Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A:  SDK Python azure-ai-ml v2 (corrente)
SDK Python azure-ai-ml v2 (corrente)
Informazioni su come uno scienziato dei dati usa Azure Machine Learning per eseguire il training di un modello. In questo esempio si usa un set di dati con carta di credito per comprendere come usare Azure Machine Learning per un problema di classificazione. L'obiettivo è prevedere se un cliente ha una probabilità elevata di insolvenza per un pagamento con carta di credito. Lo script di training gestisce la preparazione dei dati. Lo script esegue quindi il training e registra un modello.
Questa esercitazione illustra i passaggi per inviare un processo di training basato sul cloud (processo di comando).
- Ottenere un handle all'area di lavoro di Azure Machine Learning
- Creare la risorsa di calcolo e l'ambiente del processo
- Creare lo script di training
- Creare ed eseguire il processo di comando per eseguire lo script di training nella risorsa di calcolo
- Visualizzare l'output dello script di training
- Distribuire il modello appena sottoposto a training come endpoint
- Chiamare l'endpoint di Azure Machine Learning per l'inferenza
Per altre informazioni su come caricare i dati in Azure, vedere Esercitazione: Caricare, accedere ed esplorare i dati in Azure Machine Learning.
Questo video illustra come iniziare a usare lo studio di Azure Machine Learning in modo da poter seguire i passaggi dell'esercitazione. Il video mostra come creare un notebook, creare un'istanza di ambiente di calcolo e clonare il notebook. Le sezioni seguenti descrivono anche i passaggi.
Prerequisiti
-
Per usare Azure Machine Learning, è necessaria un'area di lavoro. Se non è disponibile, completare Creare le risorse necessarie per iniziare creare un'area di lavoro e ottenere maggiori informazioni su come usarla.
Importante
Se l'area di lavoro di Azure Machine Learning è configurata con una rete virtuale gestita, potrebbe essere necessario aggiungere regole in uscita per consentire l'accesso ai repository di pacchetti Python pubblici. Per altre informazioni, vedere Scenario: accedere ai pacchetti di apprendimento automatico pubblici.
-
Accedere allo studio e selezionare l'area di lavoro, se non è già aperta.
-
Aprire o creare un notebook nell'area di lavoro:
- Se si vuole copiare e incollare il codice nelle celle, creare un nuovo notebook.
- In alternativa, aprire tutorials/get-started-notebooks/train-model.ipynb dalla sezione Esempi dello studio. Selezionare quindi Clona per aggiungere il notebook in File. Per trovare notebook di esempio, vedere Apprendere dai notebook di esempio.
Impostare il kernel e aprirlo in Visual Studio Code (VS Code)
Nella barra superiore sopra il notebook aperto creare un'istanza di ambiente di calcolo, se non ne è già disponibile una.

Se l'istanza di ambiente di calcolo viene arrestata, selezionare Avviare ambiente di calcolo e attendere fino a quando non è in esecuzione.

Attendere che l'istanza di ambiente di calcolo sia indicata come "In esecuzione". Assicurarsi quindi che il kernel, visualizzato in alto a destra, sia
Python 3.10 - SDK v2. In caso contrario, usare l'elenco a discesa per selezionare questo kernel.
Se il kernel non viene visualizzato, verificare che l'istanza di ambiente di calcolo sia in esecuzione. In caso affermativo, selezionare il pulsante Aggiorna in alto a destra del notebook.
Se viene visualizzato un banner che indica che è necessario eseguire l'autenticazione, selezionare Autenticazione.
È possibile eseguire il notebook qui o aprirlo in VS Code per usare un ambiente di sviluppo integrato (IDE) completo con la potenza delle risorse di Azure Machine Learning. Selezionare Apri in VS Code, quindi selezionare l'opzione Web o desktop. Quando viene avviato in questo modo, VS Code viene collegato all'istanza di ambiente di calcolo, al kernel e al file system dell'area di lavoro.





Importante
La parte rimanente di questa esercitazione contiene le celle del notebook dell'esercitazione. Copiarle e incollarle nel nuovo notebook oppure passare al notebook, se è stato clonato.
Usare un processo di comando per eseguire il training di un modello in Azure Machine Learning
Per eseguire il training di un modello, è necessario inviare un processo. Azure Machine Learning offre diversi tipi di processi per il training dei modelli. È possibile selezionare il metodo di training in base alla complessità del modello, delle dimensioni dei dati e dei requisiti di velocità di training. In questa esercitazione si apprenderà come inviare un processo di comando per eseguire uno script di training.
Un processo di comando è una funzione che consente di inviare uno script di training personalizzato per eseguire il training del modello. È anche possibile definire questo processo come processo di training personalizzato. Un processo di comando in Azure Machine Learning è un tipo di processo che esegue uno script o un comando in un ambiente specificato. È possibile usare i processi di comando per eseguire il training di modelli, elaborare i dati o eseguire qualsiasi altro codice personalizzato da eseguire nel cloud.
In questa esercitazione viene illustrato l'uso di un processo di comando per creare un processo di training personalizzato che viene usato per eseguire il training di un modello. Per qualsiasi processo di training personalizzato sono necessari gli elementi seguenti:
- environment
- data
- processo di comando
- script di training
In questa esercitazione vengono forniti tutti gli elementi per l'esempio: creazione di un classificatore per prevedere i clienti che hanno una probabilità elevata di insolvenza per i pagamenti con carta di credito.
Creare un handle all'area di lavoro
Prima di approfondire il codice, è necessario un modo per fare riferimento all'area di lavoro. Crea ml_client come riferimento per l'area di lavoro. Si userà quindi ml_client per gestire risorse e processi.
Nella cella successiva immettere l'ID sottoscrizione, il nome del gruppo di risorse e il nome dell'area di lavoro. Per trovare questi valori:
- In alto a destra nella barra degli strumenti dello studio di Azure Machine Learning selezionare il nome dell'area di lavoro.
- Copiare i valori per l'area di lavoro, il gruppo di risorse e l'ID sottoscrizione nel codice. È necessario copiare un valore, chiudere l'area e incollarlo, quindi tornare indietro per quello successivo.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Note
La creazione di MLClient non comporta una connessione all'area di lavoro. L'inizializzazione client è differita. Attende la prima volta che deve effettuare una chiamata, che si verifica nella cella di codice successiva.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Creare un ambiente di processo
Per eseguire il processo di Azure Machine Learning nella risorsa di calcolo, è necessario un ambiente. Un ambiente elenca il runtime software e le librerie da installare sull'ambiente di calcolo dove avviene il training. È simile all'ambiente Python nel computer locale. Per altre informazioni, vedere Che cosa sono gli ambienti di Azure Machine Learning?.
Azure Machine Learning fornisce molti ambienti curati o pronti per l'uso, utili per scenari di training e inferenza comuni.
In questo esempio viene creato un ambiente Conda personalizzato per i processi usando un file YAML Conda.
Prima di tutto, creare una directory in cui archiviare il file.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
La cella seguente usa un magic IPython per scrivere il file Conda nella directory creata.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=1.0.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- mlflow==2.8.0
- mlflow-skinny==2.8.0
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- tqdm>=4.59,<4.60
- ipykernel~=6.0
- matplotlib
La specifica contiene alcuni pacchetti consueti, che vengono usati nel processo, ad esempio, numpy e pip.
Fare riferimento a questo file YAML per creare e registrare l'ambiente personalizzato nell'area di lavoro:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
custom_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults job",
tags={"scikit-learn": "1.0.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
custom_job_env = ml_client.environments.create_or_update(custom_job_env)
print(
f"Environment with name {custom_job_env.name} is registered to workspace, the environment version is {custom_job_env.version}"
)
Configurare un processo di training usando la funzione di comando
Si crea un processo di comando di Azure Machine Learning per eseguire il training di un modello per la previsione di insolvenza del credito. Il processo di comando esegue uno script di training in un ambiente specificato in una risorsa di calcolo specificata. L'ambiente e il cluster di elaborazione sono già stati creati. Successivamente, creare uno script di training. In questo caso, si sta eseguendo il training del set di dati per produrre un classificatore usando il modello GradientBoostingClassifier.
Lo script di training gestisce la preparazione dei dati, il training e la registrazione del modello sottoposto a training. Il metodo train_test_split suddivide il set di dati in dati di test e training. In questa esercitazione si crea uno script di training Python.
È possibile eseguire processi di comando dall'interfaccia della riga di comando, da Python SDK o dall'interfaccia di Studio. In questa esercitazione si usa Azure Machine Learning Python SDK v2 per creare ed eseguire il processo di comando.
Creare lo script di training
Iniziare creando lo script di training, ovvero il file python main.py. Creare prima di tutto una cartella di origine per lo script:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Questo script pre-elabora i dati, suddividerli in dati di test ed eseguirne il training. Usa quindi i dati per eseguire il training di un modello basato su albero e restituire il modello di output.
Viene usato MLFlow per registrare i parametri e le metriche durante il processo. Il pacchetto MLFlow consente di tenere traccia delle metriche e dei risultati per ogni modello di cui Azure esegue il training. Usare MLFlow per ottenere il modello migliore per i dati. Visualizzare quindi le metriche del modello nello studio di Azure. Per altre informazioni, vedere MLflow e Azure Machine Learning.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
#Split train and test datasets
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
In questo script, una volta eseguito il training del modello, il file del modello viene salvato e registrato nell'area di lavoro. La registrazione del modello consente di archiviare i modelli e creare le relative versioni nel cloud di Azure, all'interno della propria area di lavoro. Dopo aver registrato un modello, è possibile trovare tutti gli altri modelli registrati in un'unica posizione nello studio di Azure denominata registro modelli. Il registro modelli consente di organizzare i modelli sottoposti a training e tenerne traccia.
Configurare il comando
Ora che è disponibile uno script in grado di eseguire l'attività di classificazione, usare il comando per utilizzo generico che può eseguire le azioni della riga di comando. Questa azione della riga di comando può chiamare direttamente comandi di sistema o eseguire uno script.
Creare le variabili di input per specificare i dati di input, il rapporto di suddivisione, la velocità di apprendimento e il nome del modello registrato. Lo script del comando:
- Usa l'ambiente creato in precedenza. Usare la notazione
@latestper indicare la versione più recente dell'ambiente quando viene eseguito il comando. - Configurare l'azione della riga di comando stessa, in questo caso
python main.py. È possibile accedere agli input e agli output nel comando tramite la notazione${{ ... }}. - Poiché non è stata specificata una risorsa di calcolo, lo script viene eseguito in un cluster di elaborazione serverless creato automaticamente.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="aml-scikit-learn@latest",
display_name="credit_default_prediction",
)
Inviare il processo
Inviare il processo per l'esecuzione nello studio di Azure Machine Learning. Questa volta, usare create_or_update in ml_client.
ml_client è una classe client che consente di connettersi alla sottoscrizione di Azure usando Python e interagire con i servizi di Azure Machine Learning.
ml_client consente di inviare i processi usando Python.
ml_client.create_or_update(job)
Visualizzare l'output del processo e attendere il completamento del processo
Per visualizzare il processo nello studio di Azure Machine Learning selezionare il collegamento nell'output della cella precedente. L'output di questo processo sarà simile al seguente in Azure Machine Learning Studio. Esplorare le schede per vari dettagli, ad esempio metriche, output e altro ancora. Al termine del processo, registra un modello nell'area di lavoro come risultato del training.
Importante
Attendere fino a quando lo stato del processo non risulta completato prima di tornare al notebook per continuare. L'esecuzione del processo richiede da 2 a 3 minuti. Potrebbero essere necessari più tempo, fino a 10 minuti, se il cluster di calcolo si riduce a zero nodi e l'ambiente personalizzato è ancora in fase di compilazione.
Quando si esegue la cella, l'output del notebook mostra un collegamento alla pagina dei dettagli del processo nello studio di Machine Learning. In alternativa, puoi anche selezionare Lavori nel riquadro sinistro.
Un processo è un raggruppamento di più esecuzioni da uno script o da un frammento di codice specificato. L'esecuzione archivia le informazioni nel processo. La pagina dei dettagli offre una panoramica del processo, il tempo impiegato per l'esecuzione, quando è stato creato e altre informazioni. La pagina include anche schede per altre informazioni sull'attività, ad esempio metriche, output e log e codice. Qui sono elencate le schede disponibili nella pagina dei dettagli del processo:
- Panoramica: informazioni di base sul processo, inclusi lo stato, l'ora di inizio e di fine e il tipo di processo eseguito
- Input: dati e codice usati come input per il processo. Questa sezione può includere set di dati, script, configurazioni dell'ambiente e altre risorse usate durante il training.
- Output e log: log generati durante l'esecuzione del processo. Questa scheda aiuta a risolvere i problemi in caso di errori con lo script di training o la creazione del modello.
- Metriche: metriche delle prestazioni chiave del modello, ad esempio punteggio di training, punteggio f1 e punteggio di precisione.
Pulire le risorse
Se si prevede di continuare con altre esercitazioni, passare a Contenuto correlato.
Arrestare l'istanza di ambiente di calcolo
Se non si intende usare l'istanza di calcolo, arrestarla:
- Nel riquadro sinistro dello studio selezionare Calcolo.
- Nelle schede in alto selezionare Istanze di ambiente di calcolo.
- Selezionare l'istanza di ambiente di calcolo nell'elenco.
- Sulla barra degli strumenti in alto selezionare Arresta.
Eliminare tutte le risorse
Importante
Le risorse create possono essere usate come prerequisiti per altre esercitazioni e articoli esplicativi per Azure Machine Learning.
Se non si prevede di usare le risorse create, eliminarle per evitare addebiti:
Nella casella di ricerca del portale di Azure, immettere Gruppi di risorse e selezionarlo nei risultati.
Dell'elenco, selezionare il gruppo di risorse creato.
Nella pagina Panoramica, selezionare Elimina gruppo di risorse.
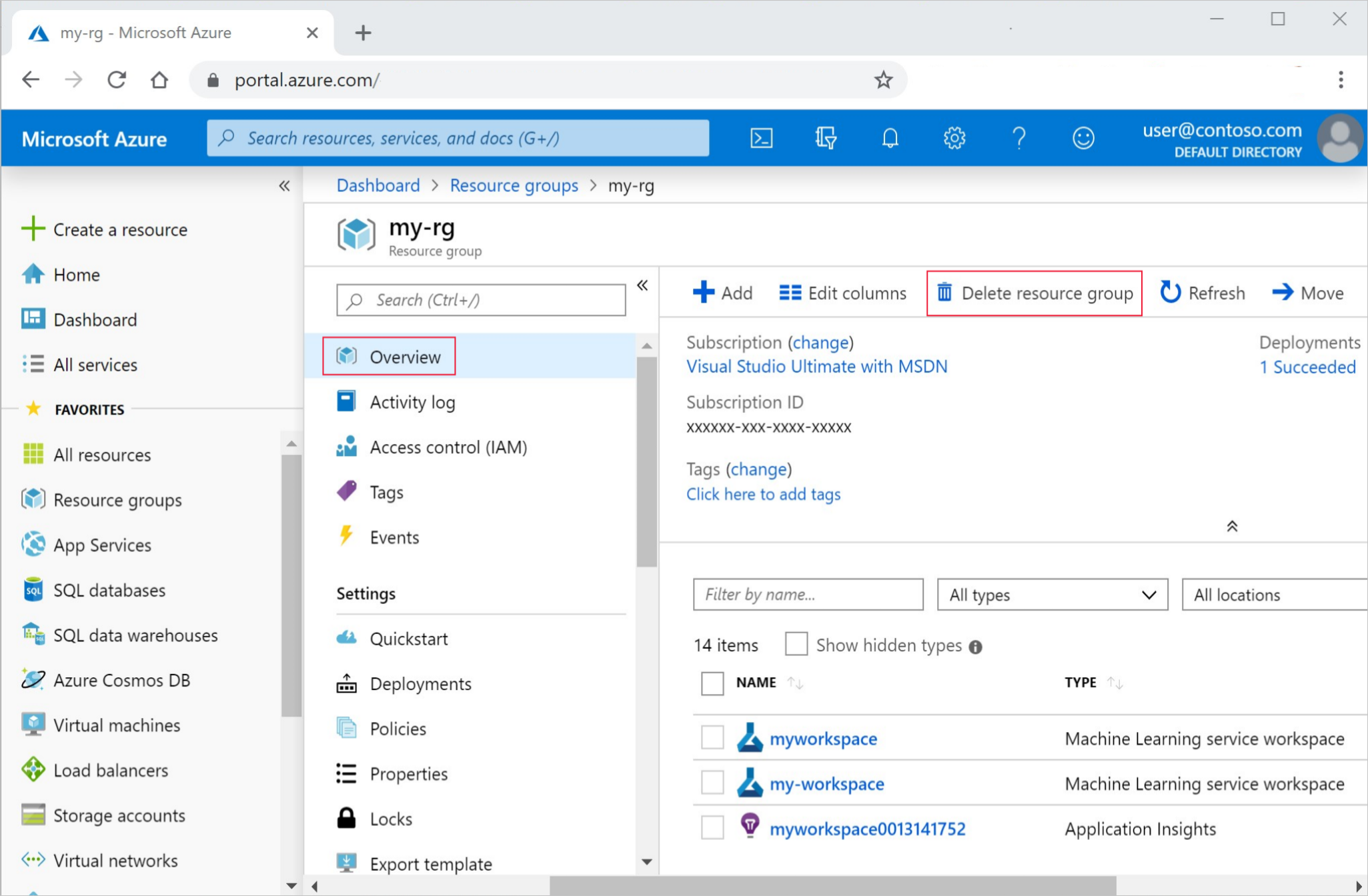
Immettere il nome del gruppo di risorse. Selezionare Elimina.
Contenuti correlati
Informazioni sulla distribuzione di un modello:
Questa esercitazione usa un file di dati online. Per altre informazioni su altri modi per accedere ai dati, vedere Esercitazione: Caricare i dati, accedervi ed esplorarli in Azure Machine Learning.
Machine Learning automatizzato è uno strumento supplementare che riduce la quantità di tempo che un data scientist dedica a trovare un modello che funziona meglio con i propri dati. Per altre informazioni, vedere Che cos'è Machine Learning automatizzato?.
Per altri esempi simili a questa esercitazione, vedere Learn from sample notebooks (Apprendere da notebook di esempio). Questi esempi sono disponibili nella pagina degli esempi di GitHub. Gli esempi includono notebook Python completi da usare per eseguire il codice e imparare a eseguire il training di un modello. È possibile modificare ed eseguire gli script esistenti dagli esempi, che contengono vari scenari, tra cui classificazione, elaborazione del linguaggio naturale e rilevamento anomalie.