Integrare il flusso di richiesta con DevOps per applicazioni basate su LLM
Il flusso di richieste di Azure Machine Learning è un metodo code-first semplice e intuitivo per sviluppatori per sviluppare ed eseguire l'iterazione dei flussi per lo sviluppo di applicazioni basate su LLM (Large Language Model). Il flusso prompt fornisce un SDK e un'interfaccia della riga di comando, un'estensione di Visual Studio Code e un'interfaccia utente di creazione del flusso. Questi strumenti facilitano lo sviluppo del flusso locale, l'esecuzione del flusso locale e l'attivazione dell'esecuzione della valutazione e la transizione dei flussi tra ambienti dell'area di lavoro locale e cloud.
È possibile combinare l'esperienza del flusso di richiesta e le funzionalità del codice con le operazioni per sviluppatori (DevOps) per migliorare i flussi di lavoro di sviluppo di applicazioni basate su LLM. Questo articolo è incentrato sull'integrazione del flusso di richiesta e di DevOps per le applicazioni basate su LLM di Azure Machine Learning.
Il diagramma seguente illustra l'interazione dello sviluppo di flussi di richieste locali e basati sul cloud con DevOps.

Prerequisiti
Un'area di lavoro di Azure Machine Learning. Per crearne uno, vedere Creare risorse per iniziare.
Un ambiente Python locale con Azure Machine Learning Python SDK v2 installato, creato seguendo le istruzioni riportate in Introduzione.
Nota
Questo ambiente è separato dall'ambiente usato dalla sessione di calcolo per eseguire il flusso, definito come parte del flusso. Per altre informazioni, vedere Gestire la sessione di calcolo del flusso di richiesta in studio di Azure Machine Learning.
Visual Studio Code con le estensioni del flusso Python e Prompt installate.
Usare un'esperienza code-first nel flusso di richiesta
Lo sviluppo di applicazioni basate su LLM segue in genere un processo di progettazione di applicazioni standardizzato che include repository di codice sorgente e pipeline di integrazione continua/distribuzione continua (CI/CD). Questo processo promuove lo sviluppo semplificato, il controllo della versione e la collaborazione tra i membri del team.
L'integrazione di DevOps con l'esperienza del codice del flusso di richiesta offre agli sviluppatori di codice un processo di iterazione GenAIOps o LLMOps più efficiente, con le funzionalità e i vantaggi principali seguenti:
Controllo delle versioni del flusso nel repository di codice. È possibile definire i file di flusso in formato YAML e rimanere allineati ai file di origine a cui si fa riferimento nella stessa struttura di cartelle.
Integrazione dell'esecuzione del flusso con pipeline CI/CD. È possibile integrare facilmente il flusso di richieste nelle pipeline CI/CD e nel processo di recapito usando l'interfaccia della riga di comando del flusso di richiesta o l'SDK per attivare automaticamente le esecuzioni del flusso.
Transizione uniforme tra locale e cloud. È possibile esportare facilmente la cartella del flusso nel repository di codice locale o upstream per il controllo della versione, lo sviluppo locale e la condivisione. È anche possibile importare facilmente la cartella di flusso in Azure Machine Learning per altre operazioni di creazione, test e distribuzione usando le risorse cloud.
Codice del flusso di richiesta di accesso
Ogni flusso di richiesta ha una struttura di cartelle di flusso contenente file di codice essenziali che definiscono il flusso. La struttura di cartelle organizza il flusso, semplificando le transizioni tra locale e cloud.
Azure Machine Learning offre un file system condiviso per tutti gli utenti dell'area di lavoro. Al momento della creazione del flusso, una cartella del flusso corrispondente viene generata automaticamente e archiviata nella directory Users/<username>/promptflow .

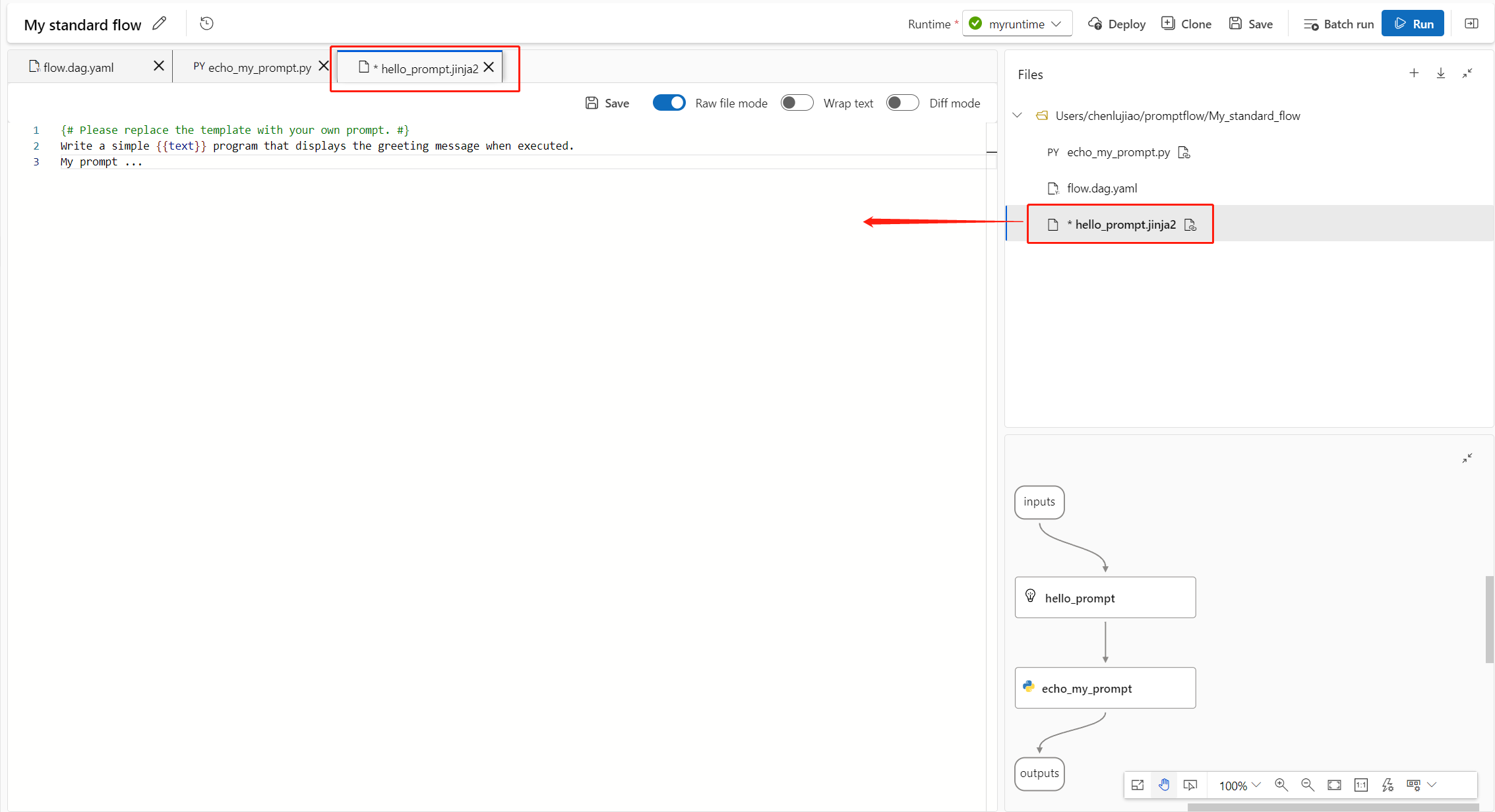
Usare i file di codice del flusso
Dopo aver creato un flusso in studio di Azure Machine Learning, è possibile visualizzare, modificare e gestire i file di flusso nella sezione File della pagina di creazione del flusso. Tutte le modifiche apportate ai file riflettono direttamente l'archiviazione della condivisione file.

La cartella del flusso per un flusso basato su LLM contiene i file di chiave seguenti.
flow.dag.yaml è il file di definizione del flusso primario in formato YAML. Questo file è integrale alla creazione e alla definizione del flusso di richiesta. Il file include informazioni su input, output, nodi, strumenti e varianti usate dal flusso.
I file di codice sorgente gestiti dall'utente in formato Python (.py) o Jinja 2 (jinja2) configurano gli strumenti e i nodi nel flusso. Lo strumento Python usa i file Python per definire la logica Python personalizzata. Lo strumento prompt e lo strumento LLM usano i file Jinja 2 per definire il contesto del prompt.
I file non di origine come utilità e file di dati possono essere inclusi nella cartella del flusso insieme ai file di origine.
Per visualizzare e modificare il codice non elaborato dei file flow.dag.yaml e di origine nell'editor di file, attivare la modalità file non elaborato.

In alternativa, è possibile accedere e modificare tutte le cartelle e i file del flusso dalla pagina studio di Azure Machine Learning Notebooks.

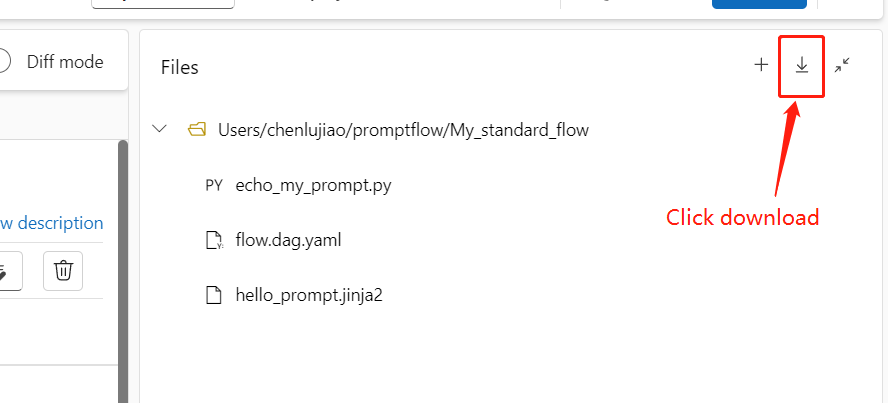
Scaricare e archiviare il codice del flusso di richiesta
Per controllare il flusso nel repository di codice, esportare la cartella del flusso da studio di Azure Machine Learning nel computer locale. Selezionare l'icona di download nella sezione File della pagina di creazione del flusso per scaricare un pacchetto ZIP contenente tutti i file di flusso. È quindi possibile controllare il file nel repository di codice o decomprimerlo per lavorare con i file in locale.
Per altre informazioni sull'integrazione di DevOps con Azure Machine Learning, vedere Integrazione di Git per Azure Machine Learning.
Sviluppare e testare localmente
Quando si ottimizza e si ottimizza il flusso o le richieste durante lo sviluppo iterativo, è possibile eseguire più iterazioni in locale all'interno del repository di codice. La versione della community di VS Code, l'estensione del flusso del prompt di VS Code e l'SDK locale e l'interfaccia della riga di comando facilitano lo sviluppo e il test locali puri senza binding di Azure.
Lavorare in locale consente di apportare e testare rapidamente le modifiche, senza dover aggiornare ogni volta il repository di codice principale. Per altre informazioni e indicazioni sull'uso delle versioni locali, vedere la community gitHub del flusso prompt.
Usare l'estensione del flusso del prompt di VS Code
Usando l'estensione Prompt flow VS Code, è possibile creare facilmente il flusso in locale nell'editor di VS Code con un'esperienza di interfaccia utente simile a quella nel cloud.
Per modificare i file in locale in VS Code con l'estensione Flusso prompt:
In VS Code con l'estensione Flusso prompt abilitata aprire una cartella del flusso di richiesta.
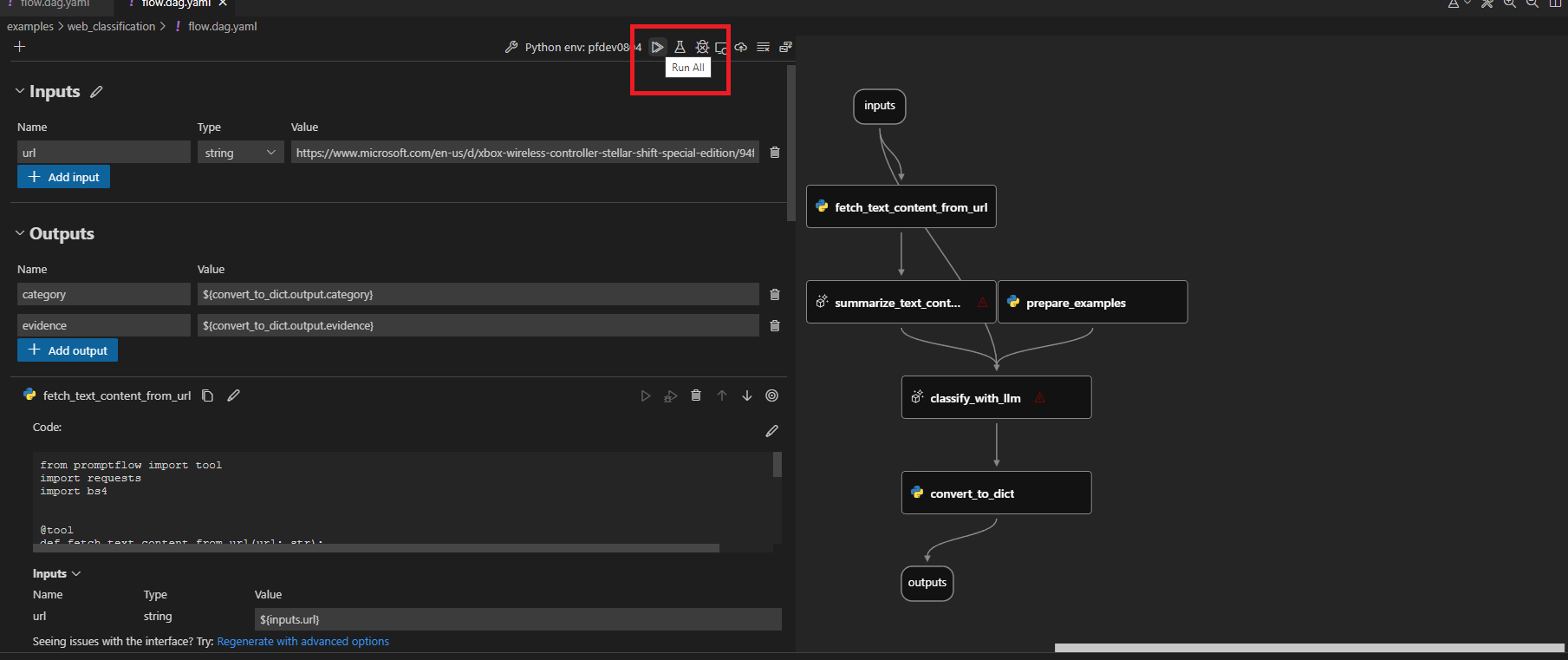
Aprire il file flow.dag.yaml e selezionare il collegamento Editor visivo nella parte superiore del file.

Usare l'editor visivo flusso di richiesta per apportare modifiche al flusso, ad esempio l'ottimizzazione delle richieste nelle varianti o l'aggiunta di altri nodi.
Per testare il flusso, selezionare l'icona Esegui nella parte superiore dell'editor visivo o per testare qualsiasi nodo, selezionare l'icona Esegui nella parte superiore del nodo.



Usare l'SDK del flusso di richiesta e l'interfaccia della riga di comando
Se si preferisce lavorare direttamente nel codice o usare Jupyter, PyCharm, Visual Studio o un altro ambiente di sviluppo integrato (IDE), è possibile modificare direttamente il codice YAML nel file flow.dag.yaml .

È quindi possibile attivare un'esecuzione di un singolo flusso per i test usando l'interfaccia della riga di comando del flusso di prompt o l'SDK nel terminale come indicato di seguito.
Per attivare un'esecuzione dalla directory di lavoro, eseguire il codice seguente:
pf flow test --flow <directory-name>
I valori restituiti sono i log di test e gli output.

Inviare esecuzioni al cloud da un repository locale
Dopo aver soddisfatto i risultati del test locale, è possibile usare l'interfaccia della riga di comando del flusso di richiesta o l'SDK per inviare esecuzioni al cloud dal repository locale. La procedura e il codice seguenti si basano sul progetto demo di classificazione Web in GitHub. È possibile clonare il repository del progetto o scaricare il codice del flusso di richiesta nel computer locale.
Installare l'SDK del prompt flow
Installare l'SDK/l'interfaccia della riga di comando del prompt di Azure eseguendo pip install promptflow[azure] promptflow-tools.
Se si usa il progetto demo, ottenere l'SDK e altri pacchetti necessari installando requirements.txt conpip install -r <path>/requirements.txt.
Connettersi all'area di lavoro di Azure Machine Learning
Caricare il flusso e creare un'esecuzione
Preparare il file run.yml per definire la configurazione per l'esecuzione di questo flusso nel cloud.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path-to-flow>
data: <path-to-flow>/<data-file>.jsonl
column_mapping:
url: ${data.url}
# Define cloud compute resource
resources:
instance_type: <compute-type>
# If using compute instance compute type, also specify instance name
# compute: <compute-instance-name>
# Specify connections
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
È possibile specificare il nome di connessione e distribuzione per ogni strumento nel flusso che richiede una connessione. Se non si specifica il nome di connessione e distribuzione, lo strumento usa la connessione e la distribuzione nel file flow.dag.yaml . Usare il codice seguente per formattare le connessioni:
...
connections:
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
...
Creare l'esecuzione.
pfazure run create --file run.yml
Creare un'esecuzione del flusso di valutazione
Preparare il file run_evaluation.yml per definire la configurazione per questo flusso di valutazione eseguito nel cloud.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path-to-flow>
data: <path-to-flow>/<data-file>.jsonl
run: <id-of-base-flow-run>
column_mapping:
<input-name>: ${data.<column-from-test-dataset>}
<input-name>: ${run.outputs.<column-from-run-output>}
resources:
instance_type: <compute-type>
compute: <compute_instance_name>
connections:
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
Creare l'esecuzione della valutazione.
pfazure run create --file run_evaluation.yml
Visualizzare i risultati dell'esecuzione
L'invio dell'esecuzione del flusso al cloud restituisce l'URL cloud dell'esecuzione. È possibile aprire l'URL per visualizzare i risultati dell'esecuzione in studio di Azure Machine Learning. È anche possibile eseguire i comandi dell'interfaccia della riga di comando o dell'SDK seguenti per visualizzare i risultati dell'esecuzione.
Eseguire lo streaming dei log
pfazure run stream --name <run-name>
Visualizzare gli output delle esecuzioni
pfazure run show-details --name <run-name>
Visualizzare le metriche di esecuzione della valutazione
pfazure run show-metrics --name <evaluation-run-name>
Integrarsi con DevOps
Una combinazione di un ambiente di sviluppo locale e di un sistema di controllo della versione, ad esempio Git, è in genere più efficace per lo sviluppo iterativo. È infatti possibile apportare modifiche e testare il codice in locale, quindi eseguire il commit delle modifiche in Git. Questo processo crea un record continuo delle modifiche e offre la possibilità di ripristinare le versioni precedenti, se necessario.
Quando è necessario condividere i flussi in ambienti diversi, è possibile eseguirne il push in un repository di codice basato sul cloud, ad esempio GitHub o Azure Repos. Questa strategia consente di accedere alla versione del codice più recente da qualsiasi posizione e fornisce strumenti per la collaborazione e la gestione del codice.
Seguendo queste procedure, i team possono creare un ambiente collaborativo facile, efficiente e produttivo per lo sviluppo di flussi di richiesta.
Ad esempio, pipeline LLMOps end-to-end che eseguono flussi di classificazione Web, vedere Configurare genAIOps end-to-end con prompt Flow e GitHub e il progetto demo di classificazione Web GitHub.
Esecuzione del flusso di trigger nelle pipeline CI
Dopo aver sviluppato e testato correttamente il flusso e averla archiviata come versione iniziale, si è pronti per l'ottimizzazione e il test delle iterazioni. In questa fase è possibile attivare le esecuzioni del flusso, inclusi i test batch e le esecuzioni di valutazione, usando l'interfaccia della riga di comando del flusso di prompt per automatizzare i passaggi nella pipeline CI.
Durante tutto il ciclo di vita delle iterazioni del flusso, è possibile usare l'interfaccia della riga di comando per automatizzare le operazioni seguenti:
- Esecuzione del flusso di richiesta dopo una richiesta pull
- Esecuzione della valutazione del prompt flow per garantire la qualità elevata dei risultati
- Registrazione dei modelli di flusso dei prompt
- Distribuzione di modelli di flusso dei prompt
Usare l'interfaccia utente di Studio per lo sviluppo continuo
In qualsiasi momento dello sviluppo del flusso, è possibile tornare all'interfaccia utente studio di Azure Machine Learning e usare le risorse e le esperienze cloud per apportare modifiche al flusso.
Per continuare a sviluppare e usare le versioni più aggiornate dei file di flusso, è possibile accedere a un terminale nella pagina Notebook ed eseguire il pull dei file di flusso più recenti dal repository. In alternativa, è possibile importare direttamente una cartella del flusso locale come nuovo flusso bozza per eseguire facilmente la transizione tra lo sviluppo locale e il cloud.

Distribuire il flusso come endpoint online
L'ultimo passaggio dell'attività di produzione consiste nel distribuire il flusso come endpoint online in Azure Machine Learning. Questo processo consente di integrare il flusso nell'applicazione e di renderlo disponibile per l'uso. Per altre informazioni su come distribuire il flusso, vedere Distribuire flussi all'endpoint online gestito di Azure Machine Learning per l'inferenza in tempo reale.
Collaborare allo sviluppo di flussi
La collaborazione tra i membri del team può essere essenziale quando si sviluppa un'applicazione basata su LLM con flusso di richiesta. I membri del team possono creare e testare lo stesso flusso, lavorando su facet diversi del flusso o apportando modifiche iterative e miglioramenti simultaneamente. Questa collaborazione richiede un approccio efficiente e semplificato alla condivisione del codice, al rilevamento delle modifiche, alla gestione delle versioni e all'integrazione delle modifiche nel progetto finale.
L'SDK/l'interfaccia della riga di comando del flusso di prompt dei prompt e l'estensione del flusso di VS Code semplificano la collaborazione nello sviluppo di flussi basati su codice all'interno di un repository di codice sorgente. È possibile usare un sistema di controllo del codice sorgente basato sul cloud, ad esempio GitHub o Azure Repos, per tenere traccia delle modifiche, gestire le versioni e integrare queste modifiche nel progetto finale.
Seguire le procedure consigliate per lo sviluppo collaborativo
Configurare un repository di codice centralizzato.
Il primo passaggio del processo di collaborazione prevede la configurazione di un repository di codice come base per il codice del progetto, incluso il codice del flusso di richiesta. Questo repository centralizzato consente un'organizzazione efficiente, il rilevamento delle modifiche e la collaborazione tra i membri del team.
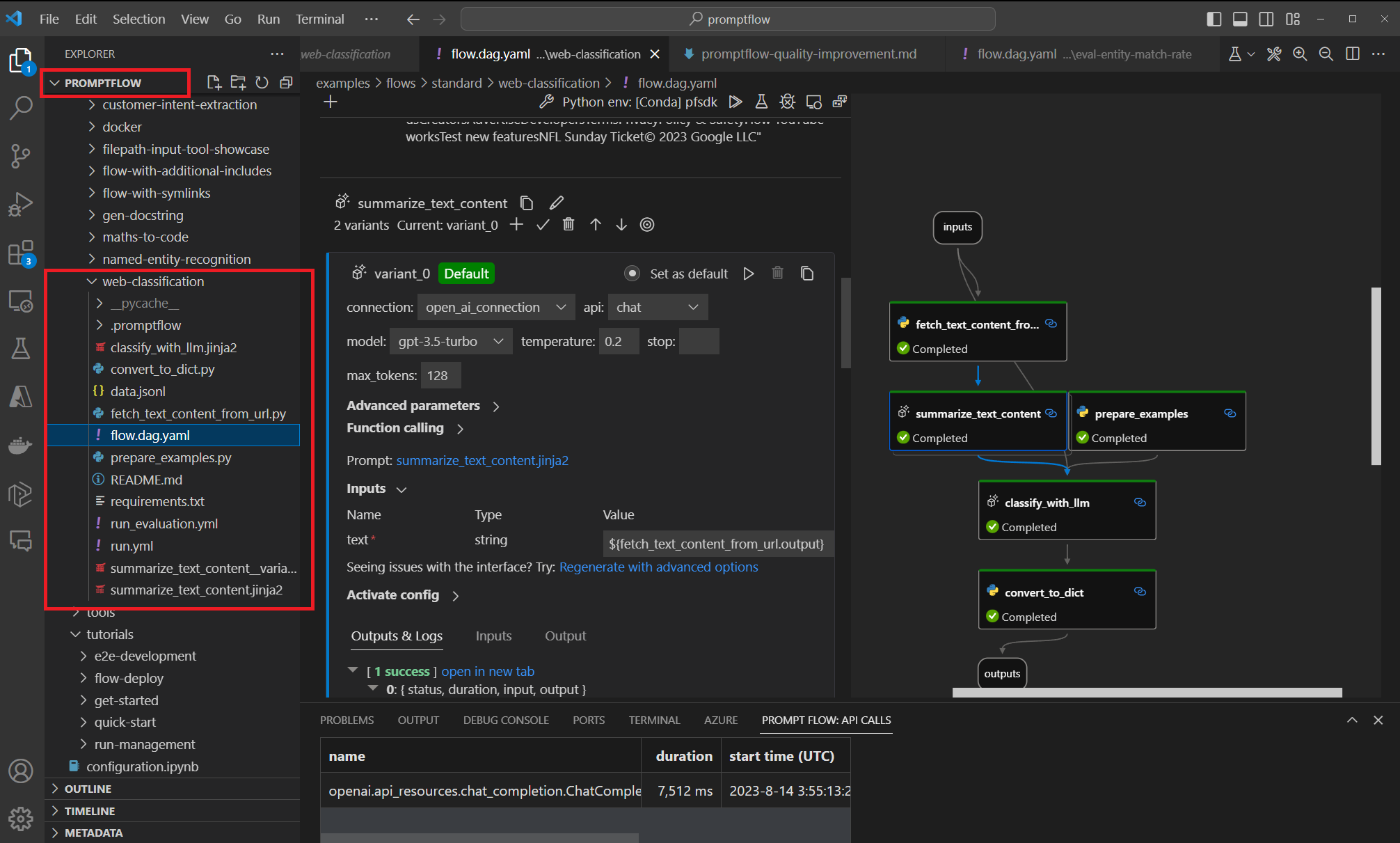
Creare e testare il flusso in locale in VS Code con l'estensione Flusso prompt.
Dopo aver configurato il repository, i membri del team possono usare VS Code con l'estensione Flusso prompt per la creazione locale e il test di input singolo del flusso. L'ambiente di sviluppo integrato standardizzato promuove la collaborazione tra più membri che lavorano su diversi aspetti del flusso.
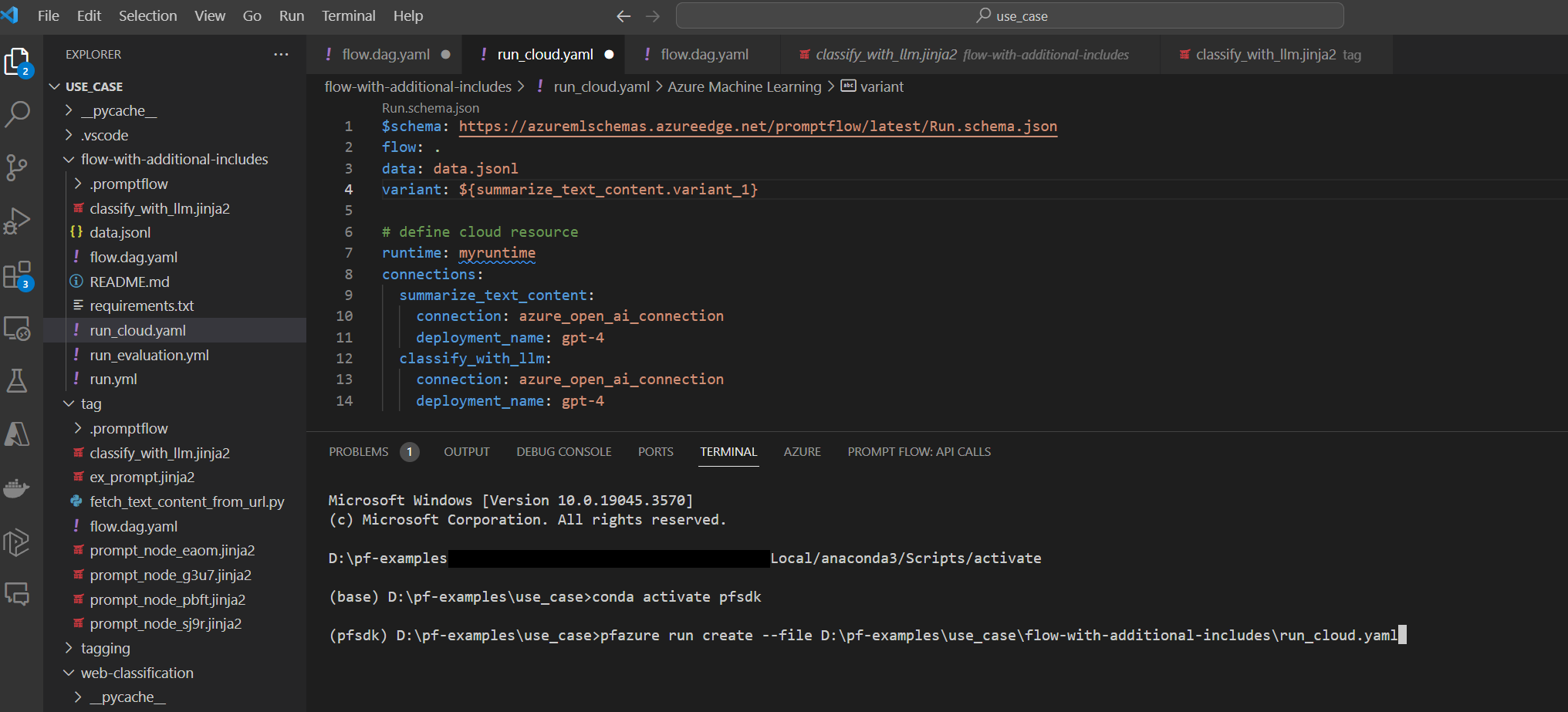
Usare l'interfaccia della riga di comando o l'SDK
pfazureper inviare esecuzioni batch e di valutazione dai flussi locali al cloud.Dopo lo sviluppo e il test locali, i membri del team possono usare l'interfaccia della riga di comando del flusso di richiesta/SDK per inviare e valutare le esecuzioni batch e di valutazione nel cloud. Questo processo consente l'utilizzo del cloud compute, l'archiviazione dei risultati permanenti, la creazione di endpoint per le distribuzioni e una gestione efficiente nell'interfaccia utente di Studio.
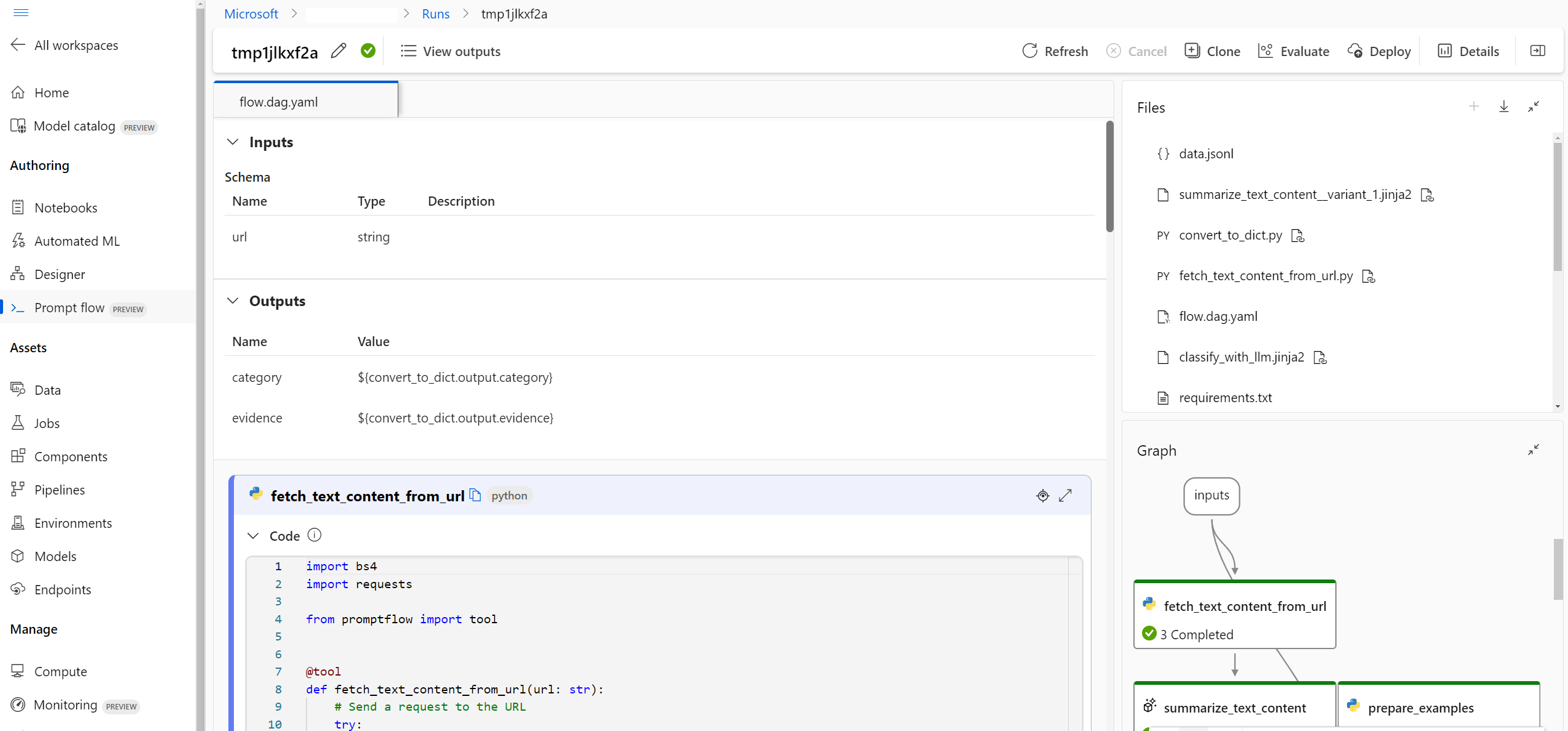
Visualizzare e gestire i risultati dell'esecuzione nell'interfaccia utente dell'area di lavoro studio di Azure Machine Learning.
Dopo l'invio delle esecuzioni al cloud, i membri del team possono accedere all'interfaccia utente di Studio per visualizzare i risultati e gestire gli esperimenti in modo efficiente. L'area di lavoro cloud offre una posizione centralizzata per la raccolta e la gestione della cronologia di esecuzione, dei log, degli snapshot, dei risultati completi e degli input e degli output a livello di istanza.
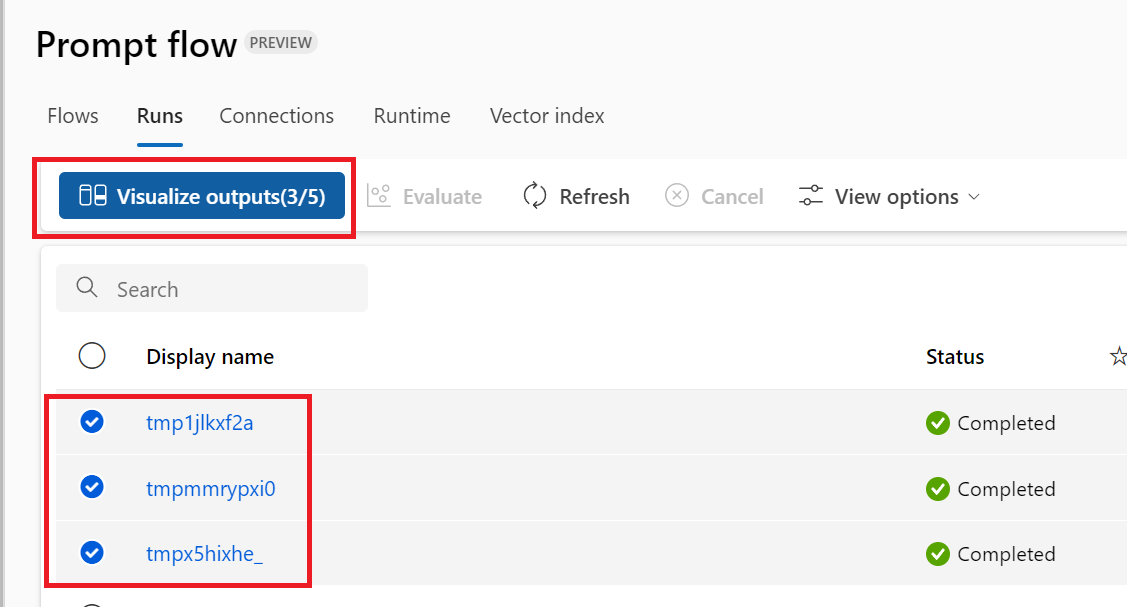
Usare l'elenco Esecuzioni che registra tutta la cronologia di esecuzione per confrontare facilmente i risultati di diverse esecuzioni, supportando l'analisi della qualità e le modifiche necessarie.
Continuare a usare lo sviluppo iterativo locale.
Dopo aver analizzato i risultati degli esperimenti, i membri del team possono tornare all'ambiente locale e al repository di codice per altre attività di sviluppo e ottimizzazione e inviare in modo iterativo le esecuzioni successive al cloud. Questo approccio iterativo garantisce un miglioramento coerente fino a quando il team non è soddisfatto della qualità per la produzione.
Usare la distribuzione in un unico passaggio nell'ambiente di produzione in studio.
Una volta che il team è completamente sicuro della qualità del flusso, può distribuirlo facilmente come endpoint online in un ambiente cloud affidabile. La distribuzione come endpoint online può essere basata su uno snapshot di esecuzione, consentendo una gestione stabile e sicura, un'ulteriore allocazione delle risorse e il monitoraggio dell'utilizzo e il monitoraggio dei log nel cloud.
La distribuzione guidata studio di Azure Machine Learning consente di configurare facilmente la distribuzione.






