Risolvere i problemi relativi alle risorse di calcolo Kubernetes
Questo articolo illustra come risolvere gli errori comuni del carico di lavoro nell'ambiente di calcolo Kubernetes. Gli errori comuni includono i processi di training e gli errori degli endpoint.
Guida di inferenza
Gli errori comuni degli endpoint Kubernetes nel calcolo Kubernetes sono suddivisi in due ambiti: ambito di calcolo e ambito cluster. Gli errori dell'ambito di calcolo sono correlati alla destinazione di calcolo, ad esempio la destinazione di calcolo non viene trovata o la destinazione di calcolo non è accessibile. Gli errori di ambito del cluster sono correlati al cluster Kubernetes sottostante, ad esempio il cluster stesso non è raggiungibile o il cluster non viene trovato.
Errori di calcolo di Kubernetes
Di seguito sono riportati i tipi di errore comuni nell'ambito di calcolo che possono verificarsi quando si usa il calcolo Kubernetes per creare endpoint online e distribuzioni online per l'inferenza del modello in tempo reale. Puoi risolvere i problemi seguendo le sezioni collegate per le linee guida:
- ERROR: GenericComputeError
- ERROR: ComputeNotFound
- ERROR: ComputeNotAccessible
- ERRORE: InvalidComputeInformation
- ERRORE: InvalidComputeNoKubernetesConfiguration
ERROR: GenericComputeError
Il messaggio di errore è il seguente:
Failed to get compute information.
Questo errore si verifica quando il sistema non riesce a ottenere le informazioni di calcolo dal cluster Kubernetes. È possibile controllare gli elementi seguenti per risolvere il problema:
- Controllare lo stato del cluster Kubernetes. Se il cluster non è in esecuzione, è prima necessario avviare il cluster.
- Controllare l’integrità del cluster Kubernetes.
- È possibile visualizzare il report di controllo dell'integrità del cluster per eventuali problemi, ad esempio se il cluster non è raggiungibile.
- È possibile passare al portale dell'area di lavoro per controllare lo stato di calcolo.
- Controllare se i tipi di istanza sono informazioni corrette. È possibile controllare i tipi di istanza supportati nella documentazione di Calcolo kubernetes.
- Provare a scollegare e ricollegare il calcolo all'area di lavoro, se applicabile.
Nota
Per risolvere gli errori mediante lo scollegamento, assicurarsi di rieseguire il collegamento con la stessa configurazione dell'ambiente di calcolo scollegato in precedenza, ad esempio lo stesso nome dell'ambiente di calcolo e lo stesso spazio dei nomi. In caso contrario, potrebbero verificarsi altri errori.
ERROR: ComputeNotFound
Di seguito è riportato il messaggio di errore:
Cannot find Kubernetes compute.
Questo errore si verifica quando:
- Il sistema non riesce a trovare il calcolo quando si crea/aggiorna un nuovo endpoint/una nuova distribuzione online.
- Il calcolo di endpoint/distribuzioni online esistenti è stato rimosso.
È possibile controllare gli elementi seguenti per risolvere il problema:
- Provare a ricreare l'endpoint e la distribuzione.
- Provare a scollegare e ricollegare il calcolo all'area di lavoro. Prestare attenzione a più note su ricollegare.
ERROR: ComputeNotAccessible
Di seguito è riportato il messaggio di errore:
The Kubernetes compute is not accessible.
Questo errore deve verificarsi quando l'identità gestita dell'area di lavoro non ha accesso al cluster del servizio Azure Kubernetes. È possibile verificare se l'identità del servizio gestito dell'area di lavoro ha accesso al servizio Azure Kubernetes e, in caso contrario, è possibile seguire questo documento per gestire l'accesso e l'identità.
ERRORE: InvalidComputeInformation
Di seguito è riportato il messaggio di errore:
The compute information is invalid.
È disponibile un processo di convalida della destinazione di calcolo durante la distribuzione di modelli nel cluster Kubernetes. Questo errore deve verificarsi quando le informazioni di calcolo non sono valide. Ad esempio, la destinazione di calcolo non viene trovata o la configurazione dell'estensione Azure Machine Learning è stata aggiornata nel cluster Kubernetes.
È possibile controllare gli elementi seguenti per risolvere il problema:
- Controllare se la destinazione di calcolo usata è corretta ed esistente nell'area di lavoro.
- Provare a scollegare e ricollegare il calcolo all'area di lavoro. Prestare attenzione a più note su ricollegare.
ERRORE: InvalidComputeNoKubernetesConfiguration
Di seguito è riportato il messaggio di errore:
The compute kubeconfig is invalid.
Questo errore dovrebbe verificarsi quando il sistema non riesce a trovare alcuna configurazione per la connessione al cluster, ad esempio:
- Per il cluster Arc-Kubernetes, non è disponibile alcuna configurazione di Inoltro di Azure.
- Per il cluster del servizio Azure Kubernetes non è disponibile alcuna configurazione del servizio Azure Kubernetes.
Per ricompilare la configurazione della connessione di calcolo nel cluster, è possibile provare a scollegare e ricollegare il calcolo all'area di lavoro. Prestare attenzione a più note su ricollegare.
Errore del cluster Kubernetes
Di seguito è riportato un elenco di tipi di errori nell'ambito del cluster che possono verificarsi quando si usa il calcolo Kubernetes per creare endpoint online e distribuzioni online per l'inferenza del modello in tempo reale, che è possibile risolvere seguendo le linee guida:
- ERROR: GenericClusterError
- ERROR: ClusterNotReachable
- ERRORE: cluster non trovato
- ERRORE: ClusterServiceNotFound
- ERRORE: ClusterUnauthorized
ERROR: GenericClusterError
Di seguito è riportato il messaggio di errore:
Failed to connect to Kubernetes cluster: <message>
Questo errore dovrebbe verificarsi quando il sistema non è riuscito a connettersi al cluster Kubernetes per un motivo sconosciuto. È possibile controllare gli elementi seguenti per risolvere il problema:
Per i cluster del servizio Azure Kubernetes:
- Controllare se il cluster del servizio Azure Kubernetes è arrestato.
- Se il cluster non è in esecuzione, è prima necessario avviare il cluster.
- Controllare se il cluster del servizio Azure Kubernetes ha abilitato la rete selezionata usando intervalli IP autorizzati.
- Se il cluster del servizio Azure Kubernetes ha abilitato intervalli IP autorizzati, assicurarsi che tutti gli intervalli IP del piano di controllo di Azure Machine Learning siano stati abilitati per il cluster del servizio Azure Kubernetes. Per altre informazioni, vedere questo documento.
Per un cluster del servizio Azure Kubernetes o per un cluster Kubernetes abilitato per Azure Arc:
- Controllare se il server API Kubernetes è accessibile eseguendo
kubectlcomando nel cluster.
ERROR: ClusterNotReachable
Di seguito è riportato il messaggio di errore:
The Kubernetes cluster is not reachable.
Questo errore dovrebbe verificarsi quando il sistema non riesce a connettersi a un cluster. È possibile controllare gli elementi seguenti per risolvere il problema:
Per i cluster del servizio Azure Kubernetes:
- Controllare se il cluster del servizio Azure Kubernetes è arrestato.
- Se il cluster non è in esecuzione, è prima necessario avviare il cluster.
Per un cluster del servizio Azure Kubernetes o per un cluster Kubernetes abilitato per Azure Arc:
- Controllare se il server API Kubernetes è accessibile eseguendo
kubectlcomando nel cluster.
ERRORE: cluster non trovato
Di seguito è riportato il messaggio di errore:
Cannot found Kubernetes cluster.
Questo errore dovrebbe verificarsi quando il sistema non riesce a trovare il cluster servizio Azure Kubernetes/Arc.
È possibile controllare gli elementi seguenti per risolvere il problema:
- Prima di tutto, controllare l'ID risorsa cluster nel portale di Azure per verificare se la risorsa del cluster Kubernetes esiste ancora ed è in esecuzione normalmente.
- Se il cluster esiste ed è in esecuzione, è possibile provare a scollegare e ricollegare il calcolo all'area di lavoro. Prestare attenzione a più note su ricollegare.
ERRORE: ClusterServiceNotFound
Di seguito è riportato il messaggio di errore:
AzureML extension service not found in cluster.
Questo errore si verifica quando il servizio di ingresso di proprietà dell'estensione non dispone di pod back-end sufficienti.
È possibile:
- Accedere al cluster e controllare lo stato del servizio
azureml-ingress-nginx-controllere del relativo pod back-end nello spazio dei nomiazureml. - Se il cluster non dispone di pod back-end in esecuzione, controllare il motivo descrivendo il pod. Ad esempio, se il pod non dispone di risorse sufficienti per l'esecuzione, è possibile eliminare alcuni pod per liberare risorse sufficienti per il pod in ingresso.
ERRORE: ClusterUnauthorized
Di seguito è riportato il messaggio di errore:
Request to Kubernetes cluster unauthorized.
Questo errore si verifica solo nel cluster abilitato per TA, il che significa che il token di accesso è scaduto durante la distribuzione.
È possibile riprovare dopo alcuni minuti.
Suggerimento
Altre informazioni sulla risoluzione dei problemi relativi agli errori comuni durante la creazione/aggiornamento degli endpoint e delle distribuzioni online di Kubernetes sono disponibili in Come risolvere i problemi degli endpoint online.
Errore di identità
ERROR: RefreshExtensionIdentityNotSet
Questo errore si verifica quando l'estensione è installata, ma l'identità dell'estensione non è assegnata correttamente. È possibile provare a reinstallare l'estensione per correggerla.
Si noti che questo errore è solo per i cluster gestiti
Come controllare sslCertPemFile e sslKeyPemFile è corretto?
Per consentire la visualizzazione di eventuali errori noti, è possibile usare i comandi per eseguire un controllo di base per il certificato e la chiave. Si prevede che il secondo comando restituisca "RSA key ok" senza richiedere la password.
openssl x509 -in cert.pem -noout -text
openssl rsa -in key.pem -noout -check
Eseguire i comandi per verificare se sslCertPemFile e sslKeyPemFile corrispondono:
openssl x509 -in cert.pem -noout -modulus | md5sum
openssl rsa -in key.pem -noout -modulus | md5sum
Per sslCertPemFile, è il certificato pubblico. Deve includere la catena di certificati che include i certificati seguenti e deve trovarsi nella sequenza del certificato del server, il certificato CA intermedio e il certificato CA radice:
- Certificato server: il server presenta al client durante l'handshake TLS. Contiene la chiave pubblica del server, il nome di dominio e altre informazioni. Il certificato server è firmato da un'autorità di certificazione intermedia (CA) che garantisce l'identità del server.
- Certificato CA intermedio: la CA intermedia si presenta al client per dimostrare l'autorità per firmare il certificato del server. Contiene la chiave pubblica della CA, il nome e altre informazioni. Il certificato CA intermedio è firmato da una CA radice che garantisce l'identità dell'autorità di certificazione intermedia.
- Certificato CA radice: la CA radice si presenta al client per dimostrare l'autorità per firmare il certificato della CA intermedia. Contiene la chiave pubblica della CA radice, il nome e altre informazioni. Il certificato CA radice è autofirmato e considerato attendibile dal client.
Guida al training
Quando il processo di training è in esecuzione, è possibile controllare lo stato del processo nel portale dell'area di lavoro. Quando si verifica uno stato anomalo del processo, ad esempio il processo è stato ritentato più volte, oppure è rimasto bloccato nello stato di inizializzazione o ha avuto esito negativo, è possibile seguire la guida per risolvere il problema.
Debug dei tentativi di ripetizione del processo
Se il pod del processo di training in esecuzione nel cluster è stato terminato a causa del nodo in esecuzione nel nodo OOM (memoria insufficiente), il processo viene riproposto automaticamente a un altro nodo disponibile.
Per eseguire il debug della causa radice del processo, è possibile passare al portale dell'area di lavoro per controllare il log dei tentativi di processo.
- Ogni log di ripetizione dei tentativi viene registrato in una nuova cartella di log con il formato "retry-<retry number>"(ad esempio: retry-001).
È quindi possibile ottenere le informazioni di mapping dei nodi del processo di ripetizione dei tentativi per individuare il nodo in cui è in esecuzione il processo di ripetizione dei tentativi.
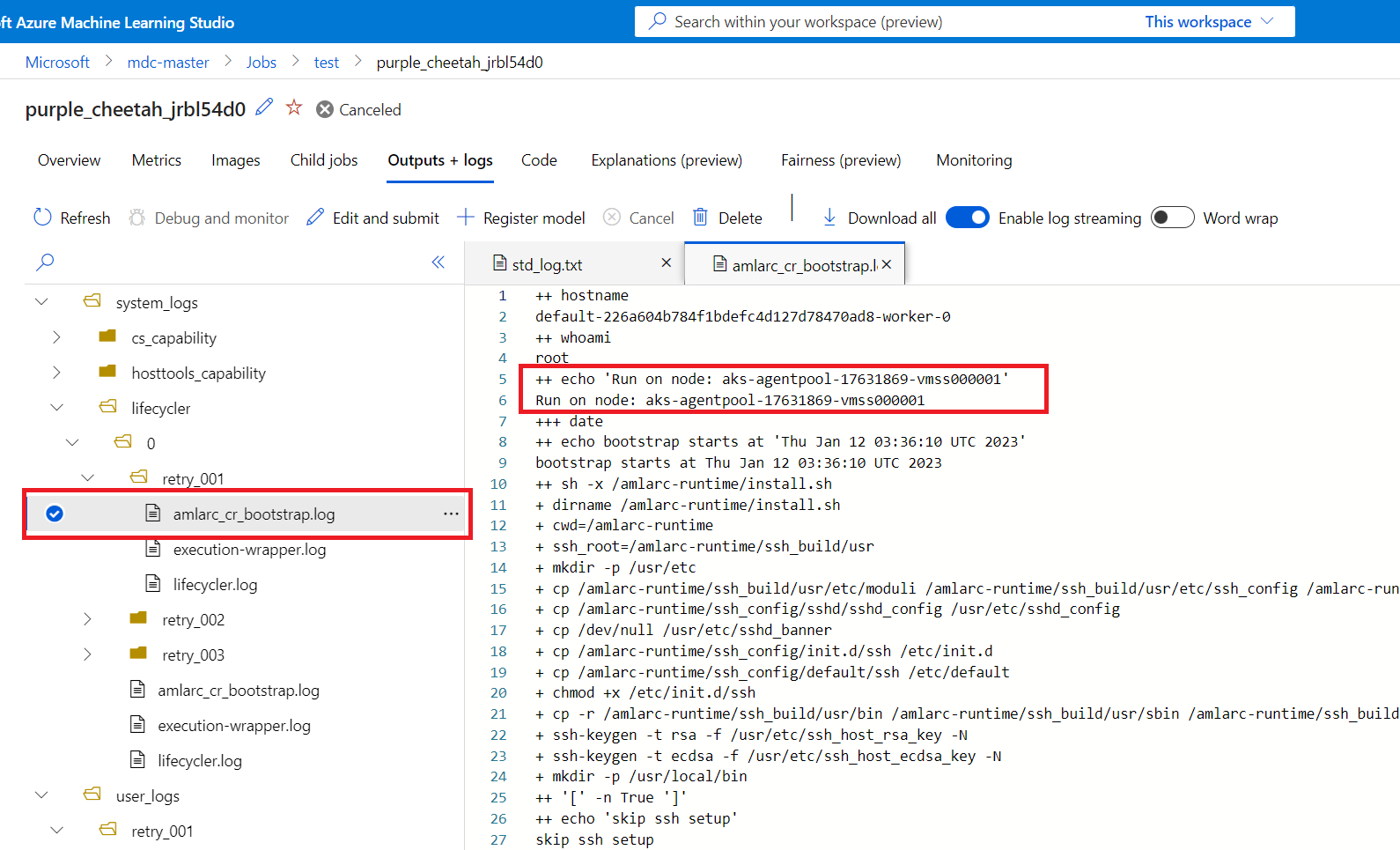
È possibile ottenere informazioni sul mapping dei nodi di processo dalla amlarc_cr_bootstrap.log nella cartella system_logs.
Il nome host del nodo in cui è in esecuzione il pod del processo è indicato in questo log, ad esempio:
++ echo 'Run on node: ask-agentpool-17631869-vmss0000"
"ask-agentpool-17631869-vmss0000" rappresenta il nome host del nodo che esegue questo processo nel cluster del servizio Azure Kubernetes. È quindi possibile accedere al cluster per verificare lo stato del nodo per ulteriori indagini.
Il pod del processo si blocca nello stato Init
Se il processo viene eseguito più a lungo del previsto e se si scopre che i pod del processo rimangono bloccati in uno stato Init con questo avviso Unable to attach or mount volumes: *** failed to get plugin from volumeSpec for volume ***-blobfuse-*** err=no volume plugin matched, il problema potrebbe verificarsi perché l'estensione Azure Machine Learning non supporta la modalità di download per i dati di input.
Per risolvere questo problema, passare alla modalità di montaggio per i dati di input.
Errori comuni relativi all'errore del processo
Di seguito è riportato un elenco dei tipi di errore comuni che possono verificarsi quando si usa il calcolo Kubernetes per creare ed eseguire un processo di training, che è possibile risolvere seguendo le linee guida seguenti:
- Job failed. 137
- Job failed. E45004
- Job failed. 400
- Specificare una chiave dell'account o un token di firma di accesso condiviso
- Autorizzazione di AzureBlob non riuscita
Job failed. 137
Se il messaggio di errore è:
Azure Machine Learning Kubernetes job failed. 137:PodPattern matched: {"containers":[{"name":"training-identity-sidecar","message":"Updating certificates in /etc/ssl/certs...\n1 added, 0 removed; done.\nRunning hooks in /etc/ca-certificates/update.d...\ndone.\n * Serving Flask app 'msi-endpoint-server' (lazy loading)\n * Environment: production\n WARNING: This is a development server. Do not use it in a production deployment.\n Use a production WSGI server instead.\n * Debug mode: off\n * Running on http://127.0.0.1:12342/ (Press CTRL+C to quit)\n","code":137}]}
Controllare l'impostazione del proxy e verificare se 127.0.0.1 è stato aggiunto all'intervallo proxy-skip-range quando si usa az connectedk8s connect seguendo questa configurazione di rete.
Job failed. E45004
Se il messaggio di errore è:
Azure Machine Learning Kubernetes job failed. E45004:"Training feature is not enabled, please enable it when install the extension."
Controllare se è stato impostato enableTraining=True durante l'installazione dell'estensione Azure Machine Learning. Per altre informazioni, vedere Distribuire l'estensione Azure Machine Learning nel servizio Azure Kubernetes o nel cluster Arc Kubernetes
Job failed. 400
Se il messaggio di errore è:
Azure Machine Learning Kubernetes job failed. 400:{"Msg":"Encountered an error when attempting to connect to the Azure Machine Learning token service","Code":400}
È possibile seguire la sezione risoluzione dei problemi dei collegamenti privati per controllare le impostazioni di rete.
Specificare una chiave dell'account o un token di firma di accesso condiviso
Se è necessario accedere al Registro Azure Container per l'immagine Docker e accedere all'account di archiviazione per i dati di training, questo problema deve verificarsi quando il calcolo non viene specificato con un'identità gestita.
Per accedere al Registro Azure Container da un cluster di elaborazione Kubernetes per le immagini Docker o accedere a un account di archiviazione per i dati di training, è necessario collegare il calcolo Kubernetes con un'identità abilitata e gestita assegnata dal sistema o dall'utente.
Nello scenario di training precedente, questa identità di calcolo è necessaria per l'uso del calcolo Kubernetes come credenziale per comunicare tra la risorsa ARM associata all'area di lavoro e il cluster di calcolo Kubernetes. Quindi, senza questa identità, il processo di training fallisce e segnala la chiave dell'account o il token di firma di accesso condiviso mancante. Accedendo all’account di archiviazione, ad esempio, se non si specifica un'identità gestita per il calcolo Kubernetes, il processo ha esito negativo con il messaggio di errore seguente:
Unable to mount data store workspaceblobstore. Give either an account key or SAS token
La causa è che l'account di archiviazione predefinito dell'area di lavoro di Machine Learning senza credenziali non è accessibile per i processi di training nell'ambiente di calcolo Kubernetes.
Per attenuare questo problema, è possibile assegnare l'identità gestita al calcolo nel passaggio di collegamento di calcolo oppure assegnare l'identità gestita al calcolo dopo che è stato collegato. Per altre informazioni, vedere Assegnare un'identità gestita alla destinazione di calcolo.
Autorizzazione di AzureBlob non riuscita
Se è necessario accedere ad AzureBlob per il caricamento o il download dei dati nei processi di training nell'ambiente di calcolo Kubernetes, il processo ha esito negativo con il messaggio di errore seguente:
Unable to upload project files to working directory in AzureBlob because the authorization failed.
La causa è l'autorizzazione non riuscita quando il processo tenta di caricare i file di progetto in AzureBlob. È possibile controllare gli elementi seguenti per risolvere il problema:
- Assicurarsi che l'account di archiviazione abbia abilitato le eccezioni di “Consenti ai servizi di Azure nell'elenco dei servizi attendibili di accedere a questo account di archiviazione” e che l'area di lavoro si trovi nell'elenco delle istanze delle risorse.
- Assicurarsi che all'area di lavoro sia assegnata un'identità gestita assegnata dal sistema.
Problema di collegamento privato
È possibile usare il metodo per controllare la configurazione dei collegamenti privati accedendo a un pod nel cluster Kubernetes e quindi controllando poi le impostazioni di rete correlate.
Trovare l'ID dell'area di lavoro nel portale di Azure o ottenere questo ID eseguendo
az ml workspace shownella riga di comando.Visualizzare tutti i pod azureml-fe eseguiti da
kubectl get po -n azureml -l azuremlappname=azureml-fe.Accedere a uno qualsiasi di essi ed eseguire
kubectl exec -it -n azureml {scorin_fe_pod_name} bash.Se il cluster non usa l'esecuzione del proxy
nslookup {workspace_id}.workspace.{region}.api.azureml.ms. Se si configura correttamente un collegamento privato dalla rete virtuale all'area di lavoro, l'indirizzo IP interno nella rete virtuale deve ricevere risposta tramite lo strumento DNSLookup.Se il cluster usa proxy, è possibile provare nell’area di lavoro
curl
curl https://{workspace_id}.workspace.westcentralus.api.azureml.ms/metric/v2.0/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{workspace_name}/api/2.0/prometheus/post -X POST -x {proxy_address} -d {} -v -k
Quando il proxy e l'area di lavoro sono configurati correttamente con un collegamento privato, è necessario provare un tentativo di connessione a un indirizzo IP interno. In questo scenario è prevista una risposta con un codice di stato HTTP 401 se non viene fornito un token.
Altri problemi noti
L'aggiornamento delle risorse di calcolo Kubernetes non ha effetto
Al momento, l'interfaccia della riga di comando v2 e l'SDK v2 non consentono l'aggiornamento di alcuna configurazione di un ambiente di calcolo Kubernetes esistente. Ad esempio, la modifica dello spazio dei nomi non ha effetto.
Il nome dell'area di lavoro o del gruppo di risorse termina con '-'
Una causa comune dell'errore "InternalServerError" durante la creazione di carichi di lavoro, ad esempio distribuzioni, endpoint o processi in un ambiente di calcolo Kubernetes, presenta caratteri speciali come '-' alla fine dell'area di lavoro o del nome del gruppo di risorse.