Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive come sviluppare uno script di training usando un notebook in una workstation cloud di Azure Machine Learning. L'esercitazione illustra i passaggi di base necessari per iniziare:
- Impostare e configurare la workstation cloud. La tua workstation cloud è alimentata da un'istanza di calcolo di Azure Machine Learning, preconfigurata con ambienti per supportare le tue esigenze di sviluppo del modello.
- Usare ambienti di sviluppo basati sul cloud.
- Usare MLflow per tenere traccia delle metriche del modello.
Prerequisiti
Per usare Azure Machine Learning, è necessaria un'area di lavoro. Se non è disponibile, completare Creare le risorse necessarie per iniziare creare un'area di lavoro e ottenere maggiori informazioni su come usarla.
Importante
Se l'area di lavoro di Azure Machine Learning è configurata con una rete virtuale gestita, potrebbe essere necessario aggiungere regole in uscita per consentire l'accesso ai repository di pacchetti Python pubblici. Per altre informazioni, vedere Scenario: accedere ai pacchetti di apprendimento automatico pubblici.
Creare o avviare il calcolo
È possibile creare risorse di calcolo nella sezione Calcolo dell'area di lavoro. Un'istanza di calcolo è una workstation basata sul cloud completamente gestita da Azure Machine Learning. Questa serie di esercitazioni usa un'istanza di ambiente di calcolo. È anche possibile usarla per eseguire codice personalizzato e per sviluppare e testare modelli.
- Accedere ad Azure Machine Learning Studio.
- Seleziona l'area di lavoro, se non è già aperta.
- Nel riquadro sinistro selezionare Calcolo.
- Se non si dispone di un'istanza di calcolo, nella parte centrale della pagina viene visualizzato Nuovo . Selezionare Nuovo e compilare il modulo. È possibile usare tutte le impostazioni predefinite.
- Se è disponibile un'istanza di ambiente di calcolo, selezionarla nell'elenco. Se è arrestata, selezionare Avvia.
Aprire Visual Studio Code (VS Code)
Dopo aver creato un'istanza di calcolo in esecuzione, è possibile accedervi in diversi modi. Questa esercitazione descrive come usare l'istanza di calcolo di Visual Studio Code. Visual Studio Code offre un ambiente di sviluppo integrato completo (IDE) per la creazione di istanze di calcolo.
Nell'elenco delle istanze di ambiente di calcolo selezionare il collegamento VS Code (Web) o VS Code (Desktop) per l'istanza di ambiente di calcolo da usare. Se si sceglie VS Code (desktop), potrebbe essere visualizzato un messaggio che chiede se si vuole aprire l'applicazione.

Questa istanza di Visual Studio Code è collegata all'istanza di calcolo e al file system dell'area di lavoro. Anche se la si apre sul desktop, i file visualizzati sono file nell'area di lavoro.
Configurare un nuovo ambiente per la creazione di prototipi
Per consentire l'esecuzione dello script, è necessario lavorare in un ambiente configurato con le dipendenze e le librerie previste dal codice. Questa sezione illustra come creare un ambiente personalizzato per il codice. Per creare il nuovo kernel Jupyter a cui si connette il notebook, usare un file YAML che definisce le dipendenze.
Caricare un file.
I file caricati vengono archiviati in una condivisione file di Azure e questi file vengono montati in ogni istanza di calcolo e condivisi all'interno dell'area di lavoro.
Passare ad azureml-examples/tutorials/get-started-notebooks/workstation_env.yml.
Scaricare il file di ambiente Conda workstation_env.yml nel computer selezionando il pulsante con i puntini di sospensione (...) nell'angolo superiore destro della pagina e quindi selezionando Scarica.
Trascinare il file dal computer alla finestra di Visual Studio Code. Il file viene caricato nell'area di lavoro.
Spostare il file nella cartella del nome utente.
Selezionare il file per visualizzare l'anteprima. Esaminare le dipendenze specificate. Dovresti vedere qualcosa di simile a questo:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibCreare un kernel.
Usare ora il terminale per creare un nuovo kernel Jupyter basato sul file workstation_env.yml .
- Nel menu nella parte superiore di Visual Studio Code selezionare Terminale > nuovo terminale.
Visualizza gli ambienti Conda correnti. L'ambiente attivo è contrassegnato con un asterisco (*).
conda env listUsare
cdper passare alla cartella in cui è stato caricato il file workstation_env.yml . Ad esempio, se è stato caricato nella cartella utente, usare questo comando:cd Users/myusernameAssicurarsi che workstation_env.yml si trova nella cartella .
lsCreare l'ambiente in base al file Conda fornito. La compilazione dell'ambiente richiede alcuni minuti.
conda env create -f workstation_env.ymlAttivare il nuovo ambiente.
conda activate workstation_envNote
Se viene visualizzato CommandNotFoundError, seguire le istruzioni per eseguire
conda init bash, chiudere il terminale e quindi aprirne uno nuovo. Quindi riprovare il comandoconda activate workstation_env.Verificare che l'ambiente corretto sia attivo, cercando di nuovo l'ambiente contrassegnato con un *.
conda env listCreare un nuovo kernel Jupyter basato sull'ambiente attivo.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Chiudere la finestra del terminale.
Sarà ora disponibile un nuovo kernel. Si aprirà quindi un notebook e si userà questo kernel.
Creare un notebook
- Nel menu nella parte superiore di Visual Studio Code selezionare File > nuovo file.
- Assegnare al nuovo file il nome develop-tutorial.ipynb (o usare un altro nome). Assicurarsi di usare l'estensione .ipynb .
Impostare il kernel
- Nell'angolo in alto a destra del nuovo file, selezionare Seleziona Kernel.
- Selezionare Istanza di ambiente di calcolo di Azure ML (computeinstance-name).
- Selezionare il kernel creato: Tutorial Workstation Env. Se il kernel non viene visualizzato, selezionare il pulsante Aggiorna sopra l'elenco.
Sviluppare uno script di training
In questa sezione sviluppate uno script di training Python che prevede i pagamenti inadempienti delle carte di credito utilizzando i set di dati di test e di addestramento preparati dal set di dati UCI.
Questo codice usa sklearn per il training e MLflow per la registrazione delle metriche.
Iniziare con il codice che importa i pacchetti e le librerie che verranno usati nello script di training.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitCaricare ed elaborare quindi i dati per l'esperimento. In questo esempio si leggono i dati da un file in Internet.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Preparare i dati per il training.
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesAggiungere codice per avviare la registrazione automatica con MLflow in modo da poter tenere traccia delle metriche e dei risultati. Con la natura iterativa dello sviluppo di modelli, MLflow consente di registrare i parametri e i risultati del modello. Fare riferimento a esecuzioni diverse per confrontare e comprendere le prestazioni del modello. I log forniscono anche il contesto per quando si è pronti per passare dalla fase di sviluppo a quella di training dei flussi di lavoro in Azure Machine Learning.
# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Eseguire il training di un modello.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Note
È possibile ignorare gli avvisi di MLflow. I risultati necessari verranno comunque monitorati.
Selezionare Esegui tutto sopra il codice.
Iterare
Dopo aver ottenuto i risultati del modello, modificare un elemento ed eseguire di nuovo il modello. Ad esempio, provare una tecnica di classificazione diversa:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Note
È possibile ignorare gli avvisi di MLflow. I risultati necessari verranno comunque monitorati.
Selezionare Esegui tutto per eseguire il modello.
Esaminare i risultati
Dopo aver provato due modelli diversi, usare i risultati rilevati da MLFfow per decidere quale modello è migliore. È possibile fare riferimento a metriche come l'accuratezza o altri indicatori più importanti per gli scenari. È possibile esaminare questi risultati in modo più dettagliato esaminando i processi creati da MLflow.
Tornare all'area di lavoro nello studio di Azure Machine Learning.
Nel riquadro a sinistra selezionare Processi.
Seleziona il tutorial Sviluppare nel cloud.
Sono visualizzati due lavori, uno per ciascuno dei modelli che hai provato. I nomi vengono generati automaticamente. Per rinominare il processo, passare il puntatore del mouse sul nome e selezionare il pulsante a forma di matita accanto.
Selezionare il collegamento per il primo processo. Il nome viene visualizzato nella parte superiore della pagina. È anche possibile rinominarlo qui usando il pulsante a forma di matita.
La pagina mostra i dettagli del processo, ad esempio proprietà, output, tag e parametri. In Tag viene visualizzato il estimator_name, che descrive il tipo di modello.
Selezionare la scheda Metriche per visualizzare le metriche registrate da MLflow. I risultati saranno diversi perché si dispone di un set di training diverso.
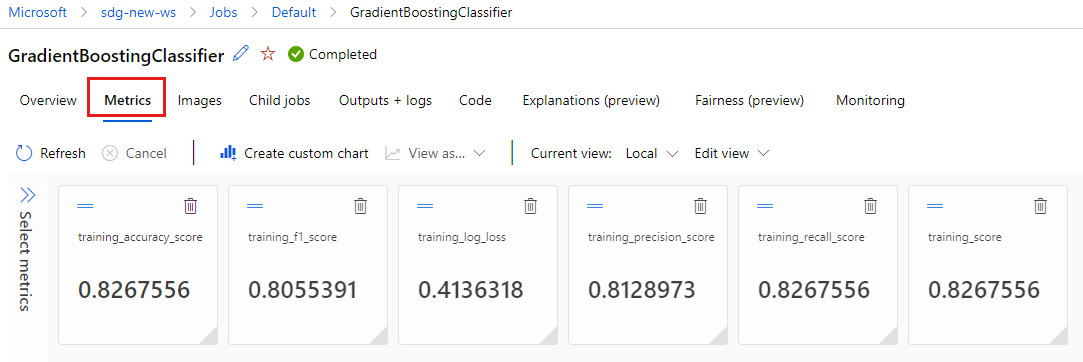
Selezionare la scheda Immagini per visualizzare le immagini generate da MLflow.
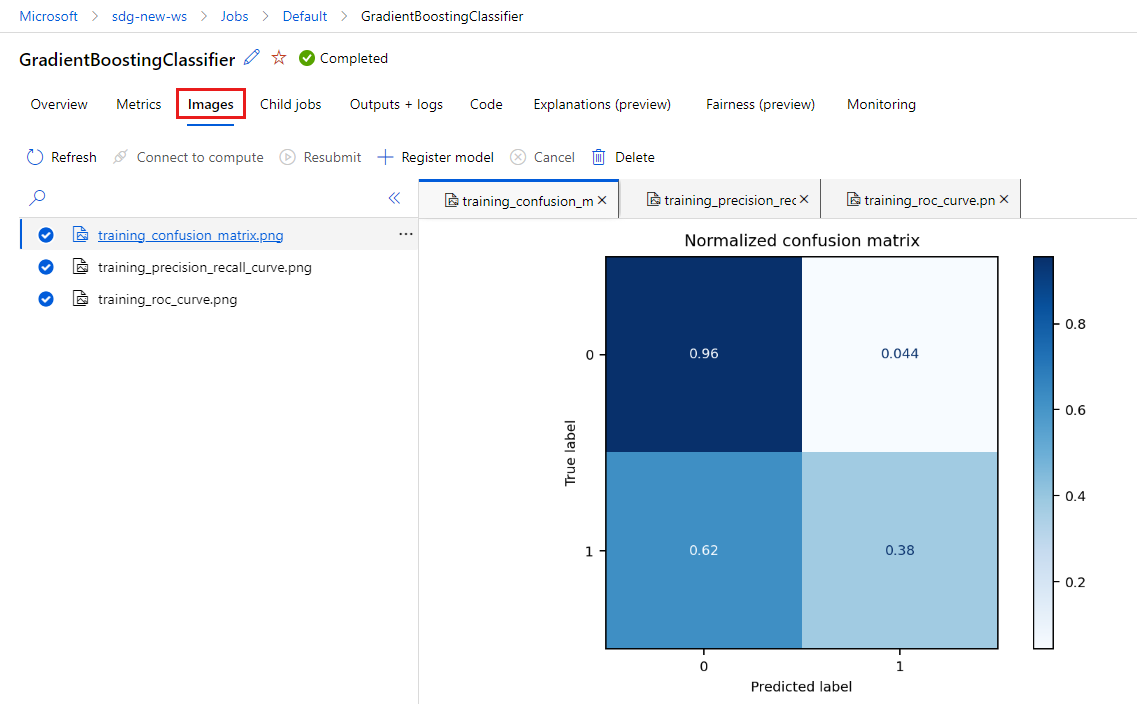
Tornare indietro ed esaminare le metriche e le immagini per l'altro modello.

Creare uno script Python
Ora creerai uno script Python dal tuo notebook per il training del modello.
In Visual Studio Code fare clic con il pulsante destro del mouse sul nome del file del notebook e scegliere Importa notebook in script.
Selezionare Salva file > per salvare il nuovo file di script. Assegnare al file il nome train.py.
Esaminare il file ed eliminare il codice che non si vuole nello script di training. Ad esempio, mantenere il codice per il modello che si vuole usare ed eliminare il codice per il modello che non si vuole usare.
- Assicurati di mantenere il codice che avvia l'autologging (
mlflow.sklearn.autolog()). - Quando si esegue lo script Python in modo interattivo, come in questo caso, è possibile mantenere la riga che definisce il nome dell'esperimento (
mlflow.set_experiment("Develop on cloud tutorial")). In alternativa, è possibile assegnare un nome diverso per vederlo come voce diversa nella sezione Lavori . Tuttavia, quando si prepara lo script per un processo di training, tale riga non si applica e deve essere omessa: la definizione del processo include il nome dell'esperimento. - Quando si esegue il training di un singolo modello, le linee per avviare e terminare un'esecuzione (
mlflow.start_run()emlflow.end_run()) non sono necessarie (non hanno alcun effetto), ma è possibile lasciarle.
- Assicurati di mantenere il codice che avvia l'autologging (
Dopo aver apportato tutte le modifiche, salvare il file.
A questo punto si dispone di uno script Python da usare per il training del modello preferito.
Eseguire lo script Python
Per il momento, questo codice viene eseguito nell'istanza di ambiente di calcolo, ovvero l'ambiente di sviluppo di Azure Machine Learning. Esercitazione: Eseguire il training di un modello illustra come eseguire uno script di training in modo più scalabile su risorse di calcolo più potenti.
Selezionare l'ambiente creato in precedenza in questa esercitazione come versione di Python (workstations_env). Nell'angolo in basso a destra del notebook verrà visualizzato il nome dell'ambiente. Selezionarlo e quindi selezionare l'ambiente nella parte superiore di Visual Studio Code.
Eseguire lo script Python selezionando il pulsante Esegui tutto sopra il codice.


Note
È possibile ignorare gli avvisi di MLflow. Si otterranno comunque tutte le metriche e le immagini dalla registrazione automatica.
Esaminare i risultati dello script
Tornare a Processi nell'area di lavoro nello studio di Azure Machine Learning per visualizzare i risultati dello script di training. Tenere presente che i dati di training cambiano con ogni suddivisione, quindi i risultati differiscono tra le esecuzioni.
Pulire le risorse
Se si prevede di continuare con altre esercitazioni, passare a Passaggi successivi.
Arrestare l'istanza di calcolo
Se non si prevede di usare subito l'istanza di ambiente di calcolo, arrestarla:
- Nel riquadro sinistro dello studio selezionare Calcolo.
- Nella parte superiore della pagina selezionare Istanze di calcolo.
- Nell'elenco selezionare l'istanza di calcolo.
- Nella parte superiore della pagina selezionare Arresta.
Eliminare tutte le risorse
Importante
Le risorse create possono essere usate come prerequisiti per altre esercitazioni e articoli esplicativi per Azure Machine Learning.
Se non si prevede di usare le risorse create, eliminarle per evitare addebiti:
Nella casella di ricerca del portale di Azure, immettere Gruppi di risorse e selezionarlo nei risultati.
Dell'elenco, selezionare il gruppo di risorse creato.
Nella pagina Panoramica, selezionare Elimina gruppo di risorse.
Immettere il nome del gruppo di risorse. Selezionare Elimina.
Passaggi successivi
Per altre informazioni, vedere queste risorse:
- Artefatti e modelli in MLflow
- Using Git with Azure Machine Learning (Uso di Git con Azure Machine Learning)
- Eseguire notebook Jupyter nell'area di lavoro
- Accedere a un terminale dell'istanza di ambiente di calcolo nell'area di lavoro
- Gestire le sessioni del notebook e del terminale
Questa esercitazione illustra i primi passaggi della creazione di un modello, la creazione di prototipi nello stesso computer in cui risiede il codice. Per il training nell'ambiente di produzione, vedere come usare lo script di training su risorse di calcolo remote più potenti: