Eseguire il training di un modello di classificazione delle immagini con Azure Machine Learning.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per