Ottimizzazione degli iperparametri per un modello (v2)
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Automatizzare un'ottimizzazione efficiente degli iperparametri con Azure Machine Learning SDK v2 e l'interfaccia della riga di comando v2 tramite il tipo SweepJob.
- Definire lo spazio di ricerca dei parametri per la versione di prova
- Specificare l'algoritmo di campionamento per il processo sweep
- Specificare l'obiettivo che si desidera ottimizzare
- Specificare i criteri di interruzione anticipata per i processi con prestazioni ridotte
- Definire i limiti per il processo sweep
- Avviare un esperimento con la configurazione definita
- Visualizzare i processi di training
- Selezionare la configurazione migliore per il modello
Che cos'è l'ottimizzazione degli iperparametri?
Gli iperparametri sono parametri regolabili che consentono di controllare il processo di training del modello. Ad esempio, con le reti neurali, si decide il numero di livelli nascosti e il numero di nodi in ogni livello. Le prestazioni del modello dipendono principalmente dagli iperparametri.
L'ottimizzazione degli iperparametri, detta anche affinamento degli iperparametri, è il processo di ricerca della configurazione degli iperparametri che produce prestazioni ottimali. Il processo è generalmente manuale e costoso a livello di calcolo.
Azure Machine Learning consente di automatizzare l'ottimizzazione degli iperparametri e di eseguire esperimenti in parallelo per affinare gli iperparametri in modo efficiente.
Definire lo spazio di ricerca
Ottimizzare gli iperparametri grazie all'esplorazione dell'intervallo dei valori definiti per ogni iperparametro.
Gli iperparametri possono essere discreti o continui e avere una distribuzione di valori descritta con un'espressione di parametro.
Iperparametri discreti
Gli iperparametri discreti vengono specificati come una scelta (Choice) tra valori discreti. Choice può essere:
- Uno o più valori delimitati da virgole
- Un oggetto
range - Un oggetto
listarbitrario
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
In questo caso, batch_size uno dei valori [16, 32, 64, 128] e number_of_hidden_layers accetta uno dei valori [1, 2, 3, 4].
È inoltre possibile specificare i seguenti iperparametri discreti avanzati usando una distribuzione:
QUniform(min_value, max_value, q)- Restituisce un valore come round(Uniform(min_value, max_value) / q) * qQLogUniform(min_value, max_value, q)- Restituisce un valore come round(exp(Uniform(min_value, max_value)) / q) * qQNormal(mu, sigma, q)- Restituisce un valore come round(Normal(mu, sigma) / q) * qQLogNormal(mu, sigma, q)- Restituisce un valore come round(exp(Normal(mu, sigma)) / q) * q
Iperparametri continui
Gli iperparametri continui vengono specificati come distribuzione su un intervallo di valori continuo:
Uniform(min_value, max_value)- Restituisce un valore distribuito in modo uniforme tra min_value e max_valueLogUniform(min_value, max_value)- Restituisce un valore ricavato in base a exp(Uniform(min_value, max_value)) in modo che il logaritmo del valore restituito sia distribuito uniformementeNormal(mu, sigma): restituisce un valore reale distribuito in modo normale con la media mu e la deviazione standard sigmaLogNormal(mu, sigma)- Restituisce un valore ricavato in base a exp(Normal(mu, sigma)) in modo che il logaritmo del valore restituito sia distribuito normalmente
Esempio di definizione per lo spazio dei parametri:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Questo codice definisce uno spazio di ricerca con due parametri: learning_rate e keep_probability. learning_rate ha una distribuzione normale con un valore medio di 10 e una deviazione standard pari a 3. keep_probability ha una distribuzione uniforme con un valore minimo di 0,05 e un valore massimo di 0,1.
Per l'interfaccia della riga di comando, è possibile usare lo schema YAML del processo sweep per definire lo spazio di ricerca nel file YAML:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
Campionamento dello spazio degli iperparametri
Specificare il metodo di campionamento dei parametri da usare nello spazio degli iperparametri. Azure Machine Learning supporta i seguenti metodi:
- Campionamento casuale
- Campionamento a griglia
- Campionamento bayesiano
Campionamento casuale
Il campionamento casuale supporta iperparametri discreti e continui. Esso supporta l'interruzione anticipata dei processi con prestazioni ridotte. Alcuni utenti eseguono una ricerca iniziale con campionamento casuale, successivamente affinano lo spazio di ricerca per migliorare i risultati.
Nel campionamento casuale i valori degli iperparametri vengono selezionati in modo casuale dallo spazio di ricerca definito. Dopo aver creato il processo di comando, è possibile usare il parametro sweep per definire l'algoritmo di campionamento.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Sobol
Sobol è un tipo di campionamento casuale supportato dai tipi di processi sweep. È possibile usare sobol per riprodurre i risultati usando il valore di inizializzazione e coprire la distribuzione dello spazio di ricerca in modo più uniforme.
Per sobol, usare la classe RandomParameterSampling per aggiungere il valore di inizializzazione e la regola, come illustrato nell'esempio riportato di seguito.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
Campionamento a griglia
Il campionamento a griglia supporta iperparametri discreti. Usare il campionamento a griglia se si ha un budget che consente di eseguire una ricerca completa nello spazio di ricerca. Supporta l'interruzione anticipata dei processi con prestazioni ridotte.
Il campionamento a griglia esegue una ricerca a griglia semplice su tutti i valori possibili. Il campionamento a griglia può essere usato soltanto con gli iperparametri choice. Ad esempio, nello spazio seguente sono presenti sei campioni:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Campionamento bayesiano
Il campionamento bayesiano si basa sull'algoritmo di ottimizzazione bayesiana. Vengono selezionati i campioni in base alla modalità di esecuzione dei campioni precedenti, affinché i nuovi campioni migliorino la metrica primaria.
Il campionamento bayesiano è consigliato se si ha un budget sufficiente per esplorare lo spazio degli iperparametri. Per ottenere risultati ottimali, si consiglia un numero massimo di processi maggiore o uguale a 20 volte il numero di iperparametri che si desidera ottimizzare.
Il numero di processi simultanei influisce sull'efficacia del processo di ottimizzazione. Un numero minore di processi simultanei può migliorare la convergenza di campionamento, poiché il minor grado di parallelismo aumenta il numero di processi che traggono vantaggio da quelli completati in precedenza.
Il campionamento bayesiano supporta solo le distribuzioni choice, uniform e quniform nello spazio di ricerca.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
Specificare l'obiettivo dello sweep
Definire l'obiettivo del processo sweep, specificando la metrica primaria e l'obiettivo che si desidera ottimizzare con l'affinamento dell'iperparametro. Ogni processo di training viene valutato in base alla metrica primaria. I criteri di interruzione anticipata usano la metrica primaria per individuare i processi con prestazioni ridotte.
primary_metric: il nome della metrica primaria deve corrispondere esattamente al nome della metrica registrato dallo script di traininggoal: può essereMaximizeoMinimizee determina se la metrica primaria sarà massimizzata o ridotta durante la valutazione dei processi.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
In questo esempio la "accuratezza" viene massimizzata.
Registrare le metriche per l'ottimizzazione degli iperparametri
Lo script di training per il modello deve registrare la metrica primaria durante il training del modello, usando lo stesso nome della metrica corrispondente. In questo modo SweepJob può accedervi per l'ottimizzazione degli iperparametri.
Registrare la metrica primaria nello script di training con il frammento di codice dell’esempio seguente:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
Lo script di training calcola val_accuracy e lo registra come "accuratezza" della metrica primaria. Ogni volta che si registra, la metrica viene ricevuta dal servizio di ottimizzazione degli iperparametri. L'utente dovrà determinare la frequenza di reporting.
Per altre informazioni sulla registrazione dei valori nei processi di training del modello, vedere Abilitare la registrazione nei processi di training di Azure Machine Learning.
Specificare i criteri per la terminazione anticipata
È possibile interrompere automaticamente i processi con prestazioni insufficienti grazie ai criteri di interruzione anticipata. L'interruzione anticipata migliora l'efficienza di calcolo.
È possibile configurare i seguenti parametri per controllare quando un criterio viene applicato:
evaluation_interval: frequenza di applicazione del criterio. Ogni volta che lo script di training registra la metrica primaria viene conteggiata come un intervallo. Un valoreevaluation_intervalpari a 1 causa l'applicazione del criterio ogni volta che lo script di training segnala la metrica primaria. Un valoreevaluation_intervalpari a 2 causa l'applicazione del criterio tutte le altre volte. Se non viene specificato,evaluation_intervalè impostato su 0 per impostazione predefinita.delay_evaluation: ritarda la prima valutazione dei criteri per un numero di intervalli specificato. Si tratta di un parametro facoltativo che evita l'interruzione anticipata dei processi di training consentendo l'esecuzione di tutte le configurazioni per un numero minimo di intervalli. Se specificato, i criteri vengono applicati ogni multiplo di evaluation_interval che è maggiore o uguale a delay_evaluation. Se non viene specificato,delay_evaluationè impostato su 0 per impostazione predefinita.
Azure Machine Learning supporta i seguenti criteri di interruzione anticipata:
- Criteri Bandit
- Criteri di arresto Median
- Criteri di selezione Truncation
- Nessun criterio di interruzione
Criteri Bandit
I criteri Bandit si basano su fattore/entità del margine di flessibilità e sull'intervallo di valutazione. I criteri Bandit interrompono un processo se la metrica primaria non rientra nei valori di fattore/entità del margine di flessibilità del processo più riuscito.
Specificare i seguenti parametri di configurazione:
slack_factoroslack_amount: margine di flessibilità consentito rispetto al processo di training con le migliori prestazioni.slack_factorspecifica il margine di flessibilità consentito come rapporto.slack_amountspecifica il margine di flessibilità consentito come valore assoluto, anziché come rapporto.Ad esempio, considerare criteri Bandit applicati all'intervallo 10. Si supponga che il processo con le migliori prestazioni nell'intervallo 10 abbia nel report della metrica primaria un valore 0,8 con l'obiettivo di massimizzare la metrica primaria. Se il criterio specifica per
slack_factorun valore di 0,2, sarà interrotto qualsiasi processo di training la cui metrica migliore nell'intervallo 10 è minore di 0,66 (0,8/(1+slack_factor)).evaluation_interval: (facoltativo) la frequenza di applicazione dei criteridelay_evaluation: (facoltativo) ritarda la prima valutazione dei criteri per un numero di intervalli specificato
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
In questo esempio, i criteri di terminazione anticipata vengono applicati a ogni intervallo in cui vengono segnalate le metriche, a partire dall'intervallo di valutazione 5. Verrà interrotto qualsiasi processo la cui metrica migliore è minore di (1/(1+0,1) o del 91%, rispetto al processo con le migliori prestazioni.
Criteri di arresto con valore mediano
Arresto Median è un criterio di interruzione anticipata basato sulle medie mobili delle metriche primarie presenti nei report dei processi. I criteri calcolano le medie mobili su tutti i processi di training e interrompono quelli il cui valore della metrica primaria è minore del valore mediano delle medie.
I parametri di configurazione accettati da questi criteri sono i seguenti:
evaluation_interval: frequenza per l'applicazione del criterio (parametro facoltativo).delay_evaluation: ritarda la prima valutazione dei criteri per un numero di intervalli specificato (parametro facoltativo).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
In questo esempio, i criteri di terminazione anticipata vengono applicati a ogni intervallo, a partire dall'intervallo di valutazione 5. Un processo viene interrotto nell'intervallo 5 se la sua metrica primaria migliore è peggiore rispetto al valore mediano delle medie mobili, su intervalli 1:5 di tutti i processi di training.
Criteri di selezione con troncamento
Selezione Truncation annulla una percentuale di processi con prestazioni più scarse in ciascun intervallo di valutazione. I processi vengono confrontati usando la metrica primaria.
I parametri di configurazione accettati da questi criteri sono i seguenti:
truncation_percentage: percentuale di processi con prestazioni più scarse da terminare in ogni intervallo di valutazione. Un valore intero compreso tra 1 e 99.evaluation_interval: (facoltativo) la frequenza di applicazione dei criteridelay_evaluation: (facoltativo) ritarda la prima valutazione dei criteri per un numero di intervalli specificatoexclude_finished_jobs: specifica se escludere i processi completati quando si applica il criterio
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
In questo esempio, i criteri di terminazione anticipata vengono applicati a ogni intervallo, a partire dall'intervallo di valutazione 5. Un processo si interrompe nell'intervallo 5 se le prestazioni in tale intervallo rientrano nel 20% di prestazioni più basse di tutti i processi nell'intervallo 5 e, quando si applica il criterio, vengono esclusi i processi completati.
Nessun criterio di interruzione (impostazione predefinita)
Se non viene specificato alcun criterio, il servizio di ottimizzazione degli iperparametri consente il completamento di tutti i processi di training.
sweep_job.early_termination = None
Selezione di un criterio di interruzione anticipata
- Per impostare un criterio conservativo che consenta di risparmiare senza interrompere processi promettenti, prendere in considerazione il criterio di arresto Median con
evaluation_intervalpari a 1 edelay_evaluationpari a 5. Queste sono impostazioni conservative, che possono garantire circa il 25-35% di risparmio, senza alcuna perdita sulla metrica primaria (in base ai dati di valutazione). - Per un risparmio più consistente, usare i criteri Bandit con margine di flessibilità consentito inferiore o i criteri di selezione Truncation con una percentuale di troncamento maggiore.
Impostare i limiti per il processo sweep
Controllare il budget delle risorse impostando i limiti per il processo sweep.
max_total_trials: numero massimo di processi di valutazione. Deve essere un numero intero compreso tra 1 e 1000.max_concurrent_trials: (facoltativo) numero massimo di processi di valutazione simultanei. Se non specificato, max_total_trials è il numero di processi avviati in parallelo. Se specificato, deve essere un numero intero compreso tra 1 e 1000.timeout: tempo massimo in secondi consentito per l'esecuzione dell'intero processo sweep. Una volta raggiunto questo limite, il sistema annulla il processo sweep, incluse tutte le relative valutazioni.trial_timeout: tempo massimo in secondi consentito per l'esecuzione di ogni processo di valutazione. Una volta raggiunto questo limite, il sistema annulla la valutazione.
Nota
Se si specificano sia max_total_trials, sia il timeout, l'esperimento di ottimizzazione degli iperparametri si interrompe al raggiungimento della prima di queste due soglie.
Nota
Il numero di processi di valutazione simultanei viene limitato in base alle risorse disponibili nella destinazione di calcolo specificata. Verificare che nella destinazione di calcolo siano disponibili risorse sufficienti per la concorrenza dei processi desiderata.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Questo codice configura l'esperimento di ottimizzazione degli iperparametri per l'uso di un massimo di 20 processi di valutazione totali, eseguendo quattro processi di valutazione alla volta, con un timeout di 1.200 secondi per l'intero processo sweep.
Configurare l'esperimento di ottimizzazione degli iperparametri
Per configurare l'esperimento di ottimizzazione degli iperparametri, devono essere disponibili gli elementi seguenti:
- Lo spazio di ricerca degli iperparametri definito
- L'algoritmo di campionamento
- I criteri di interruzione anticipata
- L'obiettivo
- Limiti delle risorse
- CommandJob oppure CommandComponent
- SweepJob
SweepJob può eseguire uno sweep degli iperparametri nel comando o nel componente del comando.
Nota
La destinazione di calcolo usata in sweep_job deve avere risorse sufficienti per soddisfare il livello di concorrenza. Per altre informazioni sulle destinazioni di calcolo, vedere Destinazione di calcolo.
Configurare l'esperimento di ottimizzazione degli iperparametri:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
command_job viene denominato come una funzione affinché sia possibile applicare le espressioni dei parametri agli input di sweep. La funzione sweep viene quindi configurata con trial, sampling-algorithm, objective,limits e compute. Il frammento di codice sopra riportato è stato preso dal notebook di esempio Eseguire lo sweep degli iperparametri in Command o in CommandComponent. In questo esempio vengono ottimizzati i parametri learning_rate e boosting. L'arresto anticipato dei processi è determinato da un MedianStoppingPolicy, che interrompe un processo il cui valore della metrica primaria è peggiore rispetto al valore mediano delle medie di tutti i processi di training. (Vedere Riferimento alla classe MedianStoppingPolicy).
Per vedere come vengono ricevuti, analizzati e trasferiti allo script di training i valori dei parametri da ottimizzare, vedere questo codice di esempio
Importante
Ogni processo sweep degli iperparametri riavvia il training dall’inizio, inclusa la ricompilazione del modello e tutti i caricatori di dati. È possibile ridurre al minimo il costo di questa operazione avvalendosi di una pipeline di Azure Machine Learning o di un processo manuale, per eseguire la massima preparazione possibile prima dei processi di training.
Inviare un esperimento di ottimizzazione degli iperparametri
Dopo aver definito la configurazione dell'ottimizzazione degli iperparametri, inviare il processo:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Visualizzare i processi di ottimizzazione degli iperparametri
È possibile visualizzare tutti i processi di ottimizzazione degli iperparametri in studio di Azure Machine Learning. Per ulteriori informazioni su come visualizzare un esperimento nel portale, vedere Visualizzare i record dei processi in studio.
Grafico delle metriche: questa visualizzazione tiene traccia delle metriche registrate per ogni elemento figlio di hyperdrive eseguito nel corso dell'ottimizzazione degli iperparametri. Ogni riga rappresenta un processo figlio e ogni punto misura il valore della metrica primaria in corrispondenza dell'iterazione del runtime.
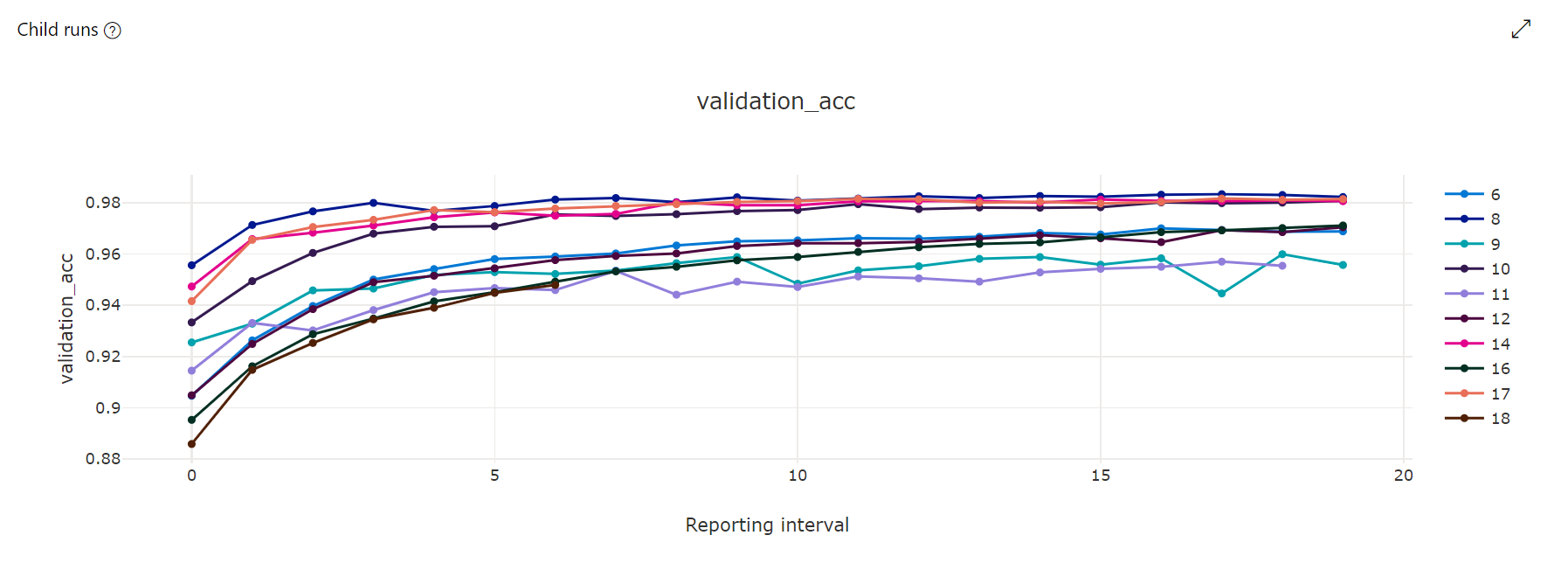
Grafico delle coordinate parallele: questa visualizzazione mostra la correlazione tra le prestazioni della metrica primaria e i singoli valori degli iperparametri. Il grafico è interattivo tramite lo spostamento degli assi (selezionare e trascinare l’etichetta dell'asse) e tramite l'evidenziazione dei valori in un singolo asse (selezionare e trascinare in verticale su un singolo asse per evidenziare un intervallo di valori desiderati). Il grafico delle coordinate parallele comprende un asse nella parte all'estrema destra, che traccia il valore migliore della metrica corrispondente agli iperparametri impostati per l'istanza del processo. L'asse viene fornito per proiettare in modo più leggibile la legenda del gradiente del grafico sui dati.
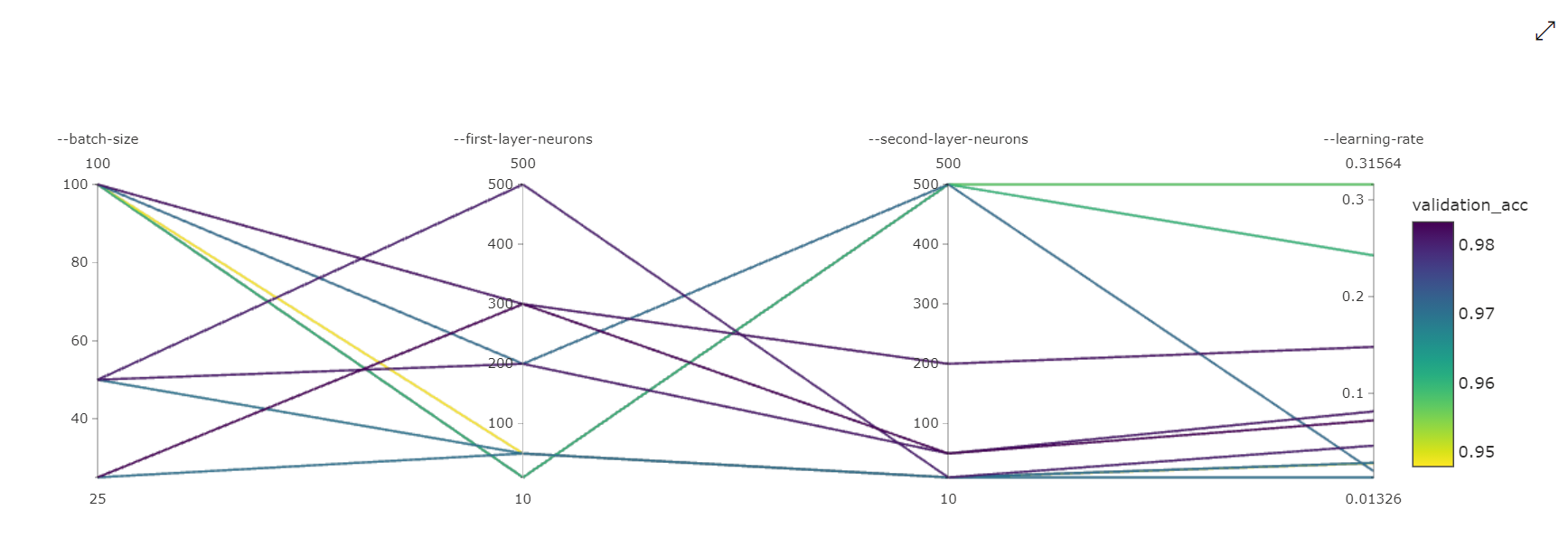
Grafico a dispersione bidimensionale: questa visualizzazione mostra la correlazione tra due iperparametri singoli insieme al valore della metrica primaria associata.
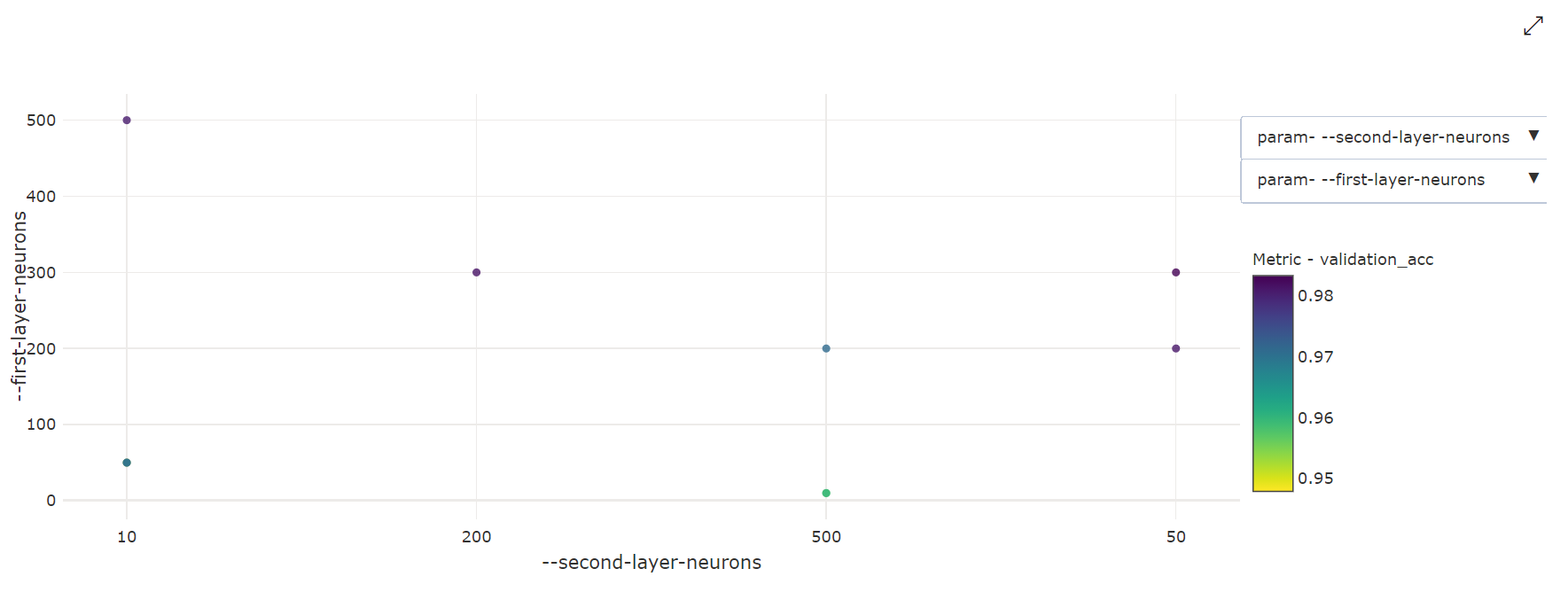
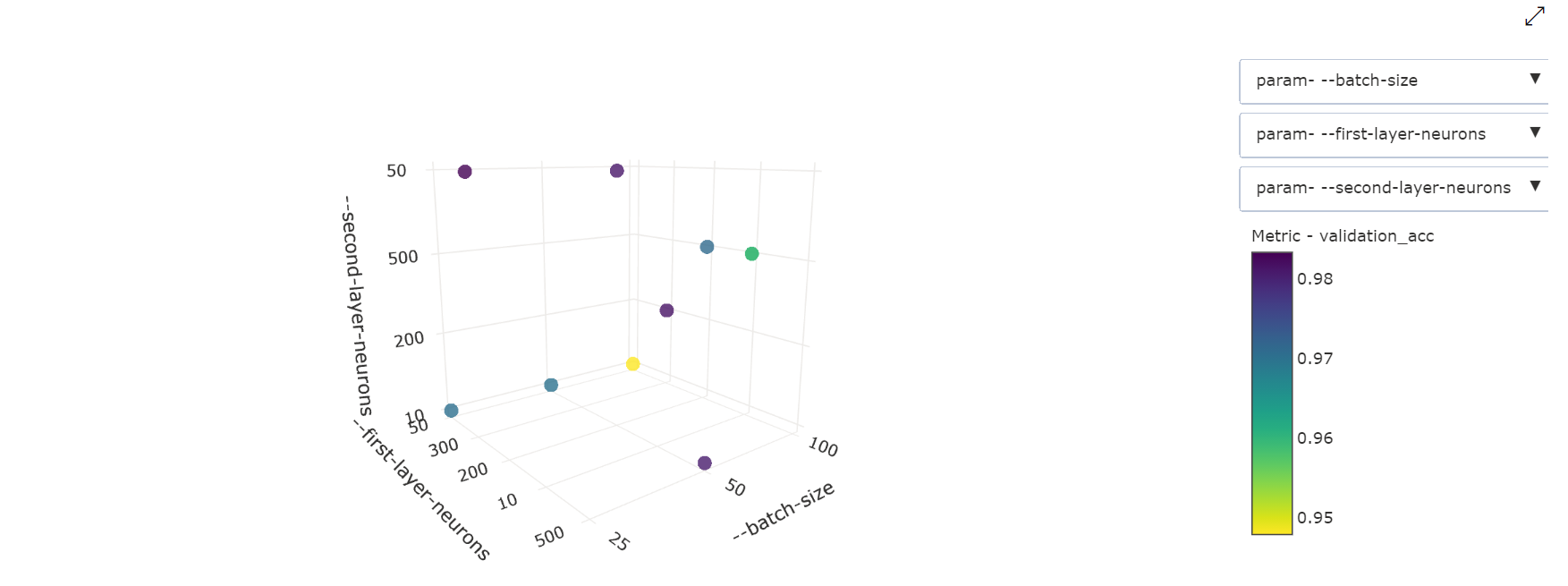
Grafico a dispersione tridimensionale: questa visualizzazione è uguale alla visualizzazione 2D, ma consente di visualizzare tre dimensioni degli iperparametri per la correlazione con il valore della metrica primaria. È anche possibile selezionare e trascinare il grafico per modificarne l'orientamento e visualizzare diverse correlazioni nello spazio 3D.
Individuare il processo di valutazione migliore
Una volta completati tutti i processi di ottimizzazione degli iperparametri, recuperare gli output di valutazione migliori:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
È possibile usare l'interfaccia della riga di comando per scaricare tutti gli output predefiniti e denominati del processo di valutazione migliore e i log del processo sweep.
az ml job download --name <sweep-job> --all
Facoltativamente, per scaricare esclusivamente l'output di valutazione migliore
az ml job download --name <sweep-job> --output-name model
Riferimenti
- Esempio di ottimizzazione degli iperparametri
- Schema YAML del processo sweep dell'interfaccia della riga di comando (v2), qui