Come usare Apache Spark (con tecnologia Azure Synapse Analytics) nella pipeline di Machine Learning (deprecata)
SI APPLICA A: Python SDK azureml v1
Python SDK azureml v1
Avviso
L'integrazione di Azure Synapse Analytics con Azure Machine Learning, disponibile Python SDK v1, è deprecata. Gli utenti possono comunque usare l'area di lavoro di Synapse, registrata con Azure Machine Learning, come servizio collegato. Tuttavia, non è più possibile registrare una nuova area di lavoro di Synapse con Azure Machine Learning come servizio collegato. È consigliabile usare l'ambiente di calcolo Spark serverless e i pool di Spark per Synapse collegati, disponibili nell'interfaccia della riga di comando v2 e in Python SDK v2. Per altre informazioni, vedere https://aka.ms/aml-spark.
Questo articolo illustra come usare i pool di Apache Spark con tecnologia Azure Synapse Analytics come destinazione di calcolo per un passaggio di preparazione dei dati in una pipeline di Azure Machine Learning. Si apprenderà come una singola pipeline può usare le risorse di calcolo appropriate per il passaggio specifico, ad esempio la preparazione dei dati o il training. Si vedrà inoltre come vengono preparati i dati per il passaggio Spark e come vengono passati al passaggio successivo.
Prerequisiti
Creare un'area di lavoro di Azure Machine Learning che conterrà tutte le risorse della pipeline
Configurare l'ambiente di sviluppo per installare Azure Machine Learning SDK o usare un'istanza di ambiente di calcolo di Azure Machine Learning con l'SDK già installato
Creare un'area di lavoro di Azure Synapse Analytics e un pool di Apache Spark. Per altre informazioni, vedere Avvio rapido: Creare un pool di Apache Spark serverless con Synapse Studio
Collegare l'area di lavoro di Azure Machine Learning e l'area di lavoro di Azure Synapse Analytics
I pool di Apache Spark vengono creati e amministrati in un'area di lavoro di Azure Synapse Analytics. Per integrare un pool di Apache Spark con un'area di lavoro di Azure Machine Learning, è necessario stabilire un collegamento all'area di lavoro di Azure Synapse Analytics. Dopo aver collegato l'area di lavoro di Azure Machine Learning e quella di Azure Synapse Analytics, è possibile collegare un pool di Apache Spark tramite:
Python SDK, come illustrato più avanti
Modello di Azure Resource Manager (ARM). Per altre informazioni, vedere Modello di Resource Manager di esempio
- È possibile usare la riga di comando per seguire il modello di ARM, aggiungere il servizio collegato e collegare il pool di Apache Spark con il codice di esempio seguente:
az deployment group create --name --resource-group <rg_name> --template-file "azuredeploy.json" --parameters @"azuredeploy.parameters.json"
Importante
Per collegarsi correttamente all'area di lavoro di Synapse, è necessario avere il ruolo di Proprietario dell'area di lavoro di Synapse. Controllare l'accesso nel portale di Azure.
Il servizio collegato otterrà un'identità gestita assegnata dal sistema al momento della creazione. È necessario assegnare all'identità gestita assegnata dal sistema del servizio collegato il ruolo "Amministratore di Apache Spark per Synapse" da Synapse Studio affinché possa inviare il processo Spark. Vedere Come gestire le assegnazioni di ruolo Controllo degli accessi in base al ruolo in Synapse Studio.
È anche necessario assegnare all'utente dell'area di lavoro di Azure Machine Learning il ruolo "Collaboratore" dal portale di Azure per la gestione delle risorse.
Recuperare il collegamento tra l'area di lavoro di Azure Synapse Analytics e quella di Azure Machine Learning
Questo codice illustra come recuperare i servizi collegati nell'area di lavoro:
from azureml.core import Workspace, LinkedService, SynapseWorkspaceLinkedServiceConfiguration
ws = Workspace.from_config()
for service in LinkedService.list(ws) :
print(f"Service: {service}")
# Retrieve a known linked service
linked_service = LinkedService.get(ws, 'synapselink1')
Per prima cosa, Workspace.from_config() accede all'area di lavoro di Azure Machine Learning con la configurazione specificata nel file config.json. Per altre informazioni, vedere Creare un file di configurazione dell'area di lavoro. Il codice stampa quindi tutti i servizi collegati disponibili nell'area di lavoro. Infine, LinkedService.get() recupera un servizio collegato denominato 'synapselink1'.
Collegare il pool di Apache Spark come destinazione di calcolo per Azure Machine Learning
Per usare il pool di Apache Spark per eseguire un passaggio nella pipeline di Machine Learning, è necessario collegarlo come oggetto ComputeTarget per il passaggio della pipeline, come illustrato nel codice di esempio seguente:
from azureml.core.compute import SynapseCompute, ComputeTarget
attach_config = SynapseCompute.attach_configuration(
linked_service = linked_service,
type="SynapseSpark",
pool_name="spark01") # This name comes from your Synapse workspace
synapse_compute=ComputeTarget.attach(
workspace=ws,
name='link1-spark01',
attach_configuration=attach_config)
synapse_compute.wait_for_completion()
Il codice configura innanzitutto l'oggetto SynapseCompute. L'argomento linked_service è l'oggetto LinkedService creato o recuperato nel passaggio precedente. L'argomento type deve essere SynapseSpark. L'argomento pool_name in SynapseCompute.attach_configuration() deve corrispondere a quello di un pool esistente nell'area di lavoro di Azure Synapse Analytics. Per altre informazioni su come creare un pool di Apache Spark nell'area di lavoro di Azure Synapse Analytics, vedere Avvio rapido: Creare un pool di Apache Spark serverless con Synapse Studio. Il tipo di attach_config è ComputeTargetAttachConfiguration.
Dopo aver creato la configurazione, viene creato un oggetto ComputeTarget per le attività di Machine Learning passando nei valori Workspace e ComputeTargetAttachConfiguration e il nome che si vuole usare per fare riferimento all'ambiente di calcolo all'interno dell'area di lavoro di Machine Learning. La chiamata a ComputeTarget.attach() è asincrona, quindi l'esecuzione dell'esempio viene bloccata fino al completamento della chiamata.
Creare un oggetto SynapseSparkStep che usa il pool di Apache Spark collegato
Il notebook di esempio di un processo Spark nel pool di Apache Spark definisce una semplice pipeline di Machine Learning. Per prima cosa, il notebook definisce un passaggio di preparazione dei dati basato sull'oggetto synapse_compute definito nel passaggio precedente. Il notebook definisce quindi un passaggio di training basato su una destinazione di calcolo più appropriata per il training. Il notebook di esempio usa il database di sopravvivenza Titanic per mostrare l'input e l'output dei dati. In realtà non pulisce i dati o crea un modello predittivo. Poiché in questo esempio non viene eseguito realmente il training, il passaggio di training usa una risorsa di calcolo economica basata sulla CPU.
I dati passano a una pipeline di Machine Learning tramite oggetti DatasetConsumptionConfig, che possono contenere dati tabulari o set di file. I dati provengono spesso da file disponibili nell'archiviazione BLOB di un archivio dati dell'area di lavoro. Questo codice di esempio mostra il codice tipico per la creazione dell'input per una pipeline di Machine Learning:
from azureml.core import Dataset
datastore = ws.get_default_datastore()
file_name = 'Titanic.csv'
titanic_tabular_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, file_name)])
step1_input1 = titanic_tabular_dataset.as_named_input("tabular_input")
# Example only: it wouldn't make sense to duplicate input data, especially one as tabular and the other as files
titanic_file_dataset = Dataset.File.from_files(path=[(datastore, file_name)])
step1_input2 = titanic_file_dataset.as_named_input("file_input").as_hdfs()
Il codice di esempio presuppone che il file Titanic.csv si trovi nell'archiviazione BLOB. Il codice mostra come leggere il file sia come TabularDataset che come FileDataset. Questo codice viene fornito solo a scopo dimostrativo, in quanto duplicare gli input o interpretare una singola origine dati sia come risorsa contenente una tabella che come file potrebbe generare confusione.
Importante
Per usare FileDataset come input, è necessaria almeno la versione 1.20.0 di azureml-core. È possibile specificare questa opzione con la classe Environment, come illustrato più avanti. Al termine di un passaggio, è possibile archiviare i dati di output, come illustrato nel codice di esempio seguente:
from azureml.data import HDFSOutputDatasetConfig
step1_output = HDFSOutputDatasetConfig(destination=(datastore,"test")).register_on_complete(name="registered_dataset")
Nel codice di esempio seguente datastore archivia i dati in un file denominato test. I dati saranno disponibili nell'area di lavoro di Machine Learning come oggetto Dataset, con il nome registered_dataset.
Oltre ai dati, un passaggio della pipeline può includere dipendenze Python specifiche del passaggio. Inoltre, i singoli oggetti SynapseSparkStep possono specificare anche la configurazione precisa di Azure Synapse Apache Spark. A tale scopo, il codice di esempio seguente specifica che la versione del pacchetto azureml-core deve essere almeno 1.20.0. Come accennato in precedenza, questo requisito per il pacchetto azureml-core è necessario per usare FileDataset come input.
from azureml.core.environment import Environment
from azureml.pipeline.steps import SynapseSparkStep
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core>=1.20.0")
step_1 = SynapseSparkStep(name = 'synapse-spark',
file = 'dataprep.py',
source_directory="./code",
inputs=[step1_input1, step1_input2],
outputs=[step1_output],
arguments = ["--tabular_input", step1_input1,
"--file_input", step1_input2,
"--output_dir", step1_output],
compute_target = 'link1-spark01',
driver_memory = "7g",
driver_cores = 4,
executor_memory = "7g",
executor_cores = 2,
num_executors = 1,
environment = env)
Questo codice specifica un singolo passaggio nella pipeline di Azure Machine Learning. Il valore environment di questo codice consente di impostare una versione azureml-core specifica e il codice può aggiungere altre dipendenze Conda o PIP in base alle esigenze.
SynapseSparkStep comprime e carica dal computer locale la sottodirectory ./code. Tale directory viene ricreata nel server di calcolo e il passaggio esegue lo script dataprep.py da tale directory. Gli elementi inputs e outputs di tale passaggio sono gli oggetti step1_input1, step1_input2 e step1_output descritti in precedenza. Il modo più semplice per accedere a questi valori all'interno dello script dataprep.py consiste nell'associarli a oggetti arguments denominati.
Il set di argomenti successivo per il costruttore SynapseSparkStep controlla Apache Spark. compute_target è l'oggetto 'link1-spark01' che è stato collegato in precedenza come destinazione di calcolo. Gli altri parametri specificano la memoria e i core da usare.
Il notebook di esempio usa questo codice per dataprep.py:
import os
import sys
import azureml.core
from pyspark.sql import SparkSession
from azureml.core import Run, Dataset
print(azureml.core.VERSION)
print(os.environ)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--tabular_input")
parser.add_argument("--file_input")
parser.add_argument("--output_dir")
args = parser.parse_args()
# use dataset sdk to read tabular dataset
run_context = Run.get_context()
dataset = Dataset.get_by_id(run_context.experiment.workspace,id=args.tabular_input)
sdf = dataset.to_spark_dataframe()
sdf.show()
# use hdfs path to read file dataset
spark= SparkSession.builder.getOrCreate()
sdf = spark.read.option("header", "true").csv(args.file_input)
sdf.show()
sdf.coalesce(1).write\
.option("header", "true")\
.mode("append")\
.csv(args.output_dir)
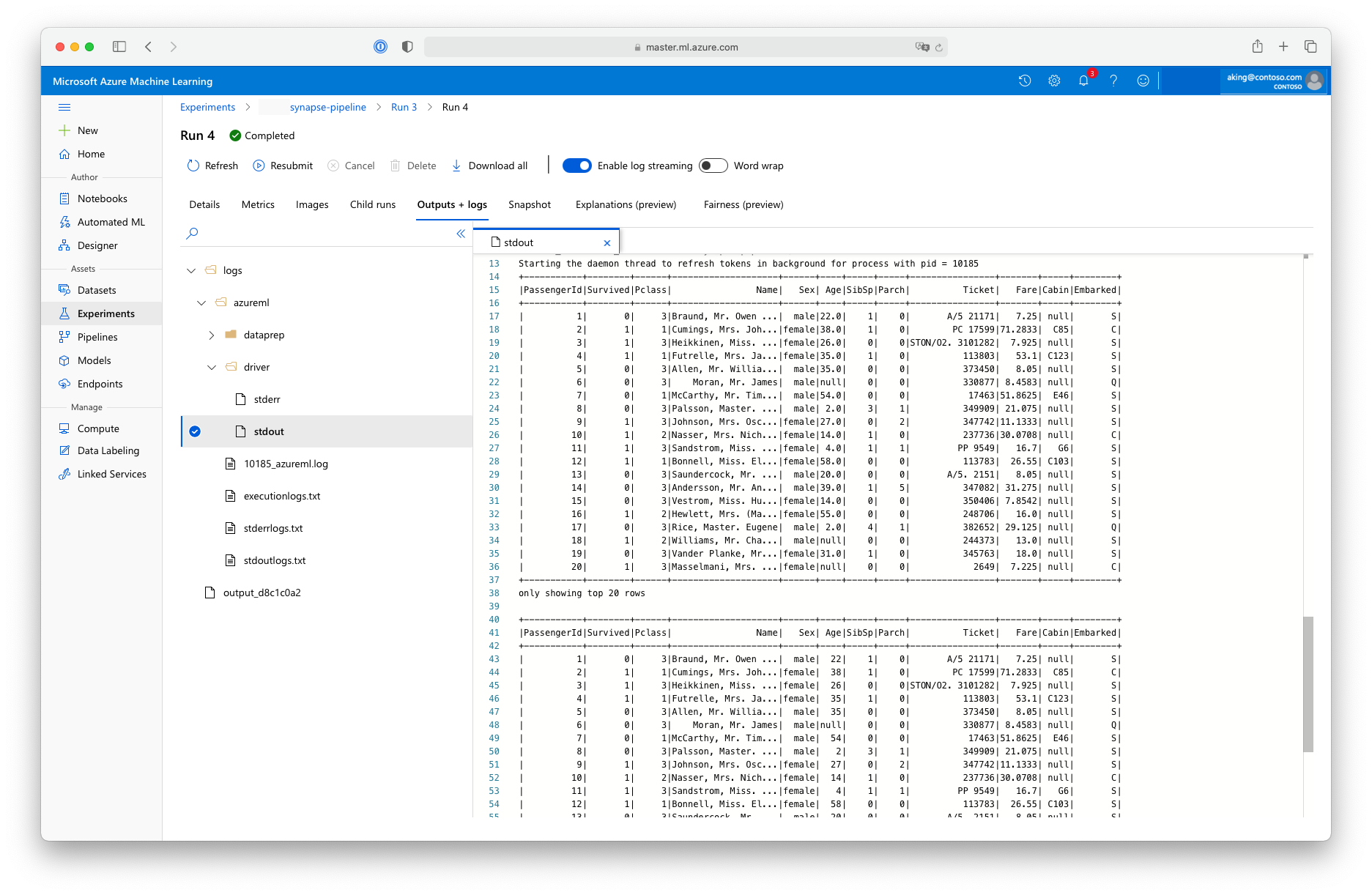
Questo script di "preparazione dei dati" non esegue alcuna effettiva trasformazione dei dati, ma mostra come recuperare i dati, convertirli in un dataframe Spark ed eseguire alcune operazioni di manipolazione di base di Apache Spark. Per trovare l'output nello studio di Azure Machine Learning, aprire il processo figlio, scegliere la scheda Output e log e aprire il file logs/azureml/driver/stdout, come illustrato in questo screenshot:
Usare SynapseSparkStep in una pipeline
L'esempio seguente usa l'output di SynapseSparkStep creato nella sezione precedente. Altri passaggi della pipeline potrebbero avere ambienti specifici ed essere eseguiti su risorse di calcolo diverse, appropriate per l'attività. Il notebook di esempio esegue il "passaggio di training" in un piccolo cluster CPU:
from azureml.core.compute import AmlCompute
cpu_cluster_name = "cpucluster"
if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
else:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=1)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
print('Allocating new CPU compute cluster')
cpu_cluster.wait_for_completion(show_output=True)
step2_input = step1_output.as_input("step2_input").as_download()
step_2 = PythonScriptStep(script_name="train.py",
arguments=[step2_input],
inputs=[step2_input],
compute_target=cpu_cluster_name,
source_directory="./code",
allow_reuse=False)
Questo codice consente di creare la nuova risorsa di calcolo, se necessario. Converte quindi il risultato di step1_output in input per il passaggio di training. L'opzione as_download() indica che i dati vengono spostati nella risorsa di calcolo, per consentire un accesso più rapido. Se il volume di dati è troppo elevato per il disco rigido di calcolo locale, è necessario usare l'opzione as_mount() per trasmettere i dati con il file system FUSE. L'oggetto compute_target di questo secondo passaggio è 'cpucluster', non la risorsa 'link1-spark01' usata nel passaggio di preparazione dei dati. Questo passaggio usa uno script train.py semplice invece dello script dataprep.py usato nel passaggio precedente. Il notebook di esempio include i dettagli dello script train.py.
Dopo aver definito tutti i passaggi, è possibile creare ed eseguire la pipeline.
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=ws, steps=[step_1, step_2])
pipeline_run = pipeline.submit('synapse-pipeline', regenerate_outputs=True)
Questo codice crea una pipeline costituita dal passaggio di preparazione dei dati nei pool di Apache Spark, basati su Azure Synapse Analytics (step_1), e dal passaggio di training (step_2). Azure esamina le dipendenze dei dati tra i passaggi per calcolare il grafo di esecuzione. In questo caso, è presente solo una semplice dipendenza, ovvero step2_input richiede necessariamente step1_output.
La chiamata a pipeline.submit crea, se necessario, un esperimento denominato synapse-pipeline, in cui avvia in modo asincrono un processo. I singoli passaggi all'interno della pipeline vengono eseguiti come processi figlio di questo processo principale e possono essere monitorati ed esaminati nella pagina Esperimenti di Studio.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per