Visualizzare il codice di training per un modello di Machine Learning automatizzato
In questo articolo viene illustrato come visualizzare il codice di training generato da qualsiasi modello sottoposto a training automatico.
La generazione di codice per i modelli con training automatico di ML consente di visualizzare i dettagli seguenti usati da ML automatizzati per eseguire il training e compilare il modello per un'esecuzione specifica.
- Pre-elaborazione dei dati
- Selezione dell'algoritmo
- Sviluppo di funzionalità
- Iperparametri
È possibile selezionare qualsiasi modello di machine learning automatizzato, eseguito consigliato o figlio e visualizzare il codice di training Python generato che ha creato tale modello specifico.
Con il codice di training del modello generato, è possibile,
- Informazioni sul processo di funzionalità e sugli iperparametri usati dall'algoritmo del modello.
- Tenere traccia/versione/controllo dei modelli sottoposti a training. Archiviare il codice con versione per tenere traccia del codice di training specifico usato con il modello da distribuire nell'ambiente di produzione.
- Personalizzare il codice di training modificando gli iperparametri o applicando le competenze/esperienza di machine learning e algoritmi e ripetere il training di un nuovo modello con il codice personalizzato.
Il diagramma seguente illustra che è possibile generare il codice per esperimenti di Machine Learning automatizzati con tutti i tipi di attività. Selezionare prima di tutto un modello. Il modello selezionato verrà evidenziato, quindi Azure Machine Learning copia i file di codice usati per creare il modello e li visualizza nella cartella condivisa dei notebook. Da qui è possibile visualizzare e personalizzare il codice in base alle esigenze.
Prerequisiti
Un'area di lavoro di Azure Machine Learning. Per creare l'area di lavoro, vedere Creare risorse dell'area di lavoro.
Questo articolo presuppone una certa familiarità con la configurazione di un esperimento di Machine Learning automatizzato. Seguire l'esercitazione o la procedura per visualizzare i principali modelli di progettazione dell'esperimento di Machine Learning automatizzati.
La generazione automatica del codice ml è disponibile solo per gli esperimenti eseguiti nelle destinazioni di calcolo di Azure Machine Learning remote. La generazione di codice non è supportata per le esecuzioni locali.
Tutte le esecuzioni automatizzate di ML attivate tramite Azure Machine Learning Studio, SDKv2 o CLIv2 avranno la generazione di codice abilitata.
Ottenere codice e artefatti del modello generati
Per impostazione predefinita, ogni modello sottoposto a training automatico genera il codice di training dopo il completamento del training. Machine Learning automatizzato salva questo codice nel modello specifico dell'esperimento outputs/generated_code . È possibile visualizzarli nell'interfaccia utente studio di Azure Machine Learning nella scheda Output e log del modello selezionato.
script.py Si tratta del codice di training del modello che probabilmente si vuole analizzare con i passaggi di funzionalità, gli algoritmi specifici usati e gli iperparametri.
script_run_notebook.ipynb Notebook con codice della piastra caldaia per eseguire il codice di training del modello (script.py) nel calcolo di Azure Machine Learning tramite Azure Machine Learning SDKv2.
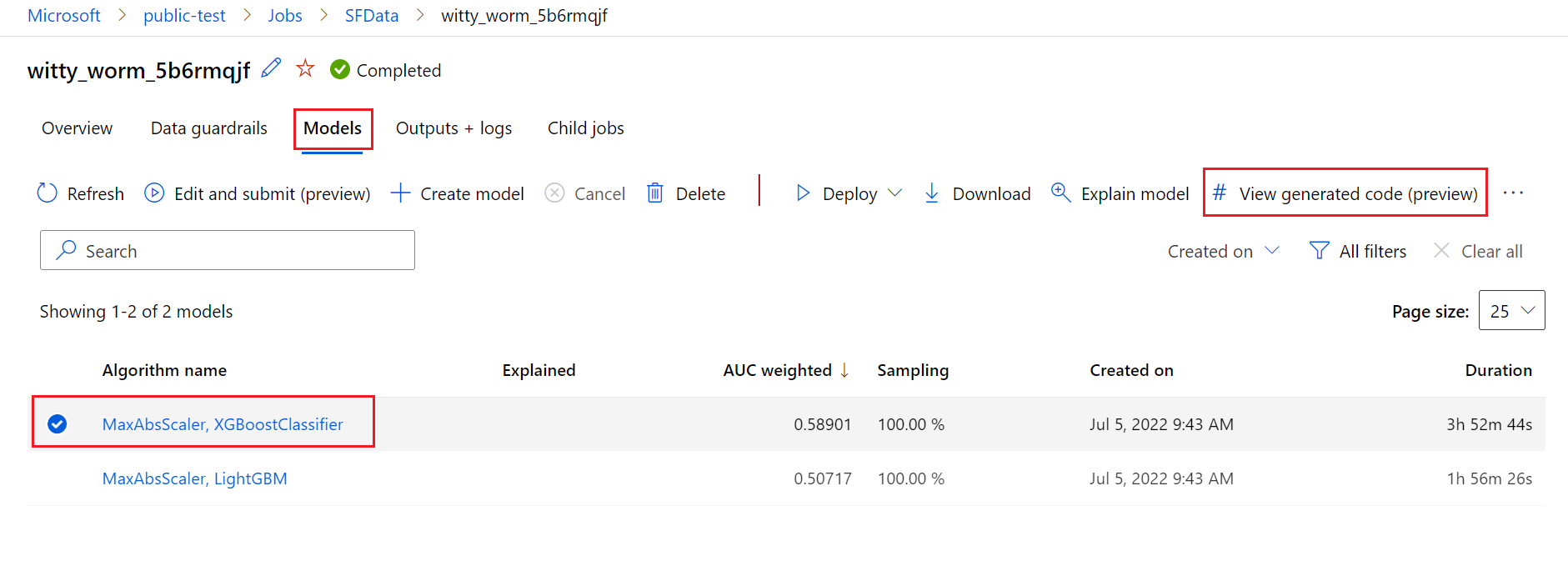
Al termine dell'esecuzione automatica del training ml, è possibile accedere ai script.py file e script_run_notebook.ipynb tramite l'interfaccia utente studio di Azure Machine Learning.
A tale scopo, passare alla scheda Modelli della pagina di esecuzione padre dell'esperimento ml automatizzato. Dopo aver selezionato uno dei modelli sottoposti a training, è possibile selezionare il pulsante Visualizza codice generato . Questo pulsante reindirizza all'estensione del portale Notebooks , in cui è possibile visualizzare, modificare ed eseguire il codice generato per quel particolare modello selezionato.
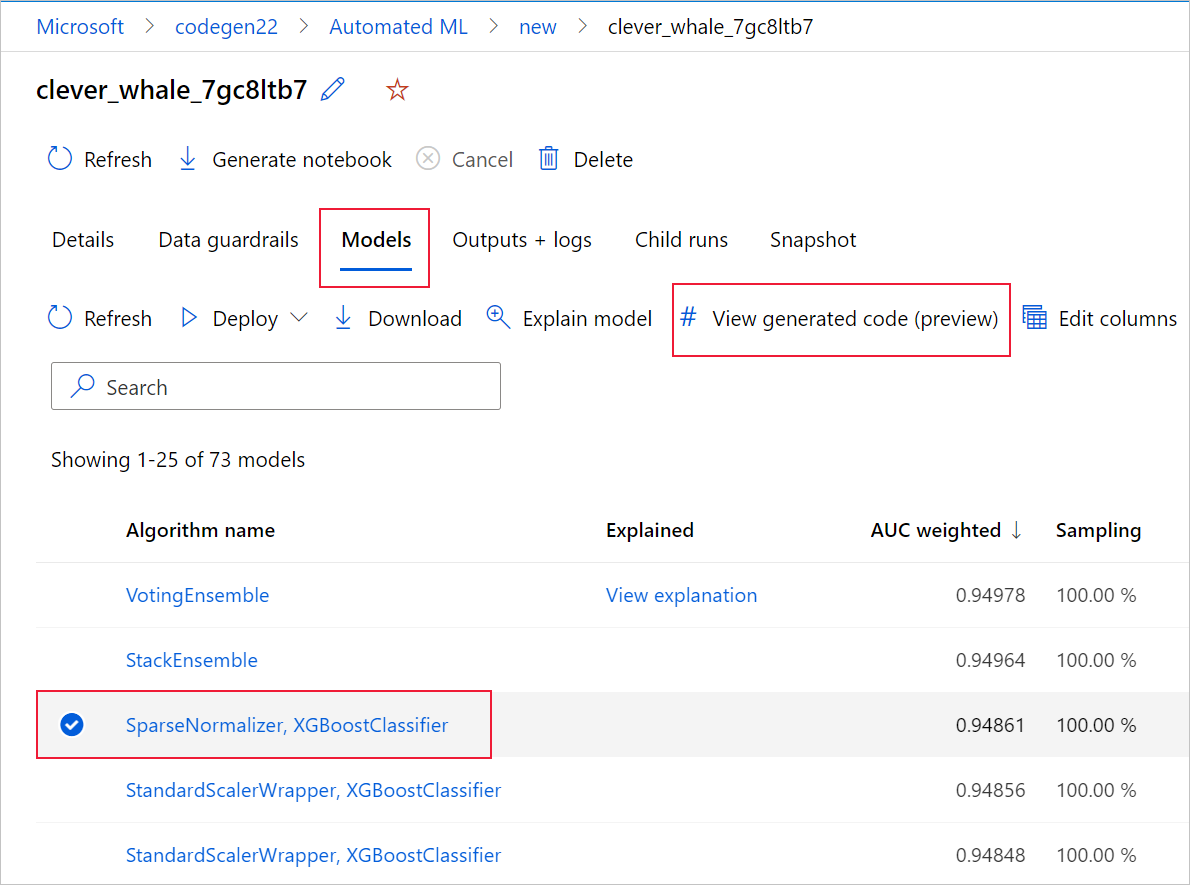
È anche possibile accedere al codice generato dal modello dalla parte superiore della pagina dell'esecuzione figlio dopo aver eseguito tale pagina nella pagina dell'esecuzione figlio di un determinato modello.
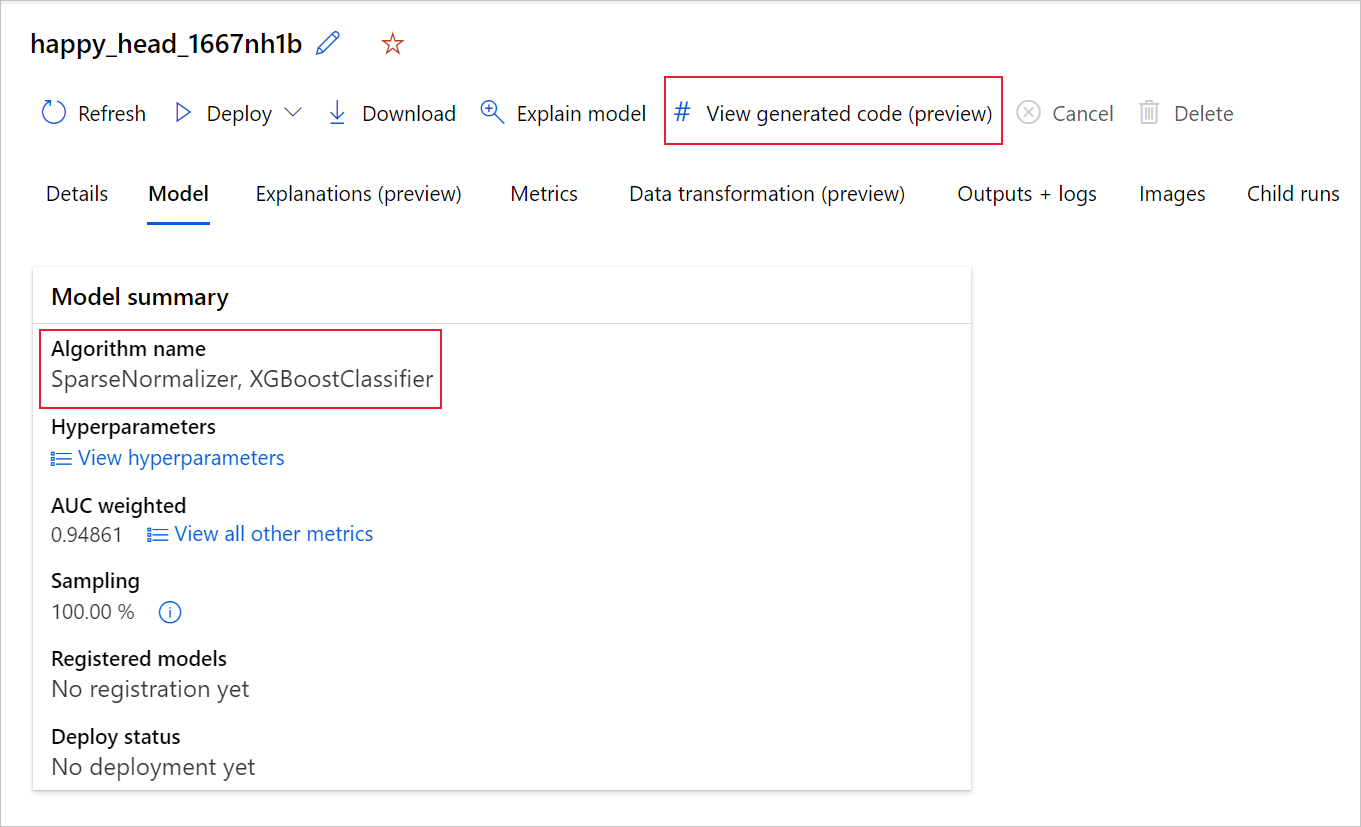
Se si usa Python SDKv2, è anche possibile scaricare "script.py" e "script_run_notebook.ipynb" recuperando l'esecuzione migliore tramite MLFlow & scaricando gli artefatti risultanti.
script.py
Il script.py file contiene la logica di base necessaria per eseguire il training di un modello con gli iperparametri usati in precedenza. Durante l'esecuzione di uno script di Azure Machine Learning, con alcune modifiche, il codice di training del modello può essere eseguito anche autonomo nell'ambiente locale.
Lo script può essere suddiviso approssimativamente in diverse parti seguenti: caricamento dei dati, preparazione dei dati, caratteristiche dei dati, specifica del preprocessore/algoritmo e training.
Caricamento dei dati
La funzione get_training_dataset() carica il set di dati usato in precedenza. Si presuppone che lo script venga eseguito in uno script di Azure Machine Learning eseguito nella stessa area di lavoro dell'esperimento originale.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
Quando viene eseguito come parte di un'esecuzione di script, Run.get_context().experiment.workspace recupera l'area di lavoro corretta. Tuttavia, se questo script viene eseguito all'interno di un'area di lavoro diversa o eseguita in locale, è necessario modificare lo script in modo esplicito per specificare in modo esplicito l'area di lavoro appropriata.
Dopo aver recuperato l'area di lavoro, il set di dati originale viene recuperato dall'ID. Un altro set di dati con esattamente la stessa struttura può essere specificato rispettivamente dall'ID o dal nome con o get_by_id()get_by_name(). È possibile trovare l'ID più avanti nello script, in una sezione simile come il codice seguente.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
È anche possibile scegliere di sostituire questa intera funzione con il proprio meccanismo di caricamento dei dati; gli unici vincoli sono che il valore restituito deve essere un dataframe Pandas e che i dati devono avere la stessa forma dell'esperimento originale.
Codice di preparazione dei dati
La funzione prepare_data() pulisce i dati, suddivide la funzionalità e le colonne di peso di esempio e prepara i dati da usare nel training.
Questa funzione può variare a seconda del tipo di set di dati e del tipo di attività dell'esperimento: classificazione, regressione, previsione delle serie temporali, immagini o attività NLP.
Nell'esempio seguente viene illustrato che in generale, il dataframe dal passaggio di caricamento dei dati viene passato. La colonna etichetta e i pesi di esempio, se originariamente specificati, vengono estratti e le righe contenenti NaN vengono eliminate dai dati di input.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Per eseguire ulteriori operazioni di preparazione dei dati, è possibile farlo in questo passaggio aggiungendo il codice di preparazione dei dati personalizzato.
Codice di funzionalità dei dati
La funzione generate_data_transformation_config() specifica il passaggio di funzionalità nella pipeline scikit-learn finale. I featurizer dell'esperimento originale vengono riprodotti qui, insieme ai relativi parametri.
Ad esempio, la possibile trasformazione dei dati che può verificarsi in questa funzione può essere basata su imputer come e , o trasformatori StringCastTransformer() come e LabelEncoderTransformer()CatImputer(). SimpleImputer()
Di seguito è riportato un trasformatore di tipo StringCastTransformer() che può essere usato per trasformare un set di colonne. In questo caso, il set indicato da column_names.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Tenere presente che se sono presenti molte colonne che devono avere la stessa funzionalità/trasformazione applicata (ad esempio, 50 colonne in diversi gruppi di colonne), queste colonne vengono gestite raggruppando in base al tipo.
Nell'esempio seguente si noti che ogni gruppo ha un mapper univoco applicato. Questo mapper viene quindi applicato a ognuna delle colonne del gruppo.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Questo approccio consente di avere un codice più semplificato, non avendo un blocco di codice di un trasformatore per ogni colonna, che può essere particolarmente complesso anche quando si hanno decine o centinaia di colonne nel set di dati.
Con le attività di classificazione e regressione, [FeatureUnion] viene usata per i featurizer.
Per i modelli di previsione delle serie temporali, vengono raccolti in una pipeline scikit-learn più tipi di funzionalità con riconoscimento della serie temporale, quindi racchiuse nell'oggetto TimeSeriesTransformer.
Qualsiasi utente ha fornito funzionalità per i modelli di previsione delle serie temporali prima che quelli forniti da ML automatizzato.
Codice di specifica del preprocessore
La funzione generate_preprocessor_config(), se presente, specifica un passaggio di pre-elaborazione da eseguire dopo la funzionalità nella pipeline scikit-learn finale.
In genere, questo passaggio di pre-elaborazione è costituito solo dalla standardizzazione/normalizzazione dei dati eseguita con sklearn.preprocessing.
Machine Learning automatizzato specifica solo un passaggio di pre-elaborazione per i modelli di classificazione e regressione non completi.
Ecco un esempio di codice preprocessore generato:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Codice di specifica dell'algoritmo e degli iperparametri
Il codice di specifica dell'algoritmo e degli iperparametri è probabilmente quello che molti professionisti di ML sono più interessati.
La generate_algorithm_config() funzione specifica l'algoritmo effettivo e gli iperparametri per il training del modello come ultima fase della pipeline scikit-learn finale.
Nell'esempio seguente viene usato un algoritmo XGBoostClassifier con iperparametri specifici.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
Il codice generato nella maggior parte dei casi usa pacchetti e classi software (OSS) open source. Esistono istanze in cui vengono usate classi wrapper intermedie per semplificare il codice più complesso. Ad esempio, il classificatore XGBoost e altre librerie comunemente usate come LightGBM o algoritmi di Scikit-Learn possono essere applicati.
Come ML Professional, è possibile personalizzare il codice di configurazione dell'algoritmo modificando i relativi iperparametri in base alle esigenze in base alle competenze e all'esperienza per tale algoritmo e al problema di ML specifico.
Per i modelli di ensemble, generate_preprocessor_config_N() (se necessario) e generate_algorithm_config_N() sono definiti per ogni learner nel modello di ensemble, dove N rappresenta il posizionamento di ogni learner nell'elenco dei modelli di ensemble. Per i modelli di insieme di stack, il meta learner generate_algorithm_config_meta() è definito.
Codice di training end-to-end
La build_model_pipeline() generazione del codice genera e train_model() consente di definire rispettivamente la pipeline scikit-learn e di chiamarla fit() .
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
La pipeline scikit-learn include il passaggio di funzionalità, un preprocessore (se usato) e l'algoritmo o il modello.
Per i modelli di previsione delle serie temporali, la pipeline scikit-learn viene sottoposta a wrapping in un ForecastingPipelineWrapperoggetto , che dispone di una logica aggiuntiva necessaria per gestire correttamente i dati delle serie temporali a seconda dell'algoritmo applicato.
Per tutti i tipi di attività viene usato PipelineWithYTransformer nei casi in cui la colonna etichetta deve essere codificata.
Dopo aver creato la pipeline scikit-Learn, tutto ciò che viene lasciato per chiamare è il metodo per eseguire il fit() training del modello:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
Il valore restituito da train_model() è il modello installato/sottoposto a training sui dati di input.
Il codice principale che esegue tutte le funzioni precedenti è il seguente:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
Dopo aver eseguito il training del modello, è possibile usarlo per effettuare stime con il metodo predict(). Se l'esperimento è per un modello di serie temporali, usare il metodo forecast() per le stime.
y_pred = model.predict(X)
Infine, il modello viene serializzato e salvato come .pkl file denominato "model.pkl":
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
Il script_run_notebook.ipynb notebook funge da modo semplice per l'esecuzione script.py in un ambiente di calcolo di Azure Machine Learning.
Questo notebook è simile ai notebook di esempio di Machine Learning automatizzati esistenti, tuttavia, esistono alcune differenze principali, come illustrato nelle sezioni seguenti.
Ambiente
In genere, l'ambiente di training per un'esecuzione automatica di Machine Learning viene impostato automaticamente dall'SDK. Tuttavia, quando si esegue uno script personalizzato come il codice generato, Machine Learning automatizzato non guida più il processo, quindi l'ambiente deve essere specificato affinché il processo di comando abbia esito positivo.
La generazione di codice riutilizza l'ambiente usato nell'esperimento di Machine Learning automatizzato originale, se possibile. In questo modo si garantisce che l'esecuzione dello script di training non abbia esito negativo a causa di dipendenze mancanti e che non sia necessaria una ricompilazione dell'immagine Docker, che consente di risparmiare tempo e risorse di calcolo.
Se si apportano modifiche a script.py che richiedono dipendenze aggiuntive o si vuole usare il proprio ambiente, è necessario aggiornare l'ambiente script_run_notebook.ipynb di conseguenza.
Inviare l'esperimento
Poiché il codice generato non è più basato su Machine Learning automatizzato, anziché creare e inviare un processo AutoML, è necessario creare e Command Job fornire il codice generato (script.py) al codice generato.
L'esempio seguente contiene i parametri e le dipendenze regolari necessarie per eseguire un processo di comando, ad esempio calcolo, ambiente e così via.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning Studio
Passaggi successivi
- Altre informazioni su come e dove distribuire un modello.
- Vedere come abilitare le funzionalità di interpretabilità in modo specifico negli esperimenti automatizzati di Machine Learning.