Condividere modelli, componenti e ambienti tra aree di lavoro con registri
Il Registro di sistema di Azure Machine Learning consente di collaborare tra aree di lavoro all'interno dell'organizzazione. Usando i registri, è possibile condividere modelli, componenti e ambienti.
Esistono due scenari in cui si vuole usare lo stesso set di modelli, componenti e ambienti in più aree di lavoro:
- MLOps tra aree di lavoro: si sta eseguendo il training di un modello in un'area
devdi lavoro ed è necessario distribuirlo nelletestaree di lavoro eprod. In questo caso, si vuole avere una derivazione end-to-end tra gli endpoint in cui il modello viene distribuito intestoprodaree di lavoro e il processo di training, le metriche, il codice, il codice e l'ambiente usati per eseguire il training del modello nell'areadevdi lavoro. - Condividere e riutilizzare modelli e pipeline tra team diversi: la condivisione e il riutilizzo migliorano la collaborazione e la produttività. In questo scenario, è possibile pubblicare un modello sottoposto a training e i componenti e gli ambienti associati usati per eseguirne il training in un catalogo centrale. Da qui, i colleghi di altri team possono cercare e riutilizzare gli asset condivisi nei propri esperimenti.
In questo articolo si apprenderà come:
- Creare un ambiente e un componente nel Registro di sistema.
- Usare il componente dal Registro di sistema per inviare un processo di training del modello in un'area di lavoro.
- Registrare il modello sottoposto a training nel Registro di sistema.
- Distribuire il modello dal Registro di sistema a un endpoint online nell'area di lavoro, quindi inviare una richiesta di inferenza.
Prerequisiti
Prima di seguire la procedura descritta in questo articolo, assicurarsi di disporre dei prerequisiti seguenti:
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
Registro di Azure Machine Learning per condividere modelli, componenti e ambienti. Per creare un registro, vedere Informazioni su come creare un registro.
Un'area di lavoro di Azure Machine Learning. Se non è disponibile, seguire la procedura descritta nell'articolo Avvio rapido: Creare risorse dell'area di lavoro per crearne una.
Importante
L'area di Azure (località) in cui si crea l'area di lavoro deve essere nell'elenco delle aree supportate per il Registro di sistema di Azure Machine Learning
L'interfaccia della riga di comando di Azure e l'estensione
mloppure Python SDK v2 per Azure Machine Learning:Per installare l'interfaccia della riga di comando di Azure e l'estensione, vedere Installare, configurare e usare l'interfaccia della riga di comando di Azure (v2).
Importante
Gli esempi dell'interfaccia della riga di comando in questo articolo presuppongono che si usi la shell Bash (o compatibile). Ad esempio, un sistema Linux o un sottosistema Windows per Linux.
Gli esempi presuppongono anche che siano state configurate le impostazioni predefinite per l'interfaccia della riga di comando di Azure in modo che non sia necessario specificare i parametri per la sottoscrizione, l'area di lavoro, il gruppo di risorse o la posizione. Per impostare le impostazioni predefinite, usare i comandi seguenti. Sostituire i parametri seguenti con i valori per la configurazione:
- Sostituire
<subscription>con l'ID della sottoscrizione di Azure. - Sostituire
<workspace>con il nome dell'area di lavoro di Azure Machine Learning. - Sostituire
<resource-group>con il gruppo di risorse di Azure che contiene l'area di lavoro. - Sostituire
<location>con l'area di Azure che contiene l'area di lavoro.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>È possibile visualizzare le impostazioni predefinite correnti usando il comando
az configure -l.- Sostituire
Clonare il repository di esempi
Gli esempi di codice in questo articolo sono basati sull'esempio nyc_taxi_data_regression nel repository di esempi. Per usare questi file nell'ambiente di sviluppo, usare i comandi seguenti per clonare il repository e modificare le directory nell'esempio:
git clone https://github.com/Azure/azureml-examples
cd azureml-examples
Per l'esempio dell'interfaccia della riga di comando, modificare directory in cli/jobs/pipelines-with-components/nyc_taxi_data_regression nel clone locale del repository di esempi.
cd cli/jobs/pipelines-with-components/nyc_taxi_data_regression
Creare una connessione SDK
Suggerimento
Questo passaggio è necessario solo quando si usa Python SDK.
Creare una connessione client sia all'area di lavoro di Azure Machine Learning che al Registro di sistema:
ml_client_workspace = MLClient( credential=credential,
subscription_id = "<workspace-subscription>",
resource_group_name = "<workspace-resource-group",
workspace_name = "<workspace-name>")
print(ml_client_workspace)
ml_client_registry = MLClient(credential=credential,
registry_name="<REGISTRY_NAME>",
registry_location="<REGISTRY_REGION>")
print(ml_client_registry)
Creare un ambiente nel Registro di sistema
Gli ambienti definiscono il contenitore Docker e le dipendenze Python necessarie per eseguire processi di training o distribuire modelli. Per altre informazioni sugli ambienti, vedere gli articoli seguenti:
- Concetti relativi all'ambiente
- Come creare gli articoli sugli ambienti (INTERFACCIA della riga di comando).
Suggerimento
Lo stesso comando dell'interfaccia della riga di comando az ml environment create può essere usato per creare ambienti in un'area di lavoro o in un registro. L'esecuzione del comando con --workspace-name il comando crea l'ambiente in un'area di lavoro, mentre l'esecuzione del comando con --registry-name crea l'ambiente nel Registro di sistema.
Verrà creato un ambiente che usa l'immagine python:3.8 Docker e installerà i pacchetti Python necessari per eseguire un processo di training usando il framework SciKit Learn. Se è stato clonato il repository di esempi e si trovano nella cartella cli/jobs/pipelines-with-components/nyc_taxi_data_regression, dovrebbe essere possibile visualizzare il file env_train.yml di definizione dell'ambiente che fa riferimento al file env_train/Dockerfiledocker . L'oggetto env_train.yml è illustrato di seguito per il riferimento:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: SKLearnEnv
version: 1
build:
path: ./env_train
Creare l'ambiente usando il come az ml environment create indicato di seguito
az ml environment create --file env_train.yml --registry-name <registry-name>
Se viene visualizzato un errore che indica che un ambiente con questo nome e versione esiste già nel Registro di sistema, è possibile modificare il version campo in env_train.yml o specificare una versione diversa nell'interfaccia della riga di comando che esegue l'override del valore di versione in env_train.yml.
# use shell epoch time as the version
version=$(date +%s)
az ml environment create --file env_train.yml --registry-name <registry-name> --set version=$version
Suggerimento
version=$(date +%s) funziona solo in Linux. Sostituire $version con un numero casuale se non funziona.
Annotare e nameversion dell'ambiente dall'output del az ml environment create comando e usarli con az ml environment show i comandi come indicato di seguito. Sarà necessario e nameversion nella sezione successiva quando si crea un componente nel Registro di sistema.
az ml environment show --name SKLearnEnv --version 1 --registry-name <registry-name>
Suggerimento
Se è stato usato un nome o una versione di ambiente diverso, sostituire i --name parametri e --version di conseguenza.
È anche possibile usare az ml environment list --registry-name <registry-name> per elencare tutti gli ambienti nel Registro di sistema.
È possibile esplorare tutti gli ambienti nel studio di Azure Machine Learning. Assicurarsi di passare all'interfaccia utente globale e cercare la voce Registries (Registri).

Creare un componente nel Registro di sistema
I componenti sono blocchi predefiniti riutilizzabili delle pipeline di Machine Learning in Azure Machine Learning. È possibile creare un pacchetto del codice, del comando, dell'ambiente, dell'interfaccia di input e dell'interfaccia di output di un singolo passaggio della pipeline in un componente. È quindi possibile riutilizzare il componente tra più pipeline senza doversi preoccupare della conversione delle dipendenze e del codice ogni volta che si scrive una pipeline diversa.
La creazione di un componente in un'area di lavoro consente di usare il componente in qualsiasi processo della pipeline all'interno di tale area di lavoro. La creazione di un componente in un registro consente di usare il componente in qualsiasi pipeline in qualsiasi area di lavoro all'interno dell'organizzazione. La creazione di componenti in un registro è un ottimo modo per creare utilità riutilizzabili modulari o attività di training condivise che possono essere usate per la sperimentazione da parte di team diversi all'interno dell'organizzazione.
Per altre informazioni sui componenti, vedere gli articoli seguenti:
Come usare i componenti nelle pipeline (SDK)
Importante
Il Registro di sistema supporta solo gli asset denominati (data/model/component/environment). Se si fa riferimento a un asset in un Registro di sistema, è prima necessario crearlo nel Registro di sistema. In particolare per il caso del componente della pipeline, se si vuole fare riferimento al componente o all'ambiente nel componente della pipeline, è prima necessario creare il componente o l'ambiente nel Registro di sistema.
Assicurarsi di essere nella cartella cli/jobs/pipelines-with-components/nyc_taxi_data_regression. Si troverà il file train.yml di definizione del componente che include uno script train_src/train.py di training scikit Learn e l'ambiente AzureML-sklearn-0.24-ubuntu18.04-py37-cpucurato. Si userà l'ambiente Scikit Learn creato in un passaggio pervioso anziché nell'ambiente curato. È possibile modificare environment il campo in per fare riferimento all'ambiente train.yml Scikit Learn. Il file train.yml di definizione del componente risultante sarà simile all'esempio seguente:
# <component>
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_linear_regression_model
display_name: TrainLinearRegressionModel
version: 1
type: command
inputs:
training_data:
type: uri_folder
test_split_ratio:
type: number
min: 0
max: 1
default: 0.2
outputs:
model_output:
type: mlflow_model
test_data:
type: uri_folder
code: ./train_src
environment: azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1`
command: >-
python train.py
--training_data ${{inputs.training_data}}
--test_data ${{outputs.test_data}}
--model_output ${{outputs.model_output}}
--test_split_ratio ${{inputs.test_split_ratio}}
Se è stato usato un nome o una versione diversa, la rappresentazione più generica è simile alla seguente: environment: azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>, <sklearn-environment-name> quindi assicurarsi di sostituire e <registry-name><sklearn-environment-version> di conseguenza. Eseguire quindi il az ml component create comando per creare il componente come indicato di seguito.
az ml component create --file train.yml --registry-name <registry-name>
Suggerimento
Lo stesso comando dell'interfaccia della riga di comando az ml component create può essere usato per creare componenti in un'area di lavoro o in un registro. L'esecuzione del comando con --workspace-name il comando crea il componente in un'area di lavoro, mentre l'esecuzione del comando con --registry-name crea il componente nel Registro di sistema.
Se si preferisce non modificare train.yml, è possibile eseguire l'override del nome dell'ambiente nell'interfaccia della riga di comando come indicato di seguito:
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1
# or if you used a different name or version, replace `<sklearn-environment-name>` and `<sklearn-environment-version>` accordingly
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>
Suggerimento
Se viene visualizzato un errore che indica che il nome del componente esiste già nel Registro di sistema, è possibile modificare la versione in train.yml o eseguire l'override della versione nell'interfaccia della riga di comando con una versione casuale.
Annotare e nameversion del componente dall'output del az ml component create comando e usarli con az ml component show i comandi come indicato di seguito. Sarà necessario name e version nella sezione successiva quando si crea un processo di training nell'area di lavoro.
az ml component show --name <component_name> --version <component_version> --registry-name <registry-name>
È anche possibile usare az ml component list --registry-name <registry-name> per elencare tutti i componenti nel Registro di sistema.
È possibile esplorare tutti i componenti nel studio di Azure Machine Learning. Assicurarsi di passare all'interfaccia utente globale e cercare la voce Registries (Registri).

Eseguire un processo della pipeline in un'area di lavoro usando un componente dal Registro di sistema
Quando si esegue un processo della pipeline che usa un componente da un registro, le risorse di calcolo e i dati di training sono locali nell'area di lavoro. Per altre informazioni sull'esecuzione di processi, vedere gli articoli seguenti:
- Esecuzione di processi (interfaccia della riga di comando)
- Esecuzione di processi (SDK)
- Processi di pipeline con componenti (interfaccia della riga di comando)
- Processi di pipeline con componenti (SDK)
Verrà eseguito un processo della pipeline con il componente di training Scikit Learn creato nella sezione precedente per eseguire il training di un modello. Verificare che si trovi nella cartella cli/jobs/pipelines-with-components/nyc_taxi_data_regression. Il set di dati di training si trova nella data_transformed cartella . Modificare la component sezione in nella train_job sezione del single-job-pipeline.yml file per fare riferimento al componente di training creato nella sezione precedente. Il risultato single-job-pipeline.yml è illustrato di seguito.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: nyc_taxi_data_regression_single_job
description: Single job pipeline to train regression model based on nyc taxi dataset
jobs:
train_job:
type: command
component: azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
compute: azureml:cpu-cluster
inputs:
training_data:
type: uri_folder
path: ./data_transformed
outputs:
model_output:
type: mlflow_model
test_data:
L'aspetto chiave è che questa pipeline verrà eseguita in un'area di lavoro usando un componente che non si trova nell'area di lavoro specifica. Il componente si trova in un registro che può essere usato con qualsiasi area di lavoro nell'organizzazione. È possibile eseguire questo processo di training in qualsiasi area di lavoro a cui si ha accesso senza doversi preoccupare di rendere disponibile il codice di training e l'ambiente in tale area di lavoro.
Avviso
- Prima di eseguire il processo della pipeline, verificare che l'area di lavoro in cui verrà eseguito il processo si trovi in un'area di Azure supportata dal Registro di sistema in cui è stato creato il componente.
- Verificare che l'area di lavoro abbia un cluster di calcolo con il nome
cpu-clustero modificare ilcomputecampo injobs.train_job.computecon il nome dell'ambiente di calcolo.
Eseguire il processo della pipeline con il az ml job create comando .
az ml job create --file single-job-pipeline.yml
Suggerimento
Se l'area di lavoro predefinita e il gruppo di risorse non sono stati configurati come illustrato nella sezione dei prerequisiti, sarà necessario specificare i --workspace-name parametri e --resource-group per il funzionamento dell'oggetto az ml job create .
In alternativa, ou può ignorare la modifica single-job-pipeline.yml ed eseguire l'override del nome del componente usato dall'interfaccia train_job della riga di comando.
az ml job create --file single-job-pipeline.yml --set jobs.train_job.component=azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
Poiché il componente usato nel processo di training viene condiviso tramite un registro, è possibile inviare il processo a qualsiasi area di lavoro a cui si ha accesso nell'organizzazione, anche in sottoscrizioni diverse. Ad esempio, se si dispone dev-workspacedi e prod-workspacetest-workspace , l'esecuzione del processo di training in queste tre aree di lavoro è semplice quanto l'esecuzione di tre az ml job create comandi.
az ml job create --file single-job-pipeline.yml --workspace-name dev-workspace --resource-group <resource-group-of-dev-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name test-workspace --resource-group <resource-group-of-test-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name prod-workspace --resource-group <resource-group-of-prod-workspace>
In studio di Azure Machine Learning selezionare il collegamento all'endpoint nell'output del processo per visualizzare il processo. Qui è possibile analizzare le metriche di training, verificare che il processo usi il componente e l'ambiente dal Registro di sistema ed esaminare il modello sottoposto a training. Annotare l'oggetto name del processo dall'output o trovare le stesse informazioni della panoramica del processo in studio di Azure Machine Learning. Queste informazioni saranno necessarie per scaricare il modello sottoposto a training nella sezione successiva sulla creazione di modelli nel Registro di sistema.

Creare un modello nel Registro di sistema
Si apprenderà come creare modelli in un registro in questa sezione. Vedere Gestire i modelli per altre informazioni sulla gestione dei modelli in Azure Machine Learning. Verranno esaminati due modi diversi per creare un modello in un registro. Per prima cosa proviene dai file locali. In secondo luogo, consiste nel copiare un modello registrato nell'area di lavoro in un registro.
In entrambe le opzioni si creerà un modello con il formato MLflow, che consentirà di distribuire questo modello per l'inferenza senza scrivere codice di inferenza.
Creare un modello nel Registro di sistema da file locali
Scaricare il modello, disponibile come output di train_job sostituendo <job-name> con il nome del processo dalla sezione precedente. Il modello insieme ai file di metadati MLflow deve essere disponibile in ./artifacts/model/.
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --query [0].name | sed 's/\"//g')
# download the default outputs of the train_job
az ml job download --name $train_job_name
# review the model files
ls -l ./artifacts/model/
Suggerimento
Se l'area di lavoro predefinita e il gruppo di risorse non sono stati configurati come illustrato nella sezione dei prerequisiti, sarà necessario specificare i --workspace-name parametri e --resource-group per il funzionamento dell'oggetto az ml model create .
Avviso
L'output di az ml job list viene passato a sed. Questa operazione funziona solo nelle shell Linux. Se si usa Windows, eseguire az ml job list --parent-job-name <job-name> --query [0].name e rimuovere le virgolette visualizzate nel nome del processo di training.
Se non è possibile scaricare il modello, è possibile trovare il modello MLflow di esempio sottoposto a training dal processo di training nella sezione precedente nella cli/jobs/pipelines-with-components/nyc_taxi_data_regression/artifacts/model/ cartella.
Creare il modello nel Registro di sistema:
# create model in registry
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path ./artifacts/model/ --registry-name <registry-name>
Suggerimento
- Usare un numero casuale per il
versionparametro se viene visualizzato un errore che indica che esiste il nome del modello e la versione. - Lo stesso comando dell'interfaccia della riga di comando
az ml model createpuò essere usato per creare modelli in un'area di lavoro o in un registro. L'esecuzione del comando con--workspace-nameil comando crea il modello in un'area di lavoro, mentre l'esecuzione del comando con--registry-namecrea il modello nel Registro di sistema.
Condividere un modello dall'area di lavoro al Registro di sistema
In questo flusso di lavoro si creerà prima di tutto il modello nell'area di lavoro e quindi lo si condividerà nel Registro di sistema. Questo flusso di lavoro è utile quando si vuole testare il modello nell'area di lavoro prima di condividerlo. Ad esempio, distribuirlo negli endpoint, provare l'inferenza con alcuni dati di test e quindi copiare il modello in un registro se tutto è corretto. Questo flusso di lavoro può essere utile anche quando si sviluppa una serie di modelli che usano tecniche, framework o parametri diversi e si vuole alzare di livello solo uno di essi al Registro di sistema come candidato di produzione.
Assicurarsi di avere il nome del processo della pipeline della sezione precedente e sostituirlo nel comando per recuperare il nome del processo di training riportato di seguito. Si registrerà quindi il modello dall'output del processo di training nell'area di lavoro. Si noti che il --path parametro fa riferimento all'output di output train_job con la azureml://jobs/$train_job_name/outputs/artifacts/paths/model sintassi .
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --workspace-name <workspace-name> --resource-group <workspace-resource-group> --query [0].name | sed 's/\"//g')
# create model in workspace
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path azureml://jobs/$train_job_name/outputs/artifacts/paths/model
Suggerimento
- Usare un numero casuale per il
versionparametro se viene visualizzato un errore che indica che il nome del modello e la versione esistono". - Se l'area di lavoro predefinita e il gruppo di risorse non sono stati configurati come illustrato nella sezione dei prerequisiti, sarà necessario specificare i
--workspace-nameparametri e--resource-groupper il funzionamento dell'oggettoaz ml model create.
Prendere nota del nome e della versione del modello. È possibile verificare se il modello è registrato nell'area di lavoro esplorandolo nell'interfaccia utente di Studio o usando il az ml model show --name nyc-taxi-model --version $model_version comando .
A questo punto si condividerà il modello dall'area di lavoro al Registro di sistema.
# share model registered in workspace to registry
az ml model share --name nyc-taxi-model --version 1 --registry-name <registry-name> --share-with-name <new-name> --share-with-version <new-version>
Suggerimento
- Assicurarsi di usare il nome e la versione del modello corretti se è stato modificato nel
az ml model createcomando . - Il comando precedente ha due parametri facoltativi "--share-with-name" e "--share-with-version". Se non vengono forniti, il nuovo modello avrà lo stesso nome e la stessa versione del modello condiviso.
Annotare e
nameversiondel modello dall'output delaz ml model createcomando e usarli conaz ml model showi comandi come indicato di seguito. Sarà necessario enameversionnella sezione successiva quando si distribuisce il modello in un endpoint online per l'inferenza.
az ml model show --name <model_name> --version <model_version> --registry-name <registry-name>
È anche possibile usare az ml model list --registry-name <registry-name> per elencare tutti i modelli nel Registro di sistema o esplorare tutti i componenti nell'interfaccia utente di studio di Azure Machine Learning. Assicurarsi di passare all'interfaccia utente globale e cercare l'hub Registries.
Lo screenshot seguente mostra un modello in un registro in studio di Azure Machine Learning. Se è stato creato un modello dall'output del processo e quindi copiato il modello dall'area di lavoro al Registro di sistema, si noterà che il modello ha un collegamento al processo che ha eseguito il training del modello. È possibile usare tale collegamento per passare al processo di training per esaminare il codice, l'ambiente e i dati usati per eseguire il training del modello.
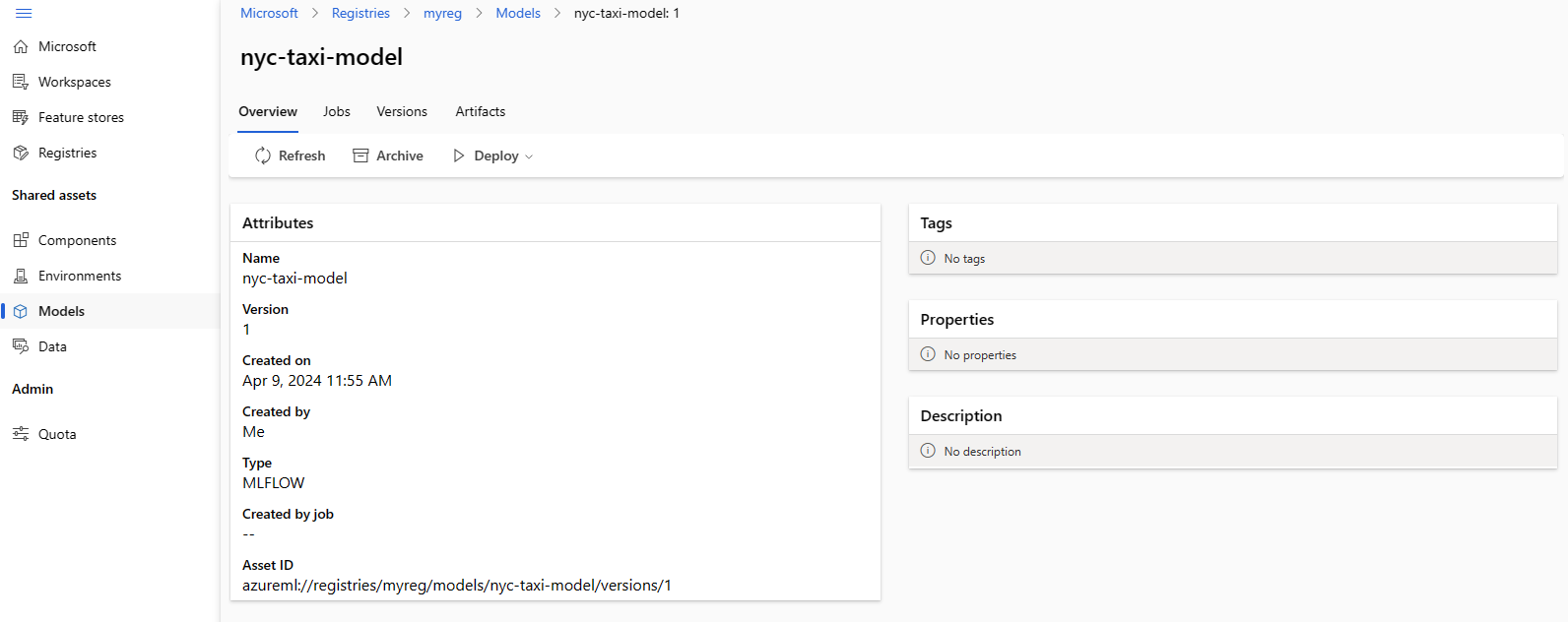
Distribuire il modello dal Registro di sistema all'endpoint online nell'area di lavoro
Nell'ultima sezione si distribuirà un modello dal Registro di sistema a un endpoint online in un'area di lavoro. È possibile scegliere di distribuire qualsiasi area di lavoro a cui si ha accesso nell'organizzazione, purché il percorso dell'area di lavoro sia uno dei percorsi supportati dal Registro di sistema. Questa funzionalità è utile se è stato eseguito il training di un modello in un'area dev di lavoro e ora è necessario distribuire il modello in o prod nell'area di lavoro, mantenendo al tempo stesso le informazioni di derivazione relative al test codice, all'ambiente e ai dati usati per eseguire il training del modello.
Gli endpoint online consentono di distribuire modelli e inviare richieste di inferenza tramite le API REST. Per altre informazioni, vedere Come distribuire e assegnare punteggi a un modello di Machine Learning usando un endpoint online.
Creare un endpoint online.
az ml online-endpoint create --name reg-ep-1234
Aggiornare la model: riga deploy.yml disponibile nella cli/jobs/pipelines-with-components/nyc_taxi_data_regression cartella per fare riferimento al nome e alla versione del modello dal passaggio pervioso. Creare una distribuzione online all'endpoint online. Di deploy.yml seguito è riportato per riferimento.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: demo
endpoint_name: reg-ep-1234
model: azureml://registries/<registry-name>/models/nyc-taxi-model/versions/1
instance_type: Standard_DS2_v2
instance_count: 1
Creare la distribuzione online. La distribuzione richiede alcuni minuti.
az ml online-deployment create --file deploy.yml --all-traffic
Recuperare l'URI di assegnazione dei punteggi e inviare una richiesta di assegnazione dei punteggi di esempio. I dati di esempio per la richiesta di assegnazione dei punteggi sono disponibili nella scoring-data.jsoncli/jobs/pipelines-with-components/nyc_taxi_data_regression cartella .
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n reg-ep-1234 -o tsv --query primaryKey)
SCORING_URI=$(az ml online-endpoint show -n reg-ep-1234 -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @./scoring-data.json
Suggerimento
curlil comando funziona solo in Linux.- Se l'area di lavoro e il gruppo di risorse predefiniti non sono stati configurati come illustrato nella sezione dei prerequisiti, sarà necessario specificare i
--workspace-nameparametri e per il funzionamento deiaz ml online-endpointcomandi e--resource-groupaz ml online-deployment.
Pulire le risorse
Se non si usa la distribuzione, è consigliabile eliminarla per ridurre i costi. Nell'esempio seguente vengono eliminati l'endpoint e tutte le distribuzioni sottostanti:
az ml online-endpoint delete --name reg-ep-1234 --yes --no-wait