Eseguire gli endpoint batch da Azure Data Factory
SI APPLICA A: Estensione ml dell'interfaccia della riga di comando di Azure v2 (corrente)SDK Python azure-ai-ml v2 (corrente)
Estensione ml dell'interfaccia della riga di comando di Azure v2 (corrente)SDK Python azure-ai-ml v2 (corrente)
I Big Data necessitano di un servizio che possa orchestrare e rendere operativi i processi per ottimizzare questi enormi archivi di dati non elaborati trasformandoli in informazioni aziendali di utilità pratica. Azure Data Factory è un servizio cloud gestito che è stato creato per questi complessi progetti ibridi di estrazione, trasformazione e caricamento (ETL), estrazione, caricamento e trasformazione (ELT) e integrazione di dati.
Azure Data Factory consente la creazione di pipeline in grado di orchestrare più trasformazioni di dati e gestirle come singola unità. Gli endpoint batch sono un candidato eccellente da usare come passaggio in tale flusso di lavoro di elaborazione. Questo esempio spiega come usare gli endpoint batch nelle attività di Azure Data Factory basandosi sull'attività di richiamo Web e sull'API REST.
Prerequisiti
Questo esempio presuppone che sia stato distribuito correttamente un modello come endpoint batch. In particolare, viene usato il classificatore di condizioni cardiache creato nell'esercitazione Uso di modelli MLflow nelle distribuzioni batch.
Una risorsa di Azure Data Factory creata e configurata. Se non è ancora stato creato il data factory, seguire la procedura descritta in Avvio rapido: creare un data factory usando il portale di Azure e Azure Data Factory Studio per crearne uno.
Dopo averlo creato, passare al data factory nel portale di Azure:
Selezionare Apri nel riquadro Apri Azure Data Factory Studio per avviare l'applicazione Integrazione dei dati in una scheda separata.
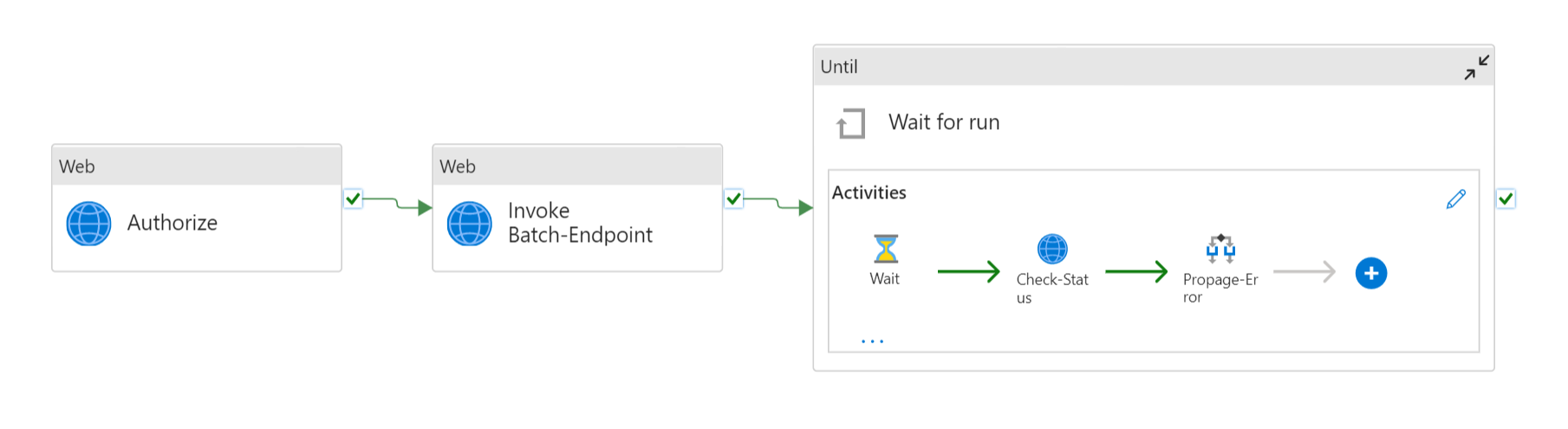
Autenticazione per gli endpoint batch
Azure Data Factory può richiamare le API REST degli endpoint batch usando l'attività Richiamo Web. Gli endpoint batch supportano Microsoft Entra ID per l'autorizzazione, quindi la richiesta inviata alle API richiede una corretta gestione dell'autenticazione.
È possibile usare un'entità servizio o un'identità gestita per eseguire l'autenticazione per gli endpoint batch. È consigliabile usare un'identità gestita in quanto semplifica l'uso dei segreti.
È possibile usare l'identità gestita di Azure Data Factory per comunicare con gli endpoint batch. In questo caso, basta accertarsi che la risorsa di Azure Data Factory sia stata distribuita con un'identità gestita.
Se una risorsa di Azure Data Factory non esiste o è già stata distribuita senza un'identità gestita, effettuare la procedura seguente per crearla: Identità gestita per Azure Data Factory.
Avviso
Tenere presente che in Azure Data Factory non è possibile modificare l'identità della risorsa dopo averla distribuita. Dopo aver creato la risorsa, sarà necessario crearla nuovamente se occorre modificarne l'identità.
Dopo la distribuzione, concedere l'accesso per l'identità gestita della risorsa creata nell'area di lavoro di Azure Machine Learning, come descritto in Concedere l'accesso. In questo esempio, l'entità servizio richiederà:
- Autorizzazione nell'area di lavoro per la lettura delle distribuzioni batch e l’esecuzione di azioni su tali distribuzioni.
- Autorizzazioni per lettura/scrittura negli archivi dati.
- Autorizzazioni per la lettura in qualunque posizione cloud (account di archiviazione) indicata come input di dati.
Informazioni sulla pipeline
Verrà creata una pipeline in Azure Data Factory che può richiamare un determinato endpoint batch su alcuni dati. La pipeline comunicherà con gli endpoint batch di Azure Machine Learning usando REST. Per altre informazioni su come usare l'API REST per gli endpoint batch, vedere Creare processi e dati di input per gli endpoint batch.
La pipeline avrà un aspetto simile al seguente:
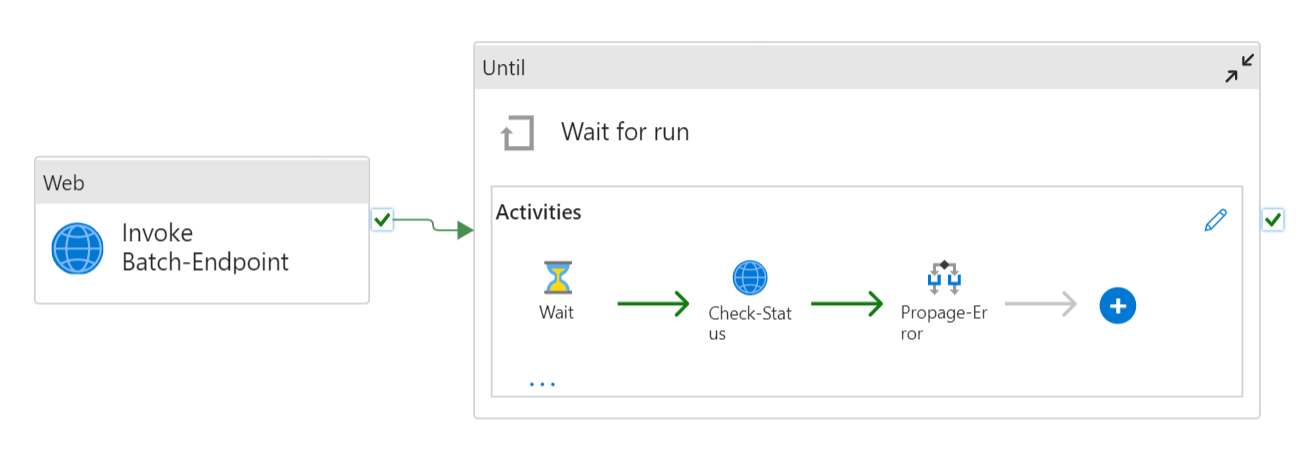
Si compone delle attività seguenti:
- Esegui endpoint batch: attività Web che usa l'URI dell'endpoint batch per richiamarlo. Passa l'URI dei dati di input in cui sono collocati i dati e il file di output previsto.
- Attendi processo: attività di ciclo che controlla lo stato del processo creato e ne attende il completamento come Completato o Non riuscito. Questa attività, a sua volta, usa le attività seguenti:
- Controlla stato: attività Web che esegue una query sullo stato della risorsa del processo restituita come risposta dell'attività Esegui endpoint batch.
- Attendi: attività di attesa che controlla la frequenza di polling dello stato del processo. Il valore predefinito è 120 (2 minuti).
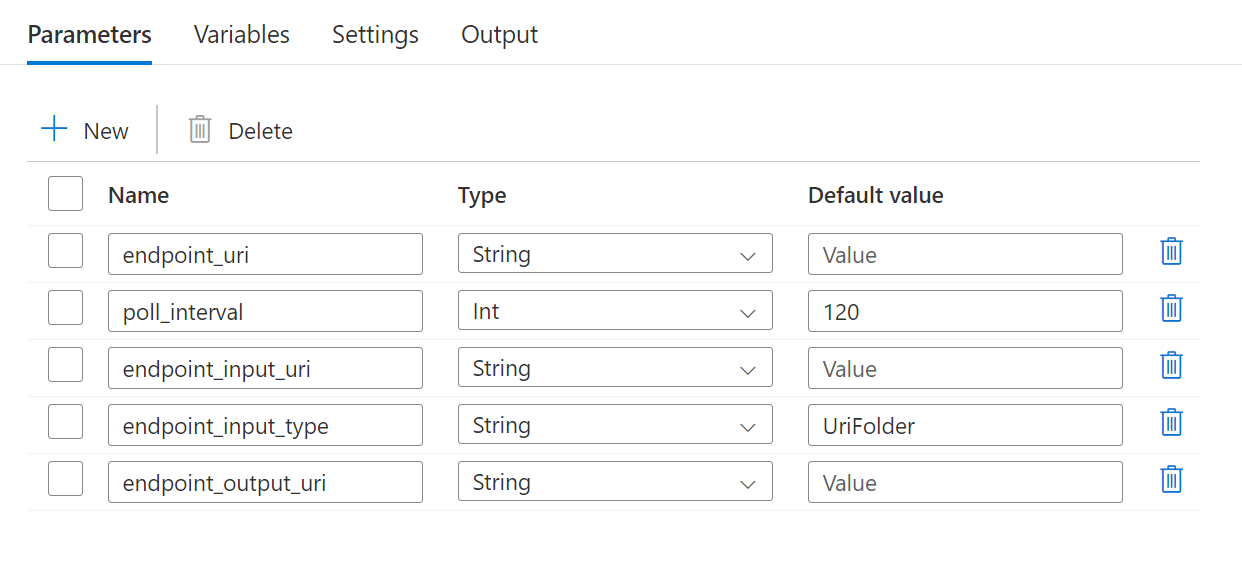
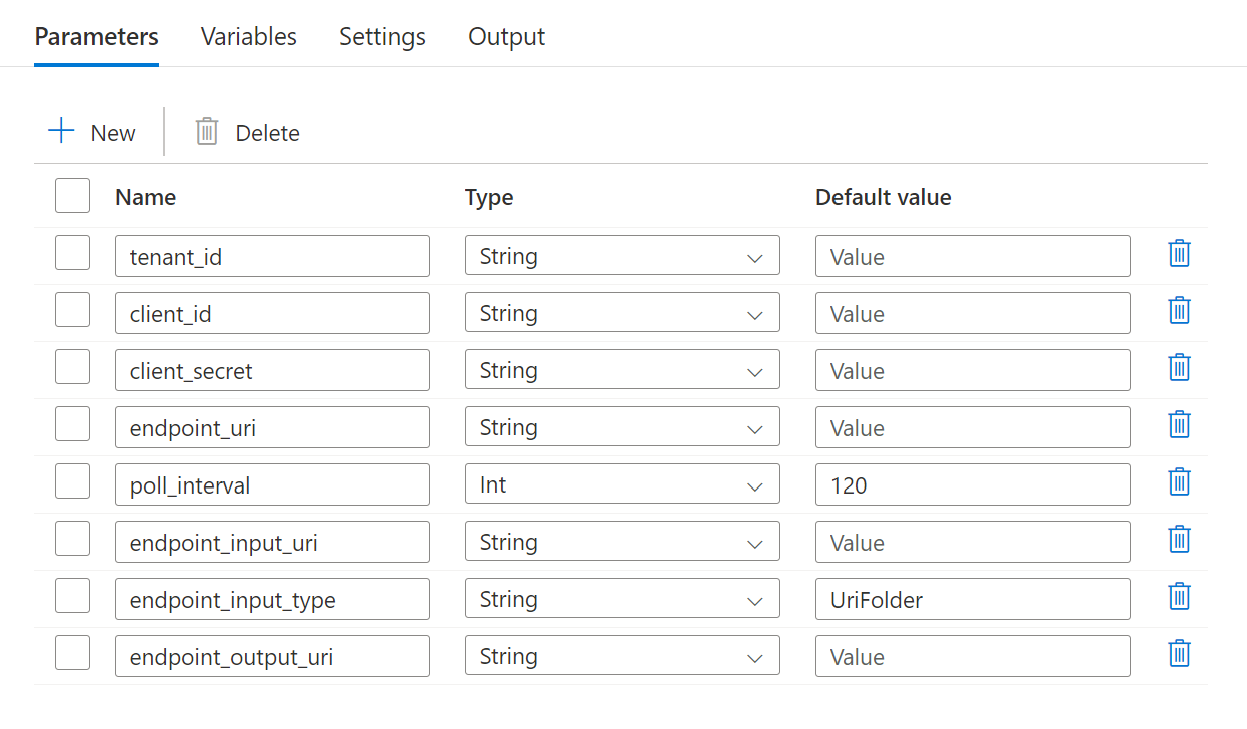
La pipeline richiede la configurazione dei parametri seguenti:
| Parametro | Descrizione | Valore di esempio |
|---|---|---|
endpoint_uri |
URI di assegnazione dei punteggi dell’endpoint | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
Numero di secondi di attesa prima del controllo dello stato di completamento del processo. Il valore predefinito è 120. |
120 |
endpoint_input_uri |
Dati di input dell'endpoint. Sono supportati più tipi di input di dati. Accertarsi che l'identità di gestione usata per l'esecuzione del processo possa accedere alla posizione sottostante. In alternativa, se si usano archivi dati, accertarsi che siano indicate le credenziali. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
Tipo dei dati di input che viene fornito. Attualmente gli endpoint batch supportano cartelle (UriFolder) e file (UriFile). Il valore predefinito è UriFolder. |
UriFolder |
endpoint_output_uri |
File di dati di output dell'endpoint. Deve essere un percorso di un file di output in un archivio dati collegato all'area di lavoro di Machine Learning. Non sono supportati altri tipi di URI. È possibile usare l'archivio dati predefinito di Azure Machine Learning, denominato workspaceblobstore. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |
Avviso
Tenere presente che endpoint_output_uri deve essere il percorso di un file che non esiste ancora. In caso contrario, l’esito del processo sarà negativo con l'errore indicante che il percorso esiste già.
Passaggi
Per creare questa pipeline in un’istanza di Azure Data Factory esistente e richiamare gli endpoint batch, effettuare la procedura seguente:
Accertarsi che l'ambiente di calcolo in cui è in esecuzione l'endpoint batch disponga delle autorizzazioni per il montaggio dei dati di Azure Data Factory come input. Tenere presente che l'accesso viene ancora concesso dall'identità che richiama l'endpoint (in questo caso Azure Data Factory). Tuttavia, l’ambiente di calcolo in cui viene eseguito l'endpoint batch deve disporre dell'autorizzazione per il montaggio dell'account di archiviazione fornito da Azure Data Factory. Per informazioni dettagliate, vedere Accesso ai servizi di archiviazione.
Aprire Azure Data Factory Studio e fare clic sul segno più in Risorse factory.
Selezionare Pipeline>Importa da modello di pipeline
Verrà chiesto di selezionare un file
zip. Usa il modello seguente se si usano identità gestite o quello seguente se si usa un'entità servizio.Nel portale verrà visualizzata un'anteprima della pipeline. Fare clic su Usa questo modello.
La pipeline verrà creata automaticamente con il nome Run-BatchEndpoint.
Configurare i parametri della distribuzione batch in uso:
Avviso
Prima di inviare un processo, accertarsi che sia stata configurata una distribuzione predefinita per l'endpoint batch. La pipeline creata richiamerà l'endpoint, per cui deve essere creata e configurata una distribuzione predefinita.
Suggerimento
Per una migliore riusabilità, usare la pipeline creata come modello e richiamarla dall'interno di altre pipeline di Azure Data Factory sfruttando l'attività Esegui pipeline. In tal caso, non configurare i parametri nella pipeline interna, ma passarli come parametri dalla pipeline esterna, come illustrato nell'immagine seguente:
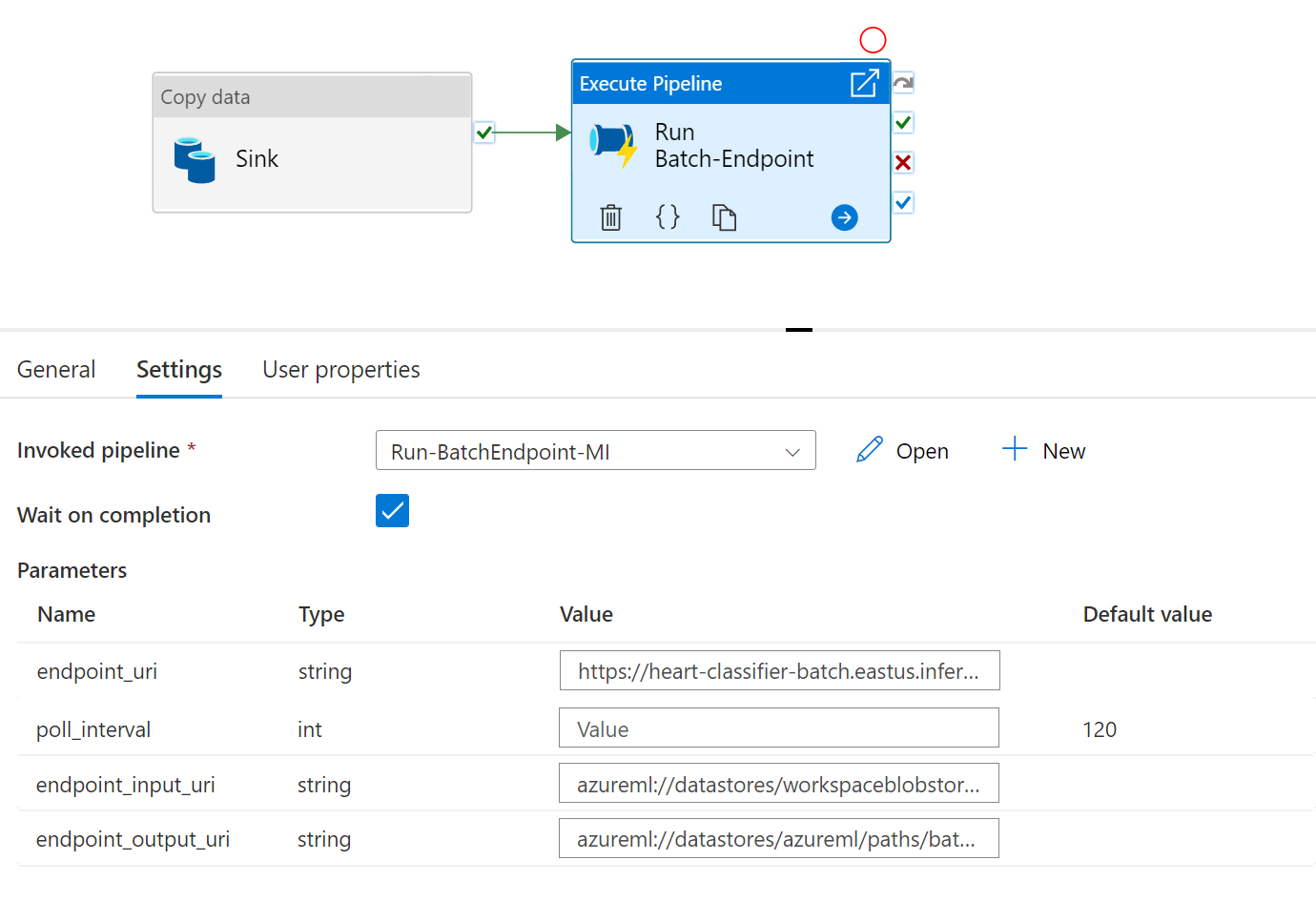
- La pipeline è pronta per l'uso.
Limiti
Quando si richiamano le distribuzioni batch di Azure Machine Learning, considerare le limitazioni seguenti:
Input dati
- Come input sono supportati solo gli archivi dati di Azure Machine Learning o gli account Archiviazione di Azure (Archiviazione BLOB di Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2). Se i dati di input si trovano in un'altra origine, usare l'attività Copy di Azure Data Factory prima dell'esecuzione del processo batch per il sink dei dati in un archivio compatibile.
- I processi degli endpoint batch non esplorano le cartelle annidate, per cui riescono a gestire strutture di cartelle annidate. Se i dati vengono distribuiti in più cartelle, tenere presente che sarà necessario appiattire la struttura.
- Accertarsi che lo script assegnazione dei punteggi fornito nella distribuzione possa gestire i dati come si prevede che vengano inseriti nel processo. Se il modello è MLflow, leggere la limitazione relativa al tipo di file al momento supportato in Uso di modelli MLflow nelle distribuzioni batch.
Output dei dati
- Al momento sono supportati solo archivi dati registrati di Azure Machine Learning. È consigliabile registrare l'account di archiviazione usato da Azure Data Factory come archivio dati in Azure Machine Learning. In questo modo sarà possibile eseguire la riscrittura nello stesso account di archiviazione da cui si esegue la lettura.
- Per gli output sono supportati solo gli account Archiviazione BLOB di Azure. Ad esempio, Azure Data Lake Storage Gen2 non è supportato come output nei processi di distribuzione batch. Se è necessario l’output dei dati in un percorso/sink diverso, usare l'attività Copy di Azure Data Factory dopo l'esecuzione del processo batch.