Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: SDK Azure Machine Learning v1 per Python
SDK Azure Machine Learning v1 per Python
Importante
Questo articolo fornisce informazioni sull'uso di Azure Machine Learning SDK v1. SDK v1 è deprecato a partire dal 31 marzo 2025. Il supporto per questo terminerà il 30 giugno 2026. È possibile installare e usare l'SDK v1 fino a tale data. I flussi di lavoro esistenti che usano SDK v1 continueranno a funzionare dopo la data di fine del supporto. Tuttavia, potrebbero essere esposti a rischi per la sicurezza o a modifiche di rilievo nel caso di cambiamenti dell'architettura del prodotto.
È consigliabile passare all'SDK v2 prima del 30 giugno 2026. Per altre informazioni su SDK v2, vedere Che cos'è l'interfaccia della riga di comando di Azure Machine Learning e Python SDK v2? e il Riferimento SDK v2.
Questo articolo mostra come eseguire il training di un modello di regressione con Python SDK di Azure Machine Learning tramite Machine Learning automatizzato di Azure Machine Learning. Il modello di regressione prevede le tariffe dei passeggeri per i taxi che operano a New York City (NYC). È sufficiente scrivere codice con Python SDK per configurare un'area di lavoro con dati preparati, eseguire il training del modello in locale con parametri personalizzati ed esplorare i risultati.
Il processo accetta i dati di training e le impostazioni di configurazione. Esegue automaticamente l'iterazione combinando diversi metodi di normalizzazione/standardizzazione delle caratteristiche, modelli e impostazioni degli iperparametri per determinare il modello migliore. Il diagramma seguente illustra il flusso del processo per il training del modello di regressione:
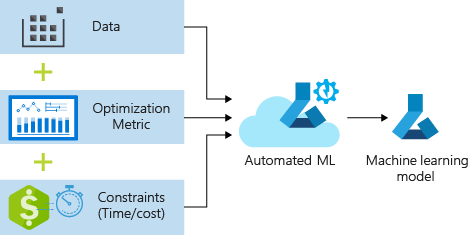
Prerequisiti
Una sottoscrizione di Azure. È possibile creare un account gratuito o a pagamento di Azure Machine Learning.
Un'area di lavoro di Azure Machine Learning e un'istanza dell’ambiente di calcolo. Per preparare queste risorse, vedere Guida introduttiva: Introduzione ad Azure Machine Learning.
Ottenere i dati di esempio preparati per gli esercizi dell'esercitazione caricando un notebook nell'area di lavoro:
Passare all'area di lavoro nello studio di Azure Machine Learning, selezionare Notebooke quindi selezionare la scheda Esempi.
Nell’elenco dei notebook espandere il nodo Esempi>SDK v1>Esercitazioni>regression-automl-nyc-taxi-data.
Selezionare il notebook regression-automated-ml.ipynb.
Per eseguire ogni cella del notebook come parte dell’esercitazione, selezionare Clona questo file.
Approccio alternativo: se si preferisce, è possibile eseguire gli esercizi dell'esercitazione in un ambiente locale. L'esercitazione è disponibile nel repository dei notebook di Azure Machine Learning in GitHub. Per questo approccio, seguire questa procedura per ottenere i pacchetti necessari:
Eseguire il comando
pip install azureml-opendatasets azureml-widgetsnel computer locale per ottenere i pacchetti necessari.
Scaricare e preparare i dati
Il pacchetto Open Datasets contiene una classe che rappresenta ogni origine dati (ad esempio NycTlcGreen) e che consente di filtrare facilmente i parametri della data prima del download.
Il codice seguente importa i pacchetti necessari:
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
Il primo passaggio consiste nel creare un DataFrame per i dati dei taxi. Quando si lavora in un ambiente non Spark, il pacchetto Open Datasets consente di scaricare solo un mese di dati alla volta con determinate classi. Questo approccio consente di evitare il problema MemoryError che può verificarsi con i set di dati di grandi dimensioni.
Per scaricare i dati dei taxi, recuperare in modo iterativo un mese alla volta. Prima di aggiungere il set di dati successivo al DataFrame green_taxi_df, campionare in modo casuale 2.000 record di ogni mese e quindi visualizzare in anteprima i dati. Questo approccio consente di evitare di aumentare eccessivamente le dimensioni del DataFrame.
Il codice seguente crea il DataFrame, recupera i dati e li carica nel DataFrame:
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
La tabella seguente mostra le numerose colonne di valori nei dati dei taxi di esempio:
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | distanza del viaggio | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | tipo di pagamento | fareAmount | aggiuntivo | mtaTax | improvementSurcharge | tipAmount | importo pedaggi | ehailFee | totalAmount | tipo di viaggio |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2015-01-30 18:38:09 | 2015-01-30 19:01:49 | 1 | 1,88 | Nessuno | Nessuno | -73.996155 | 40.690903 | -73.964287 | ... | 1 | 15,0 | 1.0 | 0,5 | 0,3 | 4.00 | 0.0 | Nessuno | 20.80 | 1.0 |
| 1 | 2015-01-17 23:21:39 | 2015-01-17 23:35:16 | 1 | 2.70 | Nessuno | Nessuno | -73.978508 | 40.687984 | -73.955116 | ... | 1 | 11.5 | 0,5 | 0,5 | 0,3 | 2.55 | 0.0 | Nessuno | 15.35 | 1.0 |
| 2 | 2015-01-16 01:38:40 | 2015-01-16 01:52:55 | 1 | 3,54 | Nessuno | Nessuno | -73.957787 | 40.721779 | -73.963005 | ... | 1 | 13,5 | 0,5 | 0,5 | 0,3 | 2.80 | 0.0 | Nessuno | 17.60 | 1.0 |
| 2 | 2015-01-04 17:09:26 | 2015-01-04 17:16:12 | 1 | 1,00 | Nessuno | Nessuno | -73.919914 | 40.826023 | -73.904839 | ... | 2 | 6.5 | 0.0 | 0,5 | 0,3 | 0,00 | 0.0 | Nessuno | 7.30 | 1.0 |
| 1 | 2015-01-14 10:10:57 | 2015-01-14 10:33:30 | 1 | 5.10 | Nessuno | Nessuno | -73.943710 | 40.825439 | -73.982964 | ... | 1 | 18,5 | 0.0 | 0,5 | 0,3 | 3.85 | 0.0 | Nessuno | 23.15 | 1.0 |
| 2 | 2015-01-19 18:10:41 | 2015-01-19 18:32:20 | 1 | 7,41 | Nessuno | Nessuno | -73.940918 | 40.839714 | -73.994339 | ... | 1 | 24.0 | 0.0 | 0,5 | 0,3 | 4,80 | 0.0 | Nessuno | 29,60 | 1.0 |
| 2 | 2015-01-01 15:44:21 | 2015-01-01 15:50:16 | 1 | 1,03 | Nessuno | Nessuno | -73.985718 | 40.685646 | -73.996773 | ... | 1 | 6.5 | 0.0 | 0,5 | 0,3 | 1,30 | 0.0 | Nessuno | 8.60 | 1.0 |
| 2 | 2015-01-12 08:01:21 | 2015-01-12 08:14:52 | 5 | 2.94 | Nessuno | Nessuno | -73.939865 | 40.789822 | -73.952957 | ... | 2 | 12.5 | 0.0 | 0,5 | 0,3 | 0,00 | 0.0 | Nessuno | 13.30 | 1.0 |
| 1 | 2015-01-16 21:54:26 | 2015-01-16 22:12:39 | 1 | 3,00 | Nessuno | Nessuno | -73.957939 | 40.721928 | -73.926247 | ... | 1 | 14,0 | 0,5 | 0,5 | 0,3 | 2,00 | 0.0 | Nessuno | 17:30 | 1.0 |
| 2 | 2015-01-06 06:34:53 | 2015-01-06 06:44:23 | 1 | 2.31 | Nessuno | Nessuno | -73.943825 | 40.810257 | -73.943062 | ... | 1 | 10.0 | 0.0 | 0,5 | 0,3 | 2,00 | 0.0 | Nessuno | 12,80 | 1.0 |
È utile rimuovere alcune colonne che non sono necessarie per il training o per la compilazione di altre funzionalità. Ad esempio, è possibile rimuovere la colonna lpepPickupDatetime perché Machine Learning automatizzato gestisce automaticamente le funzionalità basate sul tempo.
Il codice seguente rimuove 14 colonne dai dati di esempio:
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Pulire i dati
Il passaggio successivo consiste nel pulire i dati.
Il codice seguente esegue la funzione describe() nel nuovo DataFrame per produrre statistiche di riepilogo per ogni campo:
green_taxi_df.describe()
La tabella seguente mostra le statistiche di riepilogo per i campi rimanenti nei dati di esempio:
| vendorID | passengerCount | distanza del viaggio | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | |
|---|---|---|---|---|---|---|---|---|
| count | 24.000,00 | 24.000,00 | 24.000,00 | 24.000,00 | 24.000,00 | 24.000,00 | 24.000,00 | 24.000,00 |
| mean | 1.777625 | 1.373625 | 2,893981 | -73.827403 | 40.689730 | -73.819670 | 40.684436 | 14.892744 |
| std | 0.415850 | 1.046180 | 3.072343 | 2.821767 | 1.556082 | 2.901199 | 1.599776 | 12.339749 |
| minuti | 1,00 | 0,00 | 0,00 | -74.357101 | 0,00 | -74.342766 | 0,00 | -120.80 |
| 25% | 2,00 | 1,00 | 1,05 | -73.959175 | 40.699127 | -73.966476 | 40.699459 | 8,00 |
| 50% | 2,00 | 1,00 | 1,93 | -73.945049 | 40.746754 | -73.944221 | 40.747536 | 11,30 |
| 75% | 2,00 | 1,00 | 3.70 | -73.917089 | 40.803060 | -73.909061 | 40.791526 | 17,80 |
| max | 2,00 | 8,00 | 154.28 | 0,00 | 41.109089 | 0,00 | 40.982826 | 425.00 |
Le statistiche di riepilogo rivelano la presenza di diversi campi outlier, ovvero di valori che riducono l'accuratezza del modello. Per risolvere questo problema, filtrare i campi latitudime/longitudine (lat/long) in modo che i valori rientrino entro i limiti dell'area di Manhattan. In questo modo vengono filtrate le corse dei taxi più lunghe o le corse che sono outlier rispetto alla relazione con altre funzionalità.
Filtrare inoltre il campo tripDistance in modo che sia maggiore di zero ma minore di 31 miglia (la distanza dell'emisenoverso tra le due coppie latitudine/longitudine). In questo modo si eliminano le corse outlier lunghe con costi di viaggio incoerenti.
Infine, il campo totalAmount contiene valori negativi per le tariffe dei taxi, che non hanno senso nel contesto del modello. Il campo passengerCount contiene anche dati non validi il cui valore minimo è zero.
Il codice seguente filtra queste anomalie dei valori usando le funzioni di query. Il codice rimuove quindi le ultime colonne non necessarie per il training:
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
L'ultimo passaggio di questa sequenza consiste nel chiamare di nuovo la funzione describe() sui dati per garantire che la pulizia funzioni come previsto. È ora disponibile un set preparato e pulito di dati relativi a taxi, festività e meteo da usare per il training del modello di Machine Learning.
final_df.describe()
Configurare l'area di lavoro
Creare un oggetto area di lavoro dall'area di lavoro esistente. Un'area di lavoro è una classe che accetta le informazioni sulla sottoscrizione e sulle risorse di Azure. Crea inoltre una risorsa cloud per monitorare le esecuzioni del modello e tenerne traccia.
Il codice seguente chiama la funzione Workspace.from_config()che legge il file config.json e carica i dettagli di autenticazione in un oggetto denominato ws.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
L’oggetto ws viene usato in tutta la parte restante del codice di questa esercitazione.
Dividere i dati in set di traning e di test
Dividere i dati in set di training e test usando la funzione train_test_split nella libreria scikit-learn. Questa funzione separa i dati nel set di dati x (caratteristiche) per il training del modello e nel set di dati y (valori da stimare) per il test.
Il parametro test_size determina la percentuale di dati da allocare al test. Il parametro random_state imposta un valore di inizializzazione sul generatore di casuale, in modo che le divisioni training-test siano deterministiche.
Il codice seguente chiama la funzione train_test_split che carica i set di dati x e y:
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
Lo scopo di questo passaggio è preparare i punti dati per testare il modello finito che non vengono usati per eseguire il training del modello. Questi punti vengono usati per misurare la vera accuratezza. Un modello con training corretto è un modello in grado di eseguire stime accurate da dati non visualizzati. A questo punto sono stati preparati i dati per il training automatico di un modello di Machine Learning.
Eseguire il training automatico di modelli
Per eseguire il training automatico di un modello, eseguire queste operazioni:
Definire le impostazioni per l'esecuzione dell'esperimento. Allegare i dati di training alla configurazione e modificare le impostazioni che controllano il processo di training.
Inviare l'esperimento per l'ottimizzazione del modello. Dopo aver inviato l'esperimento, il processo esegue l'iterazione usando diversi algoritmi di machine learning e impostazioni di iperparametri, rispettando i vincoli definiti dall'utente. Sceglie il modello più appropriato ottimizzando una metrica di accuratezza.
Definire le impostazioni di training
Definire le impostazioni del modello e dei parametri dell'esperimento per il training. Visualizzare l'elenco completo delle impostazioni. L'invio dell'esperimento con queste impostazioni predefinite richiede circa 5-20 minuti. Per ridurre il tempo di esecuzione, ridurre il valore del parametro experiment_timeout_hours.
| Proprietà | Valore in questa esercitazione | Descrizione |
|---|---|---|
iteration_timeout_minutes |
10 | Limite di tempo in minuti per ogni iterazione. Aumentare questo valore per i set di dati più grandi in cui ogni iterazione richiede più tempo. |
experiment_timeout_hours |
0,3 | Quantità massima di tempo, in ore, che tutte le iterazioni combinate possono impiegare prima che l'esperimento venga terminato. |
enable_early_stopping |
True | Flag che abilita la terminazione anticipata se il punteggio non sta migliorando a breve termine. |
primary_metric |
spearman_correlation | Metrica che si vuole ottimizzare. Verrà scelto il modello più appropriato in base a questa metrica. |
featurization |
auto | Il valore auto consente all'esperimento di pre-elaborare i dati di input, inclusi la gestione dei dati mancanti, la conversione del testo in dati numerici e così via. |
verbosity |
logging.INFO | Controlla il livello di dettaglio della registrazione. |
n_cross_validations |
5 | Numero di divisioni di convalida incrociata da eseguire quando i dati di convalida non sono specificati. |
Il codice seguente invia l'esperimento:
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Il codice seguente consente di usare le impostazioni di training definite come parametro **kwargs per un oggetto AutoMLConfig. In aggiunta, è necessario specificare i dati di training e il tipo di modello, ovvero regression in questo caso.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Note
I passaggi di pre-elaborazione di Machine Learning automatizzato (normalizzazione delle funzionalità, gestione dei dati mancanti, conversione dei valori di testo in formato numerico e così via) diventano parte del modello sottostante. Quando si usa il modello per le previsioni, gli stessi passaggi di pre-elaborazione applicati durante il training vengono automaticamente applicati anche ai dati di input.
Eseguire il training del modello di regressione automatica
Creare un oggetto esperimento nell'area di lavoro. Un esperimento funge da contenitore per i singoli processi. Passare l'oggetto automl_config definito all'esperimento e impostare l'output su True per visualizzare lo stato di avanzamento durante il processo.
Dopo aver avviato l'esperimento, l'output visualizzato viene aggiornato in tempo reale durante l'esecuzione dell'esperimento. Per ogni iterazione, vengono visualizzati il tipo di modello, la durata dell'esecuzione e l'accuratezza del training. Il campo BEST tiene traccia dell miglior punteggio di training in esecuzione in base del tipo di metrica.
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Ecco l'output:
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Esplorare i risultati
Esplorare i risultati del training automatico usando un widget di Jupyter. Il widget consente di visualizzare un grafico e una tabella di tutte le iterazioni di processo singole, insieme alle metriche e ai metadati di accuratezza del training. Inoltre, è possibile filtrare in base a metriche di accuratezza diverse rispetto alla metrica primaria con il selettore a discesa.
Il codice seguente produce un grafico in cui è possibile esplorare i risultati:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
Dettagli dell'esecuzione per il widget Jupyter:

Grafico del tracciato per il widget Jupyter:

Recuperare il modello migliore
Il codice seguente consente di selezionare il modello migliore dalle iterazioni. La funzione get_output restituisce l'esecuzione migliore e il modello più adatto per l'ultima chiamata alla funzione di fit. L’uso degli overload nella funzione get_output consente di recuperare l'esecuzione migliore e il modello più adatto a qualsiasi metrica registrata o a un'iterazione specifica.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
Testare l’accuratezza del modello migliore:
Usare il modello migliore per eseguire stime sul set di dati di test per stimare le tariffe dei taxi. La funzione predict usa il modello migliore ed esegue una stima dei valori di y (costo della corsa) in base al set di dati x_test.
Il codice seguente stampa i primi 10 valori dei costi stimati dal set di dati y_predict:
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Calcolare il root mean squared error dei risultati. Convertire il DataFramrey_test in un elenco da confrontare con i valori previsti. La funzione mean_squared_error accetta due matrici di valori e calcola l'errore quadratico medio tra di essi. La radice quadrata del risultato restituisce un errore nelle stesse unità di misura della variabile y, cost. Indica approssimativamente quanto le stime dei prezzi delle corse in taxi si discostano dai prezzi effettivi.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Eseguire il codice seguente per calcolare l'errore percentuale assoluto medio usando i set di dati completi y_actual e y_predict. Questa metrica calcola una differenza assoluta tra ogni valore stimato ed effettivo e somma tutte le differenze. Esprime quindi la somma come percentuale del totale dei valori effettivi.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Ecco l'output:
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
Dalle due metriche di accuratezza della stima finali, si nota che il modello esegue una stima discreta dei prezzi delle corse in taxi in base alle funzionalità del set di dati, in genere con un margine di $4.00 in eccesso o in difetto e un errore di circa il 15%.
Il processo di sviluppo tradizionale del modello di Machine Learning è a elevato utilizzo di risorse. Richiede un notevole investimento in termini di dominio e tempo per l'esecuzione e il confronto dei risultati di decine di modelli. L'uso dell'apprendimento automatico automatizzato è un ottimo modo per testare rapidamente molti modelli diversi per il proprio scenario.
Pulire le risorse
Se non si prevede di lavorare su altre esercitazioni di Azure Machine Learning, completare la procedura seguente per rimuovere le risorse non più necessarie.
Arrestare il calcolo
Se si usa un ambiente di calcolo, è possibile arrestare la macchina virtuale quando non viene usata e ridurre i costi:
Passare all'area di lavoro nello studio di Azure Machine Learning e selezionare Calcolo.
Nell'elenco selezionare il calcolo che si vuole arrestare e quindi selezionare Arresta.
Quando si è pronti a usare di nuovo il calcolo, è possibile riavviare la macchina virtuale.
Eliminare altre risorse
Se non si prevede di usare le risorse create in questa esercitazione, è possibile eliminarle ed evitare costi aggiuntivi.
Seguire questa procedura per rimuovere il gruppo di risorse e tutte le risorse:
Nel portale di Azure passare a Gruppi di risorse.
Nell'elenco selezionare il gruppo di risorse creato in questa esercitazione e quindi selezionare Elimina gruppo di risorse.
Appena viene visualizzata la richiesta di conferma, immettere il nome del gruppo di risorse, quindi selezionare Elimina.
Per mantenere il gruppo di risorse ed eliminare una singola area di lavoro, seguire questa procedura:
Nel portale di Azure passare al gruppo di risorse che contiene l'area di lavoro da rimuovere.
Selezionare l'area di lavoro, selezionare Proprietàe quindi Elimina.