Come scegliere gli algoritmi di Azure Machine Learning
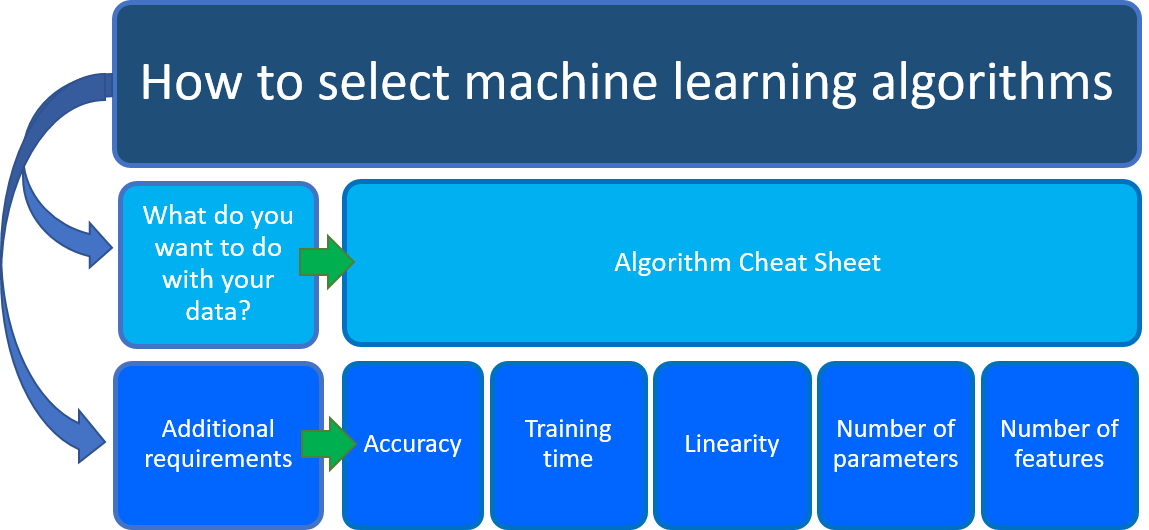
Se non si è certi di quale algoritmo di Machine Learning usare, la risposta dipende principalmente da due aspetti dello scenario di data science:
Cosa si vuole fare con i dati? In particolare, qual è la domanda aziendale a cui si vuole rispondere in base a quanto imparato da dati accumulati in passato?
Quali sono i requisiti dello scenario di data science? Quali sono le caratteristiche, l'accuratezza, il tempo di training, la linearità e i parametri supportati dalla soluzione?
Nota
La finestra di progettazione di Azure Machine Learning supporta due tipi di componenti: componenti predefiniti classici (v1) e componenti personalizzati (v2). Questi due tipi di componenti NON sono compatibili.
I componenti predefiniti classici sono principalmente dedicati all'elaborazione dei dati e alle attività tradizionali di Machine Learning, ad esempio regressione e classificazione. Questo tipo di componente continua a essere supportato, ma non avrà nuove aggiunte future.
I componenti personalizzati consentono di eseguire il wrapping del codice personalizzato come componente. Questi supportano la condivisione di componenti tra aree di lavoro e la creazione senza interruzioni nelle interfacce di Studio, CLI v2 e SDK v2.
Per nuovi progetti, è consigliabile usare componenti personalizzati compatibili con AzureML V2 e continuare a ricevere nuovi aggiornamenti.
Questo articolo si applica ai componenti predefiniti classici e non è compatibile con CLI v2 e SDK v2.
Scheda di riferimento rapido sugli algoritmi di Azure Machine Learning
Il foglio informativo sugli algoritmi di Azure Machine Learning consente di rispondere alla prima domanda: cosa si vuole fare con i dati? Nella scheda di riferimento rapido, cercare l'attività da eseguire, quindi trovare un algoritmo della finestra di progettazione di Azure Machine Learning per la soluzione di analisi predittiva.
Nota
È possibile scaricare foglio informativo sugli algoritmi di Machine Learning.
La finestra di progettazione offre un portfolio completo di algoritmi, ad esempio la Foresta di decisioni multiclasse, i Sistemi di raccomandazione, la Regressione della rete neurale, la Rete neurale multiclassee il Clustering K-Means. Ogni algoritmo è progettato per risolvere un tipo diverso di problema di Machine Learning. Per un elenco completo di informazioni sul funzionamento di ogni algoritmo e su come modificare i parametri per ottimizzare l'algoritmo, vedere leinformazioni di riferimento su algoritmi e componenti.
Oltre a queste indicazioni, tenere presenti altri requisiti nella scelta di un algoritmo di Machine Learning. Di seguito sono riportati altri fattori importanti, come l'accuratezza, il tempo di training, la linearità, il numero di parametri e il numero di caratteristiche.
Confronto tra algoritmi di Machine Learning
Alcuni algoritmi di apprendimento hanno particolari preconcetti sulla struttura dei dati o sui risultati desiderati. Se è possibile trovarne uno adatto alle proprie esigenze, può fornire risultati più utili, previsioni più accurate o tempi di addestramento più rapidi.
La tabella seguente riepiloga alcune delle caratteristiche più importanti degli algoritmi di classificazione, regressione e clustering:
| Algoritmo | Precisione | Tempo di addestramento | Linearità | Parametri | Note |
|---|---|---|---|---|---|
| Gruppo di classificazione | |||||
| Regressione logistica a due classi | Bene | Veloce | Sì | 4 | |
| Foresta delle decisioni a due classi | Eccellente | Moderato | No | 5 | Mostra tempi più lenti per l'assegnazione dei punteggi. Suggeriamo di non usare One-vs-All Multiclass, perché il blocco dei thread nell'accumulo di previsioni dell'albero comporta tempi più lenti per l'assegnazione di punteggi |
| Albero delle decisioni incrementato a due classi | Eccellente | Moderato | No | 6 | Footprint della memoria di grandi dimensioni |
| Rete neurale a due classi | Bene | Moderato | No | 8 | |
| Percettrone medio a due classi | Bene | Moderato | Sì | 4 | |
| Macchina a vettori di supporto a due classi | Bene | Veloce | Sì | 5 | Particolarmente valido per set di funzioni di grandi dimensioni |
| Regressione logistica multiclasse | Bene | Veloce | Sì | 4 | |
| Foresta delle decisioni multiclasse | Eccellente | Moderato | No | 5 | Mostra tempi più lenti per l'assegnazione dei punteggi |
| Albero delle decisioni incrementato multiclasse | Eccellente | Moderato | No | 6 | Tende a migliorare l'accuratezza con un piccolo rischio di minore copertura |
| Rete neurale multiclasse | Bene | Moderato | No | 8 | |
| One-vs-All Multiclass | - | - | - | - | Visualizzare le proprietà del metodo a due classi selezionato |
| Gruppo di regressione | |||||
| Regressione lineare | Bene | Veloce | Sì | 4 | |
| Regressione foresta delle decisioni | Eccellente | Moderato | No | 5 | |
| Regressione albero delle decisioni incrementato | Eccellente | Moderato | No | 6 | Footprint della memoria di grandi dimensioni |
| Regressione rete neurale | Bene | Moderato | No | 8 | |
| Gruppo di clustering | |||||
| Clustering K-means | Eccellente | Moderato | Sì | 8 | Algoritmo di clustering |
Requisiti dello scenario di data science
Una volta definito cosa si vuole fare con i dati, è necessario determinare altri requisiti per lo scenario di data science.
Compiere scelte ed eventualmente trovare compromessi per i requisiti seguenti:
- Accuratezza
- Tempo di addestramento
- Linearità
- Numero di parametri
- Numero di caratteristiche
Accuratezza
L'accuratezza di Machine Learning misura l'efficacia di un modello come percentuale dei risultati effettivi rispetto al numero totale di casi. Nella finestra di progettazione, il componente Valuta modello calcola un set di metriche di valutazione standard del settore. È possibile usare questo componente per misurare l'accuratezza di un modello sottoposto a training.
Ottenere la risposta più precisa possibile non è sempre necessario. Talvolta un'approssimazione è sufficiente, a seconda di ciò per cui si desidera utilizzarla. In tal caso, è possibile ridurre drasticamente il tempo di elaborazione utilizzando più metodi approssimativi. Anche i metodi approssimativi tendono naturalmente ad evitare l'overfitting.
Esistono tre modi per usare il componente Valuta modello:
- Generare i punteggi dei dati di training per valutare il modello.
- Generare i punteggi del modello, ma confrontarli con quelli ottenuti in un set di test riservati.
- Confrontare i punteggi per due modelli diversi ma correlati, usando lo stesso set di dati.
Per un elenco completo delle metriche e degli approcci che è possibile usare per valutare l'accuratezza dei modelli di Machine Learning, vedere il componente Valuta modello.
Tempo di addestramento
Nell'apprendimento supervisionato, il training prevede l'utilizzo di dati storici per creare un modello di Machine Learning che riduca al minimo gli errori. Il numero di minuti o ore necessarie per eseguire l’addestramento di un modello varia notevolmente tra gli algoritmi. Il tempo di training è spesso strettamente correlato all'accuratezza, con cui va di pari passo.
Inoltre, alcuni algoritmi sono più sensibili al numero di punti dati rispetto ad altri. È possibile scegliere un algoritmo specifico per un periodo di tempo limitato, soprattutto con set di dati di grandi dimensioni.
Nella finestra di progettazione, la creazione e l'uso di un modello di Machine Learning costituiscono in genere un processo in tre fasi:
Configurare un modello scegliendo un particolare tipo di algoritmo, quindi definirne parametri o iper-parametri.
Specificare un set di dati etichettato e contenente dati compatibili con l'algoritmo. Connettere sia i dati che il modello al componente Esegui il training del modello .
Al termine del training, usare il modello sottoposto a training con uno dei componenti di assegnazione dei punteggi per eseguire previsioni sui nuovi dati.
Linearità
La linearità, nei campi della statistica e del Machine Learning, indica che esiste una relazione lineare tra una variabile e una costante nel set di dati. Ad esempio, gli algoritmi di classificazione lineare ipotizzano che le classi possano essere separate da una linea retta (o dal suo equivalente della dimensione superiore).
Un numero elevato di algoritmi di Machine Learning utilizza la linearità. Nella finestra di progettazione di Azure Machine Learning, comprendono:
Gli algoritmi di regressione lineare ipotizzano che le tendenze dei dati seguano una linea retta. Questa ipotesi funziona discretamente con alcuni problemi, ma in altri casi compromette l'accuratezza. Nonostante i loro svantaggi, gli algoritmi lineari sono i più richiesti come strategia principale. Tendono ad essere algoritmicamente semplici e rapidi da addestrare.
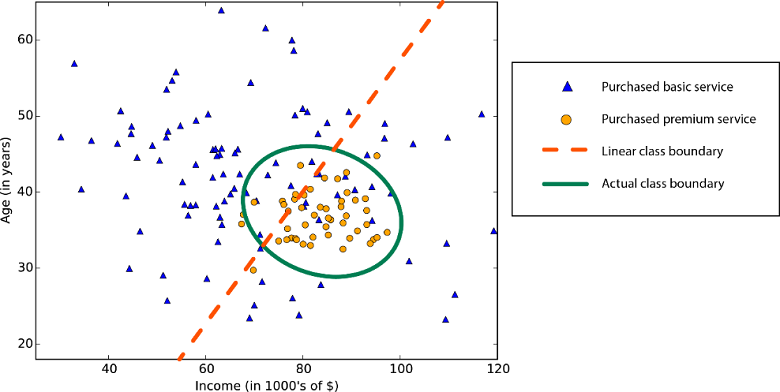
Limite di classe non lineare: basarsi su un algoritmo di classificazione lineare riduce l'accuratezza.
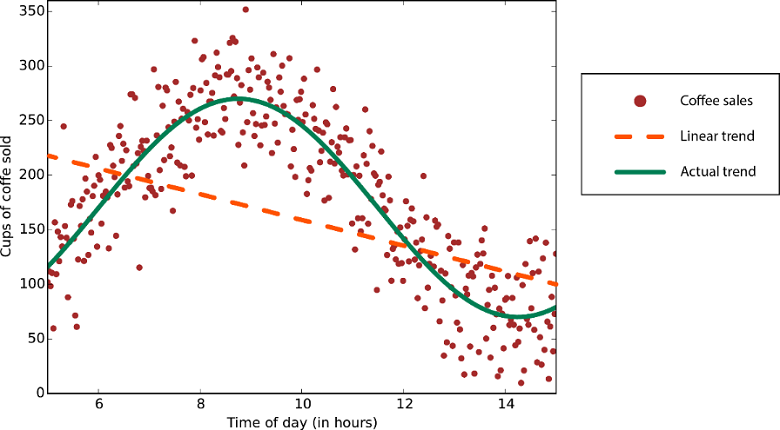
Dati con una tendenza non lineare: l'uso di un metodo di regressione lineare genera errori più grandi del necessario.
Numero di parametri
I parametri sono i pulsanti che uno scienziato dei dati deve utilizzare per configurare un algoritmo. Sono numeri che influiscono sul comportamento dell'algoritmo, ad esempio sulla tolleranza di errori o sul numero di iterazioni, o sulle opzioni tra le varianti del comportamento dell'algoritmo. Il tempo di training e l'accuratezza dell'algoritmo possono talvolta risultare abbastanza cruciali per ottenere le impostazioni corrette. Di solito, gli algoritmi con parametri in numero elevato richiedono molti tentativi ed errori per trovare una combinazione ottimale.
In alternativa, nella finestra di progettazione è presente il componente Ottimizza iperparametri del modello. L'obiettivo di questo componente è determinare gli iperparametri ottimali per un modello di Machine Learning. Il componente compila e testa più modelli usando diverse combinazioni di impostazioni. Inoltre, confronta le metriche di tutti i modelli per ottenere le combinazioni di impostazioni.
Sebbene si tratti di un ottimo modo per assicurarsi di aver utilizzato al massimo lo spazio di parametri, il tempo necessario per eseguire il training di un modello aumenta in misura esponenziale con il numero di parametri. Il vantaggio è un numero elevato di parametri in genere indica che un algoritmo ha maggiore flessibilità. Ammesso che si trovi la giusta combinazione di impostazioni dei parametri, spesso è possibile raggiungere un buon livello di accuratezza.
Numero di caratteristiche
In Machine Learning, una caratteristica è una variabile quantificabile del fenomeno che si sta provando ad analizzare. Per alcuni tipi di dati, il numero di caratteristiche può essere molto grande rispetto al numero di punti dati. Questo accade spesso con i dati testuali o sulla genetica.
L'elevato numero di caratteristiche può rallentare alcuni algoritmi di apprendimento, rendendo il tempo di training esageratamente lungo. Le macchine a vettori di supporto sono adatte a scenari con un numero elevato di caratteristiche. Per questo motivo, sono utilizzate in molte applicazioni, dal recupero di informazioni alla classificazione di testo e immagini. Le macchine a vettori di supporto possono essere utilizzate sia per le attività di classificazione che di regressione.
La selezione delle caratteristiche si riferisce al processo di applicazione di test statistici agli input, in base a un output specifico. L'obiettivo è di determinare quali colonne sono più predittive dell'output. Il componente Selezione caratteristiche basata su filtro nella finestra di progettazione consente di scegliere tra più algoritmi di selezione delle caratteristiche. Il componente include metodi di correlazione come la correlazione di Pearson e i valori chi quadrato.
È anche possibile usare il componente Importanza della caratteristica di permutazione per calcolare un set di punteggi di importanza della caratteristica per il set di dati. È quindi possibile sfruttare questi punteggi per determinare le caratteristiche migliori da usare in un modello.