Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa guida rapida, si apprenderà come utilizzare una risorsa Microsoft Planetary Computer Pro GeoCatalog in Azure Batch per elaborare dati geospaziali su larga scala.
Azure Batch è un servizio di pianificazione dei processi basato sul cloud che consente di eseguire carichi di lavoro HPC (High Performance Computing) su larga scala. Combinando Azure Batch con Microsoft Planetary Computer Pro, è possibile:
- Elaborare grandi volumi di dati geospaziali in parallelo tra più nodi di calcolo
- Eseguire l'autenticazione sicura alle API GeoCatalog usando le identità gestite
- Aumentare o ridurre la potenza di elaborazione in base alle esigenze del carico di lavoro
- Automatizzare le pipeline di dati geospaziali senza gestire l'infrastruttura
Questa guida introduttiva illustra come configurare un pool di Batch con un'identità gestita assegnata dall'utente, configurare le autorizzazioni per accedere a GeoCatalog ed eseguire processi che eseguono query sull'API STAC.
Suggerimento
Per una panoramica delle opzioni di sviluppo di applicazioni con Microsoft Planetary Computer Pro, vedere Connettere e creare applicazioni con i dati.
Prerequisiti
Prima di iniziare, assicurarsi di soddisfare i requisiti seguenti per completare questa guida introduttiva:
- Un account Azure con una sottoscrizione attiva. Usare il collegamento Crea un account gratuitamente.
- Una risorsa Microsoft Planetary Computer Pro GeoCatalog.
Un computer Linux con gli strumenti seguenti installati:
- Interfaccia della riga di comando di Azure
-
perlpacchetto.
Creare un account Batch
Creare un gruppo di risorse:
az group create \
--name spatiobatchdemo \
--location uksouth
Creare un account di archiviazione:
az storage account create \
--resource-group spatiobatchdemo \
--name spatiobatchstorage \
--location uksouth \
--sku Standard_LRS
Attribuire il ruolo Storage Blob Data Contributor all'utente corrente dell'account di archiviazione:
az role assignment create \
--role "Storage Blob Data Contributor" \
--assignee $(az account show --query user.name -o tsv) \
--scope $(az storage account show --name spatiobatchstorage --resource-group spatiobatchdemo --query id -o tsv)
Creare un account Batch:
az batch account create \
--name spatiobatch \
--storage-account spatiobatchstorage \
--resource-group spatiobatchdemo \
--location uksouth
Importante
Assicurarsi di avere una quota sufficiente per creare un pool di nodi computer. Se la quota non è sufficiente, è possibile richiedere un aumento seguendo le istruzioni riportate nella documentazione relativa alle quote e ai limiti di Azure Batch .
Accedere al nuovo account Batch eseguendo il comando seguente:
az batch account login \
--name spatiobatch \
--resource-group spatiobatchdemo \
--shared-key-auth
Dopo aver autenticato l'account con Batch, i comandi successivi az batch in questa sessione usano l'account Batch creato.
Creare un'identità gestita assegnata dall'utente:
az identity create \
--name spatiobatchidentity \
--resource-group spatiobatchdemo
Creare un pool di nodi di calcolo usando il portale di Azure:
- Nel portale di Azure passare all'account Batch e selezionare Pool:
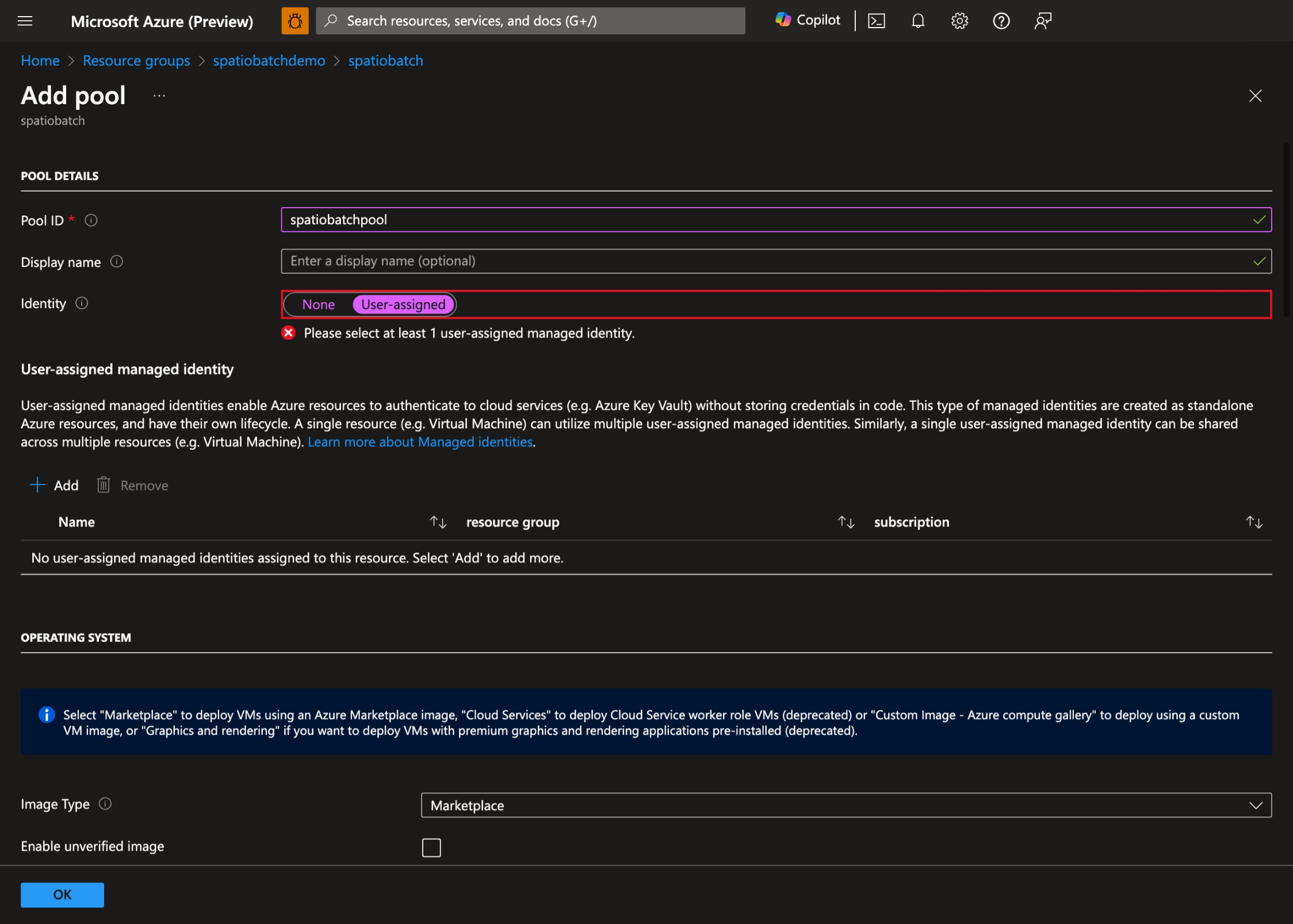
- Selezionare + Aggiungi per creare un nuovo pool e selezionare Assegnata dall'utente come identità del pool:
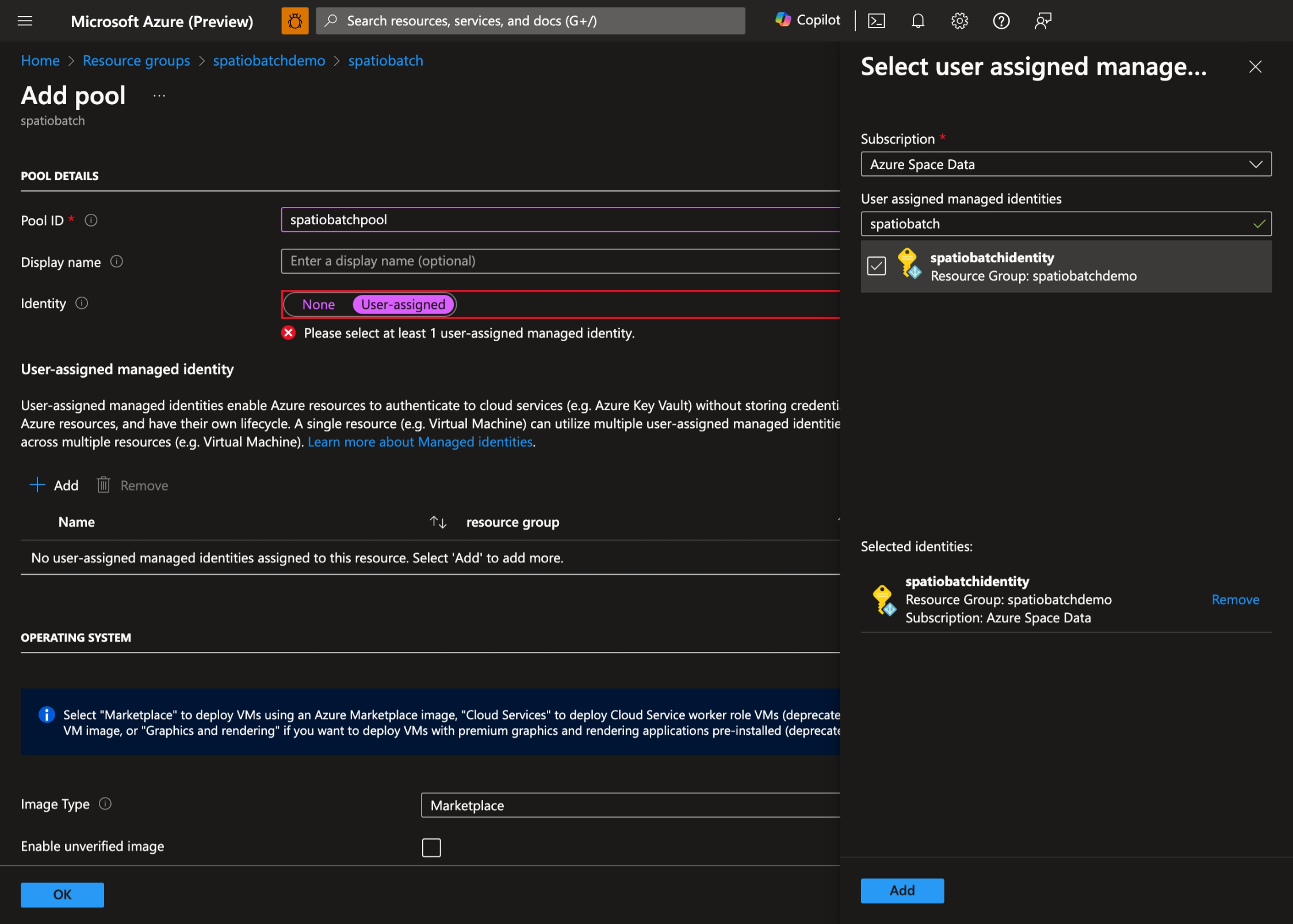
- Selezionare l'identità gestita assegnata dall'utente creata in precedenza:
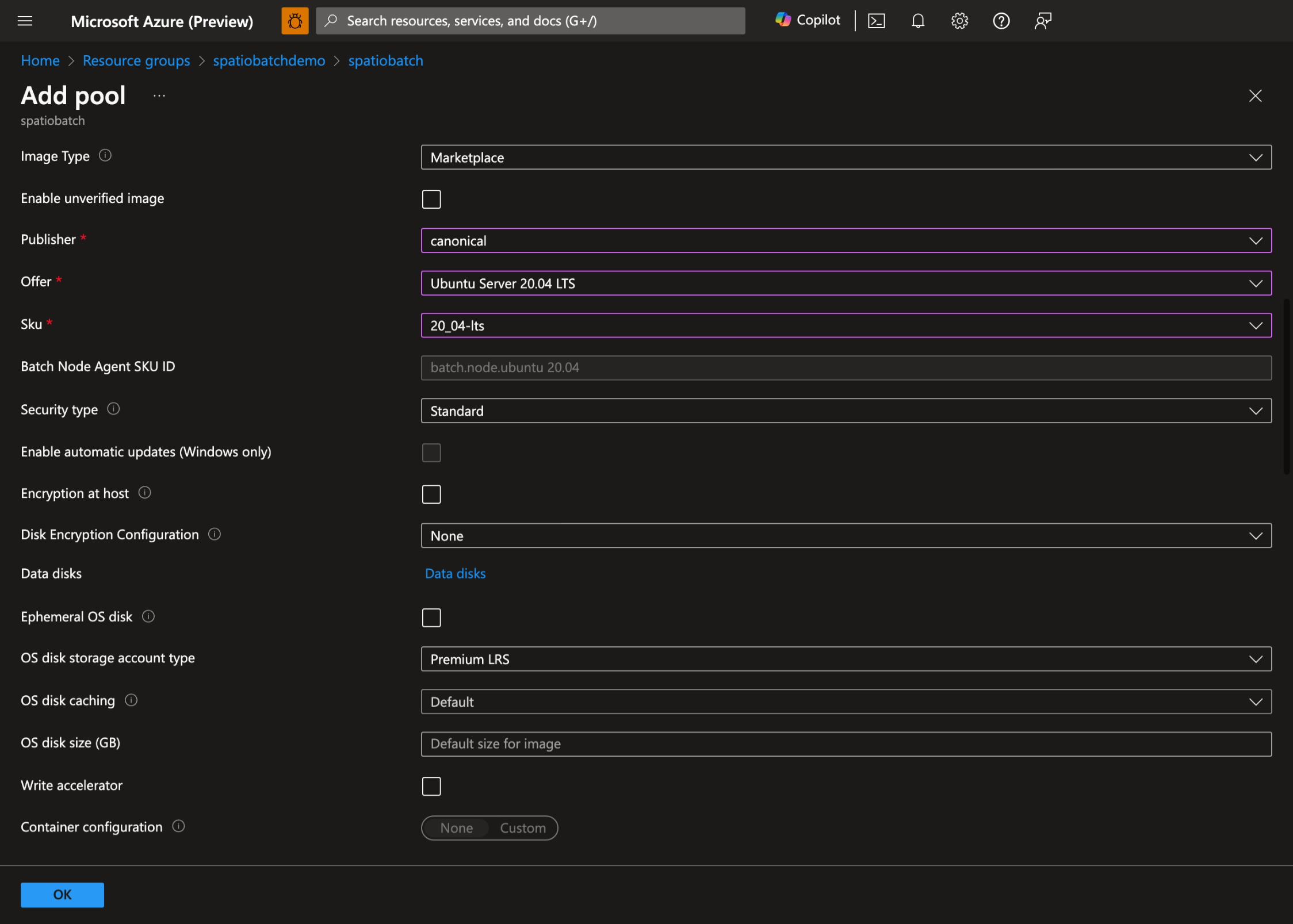
- Selezionare il sistema operativo preferito e le dimensioni della macchina virtuale. In questa demo si usa Ubuntu Server 20.04 LTS:
- Attivare Start Task, impostare il seguente Command line:
bash -c "apt-get update && apt-get install jq python3-pip -y && curl -sL https://aka.ms/InstallAzureCLIDeb | bash"e impostare il Livello di elevazione su Pool autouser, Admin: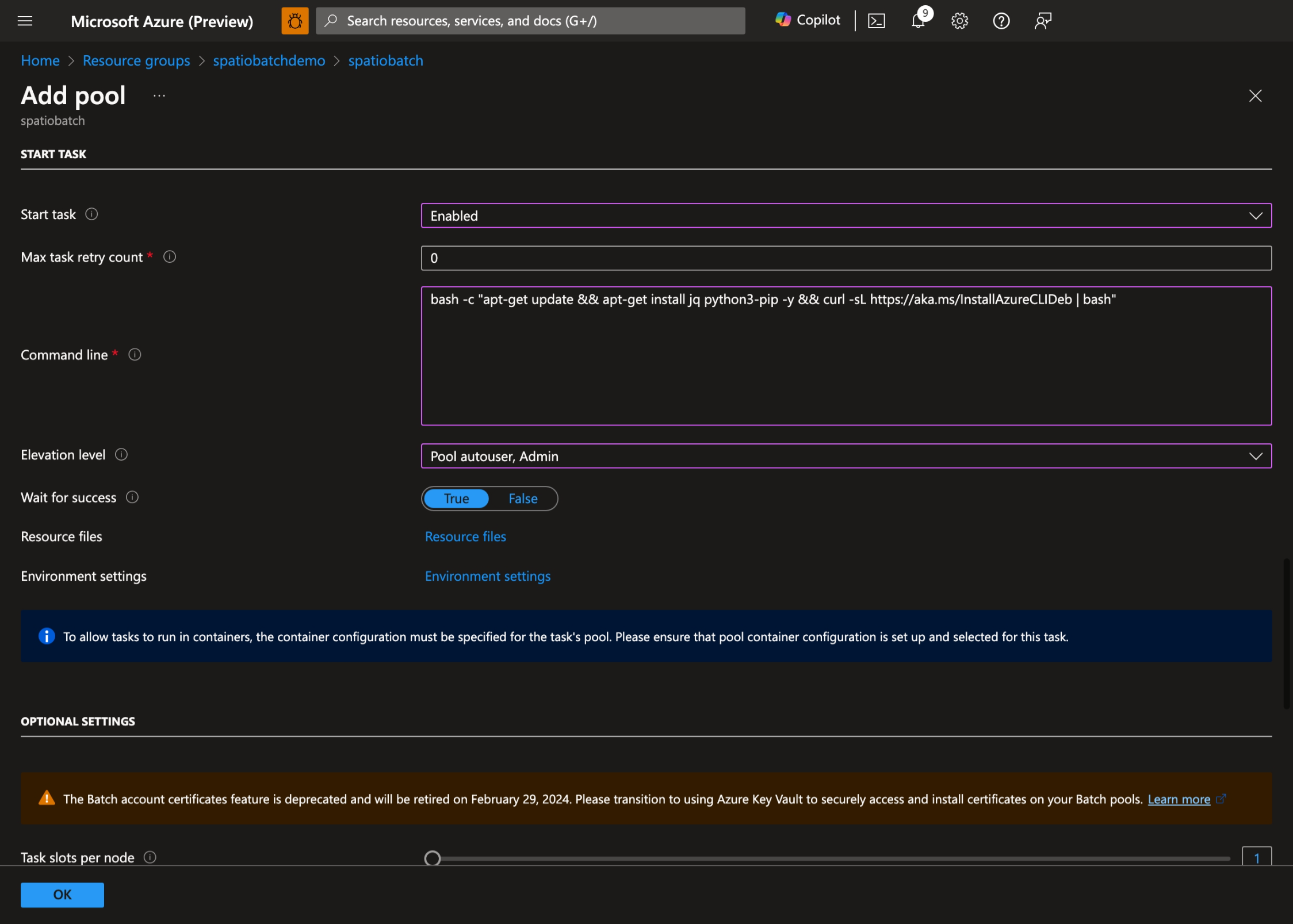
- Selezionare OK per creare il pool.





Assegnare autorizzazioni per l'identità gestita
È necessario fornire all'identità gestita l'accesso al GeoCatalog. Passare a GeoCatalog, selezionare Controllo di accesso (IAM) e selezionare Aggiungi assegnazione di ruolo:

Selezionare il ruolo appropriato in base alle esigenze GeoCatalog Administrator o GeoCatalog Readere selezionare Avanti:

Selezionare l'identità gestita creata e quindi selezionare Rivedi e assegna.

Preparare il processo Batch
Creare un contenitore nell'account di archiviazione:
az storage container create \
--name scripts \
--account-name spatiobatchstorage
Caricare lo script nel contenitore:
az storage blob upload \
--container-name scripts \
--file src/task.py \
--name task.py \
--account-name spatiobatchstorage
Eseguire i processi Batch
In questa guida introduttiva sono disponibili due esempi: uno script Python e uno script Bash. Puoi usare uno di loro per creare un lavoro.
Lavoro di script Python
Per eseguire il processo di script Python, eseguire i comandi seguenti:
geocatalog_url="<geocatalog url>"
token_expiration=$(date -u -d "30 minutes" "+%Y-%m-%dT%H:%M:%SZ")
python_task_url=$(az storage blob generate-sas --account-name spatiobatchstorage --container-name scripts --name task.py --permissions r --expiry $token_expiration --auth-mode login --as-user --full-uri -o tsv)
cat src/pythonjob.json | perl -pe "s,##PYTHON_TASK_URL##,$python_task_url,g" | perl -pe "s,##GEOCATALOG_URL##,$geocatalog_url,g" | az batch job create --json-file /dev/stdin
Il processo Python esegue il seguente script Python:
import json
from os import environ
import requests
from azure.identity import DefaultAzureCredential
MPCPRO_APP_ID = "https://geocatalog.spatio.azure.com"
credential = DefaultAzureCredential()
access_token = credential.get_token(f"{MPCPRO_APP_ID}/.default")
geocatalog_url = environ["GEOCATALOG_URL"]
response = requests.get(
f"{geocatalog_url}/stac/collections",
headers={"Authorization": "Bearer " + access_token.token},
params={"api-version": "2025-04-30-preview"},
)
print(json.dumps(response.json(), indent=2))
Che usa DefaultAzureCredential per eseguire l'autenticazione con l'identità gestita e recupera le raccolte da GeoCatalog. Per ottenere i risultati del processo, eseguire il comando seguente:
az batch task file download \
--job-id pythonjob1 \
--task-id task1 \
--file-path "stdout.txt" \
--destination /dev/stdout
Processo Bash
Per eseguire il processo di script Bash, eseguire i comandi seguenti:
geocatalog_url="<geocatalog url>"
cat src/bashjob.json | perl -pe "s,##GEOCATALOG_URL##,$geocatalog_url,g" | az batch job create --json-file /dev/stdin
Il processo Bash esegue lo script Bash seguente:
az login --identity --allow-no-subscriptions > /dev/null
token=$(az account get-access-token --resource https://geocatalog.spatio.azure.com --query accessToken --output tsv)
curl --header \"Authorization: Bearer $token\" $GEOCATALOG_URL/stac/collections | jq
Che usa az login --identity per eseguire l'autenticazione con l'identità gestita e recupera le raccolte da GeoCatalog. Per ottenere i risultati del processo, eseguire il comando seguente:
az batch task file download \
--job-id bashjob1 \
--task-id task1 \
--file-path "stdout.txt" \
--destination /dev/stdout
Contenuti correlati
- Connettere e compilare applicazioni con i dati
- Configurare l'autenticazione dell'applicazione per Microsoft Planetary Computer Pro
- Creare un'applicazione Web con Microsoft Planetary Computer Pro
- Utilizzare Microsoft Planetary Computer Pro Explorer
- Gestire l'accesso a Microsoft Planetary Computer Pro
- Configurare le identità gestite nei pool Batch
- Copiare applicazioni e dati nei nodi del pool
- Distribuire applicazioni ai nodi di calcolo con pacchetti applicativi Batch
- Creazione e uso di file di risorse