Che cos'è Azure Machine Learning?
Azure Machine Learning è un servizio cloud per l'accelerazione e la gestione del ciclo di vita di progetti di Machine Learning (ML). I professionisti, gli scienziati dei dati e i tecnici specializzati in ML possono usarlo nei flussi di lavoro quotidiani per eseguire il training e distribuire modelli e gestire le operazioni per l'apprendimento automatico (MLOps).
È possibile creare un modello in Machine Learning o usarne uno creato da una piattaforma open source, ad esempio PyTorch, TensorFlow o scikit-learn. Gli strumenti MLOps consentono di monitorare, ripetere il training e ridistribuire i modelli.
Suggerimento
Versione di valutazione gratuita. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning. Si ricevono così crediti da spendere in servizi di Azure. Quando i crediti saranno esauriti, sarà possibile mantenere l'account e usare i servizi di Azure gratuiti. Verranno applicati addebiti alla carta di credito solo se l'utente modifica le impostazioni e richiede esplicitamente l'addebito.
A chi è destinato Azure Machine Learning?
Machine Learning è destinato a singoli utenti e team che implementano operazioni per l'apprendimento automatico all'interno dell'organizzazione per portare i modelli di ML in un ambiente di produzione sicuro e controllabile.
Gli scienziati dei dati e i tecnici specializzati in ML possono usare strumenti per accelerare e automatizzare le aree di lavoro quotidiane. Gli sviluppatori di applicazioni possono usare strumenti per l'integrazione di modelli in applicazioni o servizi. Gli sviluppatori di piattaforme possono usare un solido set di strumenti, supportato da potenti API di Azure Resource Manager, per la creazione di strumenti avanzati di ML.
Le aziende che operano nel cloud di Microsoft Azure possono usare la sicurezza già nota e il controllo degli accessi in base al ruolo per l'infrastruttura. È possibile configurare un progetto per negare l'accesso ai dati protetti e selezionare le operazioni.
Produttività per tutti i membri del team
I progetti di ML richiedono spesso un team con un'ampia competenza impostata per la creazione e la gestione. Machine Learning include strumenti che consentono di:
Collaborare con il team tramite notebook condivisi, risorse di calcolo, elaborazione serverless, dati e ambienti
Sviluppare modelli che garantiscono equità e spiegabilità, tracciabilità e verificabilità per soddisfare i requisiti di conformità di derivazione e controllo
Distribuire modelli di ML in modo rapido e semplice su larga scala e gestirli in modo efficiente con MLOps
Eseguire carichi di lavoro di Machine Learning ovunque con governance, sicurezza e conformità predefinite
Strumenti multipiattaforma che soddisfano le esigenze
Chiunque in un team di ML può usare gli strumenti preferiti per svolgere il lavoro. Durante l'esecuzione di esperimenti rapidi, l'ottimizzazione degli iperparametri, la creazione di pipeline o la gestione di interferenze è possibile usare interfacce già note, tra cui:
- Studio di Azure Machine Learning
- Python SDK (v2)
- Interfaccia della riga di comando di Azure (v2)
- API REST di Azure Resource Manager
Man mano che si affina il modello e si collabora con altri utenti nelle altre fasi del ciclo di sviluppo di Machine Learning, è possibile condividere e trovare asset, risorse e metriche per i progetti nell'interfaccia utente di Machine Learning Studio.
Studio
Machine Learning Studio offre diverse esperienze di creazione in base al tipo di progetto e al livello della precedente esperienza di ML senza dover installare nulla.
Notebook: consentono di scrivere ed eseguire il codice personalizzato nei server gestiti da Jupyter Notebook direttamente integrati nello Studio. In alternativa, aprire i notebook in VS Code, sul Web o sul desktop.
Visualizzazione di metriche di esecuzione: per analizzare e ottimizzare gli esperimenti con la visualizzazione.
Finestra di progettazione di Azure Machine Learning: usare la finestra di progettazione per eseguire il training e distribuire i modelli di ML senza scrivere codice. Trascinare e rilasciare i set di dati e i componenti per creare pipeline di ML.
Interfaccia utente di Machine Learning automatizzato: informazioni su come creare esperimenti di Machine Learning automatizzato con un'interfaccia di facile uso.
Etichettatura dei dati: usare l'etichettatura dei dati di Machine Learning per coordinare in modo efficiente i progetti di etichettatura di immagini o di etichettatura di testo.
Usare LLM e IA generativa
Azure Machine Learning include strumenti che consentono di creare applicazioni di IA generativa basate su modelli linguistici di grandi dimensioni. La soluzione include un catalogo modelli, un prompt flow e una suite di strumenti per semplificare il ciclo di sviluppo delle applicazioni di intelligenza artificiale.
Sia lo studio di Azure Machine Learning sia Studio AI della piattaforma Azure consentono di usare modelli linguistici di grandi dimensioni. Usare questa guida per decidere quale versione dello studio usare.
Catalogo modelli
Il catalogo modelli nello studio di Azure Machine Learning è l'hub che consente di individuare e usare un'ampia gamma di modelli per la creazione di applicazioni di intelligenza artificiale generativa. Il catalogo modelli include centinaia di modelli di diversi provider, tra cui il servizio Azure OpenAI, Mistral, Meta, Cohere, Nvidia, Hugging Face, nonché alcuni modelli sottoposti a training da Microsoft. I modelli dei provider diversi da Microsoft sono prodotti non Microsoft, come definito nelle Condizioni per i prodotti Microsoft e sono soggetti alle condizioni fornite con il modello.
Prompt flow
Prompt flow di Azure Machine Learning è uno strumento di sviluppo progettato per semplificare l'intero ciclo di sviluppo delle applicazioni di IA basate su Large Language Model (LLM). Prompt flow offre una soluzione completa che semplifica il processo di creazione di prototipi, la sperimentazione, l'iterazione e la distribuzione delle applicazioni di intelligenza artificiale.
Idoneità e sicurezza aziendale
Machine Learning si integra con la piattaforma cloud di Azure per aggiungere sicurezza ai progetti di ML.
Le integrazioni per la sicurezza includono:
- Reti virtuali di Azure con gruppi di sicurezza di rete.
- Azure Key Vault, dove è possibile salvare i segreti di sicurezza, ad esempio le informazioni di accesso per gli account di archiviazione.
- Registro Azure Container configurato dietro una rete virtuale.
Per altre informazioni, vedere Esercitazione: Configurare un'area di lavoro sicura.
Integrazioni di Azure per soluzioni complete
Altre integrazioni con i servizi di Azure supportano un progetto di ML dall'inizio alla fine. che includono:
- Azure Synapse Analytics, usato per elaborare e trasmettere dati con Spark.
- Azure Arc, dove è possibile eseguire i servizi di Azure in un ambiente Kubernetes.
- Opzioni di archiviazione e di database, come il database SQL di Azure e Archiviazione BLOB di Azure.
- Servizio app di Azure, che è possibile usare per distribuire e gestire app basate su ML.
- Microsoft Purview, che consente di individuare e catalogare asset di dati nell'intera organizzazione.
Importante
Azure Machine Learning non archivia né elabora i dati dei clienti all'esterno dell'area di distribuzione.
Flusso di lavoro del progetto di Machine Learning
In genere, i modelli vengono sviluppati come parti di un progetto con uno o più obiettivi. I progetti spesso coinvolgono più di una persona. Quando si sperimentano dati, algoritmi e modelli, lo sviluppo è iterativo.
Ciclo di vita del progetto
Il ciclo di vita del progetto può variare in base al progetto, ma spesso è simile a quello raffigurato in questo diagramma.
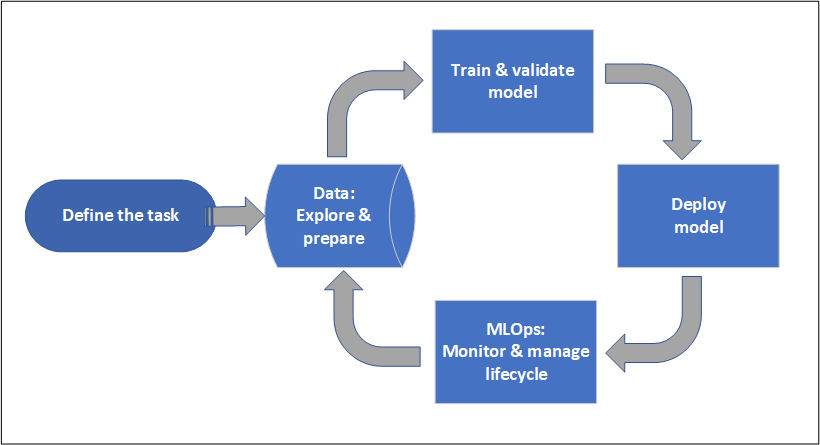
Un'area di lavoro organizza un progetto e consente la collaborazione di molti utenti che lavorano per un obiettivo comune. Gli utenti in un'area di lavoro possono condividere facilmente i risultati delle esecuzioni dalla sperimentazione nell'interfaccia utente dello studio. In alternativa, possono usare asset con controllo delle versioni per processi come ambienti e riferimenti alle risorse di archiviazione.
Per altre informazioni, vedere Gestire aree di lavoro di Azure Machine Learning.
Quando un progetto è pronto per l'operazionalizzazione, è possibile usare il lavoro degli utenti in una pipeline di ML e attivato in base a una pianificazione o a una richiesta HTTPS.
È possibile distribuire modelli nella soluzione di inferenza gestita, sia per le distribuzioni in tempo reale che per le distribuzioni batch, astraendo la gestione dell'infrastruttura in genere obbligatoria per la distribuzione dei modelli.
Eseguire il training dei modelli
In Azure Machine Learning è possibile eseguire lo script di training nel cloud o creare un modello da zero. I clienti spesso usano modelli creati e sottoposti a training in framework open source per permetterne l'operazionalizzazione nel cloud.
Aperto e con interoperabilità
Gli scienziati dei dati possono usare modelli in Azure Machine Learning creati in framework Python comuni, tra cui:
- PyTorch
- TensorFlow
- scikit-learn
- XGBoost
- LightGBM
Vengono supportati altre lingue e altri framework:
- R
- .NET
Per altre informazioni, vedere Integrazione open source con Azure Machine Learning.
Selezione automatizzata delle definizioni delle funzionalità e degli algoritmi
In un processo ripetitivo e dispendioso in termini di tempo, nel ML classico, gli scienziati dei dati sfruttano esperienza e intuizioni precedenti per selezionare la definizione delle funzionalità e l'algoritmo dei dati corretti per il training. ML automatizzato (AutoML) velocizza questo processo. È possibile usarlo tramite l'interfaccia utente di Machine Learning Studio o Python SDK.
Per altre informazioni, vedere Che cos'è Machine Learning automatizzato?.
Ottimizzazione degli iperparametri
L'ottimizzazione degli iperparametri può essere un'attività noiosa. Machine Learning può automatizzare questa attività per comandi con parametri arbitrari con poche modifiche alla definizione del processo. I risultati vengono visualizzati nello studio.
Per altre informazioni, vedere Ottimizzare gli iperparametri.
Training distribuito tra più nodi
L'efficienza del training per il Deep Learning e talvolta i processi di training di Machine Learning classici possono essere notevolmente migliorati tramite il training distribuito tra più nodi. I cluster di elaborazione di Azure Machine Learning e l'elaborazione serverless offrono le opzioni GPU più recenti.
Supportato tramite Kubernetes di Azure Machine Learning, cluster di elaborazione di Azure Machine Learning ed elaborazione serverless:
- PyTorch
- TensorFlow
- MPI
È possibile usare la distribuzione MPI per Horovod o la logica a più nodi personalizzata. Apache Spark è supportato tramite l'ambiente di elaborazione Spark serverless il pool di Spark per Synapse collegato che usano cluster Spark di Azure Synapse Analytics.
Per altre informazioni, vedere Training distribuito con Azure Machine Learning.
Training perfettamente paralleli
Il ridimensionamento di un progetto di ML potrebbe richiedere il ridimensionamento del training del modello perfettamente parallelo. Questo criterio è comune per scenari come la previsione della domanda, in cui è possibile eseguire il training di un modello per molti negozi.
Distribuire i modelli
Per portare un modello in produzione, si distribuisce il modello. Gli endpoint gestiti di Azure Machine Learning astraggono l'infrastruttura necessaria per l'assegnazione dei punteggi dei modelli (inferenza) batch o in tempo reale (online).
Assegnazione dei punteggi (inferenza) in tempo reale e batch
L'assegnazione dei punteggi batch o inferenza batch comporta la chiamata di un endpoint con un riferimento ai dati. Gli endpoint batch eseguono processi in modo asincrono per elaborare i dati in parallelo nei cluster di elaborazione e archiviano i dati per un'ulteriore analisi.
L'assegnazione dei punteggi in tempo reale o inferenza online comporta la chiamata di un endpoint con una o più distribuzioni di modelli e la ricezione di una risposta quasi in tempo reale tramite HTTPS. Il traffico può essere suddiviso tra più distribuzioni per consentire di testare nuove versioni del modello deviando inizialmente una certa quantità di traffico e aumentando dopo aver stabilito confidenza nel nuovo modello.
Per altre informazioni, vedi:
- Distribuire un modello con un endpoint gestito in tempo reale
- Usare endpoint batch per l'assegnazione di punteggi
MLOps: DevOps per Machine Learning
DevOps per i modelli di ML, spesso noto come MLOps, è un processo per lo sviluppo di modelli per ambienti di produzione. Il ciclo di vita di un modello dal training alla distribuzione deve essere controllabile se non riproducibile.
Ciclo di vita di un modello di ML
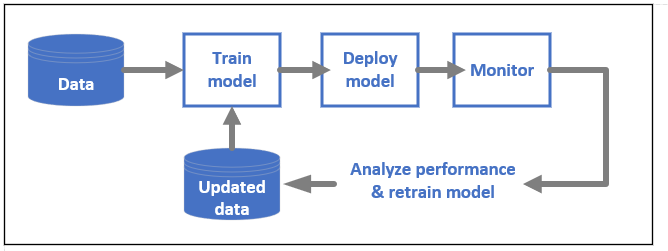
Altre informazioni su MLOps in Azure Machine Learning.
Integrazioni che abilitano MLOPs
Machine Learning si basa sul ciclo di vita del modello. È possibile controllare il ciclo di vita del modello fino a un ambiente e un commit specifico.
Ecco alcune delle principali funzionalità che include l'abilitazione di MLOps:
- Integrazione di
git. - Integrazione di MLflow.
- Pianificazione della pipeline di Machine Learning.
- Integrazione di Griglia di eventi di Azure per trigger personalizzati.
- Facilità d'uso con strumenti CI/CD come GitHub Actions o Azure DevOps.
Machine Learning include anche funzionalità per il monitoraggio e il controllo:
- Artefatti del processo, ad esempio snapshot di codice, log e altri output.
- Derivazione tra processi e asset, ad esempio contenitori, dati e risorse di calcolo.
Se si usa Apache Airflow, il pacchetto airflow-provider-azure-machinelearning è un provider che consente di inviare flussi di lavoro ad Azure Machine Learning da Apache AirFlow.
Contenuto correlato
Iniziare a usare Azure Machine Learning: