Eseguire query e confrontare esperimenti ed esecuzioni con MLflow
È possibile eseguire query su esperimenti e processi (o esecuzioni) in Azure Machine Learning usando MLflow. Non è necessario installare un SDK specifico per gestire ciò che accade all'interno di un processo di training, creando una transizione più semplice tra le esecuzioni locali e il cloud rimuovendo le dipendenze specifiche del cloud. Questo articolo illustra come eseguire query e confrontare esperimenti ed esecuzioni nell'area di lavoro usando Azure Machine Learning e MLflow SDK in Python.
MLflow consente di:
- Creare, eseguire query, eliminare e cercare esperimenti in un'area di lavoro.
- Eseguire query, eliminare e cercare le esecuzioni in un'area di lavoro.
- Tenere traccia e recuperare metriche, parametri, artefatti e modelli da esecuzioni.
Per un confronto dettagliato tra MLflow open source e MLflow quando si è connessi ad Azure Machine Learning, vedere Matrice di supporto per l'esecuzione di query e esperimenti in Azure Machine Learning.
Nota
Azure Machine Learning Python SDK v2 non offre funzionalità di registrazione o rilevamento native. Questo vale non solo per la registrazione, ma anche per l'esecuzione di query sulle metriche registrate. Usare invece MLflow per gestire esperimenti ed esecuzioni. Questo articolo illustra come usare MLflow per gestire esperimenti ed esecuzioni in Azure Machine Learning.
È anche possibile eseguire query ed esperimenti di ricerca usando l'API REST MLflow. Per un esempio su come usarlo, vedere Uso di REST MLflow con Azure Machine Learning .
Prerequisiti
Installare il pacchetto
mlflowdi MLflow SDK e il plug-in di Azure Machine Learning per MLflowazureml-mlflow.pip install mlflow azureml-mlflowSuggerimento
È possibile usare il pacchetto
mlflow-skinny, che è un pacchetto di MLflow leggero senza risorse di archiviazione SQL, server, interfaccia utente o dipendenze di data science.mlflow-skinnyè consigliabile per gli utenti che necessitano principalmente delle funzionalità di rilevamento e registrazione di MLflow senza importare il gruppo completo di funzionalità, incluse le distribuzioni.Un'area di lavoro di Azure Machine Learning. È possibile crearne una seguendo l'esercitazione Creare risorse di Machine Learning.
Se si esegue il rilevamento remoto, ovvero si monitorano esperimenti in esecuzione all'esterno di Azure Machine Learning, configurare MLflow in modo che punti all'URI di rilevamento dell'area di lavoro di Azure Machine Learning. Per altre informazioni su come connettere MLflow all'area di lavoro, vedere Configurare MLflow per Azure Machine Learning.
Eseguire query ed esperimenti di ricerca
Usare MLflow per cercare esperimenti all'interno dell'area di lavoro. Vedere gli esempi seguenti:
Ottenere tutti gli esperimenti attivi:
mlflow.search_experiments()Nota
Nelle versioni legacy di MLflow (<2.0), usare invece il metodo
mlflow.list_experiments().Ottenere tutti gli esperimenti, inclusi quelli archiviati:
from mlflow.entities import ViewType mlflow.search_experiments(view_type=ViewType.ALL)Ottenere un esperimento specifico in base al nome:
mlflow.get_experiment_by_name(experiment_name)Ottenere un esperimento specifico in base all'ID:
mlflow.get_experiment('1234-5678-90AB-CDEFG')
Esperimenti di ricerca
Il search_experiments() metodo, disponibile a partire da Mlflow 2.0, consente di cercare esperimenti che soddisfano i criteri usando filter_string.
Recuperare più esperimenti in base ai relativi ID:
mlflow.search_experiments(filter_string="experiment_id IN (" "'CDEFG-1234-5678-90AB', '1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')" )Recuperare tutti gli esperimenti creati dopo un determinato periodo di tempo:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_experiments(filter_string=f"creation_time > {int(dt.timestamp())}")Recuperare tutti gli esperimenti con un tag specificato:
mlflow.search_experiments(filter_string=f"tags.framework = 'torch'")
Query e esecuzioni di ricerca
MLflow consente di cercare le esecuzioni all'interno di qualsiasi esperimento, inclusi più esperimenti contemporaneamente. Il metodo mlflow.search_runs() accetta l'argomento experiment_ids e experiment_name per indicare gli esperimenti da cercare. È anche possibile indicare search_all_experiments=True se si vuole eseguire ricerche in tutti gli esperimenti nell'area di lavoro:
In base al nome dell'esperimento:
mlflow.search_runs(experiment_names=[ "my_experiment" ])Per ID esperimento:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ])Eseguire ricerche in tutti gli esperimenti nell'area di lavoro:
mlflow.search_runs(filter_string="params.num_boost_round='100'", search_all_experiments=True)
Si noti che experiment_ids supporta la fornitura di una matrice di esperimenti, in modo da poter eseguire ricerche in più esperimenti, se necessario. Questo può essere utile nel caso in cui si voglia confrontare le esecuzioni dello stesso modello quando viene registrato in esperimenti diversi( ad esempio, da persone diverse o iterazioni di progetto diverse).
Importante
Se experiment_ids, experiment_nameso search_all_experiments non sono specificati, MLflow cerca per impostazione predefinita nell'esperimento attivo corrente. È possibile impostare l'esperimento attivo usando mlflow.set_experiment().
Per impostazione predefinita, MLflow restituisce i dati in formato Pandas, utile quando si esegue un'ulteriore elaborazione dell'analisi delle esecuzioni Dataframe . I dati restituiti includono colonne con:
- Informazioni di base sull'esecuzione.
- Parametri con il nome
params.<parameter-name>della colonna . - Metriche (ultimo valore registrato di ogni) con il nome
metrics.<metric-name>della colonna .
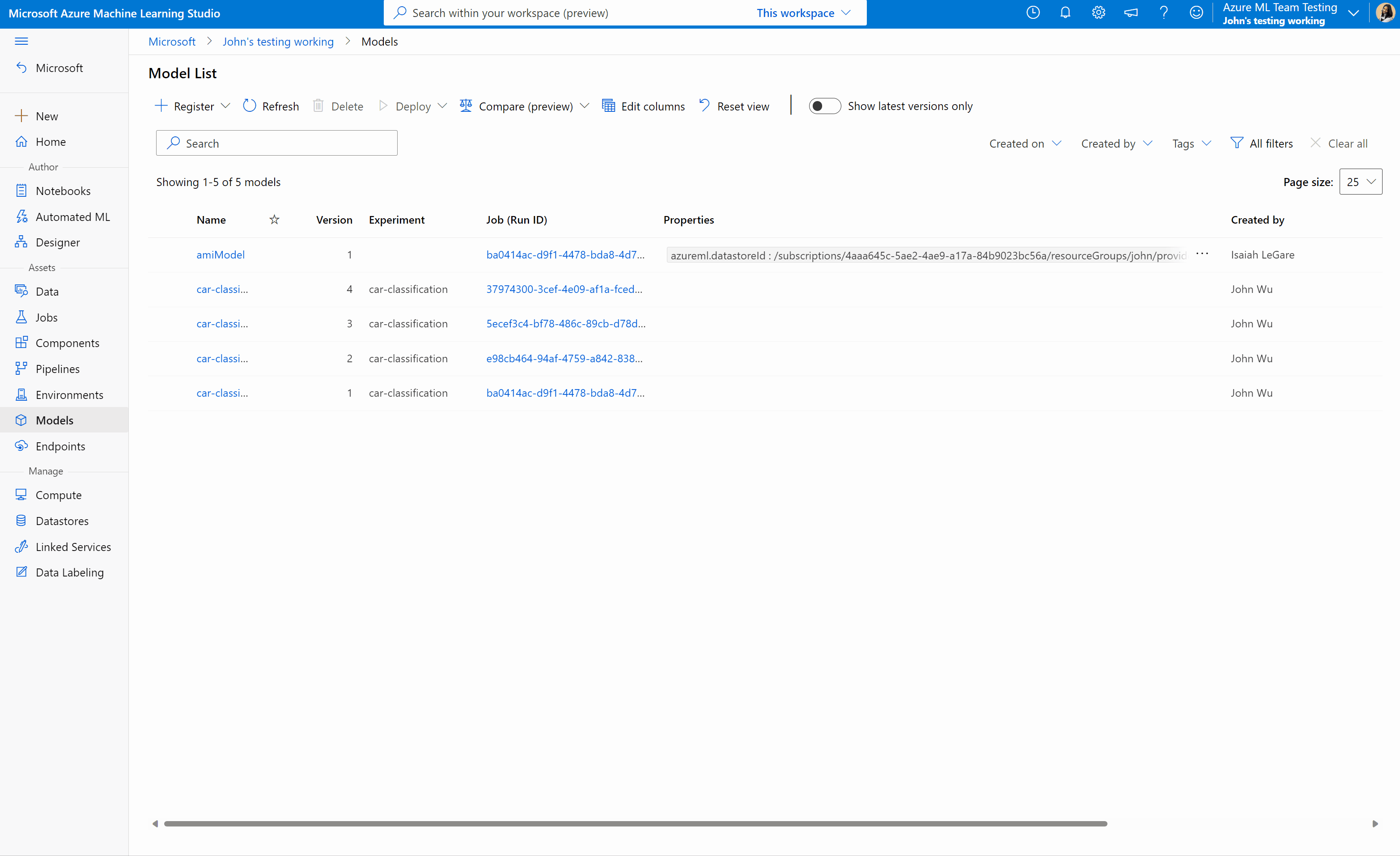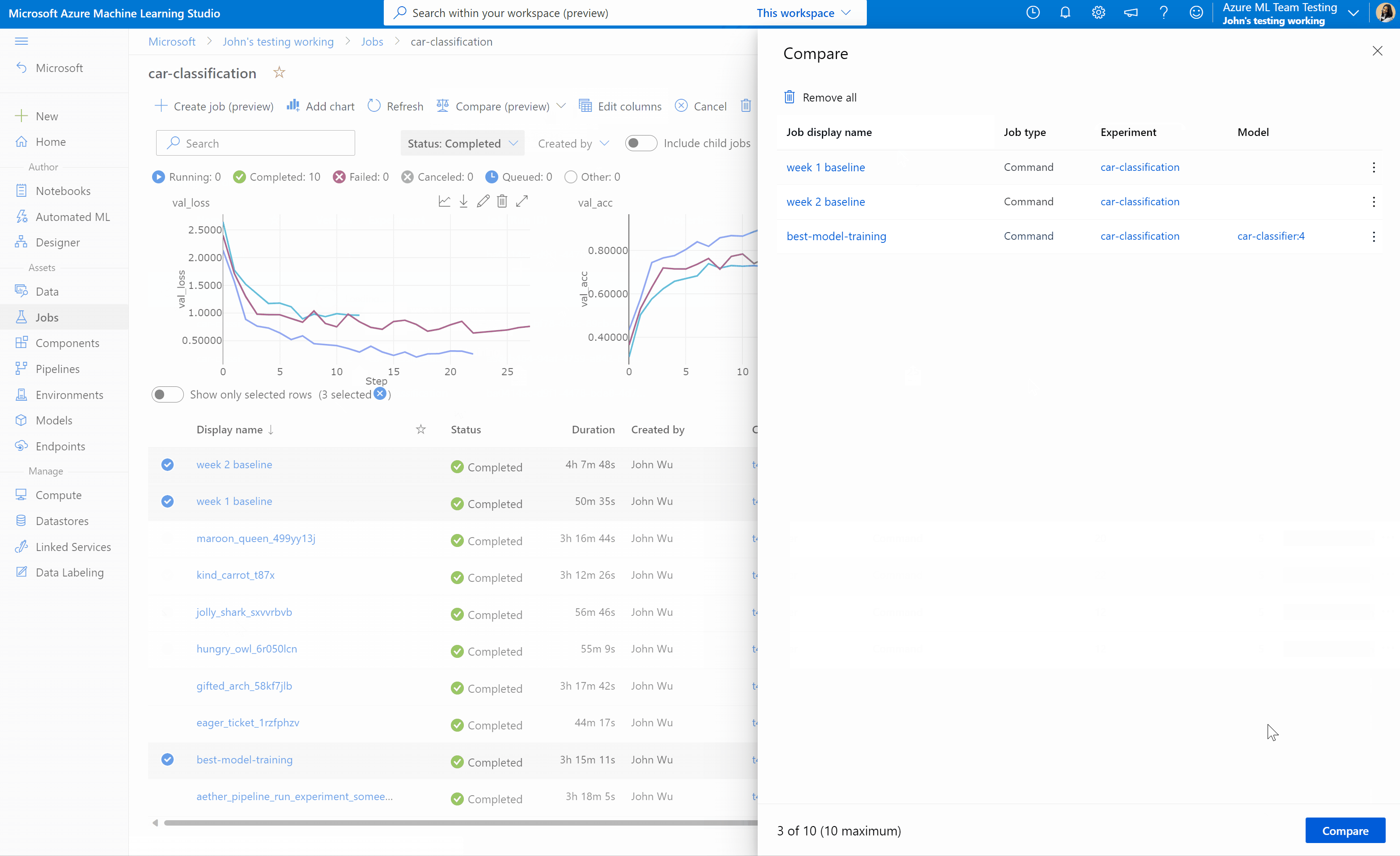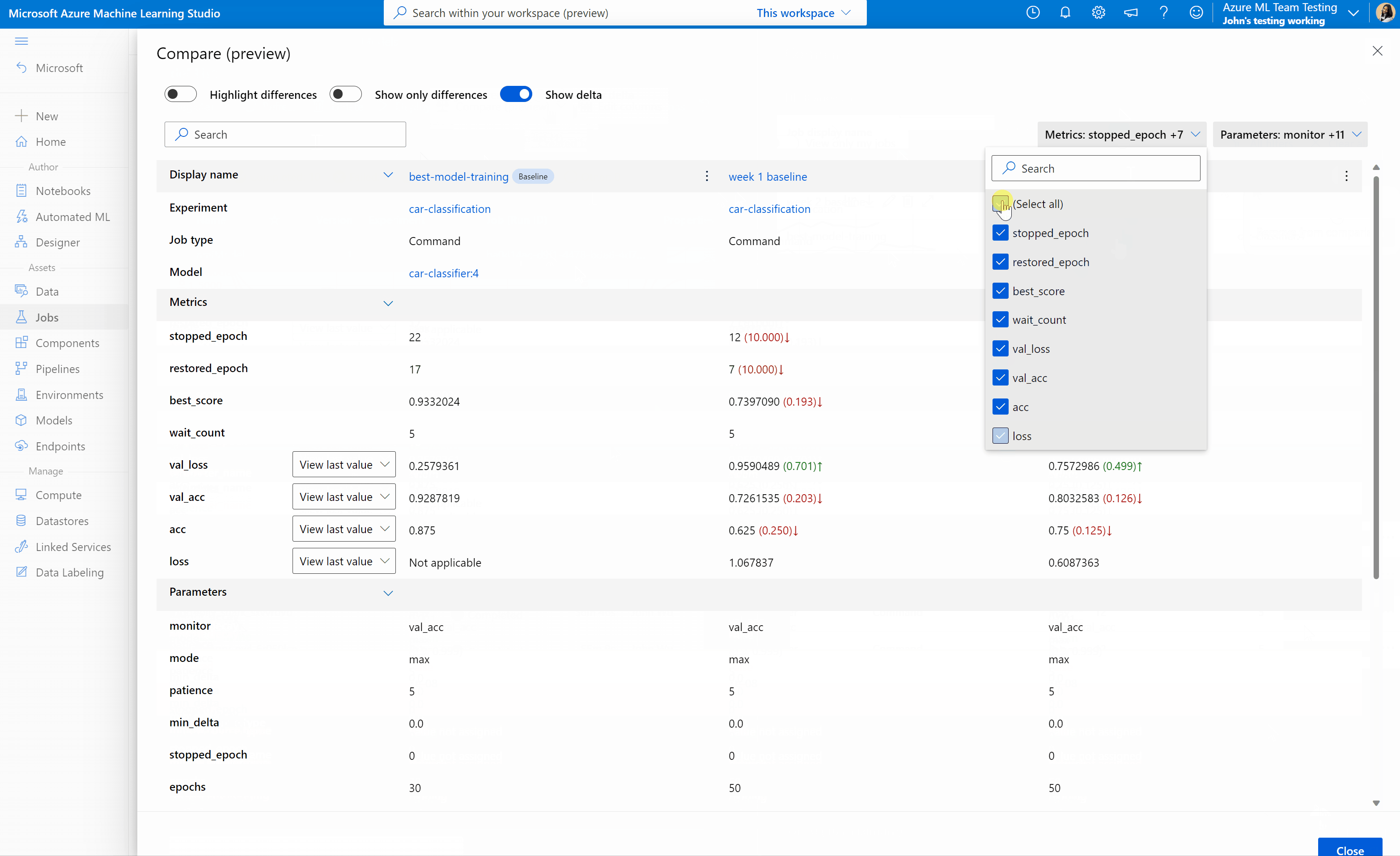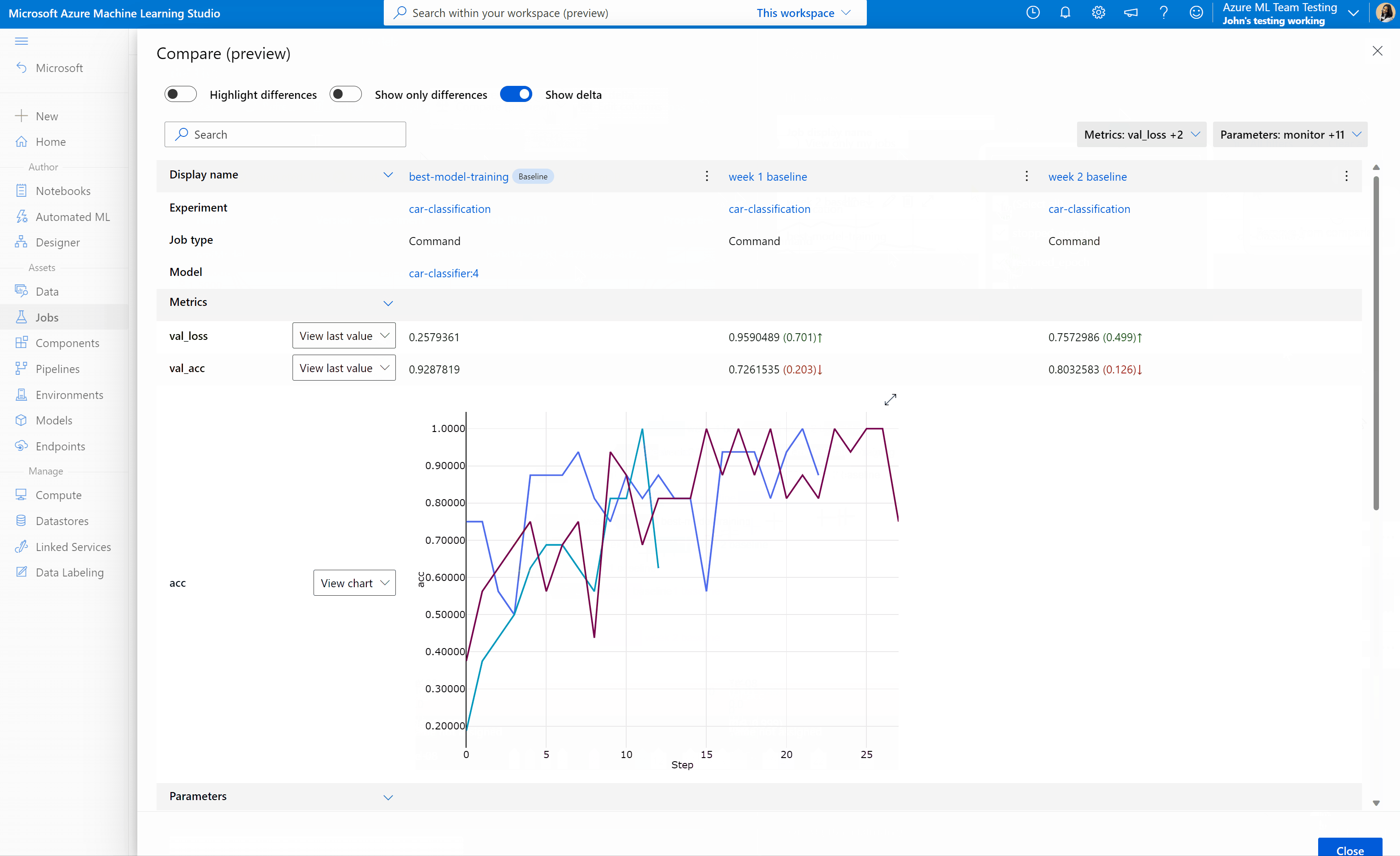
Tutte le metriche e i parametri vengono restituiti anche durante l'esecuzione di query. Tuttavia, per le metriche che contengono più valori (ad esempio, una curva di perdita o una curva pull), viene restituito solo l'ultimo valore della metrica. Se si desidera recuperare tutti i valori di una determinata metrica, usa il mlflow.get_metric_history metodo . Per un esempio, vedere Recupero di parametri e metriche da un'esecuzione .
Ordina esecuzioni
Per impostazione predefinita, gli esperimenti sono in ordine decrescente per start_time, ovvero l'ora in cui l'esperimento è stato accodato in Azure Machine Learning. Si può tuttavia possibile modificare questa impostazione predefinita usando il parametro order_by.
Ordinare le esecuzioni in base agli attributi, ad esempio
start_time:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.start_time DESC"])Ordina le esecuzioni e limita i risultati. Nell'esempio seguente viene restituita l'ultima esecuzione singola dell'esperimento:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["attributes.start_time DESC"])L'ordine viene eseguito dall'attributo
duration:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.duration DESC"])Suggerimento
attributes.durationnon è presente in MLflow OSS, ma viene fornito in Azure Machine Learning per praticità.L'ordine viene eseguito in base ai valori della metrica:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ]).sort_values("metrics.accuracy", ascending=False)Avviso
L'uso di
order_bycon espressioni contenentimetrics.*,params.*otags.*nel parametroorder_bynon è attualmente supportato. Usare invece ilorder_valuesmetodo di Pandas come illustrato nell'esempio.
Esecuzioni di filtri
È anche possibile cercare un'esecuzione con una combinazione specifica negli iperparametri usando il parametro filter_string. Usare params per accedere ai parametri dell'esecuzione, metrics per accedere alle metriche registrate nell'esecuzione e attributes per accedere ai dettagli delle informazioni sull'esecuzione. MLflow supporta le espressioni unite dalla parola chiave AND (la sintassi non supporta OR):
La ricerca viene eseguita in base al valore di un parametro:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="params.num_boost_round='100'")Avviso
Solo gli operatori
=,likee!=sono supportati per filtrareparameters.La ricerca viene eseguita in base al valore di una metrica:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="metrics.auc>0.8")La ricerca viene eseguita con un tag specificato:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="tags.framework='torch'")Le esecuzioni di ricerca create da un determinato utente:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.user_id = 'John Smith'")Le esecuzioni di ricerca non sono riuscite. Per i valori possibili, vedere Filtrare le esecuzioni in base allo stato :
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.status = 'Failed'")Le esecuzioni di ricerca vengono create dopo un determinato periodo di tempo:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.creation_time > '{int(dt.timestamp())}'")Suggerimento
Per la chiave
attributes, i valori devono essere sempre stringhe e quindi codificati tra virgolette.Esecuzioni di ricerca che richiedono più di un'ora:
duration = 360 * 1000 # duration is in milliseconds mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.duration > '{duration}'")Suggerimento
attributes.durationnon è presente in MLflow OSS, ma viene fornito in Azure Machine Learning per praticità.Le esecuzioni di ricerca con l'ID in un determinato set:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.run_id IN ('1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')")
Filtra le esecuzioni in base allo stato
Quando si filtrano le esecuzioni in base allo stato, MLflow usa una convenzione diversa per assegnare un nome al diverso stato possibile di un'esecuzione rispetto ad Azure Machine Learning. La tabella seguente illustra i valori possibili:
| Stato del processo di Azure Machine Learning | MLFlow attributes.status |
Significato |
|---|---|---|
| Non avviato | Scheduled |
Il processo/esecuzione è stato ricevuto da Azure Machine Learning. |
| Queue | Scheduled |
Il processo/esecuzione è pianificato per l'esecuzione, ma non è ancora stato avviato. |
| Preparazione | Scheduled |
Il processo/esecuzione non è ancora stato avviato, ma un calcolo è stato allocato per l'esecuzione e sta preparando l'ambiente e i relativi input. |
| In esecuzione | Running |
Il processo/esecuzione è attualmente in esecuzione attiva. |
| Completato | Finished |
Il processo/esecuzione è stato completato senza errori. |
| Non riuscito | Failed |
Il processo/esecuzione è stato completato con errori. |
| Annullati | Killed |
Il processo/esecuzione è stato annullato dall'utente o terminato dal sistema. |
Esempio:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="attributes.status = 'Failed'")
Ottenere metriche, parametri, artefatti e modelli
Il metodo search_runs restituisce un pandas Dataframe che contiene una quantità limitata di informazioni per impostazione predefinita. Se necessario, è possibile ottenere oggetti Python, che potrebbero essere utili per ottenere dettagli su di essi. Usare il parametro per controllare la output_format modalità di restituzione dell'output:
runs = mlflow.search_runs(
experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="params.num_boost_round='100'",
output_format="list",
)
È quindi possibile accedere ai dettagli dal info membro. L'esempio seguente illustra come ottenere :run_id
last_run = runs[-1]
print("Last run ID:", last_run.info.run_id)
Ottenere parametri e metriche da un'esecuzione
Quando vengono restituite esecuzioni usando output_format="list", è possibile accedere facilmente ai parametri usando la chiave data:
last_run.data.params
Allo stesso modo, è possibile eseguire query sulle metriche:
last_run.data.metrics
Per le metriche che contengono più valori ( ad esempio, una curva di perdita o una curva pull), viene restituito solo l'ultimo valore registrato della metrica. Se si desidera recuperare tutti i valori di una determinata metrica, usa il mlflow.get_metric_history metodo . Questo metodo richiede l'uso di MlflowClient:
client = mlflow.tracking.MlflowClient()
client.get_metric_history("1234-5678-90AB-CDEFG", "log_loss")
Ottenere elementi da un'esecuzione
MLflow può eseguire query su qualsiasi artefatto registrato da un'esecuzione. Non è possibile accedere agli artefatti usando l'oggetto run stesso e il client MLflow deve essere invece usato:
client = mlflow.tracking.MlflowClient()
client.list_artifacts("1234-5678-90AB-CDEFG")
Il metodo precedente elenca tutti gli artefatti registrati nell'esecuzione, ma rimangono archiviati nell'archivio artefatti (archiviazione di Azure Machine Learning). Per scaricarli, usare il metodo download_artifact:
file_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path="feature_importance_weight.png"
)
Nota
Nelle versioni legacy di MLflow (<2.0), usare invece il metodo MlflowClient.download_artifacts() .
Ottenere modelli da un'esecuzione
I modelli possono anche essere registrati nell'esecuzione e quindi recuperati direttamente da esso. Per recuperare un modello, è necessario conoscere il percorso dell'artefatto in cui è archiviato. Il metodo list_artifacts può essere usato per trovare elementi che rappresentano un modello poiché i modelli MLflow sono sempre cartelle. È possibile scaricare un modello specificando il percorso in cui è archiviato il modello usando il download_artifact metodo :
artifact_path="classifier"
model_local_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path=artifact_path
)
È quindi possibile caricare di nuovo il modello dagli artefatti scaricati usando la funzione load_model tipica nello spazio dei nomi specifico del gusto. Nell'esempio seguente viene usato xgboost:
model = mlflow.xgboost.load_model(model_local_path)
MLflow consente anche di eseguire entrambe le operazioni contemporaneamente e di scaricare e caricare il modello in un'unica istruzione. MLflow scarica il modello in una cartella temporanea e lo carica da questa posizione. Il metodo load_model usa un formato URI per indicare da dove deve essere recuperato il modello. Nel caso di caricamento di un modello da un'esecuzione, la struttura URI è la seguente:
model = mlflow.xgboost.load_model(f"runs:/{last_run.info.run_id}/{artifact_path}")
Suggerimento
Per eseguire query e caricare modelli registrati nel Registro modelli, vedere Gestire i registri dei modelli in Azure Machine Learning con MLflow.
Ottenere esecuzioni figlio (annidate)
MLflow supporta il concetto di esecuzioni figlio (annidate). Queste esecuzioni sono utili quando è necessario avviare routine di training che devono essere monitorate indipendentemente dal processo di training principale. I processi di ottimizzazione degli iperparametri o le pipeline di Azure Machine Learning sono esempi tipici di processi che generano più esecuzioni figlio. È possibile eseguire una query su tutte le esecuzioni figlio di un'esecuzione specifica usando il tag mlflow.parentRunIddi proprietà , che contiene l'ID esecuzione dell'esecuzione padre.
hyperopt_run = mlflow.last_active_run()
child_runs = mlflow.search_runs(
filter_string=f"tags.mlflow.parentRunId='{hyperopt_run.info.run_id}'"
)
Confrontare processi e modelli in studio di Azure Machine Learning (anteprima)
Per confrontare e valutare la qualità dei processi e dei modelli in studio di Azure Machine Learning, usare il pannello di anteprima per abilitare la funzionalità. Dopo l'abilitazione, è possibile confrontare i parametri, le metriche e i tag tra i processi e/o i modelli selezionati.
Importante
Gli elementi contrassegnati come (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. La versione di anteprima viene messa a disposizione senza contratto di servizio e non è consigliata per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
In MLflow con notebook di Azure Machine Learning vengono illustrati e ampliati i concetti presentati in questo articolo.
- Eseguire il training e tenere traccia di un classificatore con MLflow: illustra come tenere traccia degli esperimenti usando MLflow, i modelli di log e combinare più versioni in pipeline.
- Gestire esperimenti ed esecuzioni con MLflow: illustra come eseguire query su esperimenti, esecuzioni, metriche, parametri e artefatti di Azure Machine Learning usando MLflow.
Matrice di supporto per l'esecuzione di query e esperimenti
MLflow SDK espone diversi metodi per recuperare le esecuzioni, incluse le opzioni per controllare cosa viene restituito e come. Usare la tabella seguente per informazioni su quali di questi metodi sono attualmente supportati in MLflow quando si è connessi ad Azure Machine Learning:
| Funzionalità | Supportato da MLflow | Supportato da Azure Machine Learning |
|---|---|---|
| Ordinamento delle esecuzioni in base agli attributi | ✓ | ✓ |
| Ordinamento delle esecuzioni in base alle metriche | ✓ | 1 |
| Ordinamento delle esecuzioni in base ai parametri | ✓ | 1 |
| Ordinamento delle esecuzioni in base ai tag | ✓ | 1 |
| Filtro delle esecuzioni in base agli attributi | ✓ | ✓ |
| Filtro delle esecuzioni in base alle metriche | ✓ | ✓ |
| Filtro delle esecuzioni in base alle metriche con caratteri speciali (preceduti da escape) | ✓ | |
| Filtro delle esecuzioni in base ai parametri | ✓ | ✓ |
| Filtro delle esecuzioni in base ai tag | ✓ | ✓ |
Il filtro viene eseguito con comparatori numerici (metriche), tra cui =, !=>, >=, <, e<= |
✓ | ✓ |
Il filtro viene eseguito con i comparatori di stringhe (parametri, tag e attributi): = e != |
✓ | ✓2 |
Il filtro viene eseguito con i comparatori di stringhe (parametri, tag e attributi): LIKE/ILIKE |
✓ | ✓ |
Filtro delle esecuzioni con comparatori AND |
✓ | ✓ |
Filtro delle esecuzioni con comparatori OR |
||
| Ridenominazione degli esperimenti | ✓ |
Nota
- 1 Controllare la sezione Ordinamento delle esecuzioni per istruzioni ed esempi su come ottenere la stessa funzionalità in Azure Machine Learning.
- 2
!=per i tag non supportati.
Contenuto correlato
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per