Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come valutare e confrontare i modelli sottoposti a training dall'esperimento di Machine Learning automatizzato (ML automatizzato). Nel corso di un esperimento ML automatizzato, vengono creati molti processi e ogni processo crea un modello. Per ogni modello, ML automatizzato genera metriche di valutazione e grafici che consentono di misurare le prestazioni del modello. Per impostazione predefinita, è possibile generare un dashboard di intelligenza artificiale responsabile per eseguire una valutazione olistica e il debug del modello migliore consigliato. Sono incluse informazioni dettagliate, ad esempio spiegazioni dei modelli, equità e esplora prestazioni, Esplora dati, analisi degli errori del modello. Altre informazioni su come generare un dashboard di intelligenza artificiale responsabile.
Ad esempio, il ML automatizzato genera i grafici seguenti in base al tipo di esperimento.
Importante
Gli elementi contrassegnati (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. La versione di anteprima viene messa a disposizione senza contratto di servizio e non è consigliata per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Prerequisiti
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare
- Un esperimento di Azure Machine Learning creato con:
- Studio di Azure Machine Learning (nessun codice necessario)
- Python SDK per Azure Machine Learning
Visualizza risultati processo
Al termine dell'esperimento di Machine Learning automatizzato, è possibile trovare una cronologia dei processi tramite:
- Un browser con studio di Azure Machine Learning
- Un notebook di Jupyter usando il widget Jupyter JobDetails
I passaggi e i video seguenti illustrano come visualizzare la cronologia di esecuzione e le metriche e i grafici di valutazione del modello in studio:
- Accedere a studio e passare all'area di lavoro.
- Nel menu a sinistra, selezionare Processi.
- Selezionare l'esperimento dall'elenco degli esperimenti.
- Nella tabella nella parte inferiore della pagina selezionare un processo di Machine Learning automatizzato.
- Nella scheda Modelli selezionare il Nome algoritmo per il modello da valutare.
- Nella scheda Metriche usare le caselle di controllo a sinistra per visualizzare metriche e grafici.
Metriche per la classificazione
Machine Learning automatizzato calcola le metriche delle prestazioni per ogni modello di classificazione generato per l'esperimento. Queste metriche si basano sull'implementazione di scikit-learn.
Molte metriche di classificazione sono definite per la classificazione binaria in due classi e richiedono una media delle classi per produrre un punteggio per la classificazione multiclasse. Scikit-learn offre diversi metodi di media, tre dei quali il ML automatizzato espone: macro, micro e ponderato.
- Macro: calcolare la metrica per ogni classe e prendere la media non ponderata
- Micro: calcolare la metrica a livello globale conteggiando i veri positivi totali, i falsi negativi e i falsi positivi (indipendenti dalle classi).
- Ponderata: calcolare la metrica per ogni classe e prendere la media ponderata in base al numero di campioni per classe.
Sebbene ogni metodo di media abbia i vantaggi, una considerazione comune quando si seleziona il metodo appropriato è lo squilibrio tra classi. Se le classi hanno numeri diversi di campioni, potrebbe essere più informativo usare una media macro in cui le classi di minoranza vengono date la stessa ponderazione alle classi di maggioranza. Altre informazioni sulle metriche binarie e multiclasse in ML automatizzato.
La tabella seguente riepiloga le metriche delle prestazioni del modello calcolate da ML automatizzato per ogni modello di classificazione generato per l'esperimento. Per altri dettagli, vedere la documentazione di scikit-learn collegata nel campo Calcolo di ogni metrica.
Nota
Per altri dettagli sulle metriche per la classificazione delle immagini per i modelli di classificazione delle immagini, vedere la sezione Metriche delle immagini.
| Metrico | Descrizione | Calcolo |
|---|---|---|
| Area sotto la curva | AUC è l'area sottesa alla curva ROC (Receiver Operating Characteristic). Obiettivo: più vicino a 1 meglio Intervallo: [0, 1] I nomi delle metriche supportati includono, AUC_macro, la media aritmetica dell'AUC per ogni classe.AUC_micro, calcolato contando i veri positivi totali, i falsi negativi e i falsi positivi. AUC_weighted, media aritmetica del punteggio per ogni classe, ponderata in base al numero di istanze true in ogni classe. AUC_binary, il valore dell'AUC trattando una classe specifica come classe true e combina tutte le altre classi come classe false. |
Calcolo |
| precisione | L'accuratezza è il rapporto delle stime che corrispondono esattamente alle etichette di classe vere. Obiettivo: più vicino a 1 meglio Intervallo: [0, 1] |
Calcolo |
| average_precision | average_precision riepiloga una curva di precisione-recupero come media ponderata delle precisioni ottenute in corrispondenza di ogni soglia, usando come valore di ponderazione l'incremento nel recupero rispetto alla soglia precedente. Obiettivo: più vicino a 1 meglio Intervallo: [0, 1] I nomi delle metriche supportati includono, average_precision_score_macro, la media aritmetica del punteggio di precisione medio di ogni classe.average_precision_score_micro, calcolato contando i veri positivi totali, i falsi negativi e i falsi positivi.average_precision_score_weighted, è la media aritmetica del punteggio di precisione media per ogni classe, ponderata in base al numero di istanze vere in ogni classe. average_precision_score_binary, il valore della precisione media considerando una classe specifica come classe true e combina tutte le altre classi come classe false. |
Calcolo |
| accuratezza bilanciata | balanced_accuracy è la media aritmetica del recupero per ogni classe. Obiettivo: più vicino a 1 meglio Intervallo: [0, 1] |
Calcolo |
| f1_score | f1_score è la media armonica di precisione e recupero. È una misura bilanciata di falsi positivi e falsi negativi. Tuttavia, non tiene conto dei veri negativi. Obiettivo: più vicino a 1 meglio Intervallo: [0, 1] I nomi delle metriche supportati includono, f1_score_macro: media aritmetica del punteggio F1 per ogni classe. f1_score_micro: calcolato contando i veri positivi totali, i falsi negativi e i falsi positivi. f1_score_weighted: media ponderata in base alla frequenza di classe del punteggio F1 per ogni classe. f1_score_binary, il valore di f1 considerando una classe specifica come classe true e combina tutte le altre classi come classe false. |
Calcolo |
| perdita logaritmica | Questa è la funzione di perdita usata per la regressione logistica (multinomiale) e le relative estensioni, ad esempio le reti neurali, definita come probabilità logaritmica negativa delle etichette vere date le stime del classificatore probabilistico. Obiettivo: più vicino a 0 meglio Intervallo: [0, inf) |
Calcolo |
| norm_macro_recall | Il richiamo di macro normalizzato è il richiamo macro-mediato e normalizzato, in modo che le prestazioni casuali dispongano di un punteggio pari a 0 e prestazioni perfette abbia un punteggio pari a 1. Obiettivo: più vicino a 1 meglio Intervallo: [0, 1] |
(recall_score_macro - R) / (1 - R) dove, R è il valore previsto di recall_score_macro per le stime casuali.R = 0.5 per la classificazione binaria. R = (1 / C) per i problemi di classificazione della classe C. |
| correlazione_di_Matthews | Il coefficiente di correlazione Matthews è una misura bilanciata dell'accuratezza, che può essere usata anche se una classe ha molti più campioni di un'altra. Un coefficiente pari a 1 indica una stima perfetta, 0 stima casuale e -1 stima inversa. Obiettivo: più vicino a 1 meglio Intervallo: [-1, 1] |
Calcolo |
| precisione | La precisione è la capacità di un modello di evitare di etichettare campioni negativi come positivi. Obiettivo: più vicino a 1 meglio Intervallo: [0, 1] I nomi delle metriche supportati includono, precision_score_macro, la media aritmetica di precision per ogni classe. precision_score_micro, il valore calcolato globalmente sommando i veri positivi e i falsi positivi. precision_score_weighted, la media aritmetica della precisione per ogni classe, ponderata in base al numero di istanze vere in ogni classe. precision_score_binary, il valore della precisione considerando una classe specifica come classe true e combina tutte le altre classi come classe false. |
Calcolo |
| richiamo | Il richiamo è la capacità di un modello di rilevare tutti i campioni positivi. Obiettivo: più vicino a 1 meglio Intervallo: [0, 1] I nomi delle metriche supportati includono, recall_score_macro: la media aritmetica del recupero per ogni classe. recall_score_micro: il valore calcolato globalmente sommando i veri positivi, i falsi negativi e i falsi positivi.recall_score_weighted: la media aritmetica del recupero per ogni classe, ponderata in base al numero di istanze vere in ogni classe. recall_score_binary, il valore di richiamo considerando una classe specifica come classe true e combina tutte le altre classi come classe false. |
Calcolo |
| accuratezza pesata | L'accuratezza ponderata è l'accuratezza in cui ogni campione viene ponderato in base al numero totale di campioni appartenenti alla stessa classe. Obiettivo: più vicino a 1 meglio Intervallo: [0, 1] |
Calcolo |
Metriche di classificazione binaria e multiclasse
Machine Learning automatizzato rileva automaticamente se i dati sono binari e consente agli utenti di attivare le metriche di classificazione binaria anche se i dati sono multiclasse specificando una classe true. Le metriche di classificazione multiclasse vengono segnalate se un set di dati ha due o più classi. Le metriche di classificazione binaria vengono segnalate solo quando i dati sono binari.
Si noti che le metriche di classificazione multiclasse sono destinate alla classificazione multiclasse. Se applicata a un set di dati binario, queste metriche non considerano alcuna classe come classe true, come previsto. Le metriche chiaramente progettate per la multiclasse sono suffissi con micro, macroo weighted. Tra gli esempi sono inclusi average_precision_score, f1_score, precision_score, recall_score e AUC. Ad esempio, invece di calcolare il richiamo come tp / (tp + fn), il richiamo medio multiclasse (micro, macroo weighted) supera entrambe le classi di un set di dati di classificazione binaria. Equivale a calcolare il richiamo per la classe true e la classe false separatamente, quindi prendendo la media dei due.
Inoltre, anche se è supportato il rilevamento automatico della classificazione binaria, è comunque consigliabile specificare sempre manualmente la classe true per assicurarsi che le metriche di classificazione binaria vengano calcolate per la classe corretta.
Per attivare le metriche per i set di dati di classificazione binaria quando il set di dati stesso è multiclasse, gli utenti devono specificare solo la classe da considerare come true classe e queste metriche vengono calcolate.
Matrice di confusione
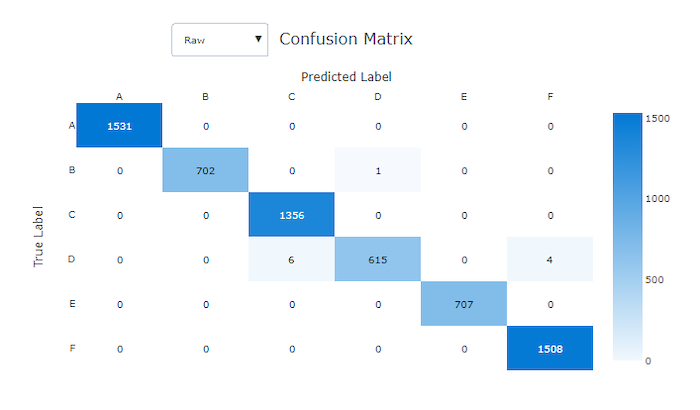
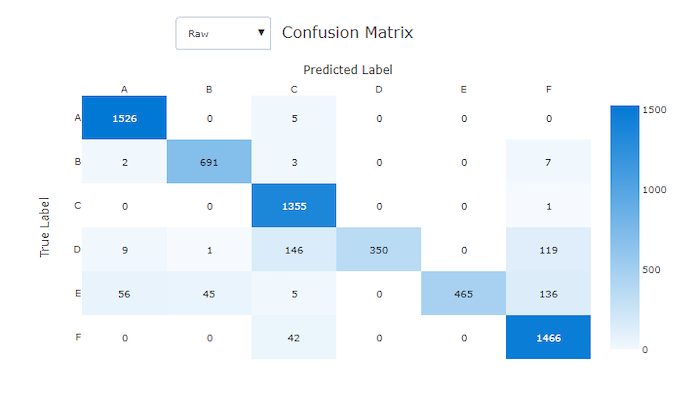
Le matrici di confusione forniscono un oggetto visivo per il modo in cui un modello di Machine Learning sta apportando errori sistematici nelle stime per i modelli di classificazione. La parola "confusione" nel nome deriva da un modello "confuso" o da esempi di errata etichettatura. Una cella in corrispondenza della riga i e della colonna j in una matrice di confusione contiene il numero di campioni nel set di dati di valutazione che appartengono alla classe C_i e sono classificati dal modello come classe C_j.
In studio, una cella più scura indica un numero maggiore di campioni. Se si seleziona visualizzazione normalizzata nell'elenco a discesa, viene normalizzata in ogni riga della matrice per visualizzare la percentuale di classe C_i stimata come classe C_j. Il vantaggio della visualizzazione Non elaborato predefinita è che è possibile verificare se lo squilibrio nella distribuzione delle classi effettive ha causato l'errata classificazione dei campioni dalla classe di minoranza, un problema comune nei set di dati sbilanciati.
La matrice di confusione di un modello valido ha la maggior parte dei campioni lungo la diagonale.
Matrice di confusione per un modello valido
Matrice di confusione per un modello non valido
Curva ROC
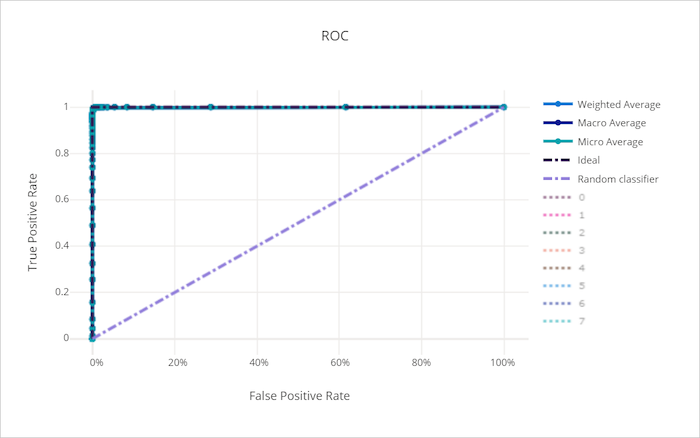
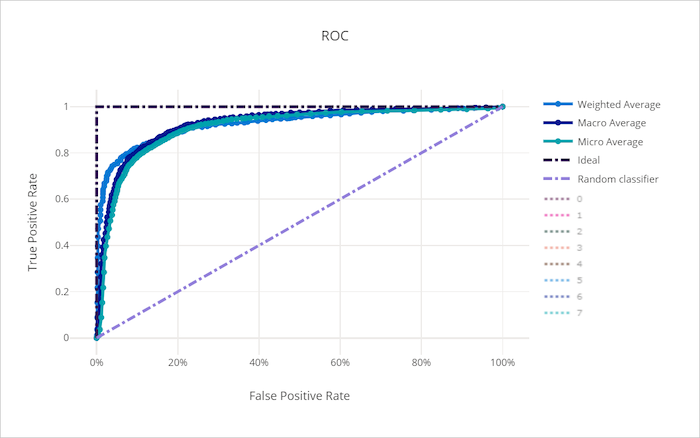
La curva ROC (Receiver Operating Characteristic) traccia la relazione tra il tasso positivo reale (TPR) e il tasso di falsi positivi (FPR) quando la soglia decisionale cambia. La curva ROC può essere meno informativa quando i modelli di training sui set di dati con squilibrio di classe elevata, in quanto la classe di maggioranza può annegare i contributi dalle classi minoritarie.
L'area sotto la curva (AUC) può essere interpretata come la proporzione di campioni classificati correttamente. Più precisamente, l'AUC è la probabilità che il classificatore classifichi in ordine di priorità un campione positivo scelto in modo casuale superiore a un campione negativo scelto in modo casuale. La forma della curva dà un'intuizione per la relazione tra TPR e FPR come funzione della soglia di classificazione o del limite decisionale.
Una curva che si avvicina all'angolo superiore sinistro del grafico si avvicina a una TPR del 100% e allo 0% di FPR, il miglior modello possibile. Un modello casuale produce una curva ROC lungo la linea y = x dall'angolo inferiore sinistro all'angolo superiore destro. Un modello peggiore di quello casuale avrebbe una curva ROC che si immerge sotto la linea y = x.
Suggerimento
Per gli esperimenti di classificazione, ogni grafico a linee prodotto per i modelli di Machine Learning automatizzato può essere usato per valutare il modello per classe o mediato su tutte le classi. È possibile passare da una visualizzazione all'altra facendo clic sulle etichette di classe nella legenda a destra del grafico.
Curva ROC per un modello valido
Curva ROC per un modello non valido
Curva di richiamo di precisione
La curva di richiamo di precisione traccia la relazione tra precisione e richiamo quando cambia la soglia decisionale. Il richiamo è la capacità di un modello di rilevare tutti i campioni positivi e la precisione è la capacità di un modello di evitare di etichettare campioni negativi come positivi. Alcuni problemi aziendali potrebbero richiedere un richiamo più elevato e una maggiore precisione a seconda dell'importanza relativa di evitare falsi negativi rispetto ai falsi positivi.
Suggerimento
Per gli esperimenti di classificazione, ogni grafico a linee prodotto per i modelli di Machine Learning automatizzato può essere usato per valutare il modello per classe o mediato su tutte le classi. È possibile passare da una visualizzazione all'altra facendo clic sulle etichette di classe nella legenda a destra del grafico.
Curva di richiamo di precisione per un modello valido
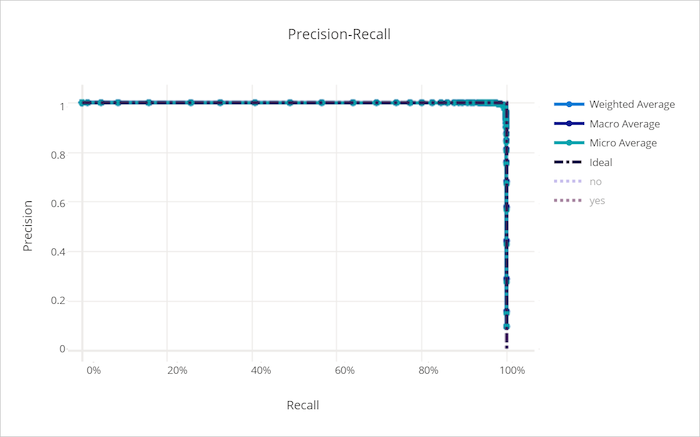
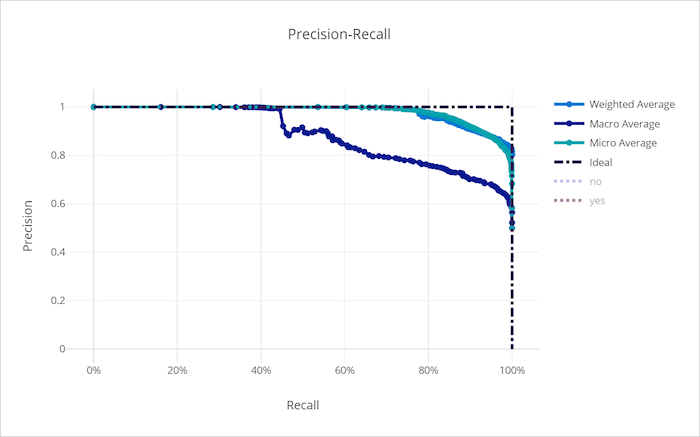
Curva di richiamo di precisione per un modello non valido
Curva dei profitti cumulativi
La curva dei guadagni cumulativi traccia la percentuale di campioni positivi classificati correttamente come funzione della percentuale di campioni considerati in cui si considerano i campioni nell'ordine di probabilità stimata.
Per calcolare il guadagno, ordinare innanzitutto tutti i campioni dalla probabilità più alta alla più bassa stimata dal modello. Eseguire quindi x% delle stime di attendibilità più elevate. Dividere il numero di campioni positivi rilevati in tale x% in base al numero totale di campioni positivi per ottenere il guadagno. Il guadagno cumulativo è la percentuale di campioni positivi rilevati quando si considera una percentuale dei dati che è più probabile appartenere alla classe positiva.
Un modello perfetto classifica tutti i campioni positivi sopra tutti i campioni negativi dando una curva di guadagno cumulativo costituita da due segmenti dritti. La prima è una linea con 1 / x pendenza da (0, 0) a (x, 1) dove x è la frazione di campioni che appartengono alla classe positiva (1 / num_classes se le classi sono bilanciate). Il secondo è una linea orizzontale da (x, 1) a (1, 1). Nel primo segmento tutti i campioni positivi vengono classificati correttamente e il guadagno cumulativo va a 100% entro il primo x% di campioni considerati.
Il modello casuale di base ha una curva dei guadagni cumulativi dopo y = x in cui sono stati rilevati x% di campioni considerati solo circa x% dei campioni positivi totali. Un modello perfetto per un set di dati bilanciato ha una curva micro media e una linea media macro con pendenza num_classes fino a quando il guadagno cumulativo non è 100% e quindi orizzontale fino a quando la percentuale di dati non è 100.
Suggerimento
Per gli esperimenti di classificazione, ogni grafico a linee prodotto per i modelli di Machine Learning automatizzato può essere usato per valutare il modello per classe o mediato su tutte le classi. È possibile passare da una visualizzazione all'altra facendo clic sulle etichette di classe nella legenda a destra del grafico.
Curva dei guadagni cumulativi per un modello valido
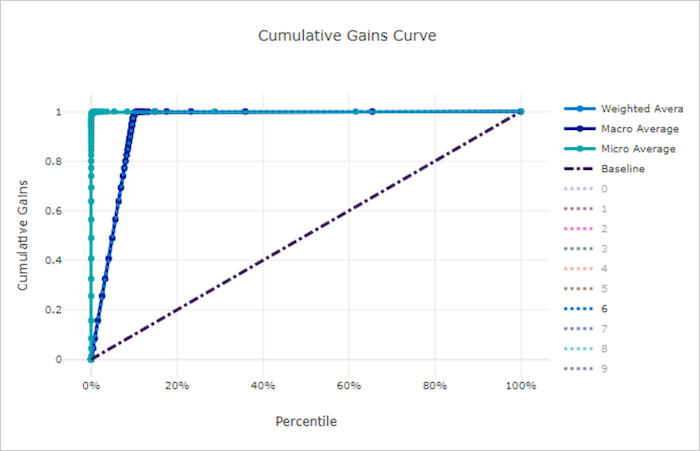
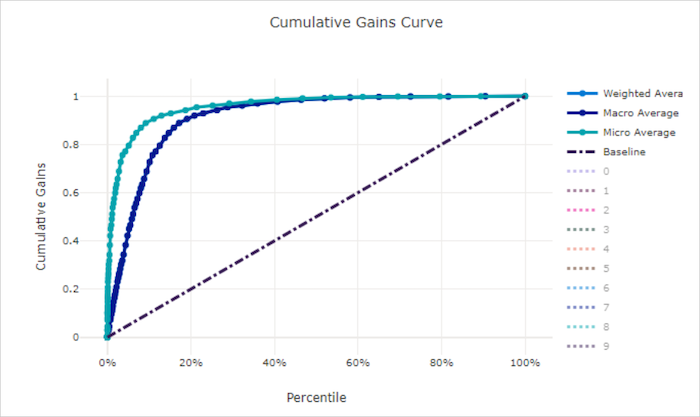
Curva dei guadagni cumulativi per un modello non valido
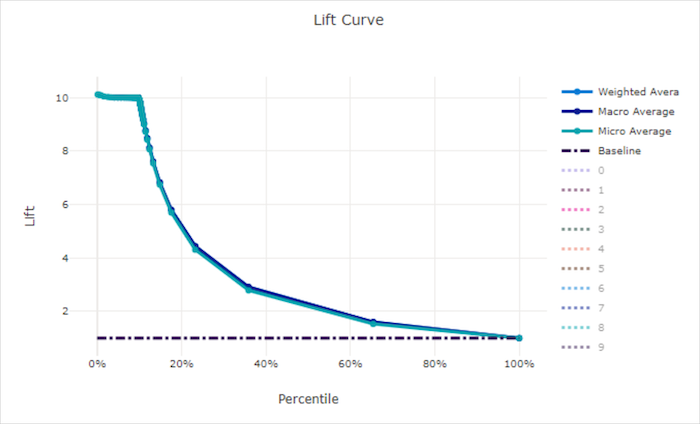
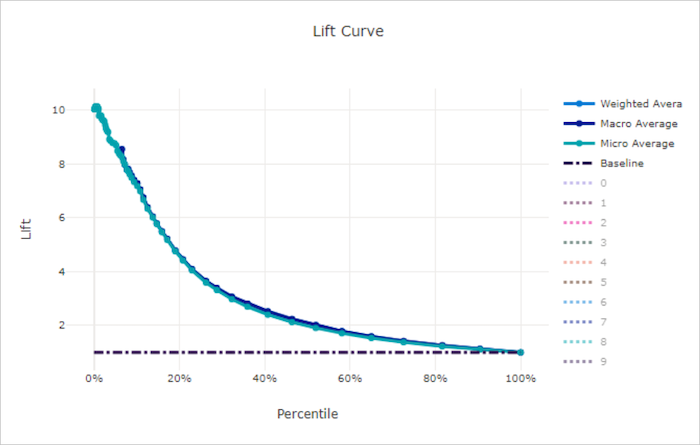
Curva di accuratezza
La curva di accuratezza mostra il numero di prestazioni migliori di un modello rispetto a un modello casuale. L'accuratezza viene definita come rapporto tra guadagno cumulativo e guadagno cumulativo di un modello casuale (che deve essere sempre 1).
Queste prestazioni relative prendono in considerazione il fatto che la classificazione diventa più difficile quando si aumenta il numero di classi. Un modello casuale prevede erroneamente una frazione più elevata di campioni da un set di dati con 10 classi rispetto a un set di dati con due classi.
La curva di accuratezza di base è la linea y = 1 in cui le prestazioni del modello sono coerenti con quella di un modello casuale. In generale, la curva di accuratezza per un buon modello è superiore a quella del grafico e più lontano dall'asse x, mostrando che quando il modello è più sicuro nelle stime che esegue molte volte meglio di un'ipotesi casuale.
Suggerimento
Per gli esperimenti di classificazione, ogni grafico a linee prodotto per i modelli di Machine Learning automatizzato può essere usato per valutare il modello per classe o mediato su tutte le classi. È possibile passare da una visualizzazione all'altra facendo clic sulle etichette di classe nella legenda a destra del grafico.
Curva di accuratezza per un modello valido
Curva di accuratezza per un modello non valido
Curva di calibrazione
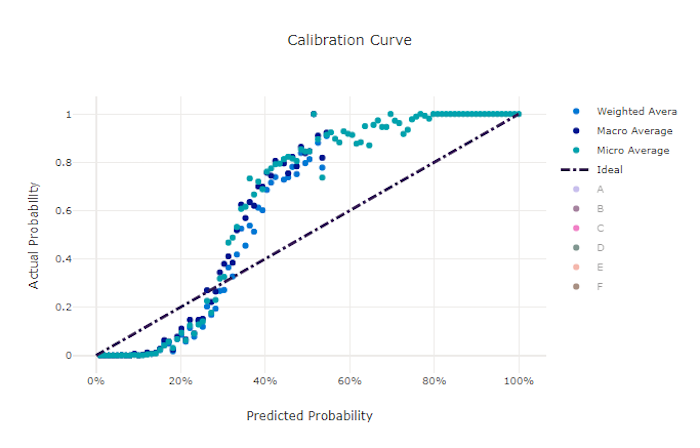
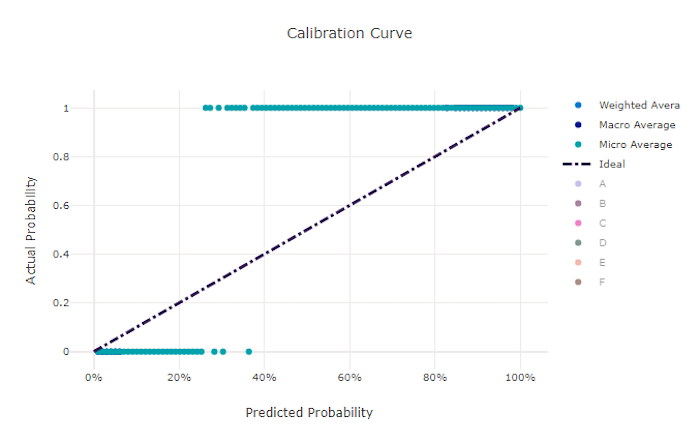
La curva di calibrazione traccia la fiducia di un modello nelle stime rispetto alla percentuale di campioni positivi a ogni livello di confidenza. Un modello ben calibrato classifica correttamente il 100% delle stime a cui assegna un 100% di attendibilità, il 50% delle stime assegna il 50% di confidenza, il 20% delle stime assegna un'attendibilità del 20% e così via. Un modello perfettamente calibrato ha una curva di calibrazione che segue la linea y = x in cui il modello stima perfettamente la probabilità che i campioni appartengano a ogni classe.
Un modello con elevata attendibilità prevede probabilità vicine a zero e uno, raramente non essendo incerto sulla classe di ogni campione e la curva di calibrazione è simile a "S". Un modello con ridotta attendibilità assegna una probabilità inferiore in media alla classe che stima e la curva di calibrazione associata ha un aspetto simile a "S". La curva di calibrazione non illustra la capacità di un modello di classificare correttamente, ma la sua capacità di assegnare correttamente l'attendibilità alle stime. Un modello non valido può comunque avere una buona curva di calibrazione se il modello assegna correttamente bassa attendibilità e incertezza elevata.
Nota
La curva di calibrazione è sensibile al numero di campioni, quindi un piccolo set di convalida può produrre risultati rumorosi che possono essere difficili da interpretare. Questo non significa necessariamente che il modello non sia ben calibrato.
Curva di calibrazione per un modello valido
Curva di calibrazione per un modello non valido
Metriche di regressione/previsione
Il Machine Learning automatizzato calcola le stesse metriche delle prestazioni per ogni modello generato, indipendentemente dal fatto che si tratti di un esperimento di regressione o previsione. Queste metriche subiscono anche la normalizzazione per consentire il confronto tra i modelli sottoposti a training sui dati con intervalli diversi. Per altre informazioni, vedere normalizzazione delle metriche.
La tabella seguente riepiloga le metriche delle prestazioni del modello generate per gli esperimenti di regressione e previsione. Analogamente alle metriche di classificazione, queste metriche si basano anche sulle implementazioni di scikit-learn. La documentazione appropriata di scikit-learn è collegata di conseguenza, nel campo Calcolo.
| Metrico | Descrizione | Calcolo |
|---|---|---|
| varianza spiegata | La varianza illustrata misura la misura in cui un modello rappresenta la variazione nella variabile di destinazione. Si tratta della riduzione percentuale della varianza dei dati originali rispetto alla varianza degli errori. Quando la media degli errori è 0, è uguale al coefficiente di determinazione (vedere r2_score nel grafico successivo). Obiettivo: più vicino a 1 meglio Intervallo: (-inf, 1] |
Calcolo |
| errore assoluto medio | Errore assoluto medio è il valore stimato del valore assoluto della differenza tra il target e la stima. Obiettivo: più vicino a 0 meglio Intervallo: [0, inf) Tipi: mean_absolute_error normalized_mean_absolute_error, mean_absolute_error diviso per l’intervallo dei dati. |
Calcolo |
| errore percentuale assoluto medio | L'errore percentuale assoluta media (MAPE) è una misura della differenza media tra un valore stimato e il valore effettivo. Obiettivo: più vicino a 0 meglio Intervallo: [0, inf) |
|
| errore_assoluto_mediano | median_absolute_error è il valore mediano di tutte le differenze assolute tra il target e la stima. Questa perdita è significativa per gli outlier. Obiettivo: più vicino a 0 meglio Intervallo: [0, inf) Tipi: median_absolute_errornormalized_median_absolute_error: median_absolute_error diviso per l'intervallo dei dati. |
Calcolo |
| r2_score | R2 (coefficiente di determinazione) misura la riduzione proporzionale dell'errore quadratico medio rispetto alla varianza totale dei dati osservati. Obiettivo: più vicino a 1 meglio Intervallo: [-1, 1] Nota: R2 spesso ha l'intervallo (-inf, 1]. L'MSE può essere maggiore della varianza osservata, pertanto R2 può avere valori negativi arbitrariamente elevati, a seconda dei dati e delle stime del modello. Le clip di ML automatizzate hanno segnalato R2 punteggi a -1, quindi un valore pari a -1 per R2 probabilmente significa che il punteggio R2 è minore di -1. Prendere in considerazione gli altri valori delle metriche e le proprietà dei dati quando si interpreta un punteggio negativo R2. |
Calcolo |
| errore quadratico medio radice | Radice errore quadratico medio (RMSE) è la radice quadrata della differenza quadratica stimata tra il target e la stima. Per uno strumento di stima non distorto, RMSE è uguale alla deviazione standard. Obiettivo: più vicino a 0 meglio Intervallo: [0, inf) Tipi: root_mean_squared_error normalized_root_mean_squared_error: root_mean_squared_error diviso per l'intervallo dei dati. |
Calcolo |
| errore quadratico medio logaritmico | La radice dell'errore logaritmico quadratico medio è la radice quadrata dell'errore logaritmico quadratico previsto. Obiettivo: più vicino a 0 meglio Intervallo: [0, inf) Tipi: root_mean_squared_log_error normalized_root_mean_squared_log_error: root_mean_squared_log_error diviso per l'intervallo dei dati. |
Calcolo |
| correlazione_di_spearman | La correlazione di Spearman è una misura non parametrica della monotonicità della relazione tra due set di dati. A differenza della correlazione di Pearson, quella di Spearman non presuppone che entrambi i set di dati siano normalmente distribuiti. Come altri coefficienti di correlazione, Spearman varia da -1 a + 1, con 0 che implica l'assenza di correlazione. Le correlazioni con coefficiente -1 o 1 implicano una relazione monotonica esatta. Spearman è una metrica di correlazione rdi ordine di rango che indica che le modifiche ai valori stimati o effettivi non cambieranno il risultato di Spearman se non modificano l'ordine di classificazione dei valori stimati o effettivi. Obiettivo: più vicino a 1 meglio Intervallo: [-1, 1] |
Calcolo |
Normalizzazione delle metriche
Il Machine Learning automatizzato normalizza le metriche di regressione e previsione che consentono il confronto tra i modelli sottoposti a training sui dati con intervalli diversi. Un modello sottoposto a training su dati con un intervallo maggiore ha un errore superiore rispetto allo stesso modello sottoposto a training sui dati con un intervallo più piccolo, a meno che tale errore non venga normalizzato.
Anche se non esiste alcun metodo standard per la normalizzazione delle metriche degli errori, il ML automatizzato adotta l'approccio comune di dividere l'errore in base all'intervallo di dati: normalized_error = error / (y_max - y_min)
Nota
L'intervallo di dati non viene salvato con il modello. Se si esegue l'inferenza con lo stesso modello in un set di test di controllo, y_min e y_max possono cambiare in base ai dati di test e le metriche normalizzate potrebbero non essere usate direttamente per confrontare le prestazioni del modello sui set di training e di test. È possibile passare il valore di y_min e y_max dal set di training per rendere il confronto equo.
Metriche di previsione: normalizzazione e aggregazione
Il calcolo delle metriche per la valutazione del modello di previsione richiede alcune considerazioni speciali quando i dati contengono più serie temporali. Esistono due opzioni naturali per l'aggregazione delle metriche su più serie:
- Una media di macro in cui alle metriche di valutazione di ogni serie viene assegnato un peso uguale,
- Una media di micro in cui le metriche di valutazione per ogni stima hanno un peso uguale.
Questi casi presentano analogie dirette con media di macro e di micro in classificazione multiclasse.
La distinzione tra media di macro e di micro può essere importante quando si seleziona una metrica primaria per la selezione del modello. Si consideri, ad esempio, uno scenario di vendita al dettaglio in cui si vuole prevedere la domanda per una selezione di prodotti consumer. Alcuni prodotti vendono a volumi più elevati di altri. Se si sceglie un RMSE con media di micro come metrica primaria, è possibile che gli elementi con volume elevato contribuiscono alla maggior parte dell'errore di modellazione e, quindi, dominano la metrica. L'algoritmo di selezione del modello potrebbe favorire i modelli con maggiore accuratezza sugli elementi con volumi elevati rispetto a quelli con volume ridotto. Al contrario, un RMSE normalizzato con macro fornisce agli elementi con volume ridotto un peso approssimativamente uguale agli elementi con volumi elevati.
La tabella seguente elenca quale delle metriche di previsione di AutoML usa media di macro e di micro:
| Media di macro | Media di micro |
|---|---|
normalized_mean_absolute_error, normalized_median_absolute_error, normalized_root_mean_squared_errornormalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, root_mean_squared_log_errorr2_score, explained_variance, , spearman_correlationmean_absolute_percentage_error |
Si noti che le metriche con media di macro normalizzano ogni serie separatamente. Le metriche normalizzate di ogni serie vengono quindi calcolate in media per dare il risultato finale. La scelta corretta tra macro e micro dipende dallo scenario aziendale, ma in genere è consigliabile usare normalized_root_mean_squared_error.
Residui
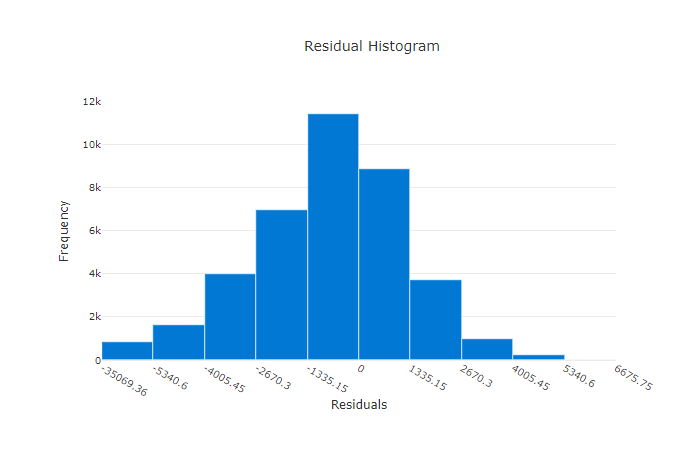
Il grafico dei residui è un istogramma degli errori di stima (residui) generati per esperimenti di regressione e previsione. I residui vengono calcolati come y_predicted - y_true per tutti i campioni e quindi visualizzati come istogramma per mostrare la distorsione del modello.
In questo esempio, entrambi i modelli sono leggermente distorti per prevedere un valore inferiore al valore effettivo. Questo non è insolito per un set di dati con una distribuzione asimmetrica di destinazioni effettive, ma indica prestazioni del modello peggiori. Un buon modello ha una distribuzione dei residui che raggiunge il picco a zero con pochi residui agli estremi. Un modello peggiore ha una distribuzione dei residui distribuiti con un minor numero di campioni intorno allo zero.
Grafico dei residui per un modello valido
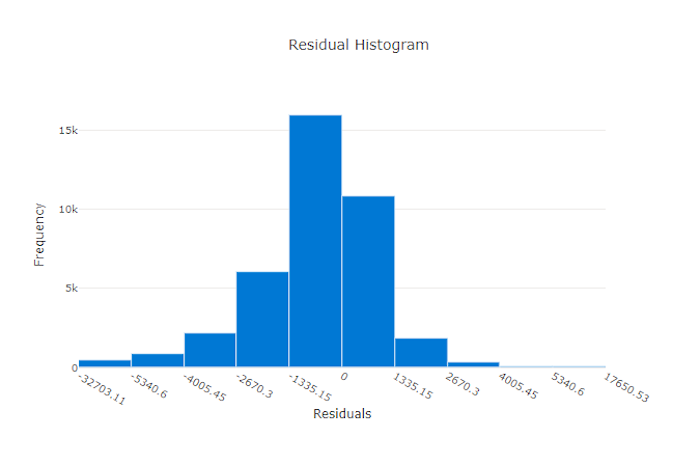
Grafico dei residui per un modello non valido
Confronto tra valori previsti ed effettivi
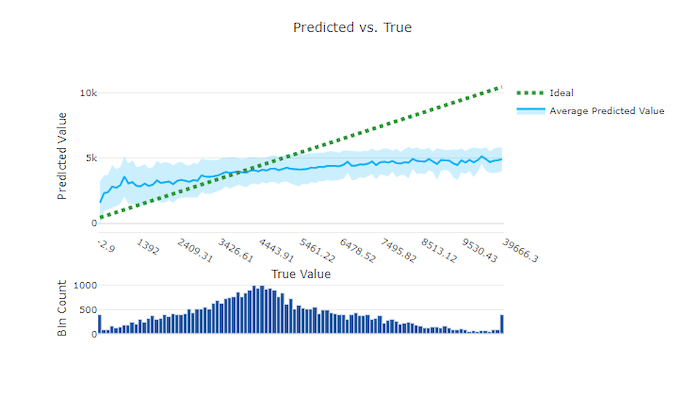
Per l'esperimento di regressione e previsione, il grafico stimato e true traccia la relazione tra la funzionalità di destinazione (valori true/effettivi) e le stime del modello. I valori true vengono inseriti nel bining lungo l'asse x e per ogni contenitore viene tracciato il valore stimato medio con barre di errore. In questo modo è possibile verificare se un modello è distorto rispetto alla stima di determinati valori. La linea visualizza la stima media e l'area ombreggiata indica la varianza delle stime intorno a tale media.
Spesso, il valore true più comune ha le stime più accurate con la varianza più bassa. La distanza della linea di tendenza dalla linea di y = x ideale in cui sono presenti pochi valori reali è una buona misura delle prestazioni del modello sugli outlier. È possibile usare l'istogramma nella parte inferiore del grafico per determinare la distribuzione effettiva dei dati. L'inclusione di altri esempi di dati in cui la distribuzione è di tipo sparse può migliorare le prestazioni del modello sui dati non visualizzati.
In questo esempio si noti che il modello migliore ha una linea stimata o true più vicina alla linea ideale y = x.
Grafico stimato e true per un modello valido
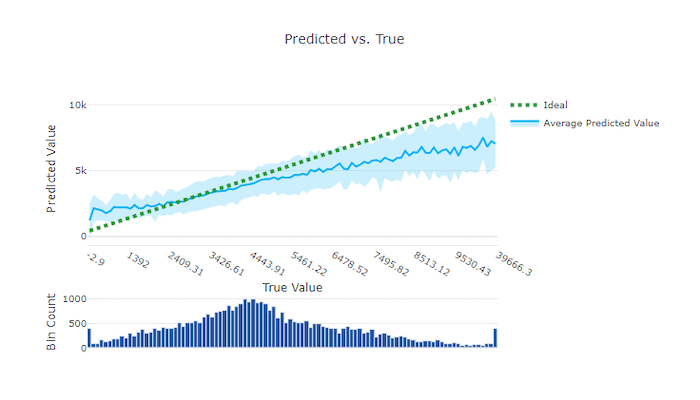
Grafico stimato e true per un modello non valido
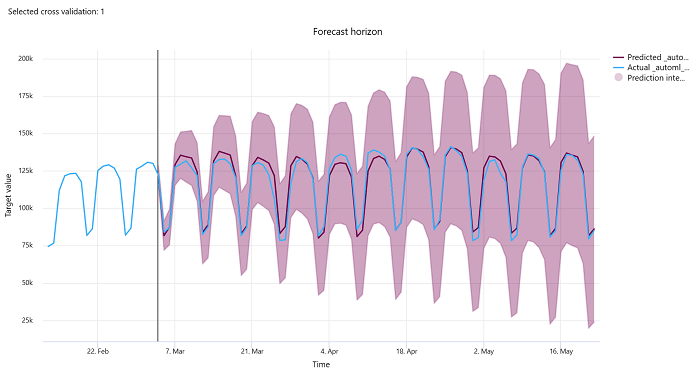
Orizzonte di previsione
Per gli esperimenti di previsione, il grafico dell'orizzonte di previsione traccia la relazione tra i modelli stimati e i valori effettivi mappati nel tempo per ogni riduzione della convalida incrociata, fino a cinque riduzioni. L'asse x esegue il mapping del tempo in base alla frequenza specificata durante la configurazione del training. La linea verticale nel grafico contrassegna il punto dell'orizzonte di previsione definito anche linea dell'orizzonte, ovvero il periodo di tempo in cui si desidera iniziare a generare stime. A sinistra della linea dell'orizzonte di previsione, è possibile visualizzare i dati di training cronologici per visualizzare meglio le tendenze passate. A destra dell'orizzonte di previsione, è possibile visualizzare le stime (la linea viola) rispetto ai valori effettivi (la linea blu) per le diverse riduzioni di convalida incrociata e gli identificatori di serie temporali. L'area viola ombreggiata indica gli intervalli di confidenza o la varianza delle stime intorno a tale media.
È possibile scegliere quali combinazioni di identificatori di serie temporali e di convalida incrociata visualizzare facendo clic sull'icona a forma di matita di modifica nell'angolo superiore destro del grafico. Selezionare tra le prime cinque riduzioni di convalida incrociata e fino a 20 identificatori di serie temporali diversi per visualizzare il grafico per le varie serie temporali.
Importante
Questo grafico è disponibile nell'esecuzione del training per i modelli generati dai dati di training e convalida, nonché nell'esecuzione del test in base ai dati di training e ai dati di test. Sono consentiti fino a 20 punti dati prima e fino a 80 punti dati dopo l'origine della previsione. Per i modelli DNN, questo grafico nell'esecuzione del training mostra i dati dell'ultimo periodo, ad esempio dopo il training completo del modello. Questo grafico nell'esecuzione del test può avere gap prima della linea dell'orizzonte se i dati di convalida sono stati forniti in modo esplicito durante l'esecuzione del training. Ciò è dovuto al fatto che i dati di training e i dati di test vengono usati nell'esecuzione del test lasciando i dati di convalida che causano lacune.
Metriche per i modelli di immagine (anteprima)
Machine Learning automatizzato usa le immagini del set di dati di convalida per valutare le prestazioni del modello. Le prestazioni del modello sono misurate a un epoch-level per comprendere il progresso del training. Un periodo è trascorso quando un intero set di dati viene passato avanti e indietro attraverso la rete neurale esattamente una volta.
Metriche di classificazione delle immagini
La metrica primaria per la valutazione è accuratezza per i modelli di classificazione binaria e multiclasse e IoU (Intersection over Union, Intersezione su Unione) per i modelli di classificazione con più etichette. Le metriche di classificazione per i modelli di classificazione delle immagini sono uguali a quelle definite nella sezione metrica di classificazione. Vengono registrati anche i valori di perdita associati a un periodo che consentono di monitorare l'avanzamento del training e determinare se il modello è di over-fitting o di under-fitting.
Ogni stima di un modello di classificazione è associata a un punteggio di attendibilità, che indica il livello di attendibilità con cui è stata eseguita la stima. Per impostazione predefinita, i modelli di classificazione delle immagini con etichetta multipla vengono valutati con una soglia di punteggio pari a 0,5, il che significa che solo le stime con almeno questo livello di attendibilità vengono considerate come una stima positiva per la classe associata. La classificazione multiclasse non usa una soglia di punteggio, ma la classe con il punteggio di attendibilità massimo viene considerata come la stima.
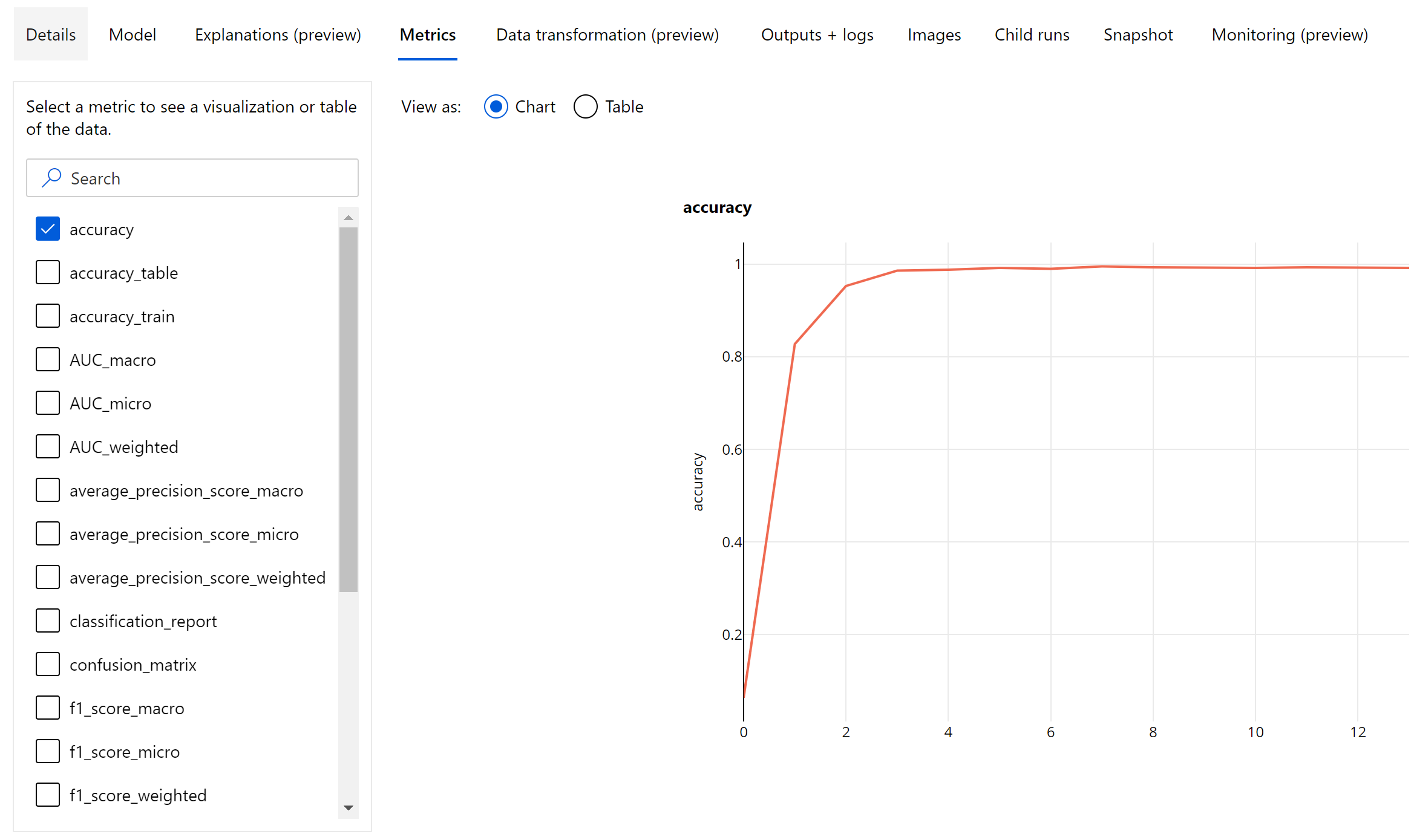
Metriche epoch-level per la classificazione delle immagini
A differenza delle metriche di classificazione per i set di dati tabulari, i modelli di classificazione delle immagini registrano tutte le metriche di classificazione a livello di periodo, come illustrato di seguito.
Metriche di riepilogo per la classificazione delle immagini
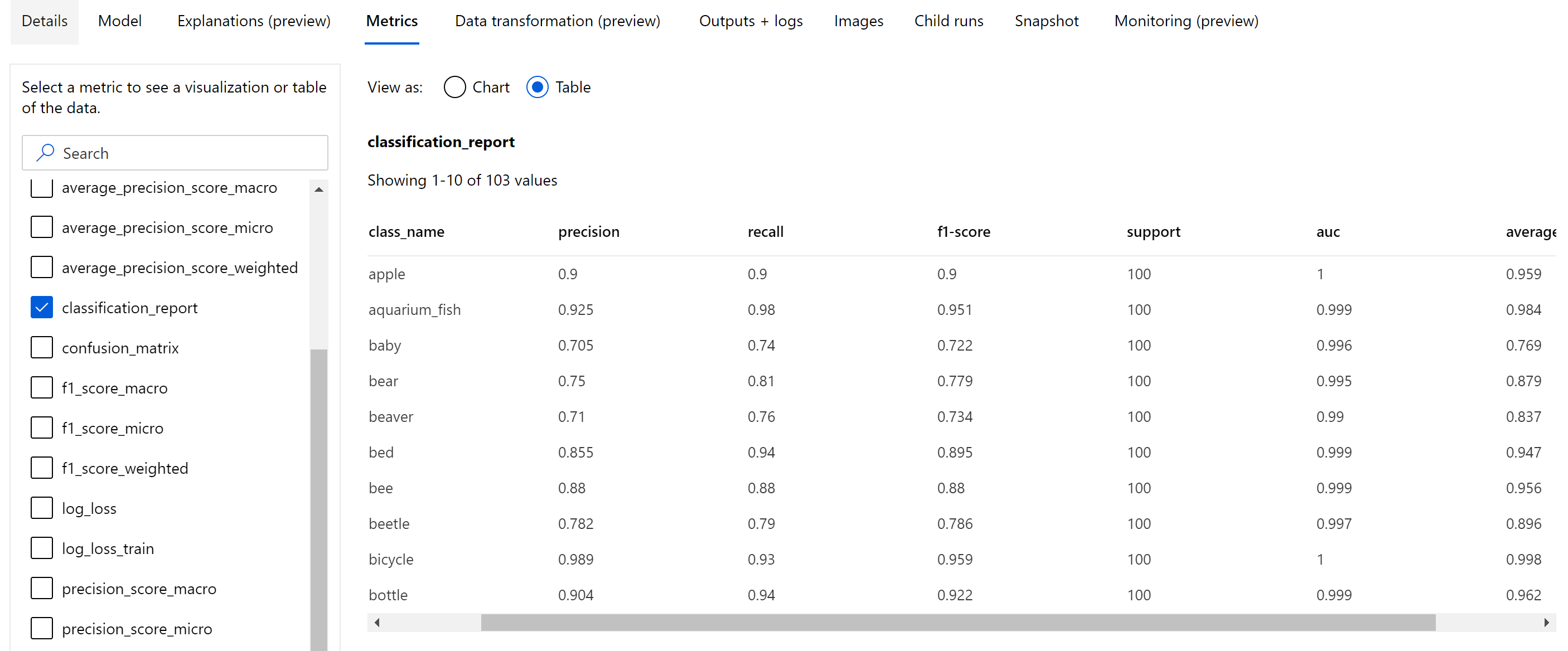
Oltre alle metriche scalari registrate a livello di periodo, il modello di classificazione delle immagini registra anche metriche di riepilogo come matrice di confusione, grafici di classificazione tra cui curva ROC, curva di richiamo della precisione e rapporto di classificazione per il modello dal periodo migliore in cui si ottiene il punteggio di metrica primaria (accuratezza) più alto.
Il report di classificazione fornisce i valori a livello di classe per metriche come precisione, richiamo, punteggio f1, supporto, auc e average_precision con vari livelli di media: micro, macro e ponderata come illustrato di seguito. Fare riferimento alle definizioni delle metriche nella sezione relativa alle metriche di classificazione.
Metriche di rilevamento degli oggetti e segmentazione dell'istanza
Ogni stima da un modello di rilevamento di oggetti immagine o segmentazione dell'istanza è associata a un punteggio di attendibilità.
Le stime con punteggio di attendibilità maggiore della soglia di punteggio vengono restituite come stime e usate nel calcolo delle metriche, il valore predefinito di cui è specifico il modello e può essere indicato dalla pagina di ottimizzazione degli iperparametri (iperparametro box_score_threshold).
Il calcolo delle metriche di un modello di rilevamento di oggetti immagine e segmentazione dell'istanza si basa su una misura di sovrapposizione definita da una metrica denominata IoU (Intersection over Union, Intersezione sull'unione) calcolata dividendo l'area di sovrapposizione tra la verità del terreno e le stime in base all'area di unione delle stime. L'IoU calcolata da ogni stima viene confrontata con una soglia di sovrapposizione denominata soglia di IoU che determina la quantità di una stima che deve sovrapporsi a una verità di base annotata dall'utente per essere considerata una stima positiva. Se l'IoU calcolata dalla stima è inferiore alla soglia di sovrapposizione, la stima non verrà considerata come una stima positiva per la classe associata.
La metrica primaria per la valutazione dei modelli di rilevamento oggetti immagine e segmentazione dell'istanza è il precisione media media (mAP). MùmAP è il valore medio della precisione media (AP) in tutte le classi. I modelli di rilevamento oggetti automatizzati di Machine Learning supportano il calcolo di mAP usando i due metodi più diffusi seguenti.
Metriche Pascal VOC:
Il mAP Pascal VOC è il modo predefinito di calcolo mAP per i modelli di segmentazione di istanze/rilevamento oggetti. Il metodo mAP dello stile Pascal VOC calcola l'area sotto una versione della curva di richiamo della precisione. Primo p(rᵢ), che è precisione al richiamo i viene calcolato per tutti i valori di richiamo univoci. p(ri) viene quindi sostituito con la precisione massima ottenuta per qualsiasi richiamo r' >= rᵢ. Il valore di precisione diminuisce in modo monotonico in questa versione della curva. La metrica mAP di Pascal VOC viene valutata per impostazione predefinita con una soglia di IoU pari a 0,5. Una spiegazione dettagliata di questo concetto è disponibile in questo blog.
Metriche COCO:
Il metodo di valutazione COCO usa un metodo interpolato a 101 punti per il calcolo delle API insieme alla media di oltre dieci soglie di IoU. AP@[.5:.95] corrisponde all'AP medio per IoU da 0,5 a 0,95 con dimensioni di passaggio pari a 0,05. Il ML automatizzato registra tutte le 12 metriche definite dal metodo COCO, tra cui l'API e l'AR(richiamo medio) su varie scale nei log applicazioni, mentre l'interfaccia utente delle metriche mostra solo mAP a una soglia di IoU pari a 05.
Suggerimento
La valutazione del modello di rilevamento oggetti immagine può usare le metriche coco se l'iperparametro validation_metric_type è impostato su "coco", come illustrato nella sezione ottimizzazione degli iperparametri.
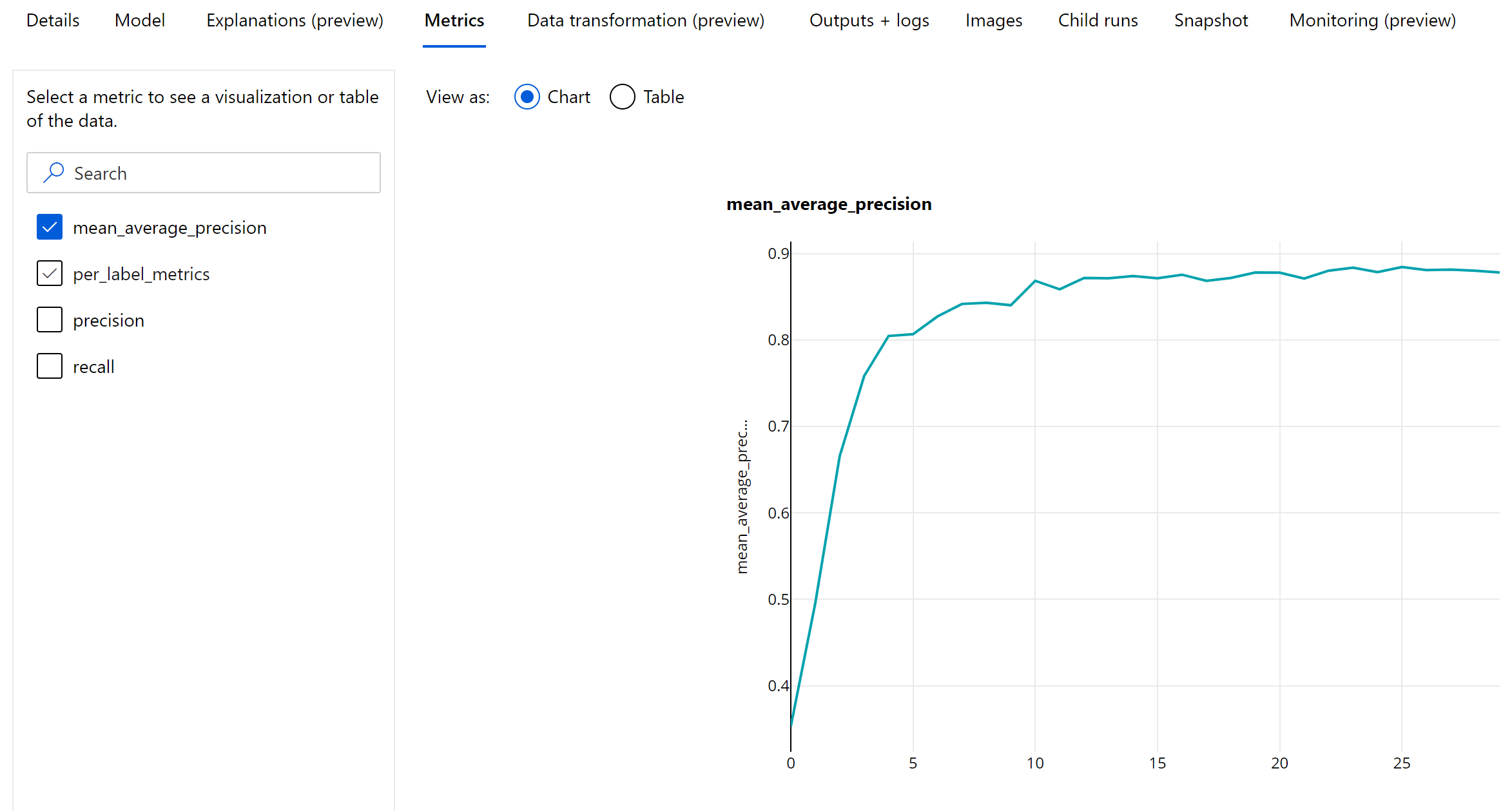
Metriche epoch-level per il rilevamento degli oggetti e la segmentazione dell'istanza
I valori mAP, precisione e richiamo vengono registrati a livello epoch-level per i modelli di segmentazione di istanza/rilevamento oggetti immagine. Le metriche mAP, precisione e richiamo vengono registrate anche a livello di classe con il nome "per_label_metrics". “per_label_metrics” deve essere visualizzato come tabella.
Nota
Le metriche epoch-level per precisione, richiamo e per_label_metrics non sono disponibili quando si usa il metodo “coco”.
Dashboard di intelligenza artificiale responsabile per il modello AutoML consigliato (anteprima)
Il dashboard di Intelligenza artificiale responsabile di Azure Machine Learning offre un'unica interfaccia che consente di implementare l'intelligenza artificiale responsabile in pratica in modo efficace ed efficiente. Il dashboard di intelligenza artificiale responsabile è supportato solo usando dati tabulari ed è supportato solo nei modelli di classificazione e regressione. Riunisce diversi strumenti di Intelligenza artificiale responsabile avanzati nelle aree di:
- Valutazione delle prestazioni e dell'equità del modello
- esplorazione dei dati
- Interpretabilità del Machine Learning
- Analisi degli errori
Anche se le metriche e i grafici di valutazione del modello sono utili per misurare la qualità generale di un modello, le operazioni come l'ispezione dell'equità del modello, la visualizzazione delle spiegazioni (nota anche come il set di dati che include un modello usato per eseguire le stime), l'analisi degli errori e dei potenziali punti ciechi sono essenziali quando si pratica l'intelligenza artificiale responsabile. Questo è il motivo per cui il ML automatizzato fornisce un dashboard di intelligenza artificiale responsabile per consentire di osservare varie informazioni dettagliate per il modello. Vedere come visualizzare il dashboard di intelligenza artificiale responsabile in studio di Azure Machine Learning.
Scopri come generare questo dashboard tramite l'interfaccia utente o l'SDK.
Spiegazioni dei modelli e importanza delle funzionalità
Anche se le metriche e i grafici di valutazione del modello sono utili per misurare la qualità generale di un modello, l'ispezione delle caratteristiche di un set di dati usato da un modello per eseguire stime è essenziale quando si pratica l'intelligenza artificiale responsabile. Ecco perché il Machine Learning automatizzato fornisce un dashboard di spiegazioni del modello per misurare e segnalare i contributi relativi delle funzionalità del set di dati. Vedere come visualizzare il dashboard delle spiegazioni in studio di Azure Machine Learning.
Nota
L'interpretazione, la spiegazione migliore del modello, non è disponibile per esperimenti di previsione automatizzati di ML che consigliano gli algoritmi seguenti come insieme o modello migliore:
- TCNForecaster
- AutoArima
- EsponenzialeSmoothing
- Profeta
- Media
- Ingenuo
- Media stagionale
- Naive stagionale
Passaggi successivi
- Provare i notebook campione di spiegazione del modello di Machine Learning automatizzato.
- Per domande specifiche sul Machine Learning automatizzato, contattare askautomatedml@microsoft.com.