Tenere traccia degli esperimenti di Azure Databricks ML con MLflow e Azure Machine Learning
MLflow è una libreria open source per la gestione del ciclo di vita degli esperimenti di machine learning. È possibile usare MLflow per integrare Azure Databricks con Azure Machine Learning così da usare al meglio entrambi i prodotti.
In questo articolo, imparerai a:
- Le librerie necessarie per usare MLflow con Azure Databricks e Azure Machine Learning.
- Come tenere traccia delle esecuzioni di Azure Databricks con MLflow in Azure Machine Learning.
- Come registrare modelli con MLflow in modo che vengano registrati in Azure Machine Learning.
- Come distribuire e utilizzare i modelli registrati in Azure Machine Learning.
Prerequisiti
- Il pacchetto
azureml-mlflow, che gestisce la connettività con Azure Machine Learning, inclusa l'autenticazione. - Un'area di lavoro e un cluster Azure Databricks.
- Area di lavoro di Azure Machine Learning.
Vedere le informazioni sulle autorizzazioni di accesso necessarie per eseguire operazioni di MLflow nell'area di lavoro.
Notebook di esempio
Il repository Training di modelli in Azure Databricks e loro distribuzione di Azure Machine Learning illustra come eseguire il training di modelli in Azure Databricks e la distribuzione in Azure Machine Learning. Ciò descrive anche come tenere traccia degli esperimenti e dei modelli con l'istanza MLflow in Azure Databricks. Descrive come usare Azure Machine Learning per la distribuzione.
Installare le librerie
Per installare le librerie nel cluster:
Passare alla scheda Librerie e selezionare Installa nuovo.
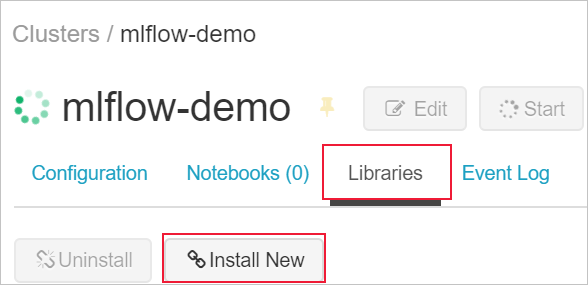
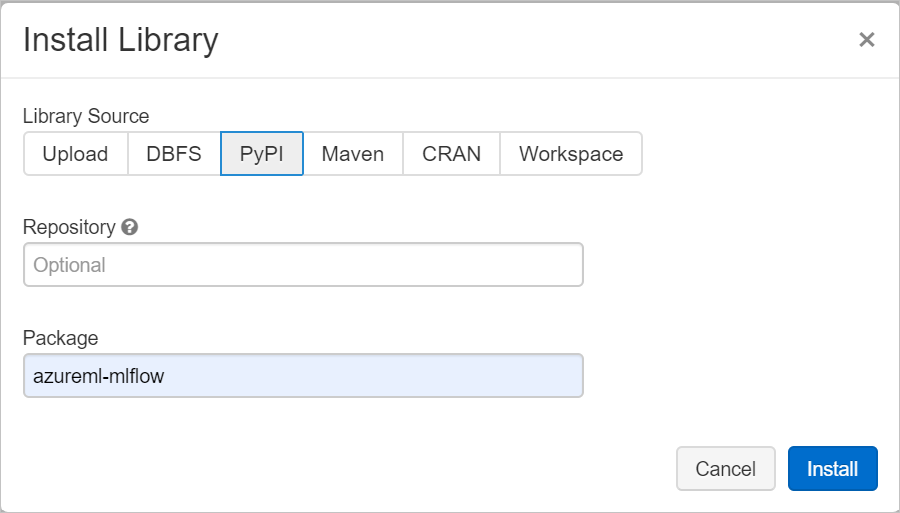
Nel campo Pacchetto digitare azureml-mlflow e quindi selezionare Installa. Ripetere questo passaggio, se necessario, per installare altri pacchetti aggiuntivi nel cluster per l'esperimento.
Tenere traccia delle esecuzioni di Azure Databricks con MLflow
È possibile configurare Azure Databricks per tenere traccia degli esperimenti con MLflow in due modi:
- Rilevamento sia nell'area di lavoro di Azure Databricks che in quella di Azure Machine Learning (doppio rilevamento)
- Rilevamento esclusivamente in Azure Machine Learning
Per impostazione predefinita, quando si collega l'area di lavoro di Azure Databricks, il rilevamento doppio viene configurato automaticamente.
Rilevamento doppio in Azure Databricks e Azure Machine Learning
Il collegamento dell'area di lavoro di Azure Databricks all'area di lavoro di Azure Machine Learning consente di tenere traccia dei dati degli esperimenti contemporaneamente nell'area di lavoro di Azure Machine Learning e nell’area di lavoro di Azure Databricks. Questa configurazione è denominata Rilevamento doppio.
Il rilevamento doppio in un'area di lavoro di Azure Machine Learning abilitata per il collegamento privato non è al momento supportato. Configurare invece il rilevamento esclusivo con l'area di lavoro di Azure Machine Learning.
Il rilevamento doppio non è attualmente supportato in Microsoft Azure gestito da 21Vianet. Configurare invece il rilevamento esclusivo con l'area di lavoro di Azure Machine Learning.
Per collegare l'area di lavoro di Azure Databricks a un'area di lavoro di Azure Machine Learning nuova o esistente:
Accedere al portale di Azure.
Passare alla pagina dell'area di lavoro di Azure Databricks Panoramica.
Selezionare Collegare l'area di lavoro di Azure Machine Learning.
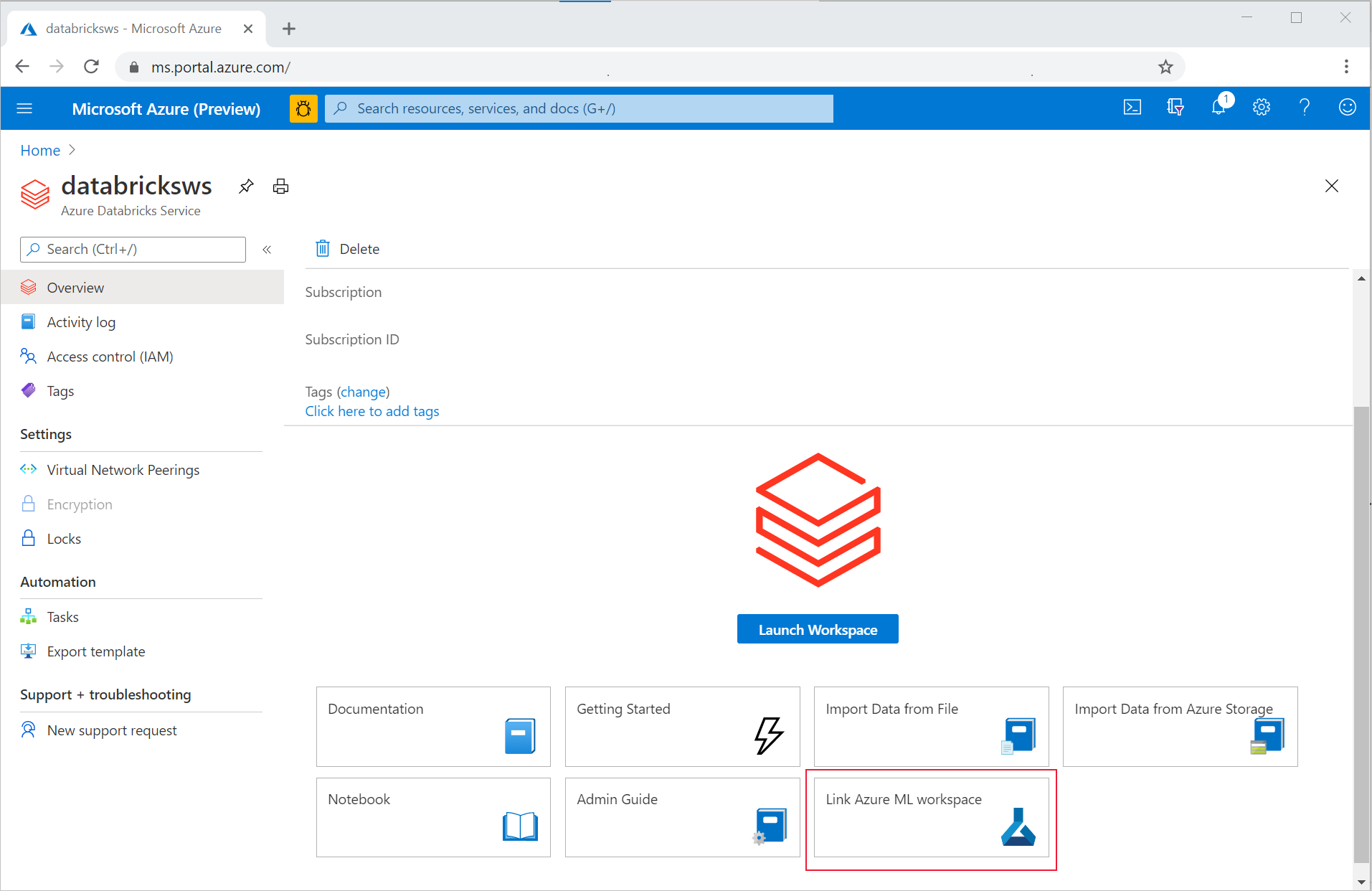

Dopo aver collegato l'area di lavoro di Azure Databricks all'area di lavoro di Azure Machine Learning, il rilevamento MLflow viene impostato automaticamente per tutte le posizioni seguenti:
- L'area di lavoro di Azure Machine Learning collegata.
- Area di lavoro di Azure Databricks originale.
È possibile usare MLflow in Azure Databricks nel modo consueto. L'esempio seguente imposta il nome dell'esperimento come avviene in genere in Azure Databricks e avvia la registrazione di alcuni parametri:
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
Nota
Diversamente da quanto avviene con il rilevamento, i registri dei modelli non supportano la registrazione di modelli contemporaneamente in Azure Machine Learning e in Azure Databricks. Per altre informazioni, vedere Registrare i modelli nel Registro di sistema con MLflow.
Rilevamento esclusivamente nell'area di lavoro di Azure Machine Learning
Se si preferisce gestire gli esperimenti in una posizione centralizzata, è possibile impostare il rilevamento di MLflow per tenere traccia esclusivamente nell'area di lavoro di Azure Machine Learning. Questa configurazione offre il vantaggio di abilitare un percorso più semplice per la distribuzione usando le opzioni di distribuzione di Azure Machine Learning.
Avviso
Per un'area di lavoro di Azure Machine Learning abilitata per il collegamento privato, è necessario distribuire Azure Databricks nella propria rete (aggiunta nella rete virtuale) per ottenere una connettività appropriata.
Configurare l'URI di rilevamento MLflow in modo che punti esclusivamente ad Azure Machine Learning, come illustrato nell'esempio seguente:
Configurare l'URI di rilevamento
Ottenere l'URI di rilevamento per la propria area di lavoro.
SI APPLICA A:
 estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Accedere e configurare la propria area di lavoro:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>È possibile ottenere l'URI di rilevamento usando il comando
az ml workspace.az ml workspace show --query mlflow_tracking_uri
Configurare l'URI di rilevamento.
Il metodo
set_tracking_uri()punta l'URI di rilevamento MLflow a tale URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)
Suggerimento
Quando si lavora con ambienti condivisi, ad esempio un cluster di Azure Databricks, un cluster di Azure Synapse Analytics o un cluster simile, è possibile impostare la variabile MLFLOW_TRACKING_URI di ambiente a livello di cluster. Questo approccio consente di configurare automaticamente l'URI di rilevamento MLflow in modo che punti ad Azure Machine Learning per tutte le sessioni eseguite nel cluster anziché per l’esecuzione in base alla sessione.
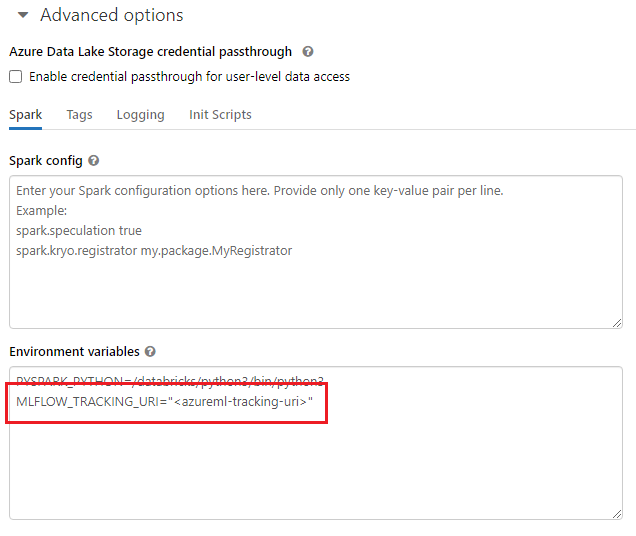
Dopo aver configurato la variabile di ambiente, qualsiasi esperimento in esecuzione in tale cluster viene rilevato in Azure Machine Learning.
Configurare l'autenticazione
Dopo aver configurato il rilevamento, configurare come eseguire l'autenticazione nell'area di lavoro associata. Per impostazione predefinita, il plug-in di Azure Machine Learning per MLflow apre un browser per richiedere in modo interattivo le credenziali. Per altre informazioni su come configurare l'autenticazione per MLflow nelle aree di lavoro di Azure Machine Learning, vedere Configurare MLflow per Azure Machine Learning: Configurare l'autenticazione.
Per i processi interattivi in cui un utente è connesso alla sessione, è possibile basarsi sull'autenticazione interattiva, per cui non è necessaria alcuna azione.
Avviso
L'autenticazione con browser interattivo blocca l'esecuzione del codice quando vengono chieste le credenziali. Questo approccio non è adatto per l'autenticazione in ambienti senza intervento dell'utente come i processi di training. È consigliabile configurare una modalità di autenticazione differente.
Per gli scenari in cui è richiesta l'esecuzione senza intervento dell'utente, è necessario configurare un'entità servizio per comunicare con Azure Machine Learning.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Suggerimento
Quando si lavora in ambienti condivisi, è consigliabile configurare queste variabili di ambiente nell'ambiente di calcolo. Come procedura consigliata, gestire come segreti in un'istanza di Azure Key Vault.
Ad esempio, in Azure Databricks è possibile usare segreti nelle variabili di ambiente, come indicato di seguito nella configurazione del cluster: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Per altre informazioni sull'implementazione di questo approccio in Azure Databricks, vedere Fare riferimento a un segreto in una variabile di ambiente o fare riferimento alla documentazione per la piattaforma.
Esperimento dei nomi in Azure Machine Learning
Quando MLflow è configurato per tenere traccia esclusivamente degli esperimenti nell'area di lavoro di Azure Machine Learning, la convenzione di denominazione per gli esperimenti deve seguire quella usata da Azure Machine Learning. In Azure Databricks, gli esperimenti vengono denominati usando il percorso in cui l'esperimento viene salvato, ad esempio /Users/alice@contoso.com/iris-classifier. In Azure Machine Learning, tuttavia, è necessario specificare direttamente il nome dell'esperimento. Lo stesso esperimento verrà denominato direttamente iris-classifier.
mlflow.set_experiment(experiment_name="experiment-name")
Rilevamento di parametri, metriche e artefatti
Dopo questa configurazione, è possibile usare MLflow in Azure Databricks nel modo consueto. Per altre informazioni, vedere Registrare e visualizzare metriche e file di log.
Registrare i modelli con MLflow
Dopo avere eseguito il training del modello, è possibile registrarlo nel server di rilevamento con il metodo mlflow.<model_flavor>.log_model(). <model_flavor> si riferisce al framework associato al modello. Leggere le informazioni sulle versioni di modelli supportate.
Nell'esempio seguente viene registrato un modello creato con la libreria Spark MLLib.
mlflow.spark.log_model(model, artifact_path = "model")
La versione spark non corrisponde al fatto che si sta eseguendo il training di un modello in un cluster Spark. Invece segue dal framework di training usato. È possibile eseguire il training di un modello usando TensorFlow con Spark. La versione da usare sarebbe tensorflow.
I modelli vengono registrati all'interno dell'esecuzione monitorata. Ciò significa che i modelli sono disponibili sia in Azure Databricks che in Azure Machine Learning (impostazione predefinita) oppure esclusivamente in Azure Machine Learning se è stato configurato l'URI di rilevamento in modo che punti a questa soluzione.
Importante
Il parametro registered_model_name non è stato specificato. Per altre informazioni su questo parametro e sul Registro di sistema, vedere Registrazione dei modelli nel registro con MLflow.
Registrazione di modelli nel registro con MLflow
Diversamente da quanto avviene con il rilevamento, i registri dei modelli non funzionano contemporaneamente in Azure Databricks e Azure Machine Learning. Devono usare uno o l'altro. Per impostazione predefinita, i registri modelli usano l'area di lavoro di Azure Databricks. Se si sceglie di impostare il rilevamento MLflow per tenere traccia solo nell'area di lavoro di Azure Machine Learning, il registro modelli è l'area di lavoro di Azure Machine Learning.
Se si usa la configurazione predefinita, il codice seguente registra un modello all'interno delle esecuzioni corrispondenti di Azure Databricks e Azure Machine Learning, ma lo registra solo in Azure Databricks.
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
- Se non esiste un modello registrato con il nome specifico, il metodo registrerà un nuovo modello, creerà la versione 1 e restituirà un oggetto
ModelVersiondi MLflow. - Se esiste già un modello registrato con il nome specifico, il metodo creerà una nuova versione del modello e restituirà l'oggetto versione.
Uso del registro di Azure Machine Learning con MLflow
Se si vuole usare il registro dei modelli di Azure Machine Learning invece di Azure Databricks, è consigliabile impostare il rilevamento MLflow per tenere traccia esclusivamente nell'area di lavoro di Azure Machine Learning. Questo approccio elimina l'ambiguità della posizione in cui vengono registrati i modelli e semplifica la configurazione.
Se si desidera continuare a usare le funzionalità di doppio rilevamento ma registrare i modelli in Azure Machine Learning, è possibile indicare a MLflow di usare Azure Machine Learning per i registri dei modelli configurando l'URI del registro dei modelli di MLflow. Questo URI ha lo stesso formato e valore che MLflow tiene traccia dell'URI.
mlflow.set_registry_uri(azureml_mlflow_uri)
Nota
Il valore di azureml_mlflow_uri è stato ottenuto nel modo descritto in Impostare il rilevamento MLflow per tenere traccia esclusivamente nell'area di lavoro di Azure Machine Learning
Per un esempio completo di questo scenario, vedere Modelli di training in Azure Databricks e distribuirli in Azure Machine Learning.
Distribuire e usare modelli registrati in Azure Machine Learning
I modelli registrati nel servizio Azure Machine Learning con MLflow possono essere utilizzati come:
- Un endpoint di Azure Machine Learning (in tempo reale e batch). Questa distribuzione consente di usare le funzionalità di distribuzione di Azure Machine Learning sia per l'inferenza in tempo reale che per l'inferenza batch in Istanze di Azure Container, Azure Kubernetes o Endpoint di inferenza gestiti.
- Oggetti modello di MLflow o funzioni definite dall'utente Pandas (UDF), che è possibile usare nei notebook di Azure Databricks in pipeline di streaming o batch.
Distribuire modelli in endpoint di Azure Machine Learning
È possibile sfruttare il plug-in azureml-mlflow per distribuire un modello nell'area di lavoro di Azure Machine Learning. Per altre informazioni su come distribuire modelli nelle diverse destinazioni Come distribuire modelli MLflow.
Importante
Affinché sia possibile distribuirli, i modelli devono essere registrati nel registro di Azure Machine Learning. Se i modelli vengono registrati nell'istanza di MLflow all'interno di Azure Databricks, registrarli nuovamente in Azure Machine Learning. Per altre informazioni, vedere Modelli di training in Azure Databricks e distribuirli in Azure Machine Learning
Distribuire modelli in Azure Databricks per l'assegnazione dei punteggi batch usando funzioni definite dall'utente
È possibile scegliere i cluster di Azure Databricks per l'assegnazione dei punteggi in batch. Utilizzando MLflow, è possibile risolvere qualsiasi modello dal registro a cui si è connessi. In genere si usa uno dei metodi seguenti:
- Se il modello è stato sottoposto a training e compilato con librerie Spark, ad esempio
MLLib, usaremlflow.pyfunc.spark_udfper caricare un modello e usarlo come funzione definita dall'utente Pandas Spark UDF per assegnare punteggi ai nuovi dati. - Se il modello non è stato sottoposto a training o compilato con librerie Spark, usare
mlflow.pyfunc.load_modelomlflow.<flavor>.load_modelper caricare il modello nel driver del cluster. È necessario orchestrare qualsiasi distribuzione parallelizzazione o di lavoro che si vuole eseguire nel cluster. MLflow non installa alcuna libreria necessaria per l'esecuzione del modello. Tali librerie devono essere installate nel cluster prima dell'esecuzione.
L'esempio seguente illustra come caricare un modello dal registro denominato uci-heart-classifier e usarlo come funzione definita dall'utente Pandas Spark per assegnare un punteggio ai nuovi dati.
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
Per informazioni su altri modi per fare riferimento ai modelli dal registro, vedere Caricamento di modelli dal registro.
Dopo il caricamento del modello, è possibile usare questo comando per assegnare un punteggio ai nuovi dati.
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Pulire le risorse
Se si vuole mantenere l'area di lavoro di Azure Databricks, ma l'area di lavoro di Azure Machine Learning non è più necessaria, è possibile eliminare quest'ultima. Questa azione comporta lo scollegamento dell'area di lavoro di Azure Databricks e dell'area di lavoro di Azure Machine Learning.
Se non si prevede di usare le metriche e gli artefatti registrati nell'area di lavoro, eliminare il gruppo di risorse che contiene l'account di archiviazione e l'area di lavoro.
- Nel portale di Azure cercare Gruppi di risorse. In servizi, selezionare Gruppi di risorse.
- Nell'elenco Gruppi di risorse trovare e selezionare il gruppo di risorse creato per aprirlo.
- Nella pagina Panoramica selezionare Elimina gruppo di risorse.
- Per verificare l'eliminazione, immettere il nome del gruppo di risorse.