Generare informazioni dettagliate sull'intelligenza artificiale responsabile nell'interfaccia utente di Studio
In questo articolo viene creato un dashboard di intelligenza artificiale responsabile e una scorecard (anteprima) con un'esperienza senza codice nell'interfaccia utente di Azure Machine Learning Studio.
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza contratto di servizio, pertanto se ne sconsiglia l’uso per i carichi di lavoro in ambienti di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Procedere come segue per accedere alla generazione guidata del dashboard e generare un dashboard di intelligenza artificiale responsabile:
Registrare il modello in Azure Machine Learning in modo da poter accedere all'esperienza senza codice.
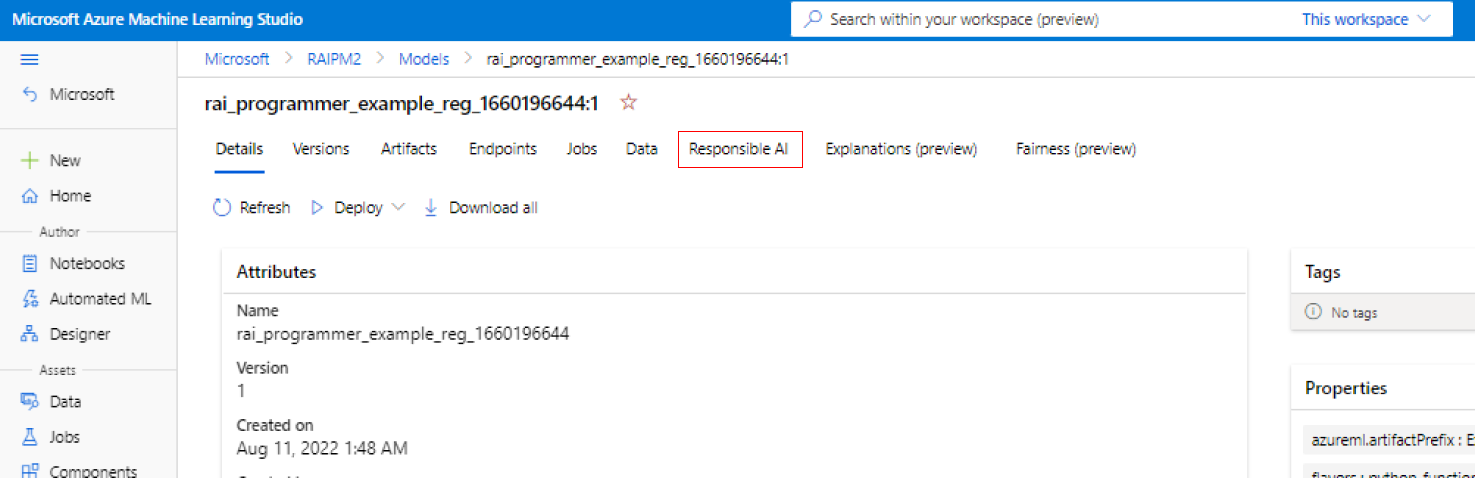
Nel riquadro a sinistra di Studio di Azure Machine Learning selezionare la scheda Modelli.
Selezionare il modello registrato per cui si desidera creare informazioni dettagliate sull'intelligenza artificiale responsabile e selezionare la scheda Dettagli.
Selezionare Creare un dashboard di intelligenza artificiale responsabile (anteprima).

Per altre informazioni sui tipi di modello e sulle limitazioni supportati nel dashboard di intelligenza artificiale responsabile, vedere scenari e limitazioni supportati.
La procedura guidata fornisce un'interfaccia per l'immissione di tutti i parametri necessari per creare il dashboard di intelligenza artificiale responsabile senza toccare il codice. L'esperienza ha luogo interamente nell'interfaccia utente di Studio di Azure Machine Learning. Studio presenta un flusso guidato e un testo informativo per facilitare la contestualizzazione della varietà di scelte su quali componenti IA responsabile si desidera popolare il dashboard.
La procedura guidata è suddivisa in cinque sezioni:
- Set di dati di training
- Set di dati di test
- Attività di modellazione
- Componenti del dashboard
- Parametri del componente
- Configurazione dell'esperimento
Selezionare i set di dati
Nelle prime due sezioni si selezionano i set di dati di training e test usati durante il training del modello per generare informazioni dettagliate sul debug del modello. Per i componenti come l'analisi causale, che non richiede un modello, si usa il set di dati di training per eseguire il training del modello causale e generare le informazioni dettagliate causali.
Nota
Sono supportati solo i formati di set di dati tabulari nella tabella ML.
Seleziona un set di dati per il training: nell'elenco dei set di dati registrati nell'area di lavoro di Azure Machine Learning selezionare il set di dati da usare per generare informazioni dettagliate sull'intelligenza artificiale responsabile per i componenti, ad esempio spiegazioni del modello e analisi degli errori.
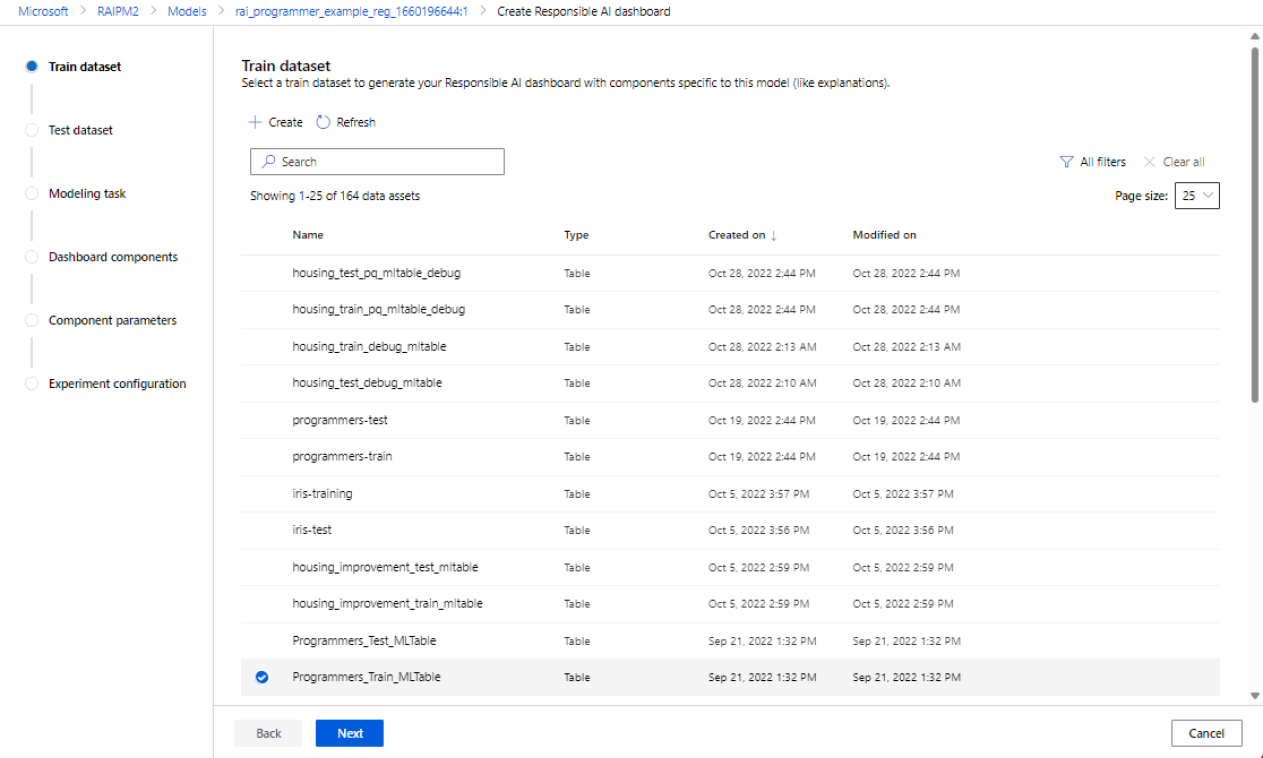
Seleziona un set di dati per il test: nell'elenco dei set di dati registrati, selezionare il set di dati da usare per popolare le visualizzazioni del dashboard di intelligenza artificiale responsabile.

Se il set di dati di training o di test da usare non è elencato, selezionare Crea per caricarlo.


Selezionare l'attività di modellazione
Dopo aver selezionato i set di dati, selezionare il tipo di attività di modellazione, come illustrato nell'immagine seguente:

Selezionare i componenti del dashboard
Il dashboard di intelligenza artificiale responsabile offre due profili per i set consigliati di strumenti che è possibile generare:
Debug del modello: comprendere ed eseguire il debug di coorti di dati errate nel modello di Machine Learning usando l'analisi degli errori, gli esempi di simulazione controfattuale e la spiegazione del modello.
Interventi reali: comprendere ed eseguire il debug di coorti di dati errati nel modello di Machine Learning usando l'analisi causale.
Nota
La classificazione multiclasse non supporta il profilo di analisi di interventi reali.

- Selezionare il profilo da usare.
- Selezionare Avanti.
Configurare i parametri per i componenti del dashboard
Dopo aver selezionato un profilo, viene visualizzato il riquadro di configurazione Parametri del componente per il debug del modello per i componenti corrispondenti.

Parametri dei componenti per il debug del modello:
Funzionalità di destinazione (obbligatoria): specificare la funzionalità che il modello deve stimare il base al training.
Funzionalità categoriche: indicare quali funzionalità sono categoriche per eseguirne correttamente il rendering come valori categorici nell'interfaccia utente del dashboard. Questo campo è precaricato in base ai metadati del set di dati.
Genera albero degli errori e mappa termica: attivare e disattivare questa opzione per generare un componente di analisi degli errori per il dashboard di intelligenza artificiale responsabile.
Funzionalità per la mappa termica degli errori: selezionare fino a due funzionalità per cui pre-generare una mappa termica degli errori.
Configurazione avanzata: specificare parametri aggiuntivi, ad esempio Profondità massima dell'albero degli errori, Numero di foglie nell'albero degli errori e Numero minimo di campioni in ogni nodo foglia.
Generare esempi di simulazione controfattuale: attivare e disattivare per generare un componente di simulazione controfattuale per il dashboard di intelligenza artificiale responsabile.
Numero di controfattuali (obbligatorio): specificare il numero di esempi controfattuali che si desidera generare per punto dati. Per ottenere la previsione desiderata, è generalmente necessario generarne almeno 10 per consentire una vista a grafico a barre delle funzionalità che sono state maggiormente perturbate.
Intervallo di stime dei valori (obbligatorio): specificare per gli scenari di regressione l'intervallo in cui gli esempi controfattuali devono includere valori di stima. Per gli scenari di classificazione binaria, l'intervallo verrà impostato automaticamente per generare controfattuali per la classe opposta di ogni punto dati. Per gli scenari di classificazione multipla, usare l'elenco a discesa per specificare la classe in base alla quale si desidera stimare ogni punto dati.
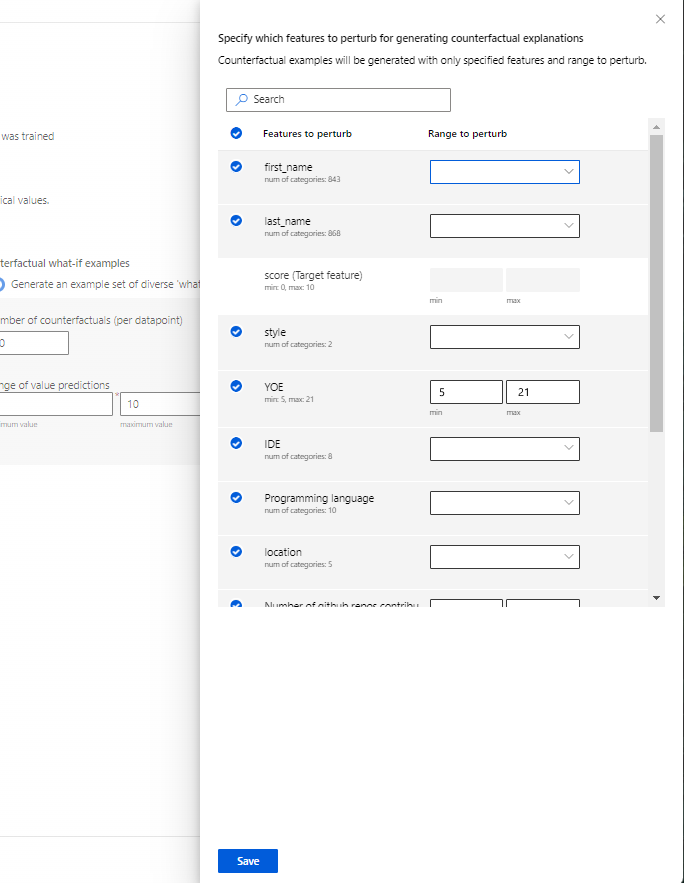
Specifica le funzionalità da perturbare: per impostazione predefinita, verranno perturbate tutte le funzionalità. Tuttavia, se si desidera perturbare solo funzionalità specifiche, selezionare Specifica le funzionalità da perturbare per la generazione di spiegazioni controfattuali per visualizzare un riquadro con un elenco di funzionalità da selezionare.
Quando si seleziona Specifica le funzionalità da perturbare, è possibile specificare l'intervallo in cui consentire le perturbazioni. Ad esempio: per la funzionalità YOE (Years Of Experience), specificare che i controfattuali devono avere valori di funzionalità compresi solo tra 10 e 21 anziché i valori predefiniti da 5 a 21.
Genera spiegazioni: attivare e disattivare questa opzione per generare un componente di spiegazione del modello per il dashboard di intelligenza artificiale responsabile. Non è necessaria alcuna configurazione, perché verrà usato un explainer box mimic opaco predefinito per generare le importanze delle caratteristiche.

In alternativa, se si seleziona il profilo di Interventi reali, verrà visualizzata la schermata seguente per la generazione di un'analisi causale. Ciò facilita la comprensione degli effetti causali delle funzionalità da “trattare” su un determinato risultato da ottimizzare.

I parametri dei componenti per gli interventi reali usano l'analisi causale. Effettua le operazioni seguenti:
- Funzionalità di destinazione (obbligatoria): scegliere il risultato per cui calcolare gli effetti causali.
- Funzionalità di trattamento (obbligatorio): scegliere una o più funzionalità di interesse nella modifica (“trattamento”) per l’ottimizzazione del risultato di destinazione.
- Funzionalità categoriche: indicare quali funzionalità sono categoriche per eseguirne correttamente il rendering come valori categorici nell'interfaccia utente del dashboard. Questo campo è precaricato in base ai metadati del set di dati.
- Impostazioni avanzate: specificare parametri aggiuntivi per l'analisi causale, ad esempio funzionalità eterogenee (vale a dire funzionalità aggiuntive per comprendere la segmentazione causale nell'analisi, oltre alle funzionalità di trattamento), e il modello causale da usare.
Configurare l'esperimento
Infine, configurare l'esperimento per avviare un processo per la generazione del dashboard di intelligenza artificiale responsabile.

Nel riquadro Processo di training o Configurazione esperimento, effettuare le operazioni seguenti:
- Nome: assegnare al dashboard un nome univoco in modo che sia possibile distinguerlo quando si visualizza l'elenco di dashboard per un determinato modello.
- Nome esperimento: selezionare un esperimento esistente in cui eseguire il processo o creare un nuovo esperimento.
- Esperimento esistente: selezionare un esperimento esistente dall'elenco a discesa.
- Seleziona tipo di calcolo: specificare il tipo di calcolo da usare per l’esecuzione del processo.
- Seleziona ambiente di calcolo: selezionare l’ambiente di calcolo da usare dall’elenco a discesa. Se non sono presenti risorse di calcolo esistenti, selezionare il segno più (+), creare una nuova risorsa di calcolo e aggiornare l'elenco.
- Descrizione: aggiungere una descrizione più lunga del dashboard di intelligenza artificiale responsabile.
- Tag: aggiungere tag a questo dashboard di intelligenza artificiale responsabile.
Dopo aver completato la configurazione dell'esperimento, selezionare Crea per avviare la generazione del dashboard di intelligenza artificiale responsabile. Si verrà reindirizzati alla pagina dell'esperimento per tenere traccia dello stato di avanzamento del processo con un collegamento al dashboard di intelligenza artificiale responsabile risultante dalla pagina del processo una volta terminato.
Per informazioni su come visualizzare e usare il dashboard di intelligenza artificiale responsabile, vedere Usare il dashboard di intelligenza artificiale responsabile in Studio di Azure Machine Learning.
Come generare la scorecard di intelligenza artificiale responsabile (anteprima)
Dopo aver creato un dashboard, è possibile usare un'interfaccia utente senza codice in Studio di Azure Machine Learning per personalizzare e generare una scorecard di intelligenza artificiale responsabile. In questo modo è possibile condividere informazioni dettagliate chiave per la distribuzione responsabile del modello, ad esempio l'equità e l'importanza della caratteristica, con stakeholder tecnici e non. Analogamente alla creazione di un dashboard, è possibile seguire questa procedura per accedere alla generazione guidata di scorecard:
- Passare alla scheda Modelli dalla barra di navigazione a sinistra in Studio di Azure Machine Learning.
- Selezionare il modello registrato per cui si desidera creare una scorecard e selezionare la scheda Intelligenza artificiale responsabile.
- Nel pannello superiore selezionare Crea informazioni dettagliate sull'intelligenza artificiale responsabile (anteprima) seguito da Genera nuova scorecard PDF.
La procedura guidata consente di personalizzare la scorecard PDF senza dover toccare il codice. L'esperienza ha luogo interamente in Studio di Azure Machine Learning per consentire di contestualizzare la varietà di scelte dell'interfaccia utente con un flusso guidato e un testo informativo che consenta di scegliere i componenti con cui si desidera popolare la scorecard. La procedura guidata è suddivisa in sette passaggi, con un ottavo passaggio (valutazione dell'equità) che sarà visualizzato solo per i modelli con caratteristiche categoriche:
- Riepilogo scorecard PDF
- Prestazioni modello
- Selezione strumento
- Analisi dei dati (precedentemente denominata Esplora dati)
- Analisi causale
- Interpretabilità
- Configurazione dell'esperimento
- Valutazione dell'equità (solo se esistono caratteristiche categoriche)
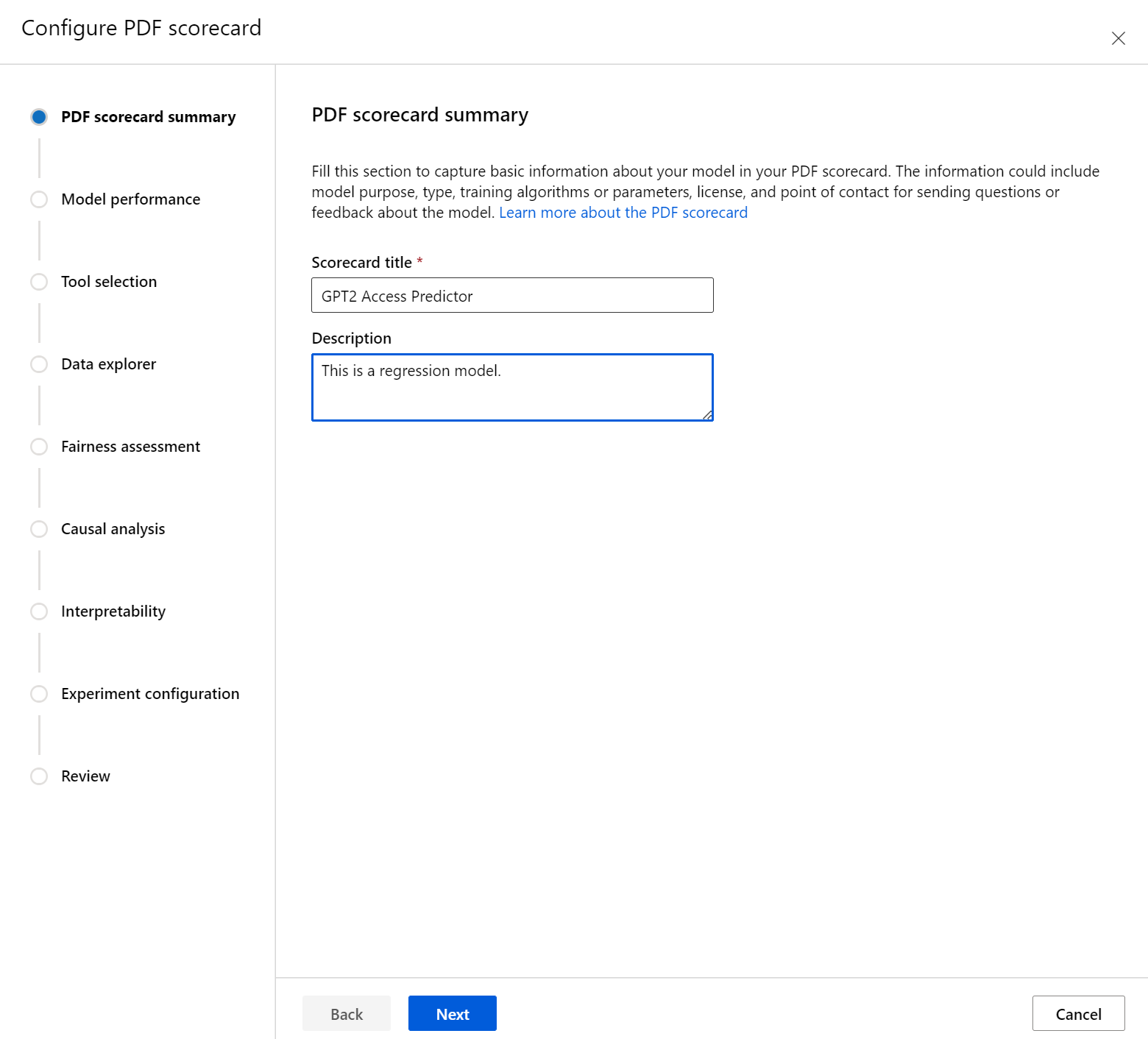
Configurazione della scorecard
Immettere prima di tutto un titolo descrittivo per la scorecard. È anche possibile immettere una descrizione facoltativa delle funzionalità del modello, i dati su cui è stato eseguito il training e la valutazione, il tipo di architettura e altro ancora.
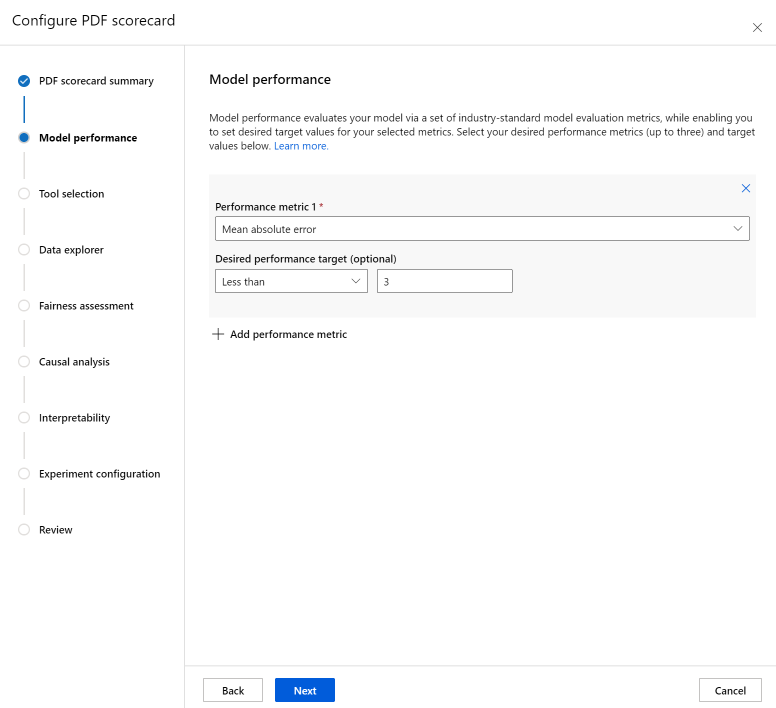
La sezione Prestazioni modello consente di incorporare nello scorecard metriche di valutazione del modello standard del settore, così da impostare i valori di destinazione desiderati per le metriche selezionate. Selezionare le metriche delle prestazioni desiderate (fino a tre) e i valori di destinazione usando gli elenchi a discesa.
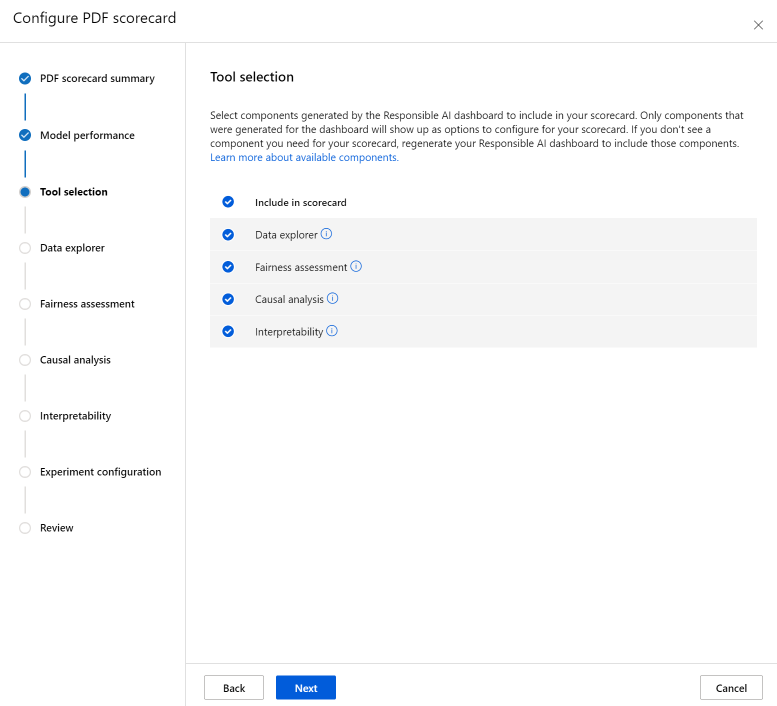
Il passaggio Selezione strumento consente di scegliere quali componenti successivi si desidera includere nella scorecard. Selezionare Includi nella scorecard per includere tutti i componenti, oppure selezionare/deselezionare singolarmente ogni componente. Selezionare l'icona delle informazioni ("i" in un cerchio) accanto ai componenti per saperne di più su di essi.
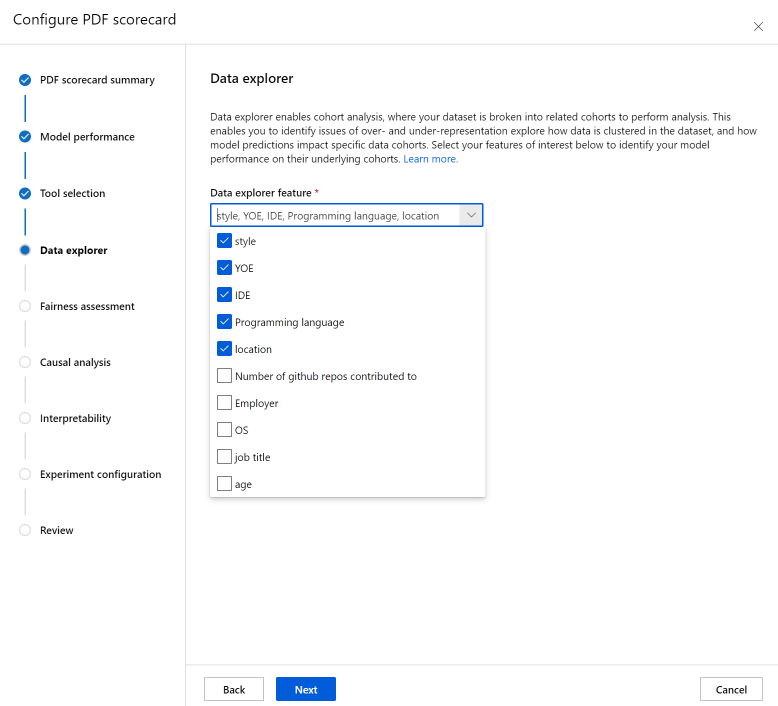
La sezione Analisi dei dati (denominata in precedenza Esplora dati) abilita l'analisi della coorte. In questo caso, è possibile identificare i problemi di sopra-e-sotto-rappresentazione, per esplorare il modo in cui i dati vengono raggruppati nel set di dati e le stime del modello influiscono sulle coorti di dati specifiche. Usare le caselle di controllo nell'elenco a discesa per selezionare le funzionalità di interesse qui di seguito e identificare le prestazioni del modello sulle coorti sottostanti.
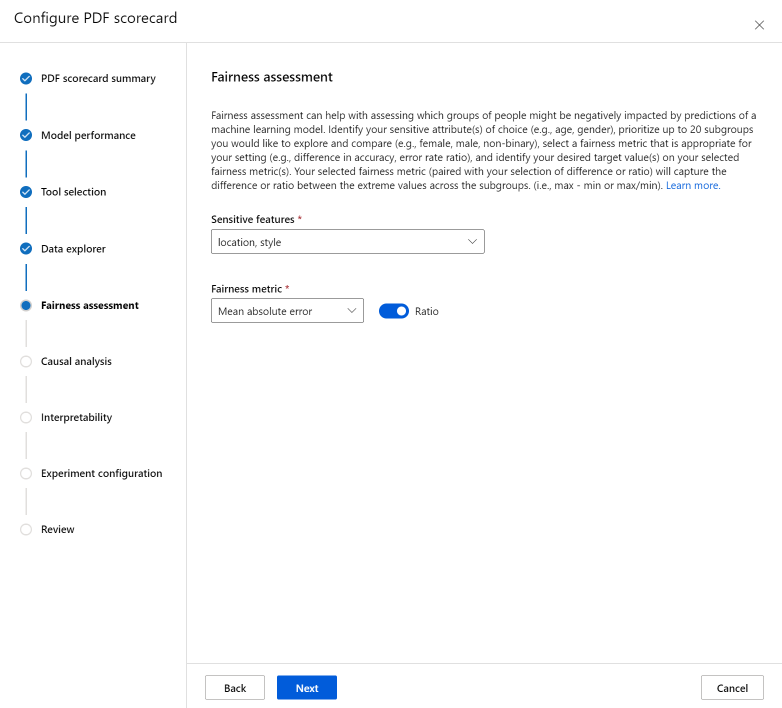
La sezione Valutazione dell'equità può essere utile per valutare quali gruppi di persone potrebbero subire un impatto negativo da parte delle stime di un modello di Machine Learning. In questa sezione sono presenti due campi.
Caratteristiche sensibili: identificare gli attributi sensibili scelti (ad esempio età, sesso) assegnando priorità a un massimo di 20 sottogruppi che si desidera esplorare e confrontare.
Metrica di equità: selezionare una metrica di equità appropriata per l'impostazione (ad esempio la differenza nell'accuratezza, il rapporto di frequenza di errore) e identificare i valori di destinazione desiderati nelle metriche di equità selezionate. La metrica di equità selezionata (abbinata alla selezione della differenza o del rapporto tramite il toggle) acquisirà la differenza o il rapporto tra i valori estremi tra i sottogruppi. (max - min o max/min).
Nota
La valutazione dell'equità è attualmente disponibile solo per attributi sensibili categorici, ad esempio il sesso.
La sezione Analisi causale risponde alle domande "what if" del mondo reale su come i cambiamenti dei trattamenti influirebbero su un risultato reale. Se il componente causale viene attivato nel dashboard di intelligenza artificiale responsabile per cui si sta generando una scorecard, non saranno necessarie altre configurazioni.

La sezione Interpretabilità genera descrizioni comprensibili per le previsioni eseguite dal modello di Machine Learning. Usando le spiegazioni del modello, è possibile comprendere il motivo delle decisioni prese dallo stesso. Selezionare un numero (K) di seguito per visualizzare le funzionalità importanti top-K che influiscono sulle previsioni complessive del modello. Il valore predefinito per K è 10.
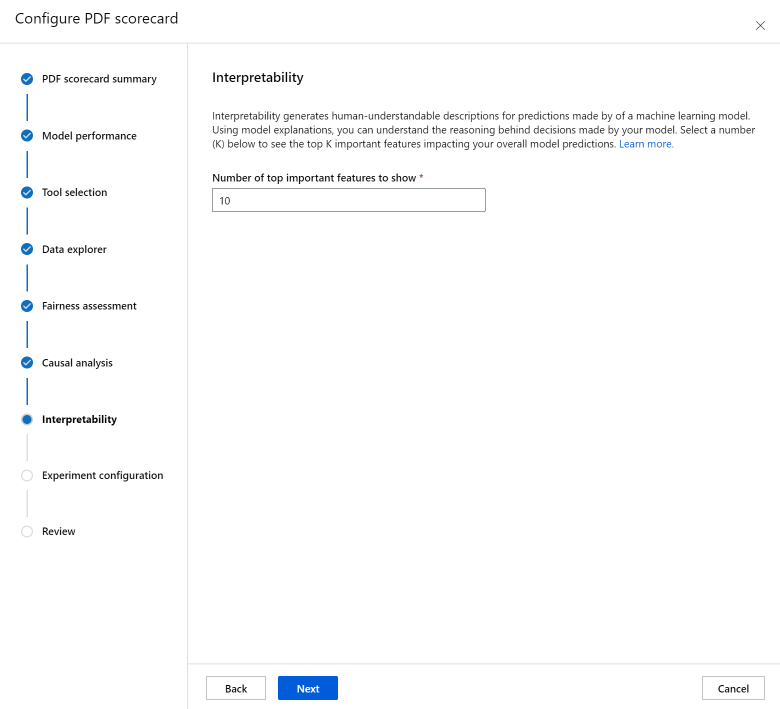
Infine, configurare l'esperimento per avviare un processo per la generazione della scorecard. Queste configurazioni sono uguali a quelle del dashboard di intelligenza artificiale responsabile.
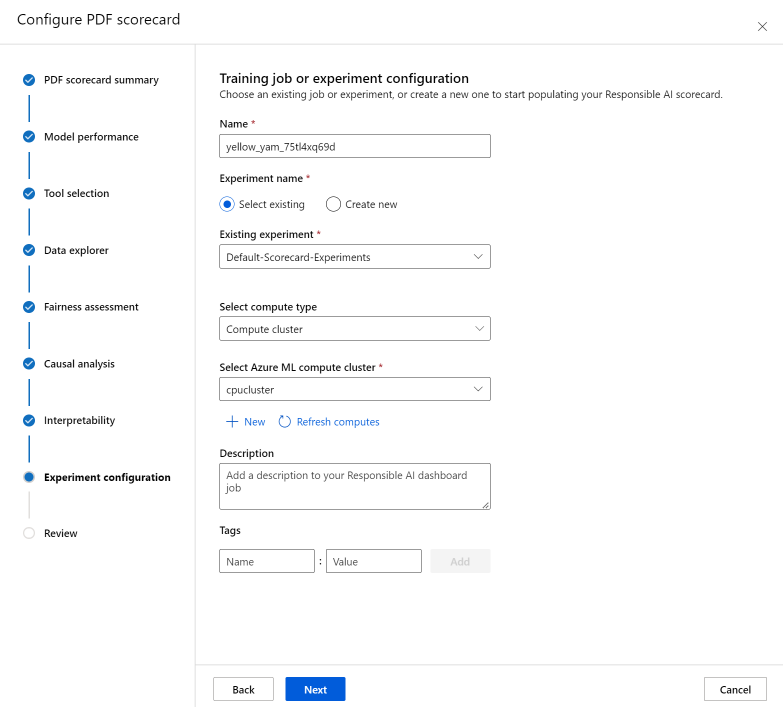
Infine, esaminare le configurazioni e selezionare Crea per avviare il processo!
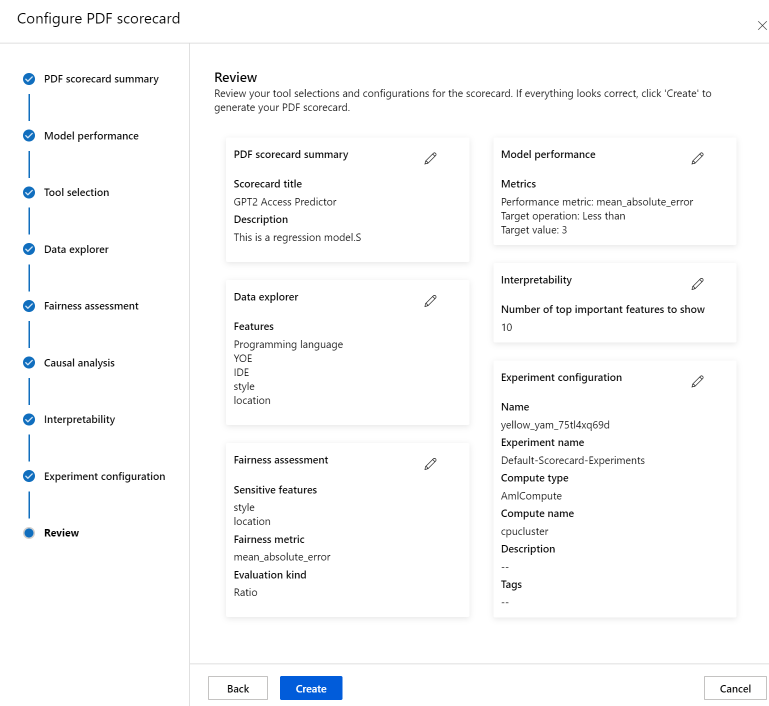
Si verrà reindirizzati alla pagina dell'esperimento per tenere traccia dello stato di avanzamento del processo dopo averlo avviato. Per informazioni su come visualizzare e usare la scorecard di intelligenza artificiale responsabile, vedere Usare la scorecard di intelligenza artificiale responsabile (anteprima).









Passaggi successivi
- Dopo aver generato il dashboard di intelligenza artificiale responsabile, vedere come accedervi e usarlo in Studio di Azure Machine Learning.
- Altre informazioni sui concetti e sulle tecniche dietro il dashboard di intelligenza artificiale responsabile.
- Altre informazioni su come raccogliere i dati in modo responsabile.
- Altre informazioni su come usare la scorecard e il dashboard di intelligenza artificiale responsabile per il debug di dati e modelli di immagine e il miglioramento dei processi decisionali informati sono reperibili in questo post del blog della community tecnica.
- Informazioni su come sono stati usati la dashboard e la scorecard di intelligenza artificiale responsabile dal Servizio sanitario nazionale britannico (NHS) nella vita reale di un cliente.
- Esplorare le funzionalità del dashboard di intelligenza artificiale responsabile tramite questa demo Web interattiva di AI Lab.