Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il servizio Istanza gestita di Azure per Apache Cassandra consente operazioni di distribuzione e ridimensionamento automatizzate per i data center Apache Cassandra open source gestiti. Questa funzionalità accelera gli scenari ibridi e consente di ridurre la manutenzione in corso.
Questa guida introduttiva illustra come usare il portale di Azure per creare un cluster Apache Spark completamente gestito all'interno della rete virtuale di Azure del cluster Istanza gestita di Azure per Apache Cassandra. Il cluster Spark viene creato in Azure Databricks. Successivamente, è possibile creare o collegare notebook al cluster, leggere i dati da origini dati diverse e analizzare le informazioni dettagliate.
Per altre informazioni, vedere Distribuire Azure Databricks nella rete virtuale di Azure (inserimento della rete virtuale).
Prerequisiti
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Creare un cluster di Azure Databricks
Seguire questa procedura per creare un cluster Azure Databricks in una rete virtuale con Istanza gestita di Azure per Apache Cassandra:
Accedere al portale di Azure.
Nel riquadro sinistro individuare Gruppi di risorse. Passare al gruppo di risorse che contiene la rete virtuale in cui è distribuita l'istanza gestita.
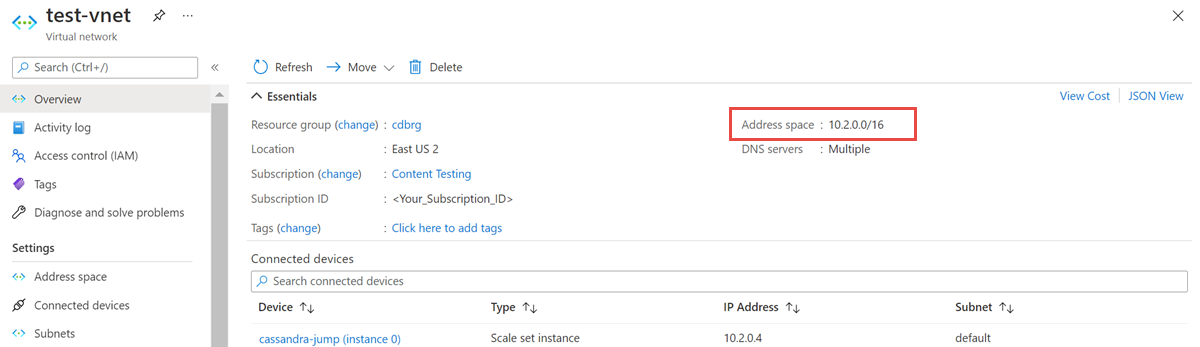
Aprire la risorsa rete virtuale e prendere nota dello spazio indirizzi.
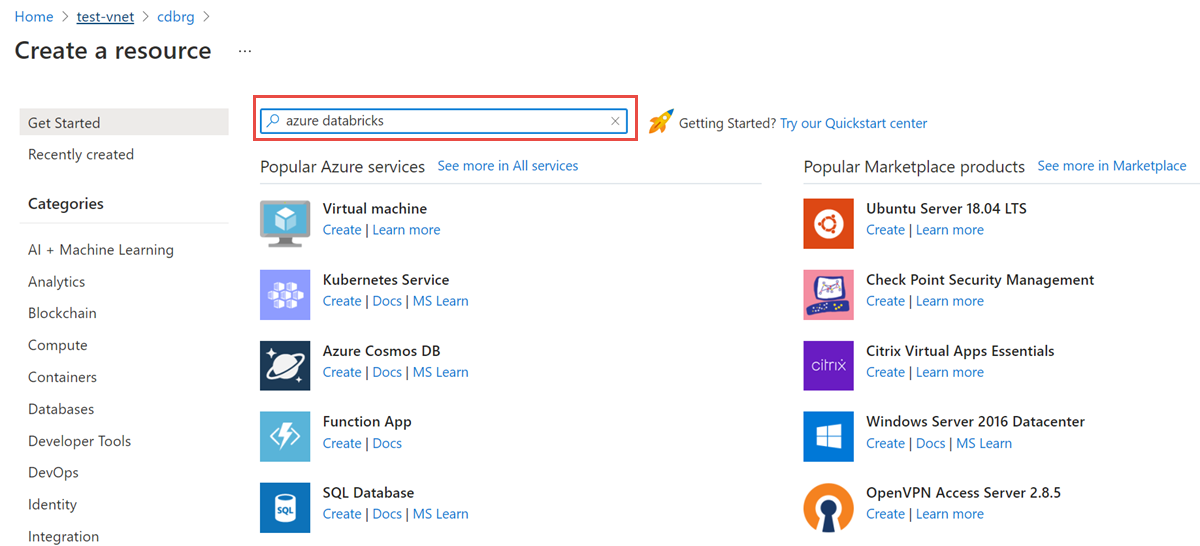
Nel gruppo di risorse selezionare Aggiungi e cercare Azure Databricks nel campo di ricerca.
Selezionare Crea per creare un account Azure Databricks.
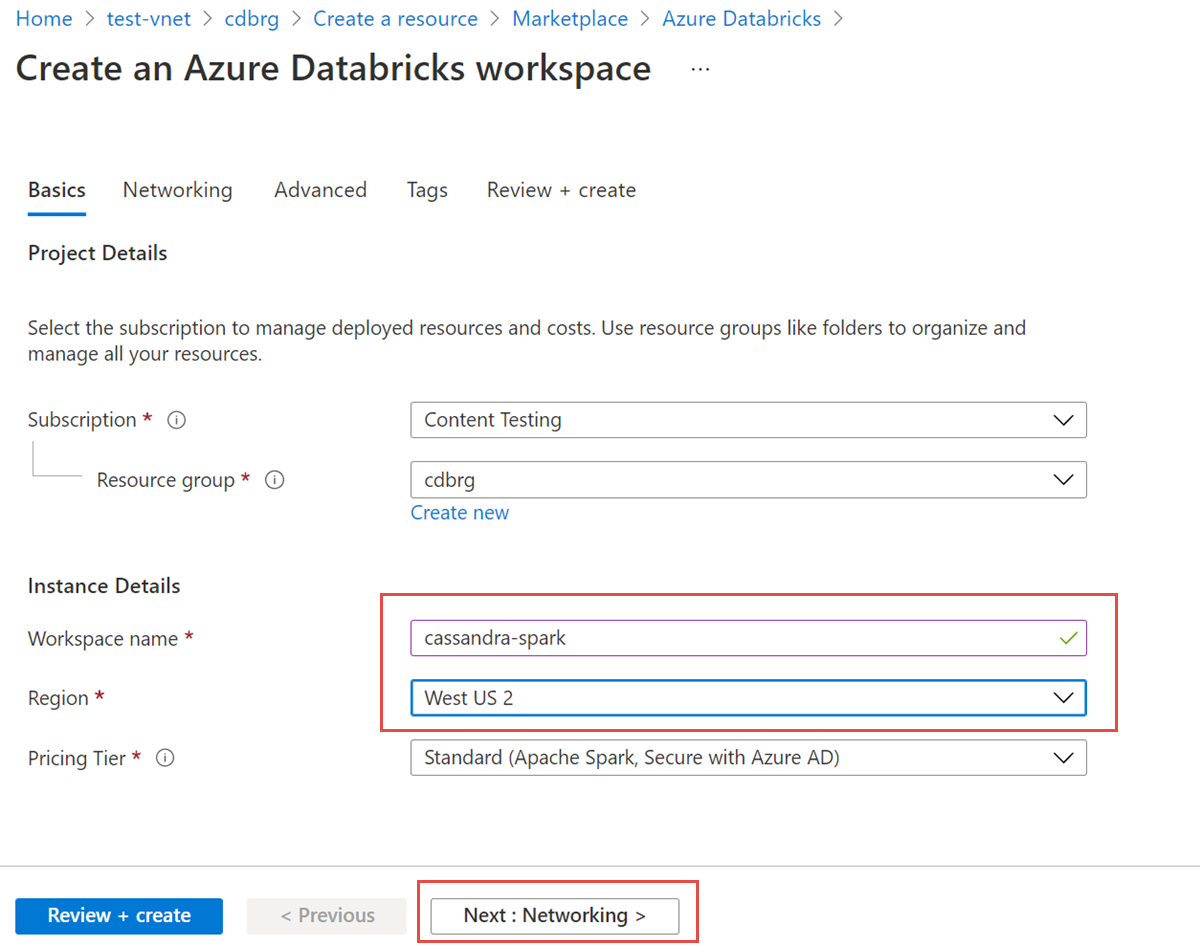
Immettere i valori seguenti:
- Nome area di lavoro: specificare un nome per l'area di lavoro di Azure Databricks.
- Area: assicurarsi di selezionare la stessa area della rete virtuale.
- Piano tariffario: selezionare Standard, Premium o Versione di valutazione. Per altre informazioni su questi livelli, vedere la pagina dei prezzi di Azure Databricks.
Selezionare la scheda Rete e immettere i dettagli seguenti:
- Distribuire l'area di lavoro di Azure Databricks nella rete virtuale: selezionare Sì.
- Rete virtuale: dall'elenco a discesa scegliere la rete virtuale in cui è presente l'istanza gestita.
- Nome subnet pubblica: inserire un nome per la subnet pubblica.
- Intervallo CIDR della subnet pubblica: immettere un intervallo IP per la subnet pubblica.
- Nome subnet privata: Inserisci un nome per la subnet privata.
- Intervallo CIDR del subnet privato: immettere un intervallo IP per il subnet privato.
Per evitare conflitti di intervallo, assicurarsi di selezionare intervalli più elevati. Se necessario, utilizzare un calcolatore di subnet visivo per suddividere le gamme.
Screenshot che mostra il Visual Subnet Calculator con due indirizzi di rete identici evidenziati.
Lo screenshot seguente mostra i dettagli di esempio nel riquadro di rete.
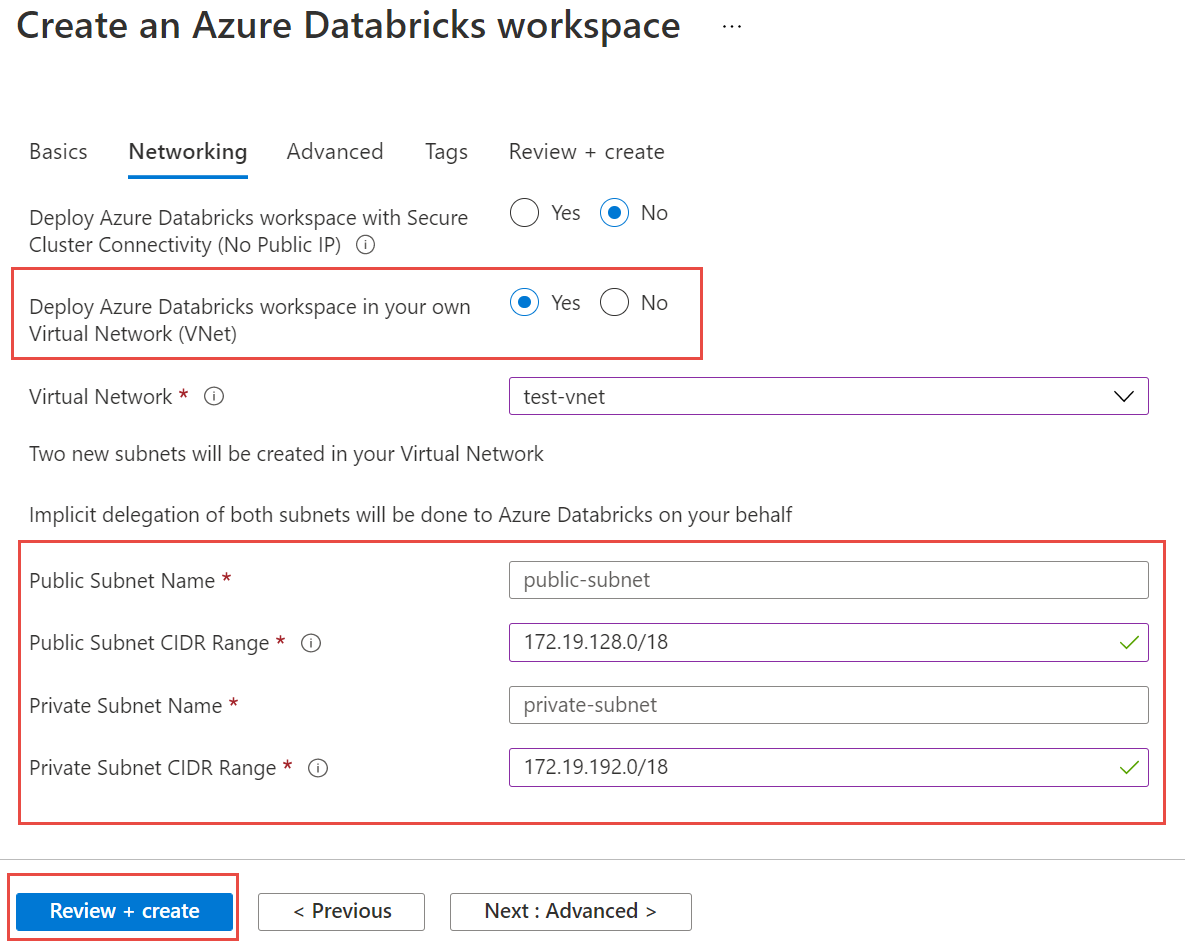
Selezionare Rivedi e crea e quindi crea per distribuire l'area di lavoro.
Aprire l'area di lavoro dopo la creazione dell'area di lavoro.
Si verrà reindirizzati al portale di Azure Databricks. Nel portale selezionare New Cluster (Nuovo cluster).
Nel riquadro Nuovo cluster accettare i valori predefiniti per tutti i campi diversi dai campi seguenti:
- Nome del cluster: Inserire un nome per il cluster.
- Versione di Databricks Runtime: è consigliabile selezionare Il runtime di Azure Databricks versione 7.5 o successiva per il supporto di Spark 3.x.

Espandere Opzioni avanzate e aggiungere la configurazione seguente. Assicurarsi di sostituire gli indirizzi IP e le credenziali del nodo.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueAggiungere la libreria del connettore Cassandra apache Spark al cluster per connettersi agli endpoint Cassandra nativi e di Azure Cosmos DB. Nel cluster selezionare Librerie>Installa nuovo>Maven e quindi aggiungere
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0nel campo Coordinate Maven.
Selezionare Installa.
Pulire le risorse
Se non si intende continuare a usare questo cluster di istanza gestita, seguire questa procedura per eliminarlo:
- Nel menu a sinistra del portale di Azure, selezionare Gruppi di risorse.
- Nell'elenco selezionare il gruppo di risorse creato per questa guida introduttiva.
- Nel riquadro Panoramica del gruppo di risorse selezionare Elimina gruppo di risorse.
- Nel riquadro successivo immettere il nome del gruppo di risorse da eliminare e quindi selezionare Elimina.
Passo successivo
In questa guida introduttiva si è appreso come creare un cluster Apache Spark completamente gestito all'interno della rete virtuale del cluster Istanza gestita di Azure per Apache Cassandra. Informazioni su come gestire le risorse del cluster e del data center.