Esercitazione: Eseguire il training e distribuire un modello di classificazione delle immagini con un esempio Jupyter Notebook
SI APPLICA A: Python SDK azureml v1
Python SDK azureml v1
In questa esercitazione si eseguirà il training di un modello di Machine Learning su risorse di calcolo remote. Si userà il flusso di lavoro per il training e la distribuzione di Azure Machine Learning in un notebook di Jupyter per Python. È quindi possibile usare il notebook come modello per eseguire il training di un modello di Machine Learning con i propri dati di training.
Questa esercitazione esegue il training di una semplice regressione logistica usando il set di dati MNIST e scikit-learn con Azure Machine Learning. MNIST è un set di dati noto costituito da 70.000 immagini in scala di grigi. Ogni immagine è una cifra in stile scrittura a mano di 28x28 pixel, che rappresenta un numero compreso tra zero e nove. L'obiettivo è creare un classificatore multiclasse per identificare la cifra rappresentata da una determinata immagine.
Si apprenderà a eseguire le operazioni seguenti:
- Scaricare un set di dati ed esaminare i dati.
- Eseguire il training di un modello di classificazione delle immagini e registrare le metriche usando MLflow.
- Distribuire il modello per eseguire l'inferenza in tempo reale.
Prerequisiti
- Completare la guida introduttiva: Introduzione ad Azure Machine Learning per:
- Creare un'area di lavoro.
- Creare un'istanza di calcolo basata sul cloud da usare per l'ambiente di sviluppo.
Eseguire un notebook dall'area di lavoro
Azure Machine Learning include un server notebook cloud nell'area di lavoro per un'esperienza preconfigurata senza installazioni. Se si preferisce avere il controllo sull'ambiente, sui pacchetti e sulle dipendenze, usare il proprio ambiente.
Clonare una cartella del notebook
Completare la configurazione dell'esperimento seguente ed eseguire i passaggi in Azure Machine Learning Studio. Questa interfaccia consolidata include gli strumenti di Machine Learning per eseguire scenari di data science per professionisti con tutti i livelli di competenze.
Accedere ad Azure Machine Learning Studio.
Selezionare la sottoscrizione e l'area di lavoro create.
Selezionare Notebook a sinistra.
Selezionare la scheda Esempi in alto.
Aprire la cartella SDK v1 .
Selezionare il pulsante ... a destra della cartella tutorials e quindi scegliere Clone (Clona).
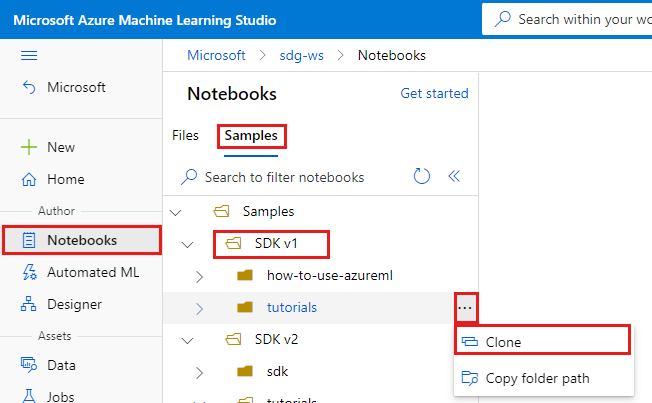
Viene visualizzato un elenco di cartelle che mostra ogni utente che accede all'area di lavoro. Selezionare la cartella in cui clonare la cartella tutorials .
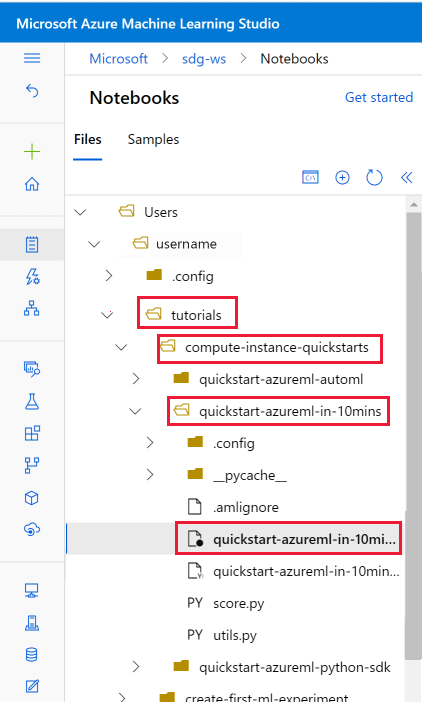
Aprire il notebook clonato
Aprire la cartella tutorials clonata nella sezione File utente .
Selezionare il file quickstart-azureml-in-10mins.ipynb dalla cartella tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins .
Installare i pacchetti
Quando l'istanza di calcolo è in esecuzione e viene visualizzato il kernel, aggiungere una nuova cella di codice per installare i pacchetti necessari per questa esercitazione.
Nella parte superiore del notebook aggiungere una cella di codice.
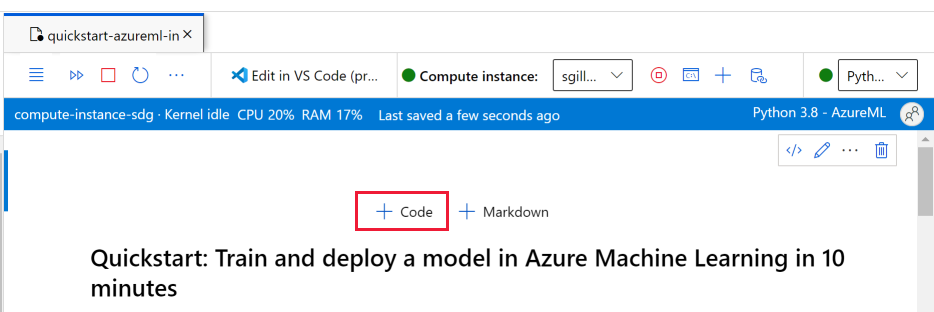
Aggiungere il codice seguente nella cella e quindi eseguire la cella usando lo strumento Esegui o premendo MAIUSC+INVIO.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
Potrebbero essere visualizzati alcuni avvisi di installazione. Tali errori possono essere ignorati.
Eseguire il notebook
Questa esercitazione e il file di utils.py associati sono disponibili anche in GitHub se si vuole usarlo nel proprio ambiente locale. Se non si usa l'istanza di calcolo, aggiungere %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib all'installazione precedente.
Importante
Il resto di questo articolo contiene lo stesso contenuto visualizzato nel notebook.
Passare al Jupyter Notebook ora se si vuole eseguire il codice durante la lettura. Per eseguire una singola cella di codice in un notebook, fare clic sulla cella di codice e premere MAIUSC + INVIO. In alternativa, eseguire l'intero notebook scegliendo Esegui tutto dalla barra degli strumenti superiore.
Importa dati
Prima di eseguire il training di un modello, è necessario comprendere i dati usati per eseguirne il training. In questa sezione viene illustrato come:
- Scaricare il set di dati MNIST
- Visualizzare alcune immagini di esempio
Si useranno i set di dati aperti di Azure per ottenere i file di dati MNIST non elaborati. I set di dati aperti di Azure sono set di dati pubblici curati che è possibile usare per aggiungere funzionalità specifiche dello scenario alle soluzioni di Machine Learning per modelli migliori. Per ogni set di dati è disponibile una classe corrispondente, in questo caso MNIST, per recuperare i dati in modi diversi.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
Esaminare i dati
Caricare i file compressi in matrici numpy. Usare quindi matplotlib per tracciare 30 immagini casuali dal set di dati con le etichette al di sopra.
Per questo passaggio è necessaria una funzione load_data inclusa in un file utils.py. Questo file viene inserito nella stessa cartella del notebook. La funzione load_data si limita ad analizzare i file compressi in matrici numpy.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
Il codice precedente visualizza un set casuale di immagini con le relative etichette, simile al seguente:

Eseguire il training di metriche del modello e del log con MLflow
Si eseguirà il training del modello usando il codice seguente. Si noti che si usa l'assegnazione automatica di MLflow per tenere traccia delle metriche e degli artefatti del modello di log.
Si userà il classificatore LogisticRegression del framework SciKit Learn per classificare i dati.
Nota
Il completamento del training del modello richiede circa 2 minuti.**
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
Visualizzare l'esperimento
Nel menu a sinistra in studio di Azure Machine Learning selezionare Processi e quindi selezionare il processo (azure-ml-in10-mins-tutorial). Un processo è un raggruppamento di molte esecuzioni da uno script o da una parte di codice specificata. È possibile raggruppare più processi come esperimento.
Le informazioni per l'esecuzione vengono archiviate nel processo. Se il nome non esiste quando si invia un processo, se si seleziona l'esecuzione verranno visualizzate varie schede contenenti metriche, log, spiegazioni e così via.
Controllo della versione dei modelli con il registro dei modelli
È possibile usare la registrazione del modello per archiviare e versione i modelli nell'area di lavoro. I modelli registrati sono identificati dal nome e dalla versione. Ogni volta che si registra un modello con lo stesso nome di uno esistente, il registro incrementa la versione. Il codice seguente registra e versioni il modello di cui è stato eseguito il training precedente. Dopo aver eseguito la cella di codice seguente, sarà possibile visualizzare il modello nel Registro di sistema selezionando Modelli nel menu a sinistra in studio di Azure Machine Learning.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
Distribuire il modello per l'inferenza in tempo reale
In questa sezione viene illustrato come distribuire un modello in modo che un'applicazione possa usare (inferenza) il modello tramite REST.
Creare la configurazione della distribuzione
La cella di codice ottiene un ambiente curato, che specifica tutte le dipendenze necessarie per ospitare il modello , ad esempio i pacchetti come scikit-learn. Viene anche creata una configurazione di distribuzione che specifica la quantità di calcolo necessaria per ospitare il modello. In questo caso, il calcolo avrà 1CPU e 1 GB di memoria.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-0.24.1-ubuntu18.04-py37-cpu-inference",
version=1
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
Distribuire il modello
Questa cella di codice successiva distribuisce il modello nell'istanza di Azure Container.
Nota
Il completamento della distribuzione richiede circa 3 minuti.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
Il file di script di assegnazione dei punteggi a cui si fa riferimento nel codice precedente si trova nella stessa cartella del notebook e ha due funzioni:
- Funzione
initche viene eseguita una sola volta all'avvio del servizio. In questa funzione si ottiene normalmente il modello dal Registro di sistema e si impostano le variabili globali - Funzione
run(data)che viene eseguita ogni volta che viene effettuata una chiamata al servizio. In questa funzione in genere si formattano i dati di input, si esegue una stima e si restituisce il risultato previsto.
Visualizzare l'endpoint
Dopo aver distribuito correttamente il modello, è possibile visualizzare l'endpoint passando a Endpoint nel menu a sinistra in studio di Azure Machine Learning. Sarà possibile visualizzare lo stato dell'endpoint (integro/non integro), i log e l'utilizzo (come le applicazioni possono usare il modello).
Testare il servizio modello
È possibile testare il modello inviando una richiesta HTTP non elaborata per testare il servizio Web.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
Pulire le risorse
Se non si continuerà a usare questo modello, eliminare il servizio Modello usando:
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
Se si desidera controllare ulteriormente i costi, arrestare l'istanza di calcolo selezionando il pulsante "Arresta calcolo" accanto all'elenco a discesa Calcolo . Avviare quindi di nuovo l'istanza di calcolo alla successiva necessità.
Eliminare tutto
Usare questa procedura per eliminare l'area di lavoro di Azure Machine Learning e tutte le risorse di calcolo.
Importante
Le risorse create possono essere usate come prerequisiti per altre esercitazioni e procedure dettagliate per Azure Machine Learning.
Se non si prevede di usare alcuna delle risorse create, eliminarle in modo da non comportare addebiti:
Nel portale di Azure fare clic su Gruppi di risorse all'estrema sinistra.
Nell'elenco selezionare il gruppo di risorse creato.
Selezionare Elimina gruppo di risorse.
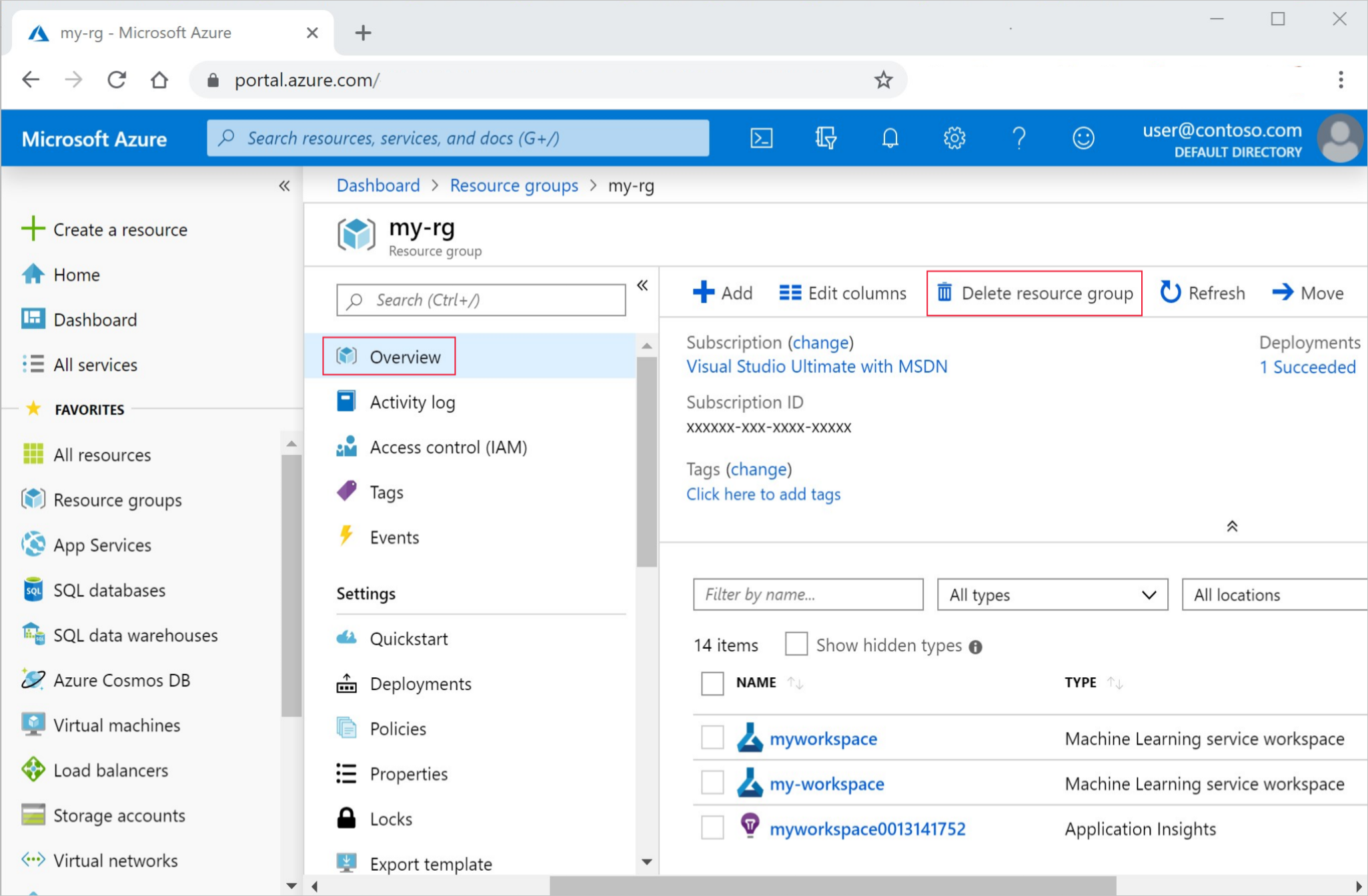
Immettere il nome del gruppo di risorse. Selezionare Elimina.
Passaggi successivi
- Informazioni su tutte le opzioni di distribuzione di Azure Machine Learning.
- Informazioni su come eseguire l'autenticazione al modello distribuito.
- Eseguire stime su grandi quantità di dati in modo asincrono.
- Monitorare i modelli di Azure Machine Learning con Application Insights.