Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive come identificare e diagnosticare la causa radice delle query con esecuzione lenta.
Contenuto dell'articolo:
- Come identificare query con esecuzione lenta.
- Come identificare la relativa procedura con esecuzione lenta. Identificare una query lenta tra un elenco di query che appartengono alla stessa stored procedure con esecuzione lenta.
Prerequisiti
Abilitare le guide alla risoluzione dei problemi seguendo i passaggi descritti in Usare le guide alla risoluzione dei problemi.
Configurare l'estensione
auto_explainaggiungendo alla lista consentita e creando l'estensione.Dopo aver configurato l'estensione
auto_explain, modificare i parametri del server seguenti, che controllano il comportamento dell'estensione:-
auto_explain.log_analyzesuON. -
auto_explain.log_bufferssuON. -
auto_explain.log_min_durationin base alle esigenze dello scenario. -
auto_explain.log_timingsuON. -
auto_explain.log_verbosesuON.
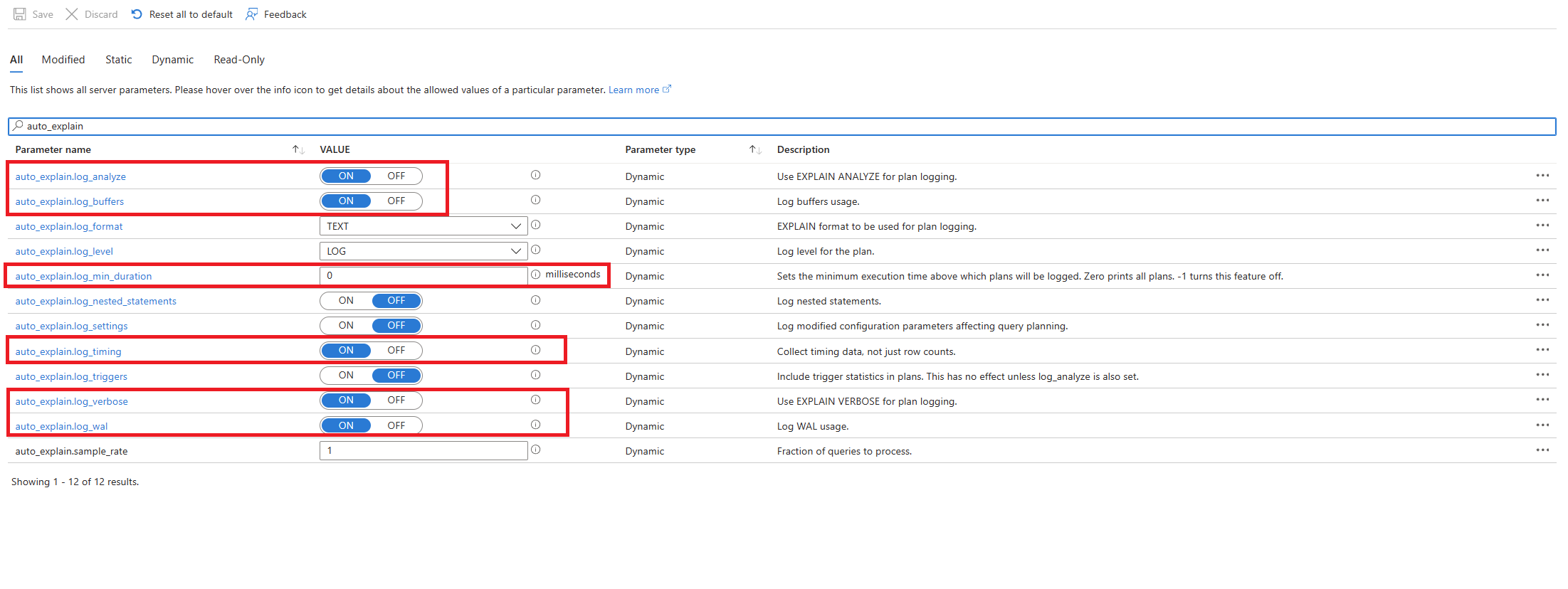
-

Nota
Se si imposta auto_explain.log_min_duration su 0, l'estensione avvia la registrazione di tutte le query eseguite nel server. Ciò potrebbe influire sulle prestazioni del database. Eseguire le opportune attività di due diligence adeguata per ottenere un valore considerato lento sul server. Ad esempio, se tutte le query vengono completate in meno di 30 secondi ed è accettabile per l'applicazione, è consigliabile aggiornare il parametro a 30.000 millisecondi. Verrà quindi registrata ogni query che impiega più di 30 secondi per essere completata.
Identificare una query lenta
Una volta implementate le guide alla risoluzione dei problemi e l'estensione auto_explain, lo scenario viene descritto con l'aiuto di un esempio.
Supponiamo che l'utilizzo della CPU raggiunga il 90% e si voglia determinare la causa del picco. Per eseguire il debug dello scenario, seguire questa procedura:
Non appena ricevi un avviso di uno scenario CPU, nel menu delle risorse dell'istanza del server flessibile di Azure Database per PostgreSQL interessata, nella sezione Monitoraggio, seleziona Guide alla risoluzione dei problemi.
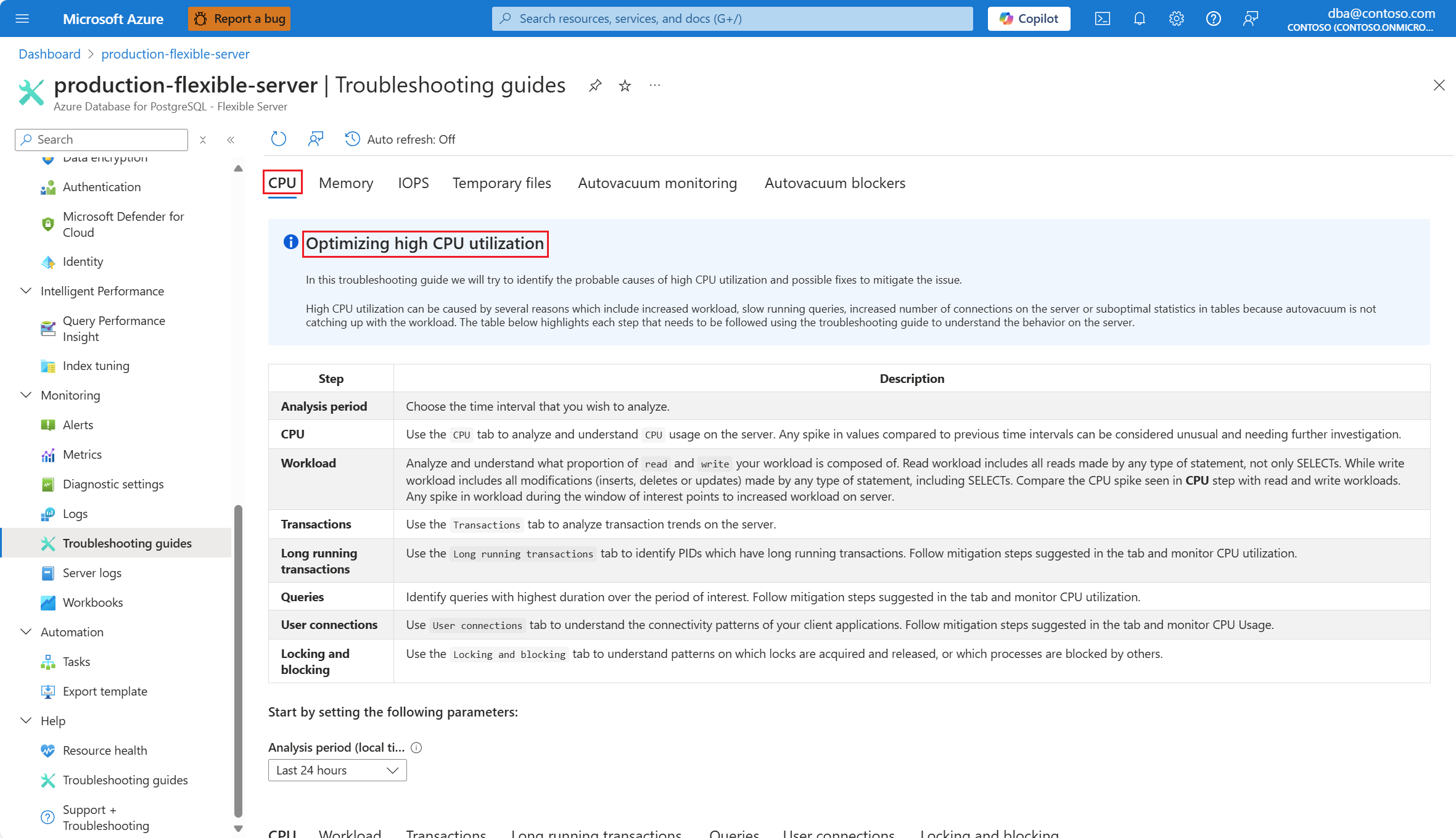
Selezionare la scheda CPU. Si apre la guida alla risoluzione dei problemi di Ottimizzazione dell'uso elevato della CPU.
Nell'elenco a discesa Periodo di analisi (ora locale) selezionare l'intervallo di tempo su cui concentrarsi l'analisi.
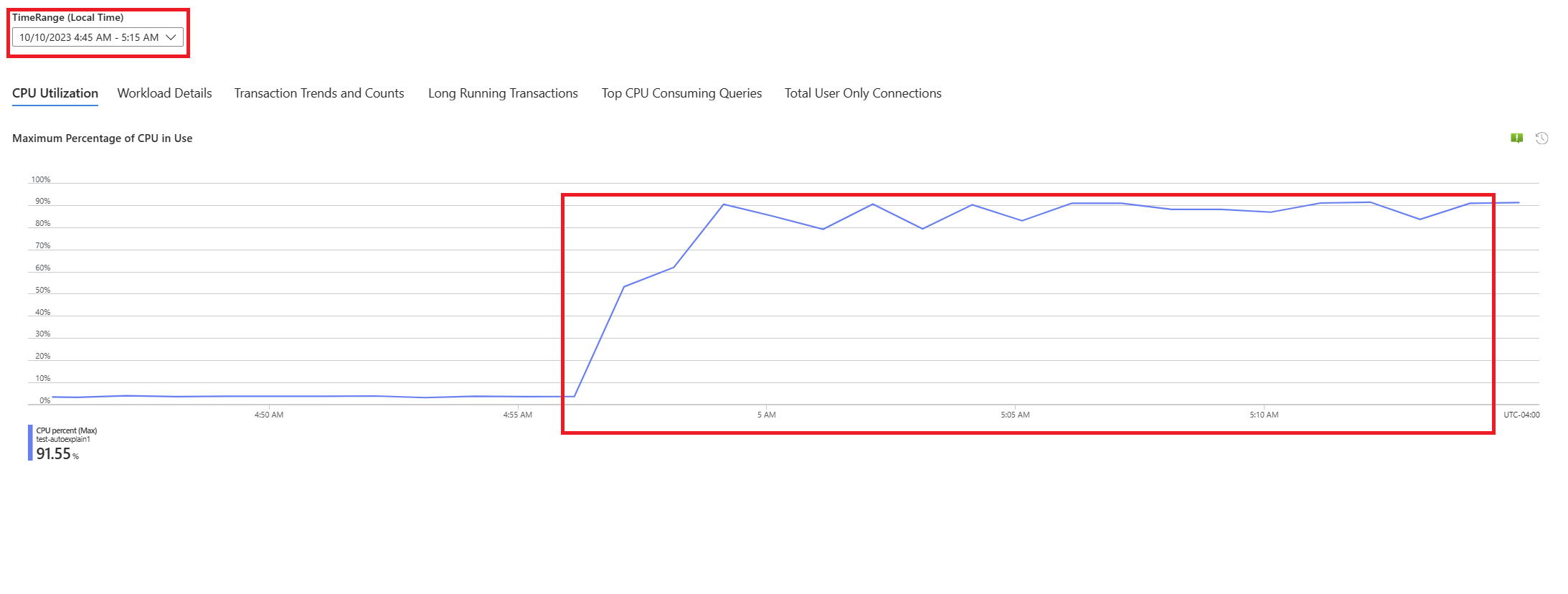
Selezionare la scheda Query. Vengono visualizzati i dettagli di tutte le query eseguite nell'intervallo in cui è stato rilevato un utilizzo della CPU al 90%. Dallo snapshot, sembra che la query con il tempo di esecuzione medio più lento durante l'intervallo di tempo sia di circa 2,6 minuti e che sia stata eseguita 22 volte durante l'intervallo. È probabile che la causa dei picchi di CPU risieda in questa query.
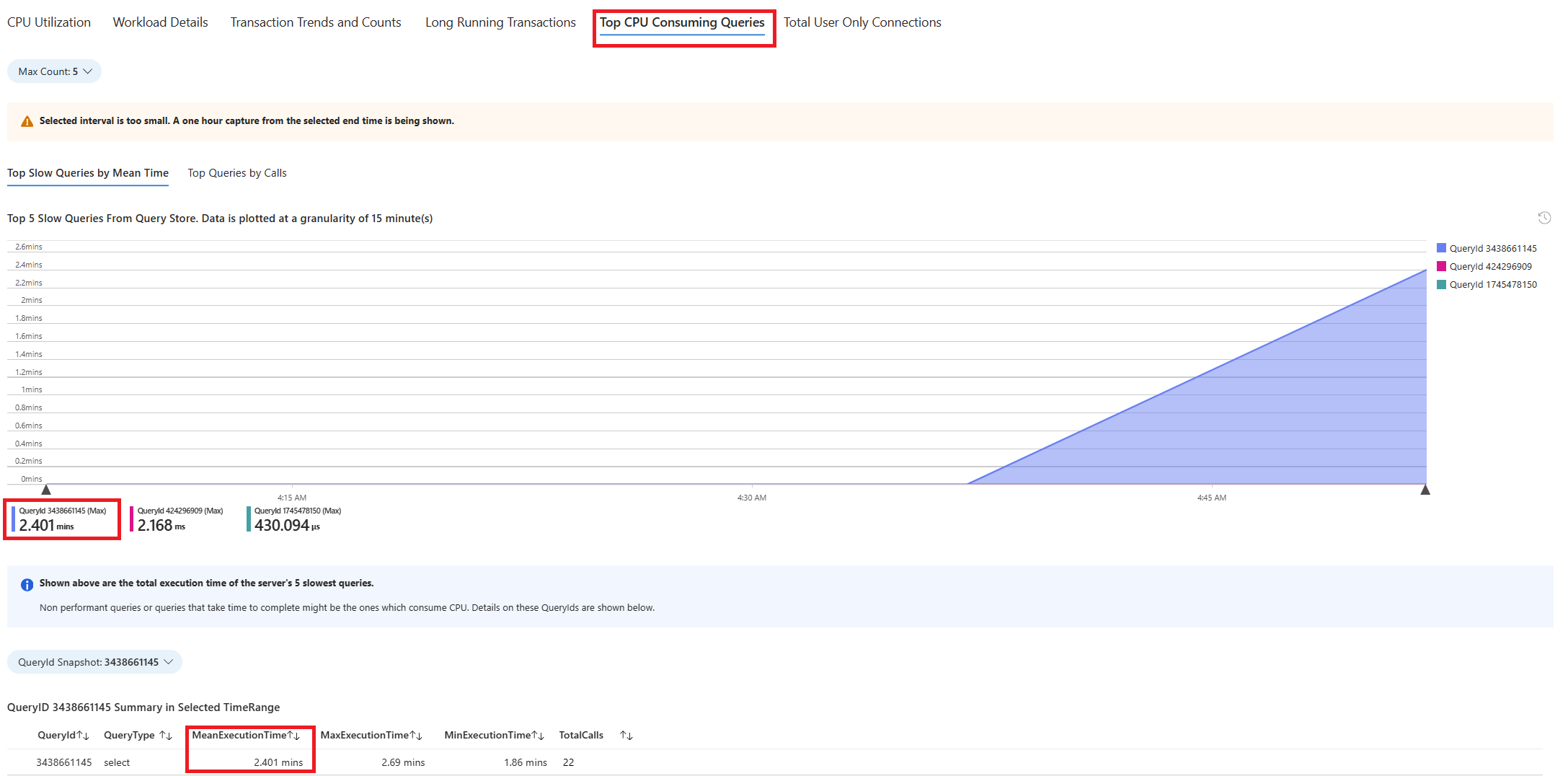
Per recuperare il testo effettivo della query, connettersi al database
azure_sysed eseguire la query seguente.




psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- Nell'esempio considerato, la query lenta individuata era la seguente:
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
Per comprendere quale piano di esecuzione esatto è stato generato, utilizzare i log di Azure Database per PostgreSQL. Ogni volta che l'esecuzione della query viene completata in tale intervallo di tempo, l'estensione
auto_explaindeve scrivere una voce nei log. Nel menu delle risorse, nella sezione Monitoraggio selezionare Log.
Selezionare l'intervallo di tempo in cui è stato rilevato un utilizzo della CPU al 90%.
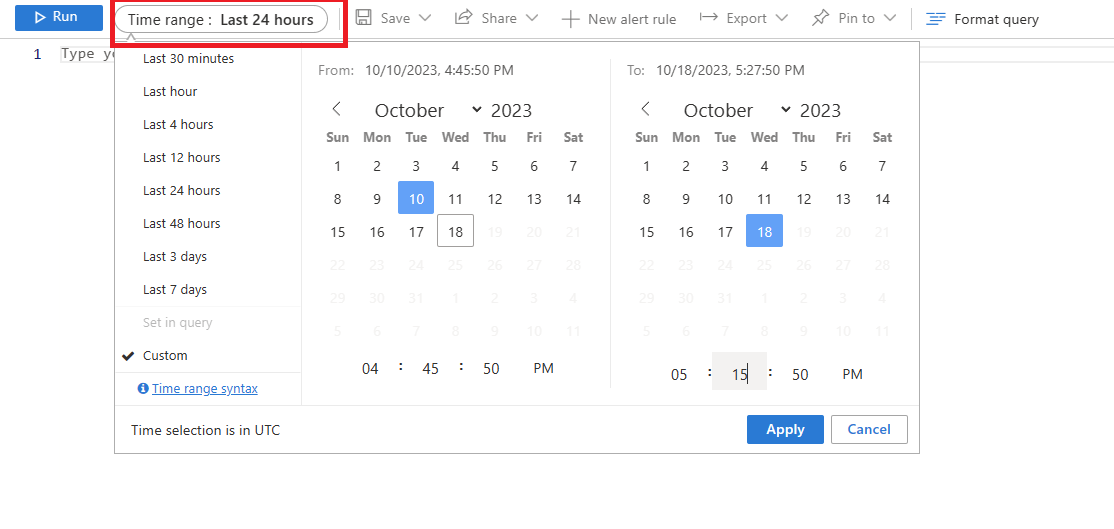
Eseguire la query seguente per recuperare l'output EXPLAIN ANALYZE per la query identificata.

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
La colonna di messaggio archivia il piano di esecuzione come illustrato in questo output:
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
La query è stata eseguita per circa 2,5 minuti, come illustrato nella guida alla risoluzione dei problemi. Il valore duration di 150692.864 ms recuperato dell'output del piano di esecuzione ne è una conferma. Usare l'output EXPLAIN ANALYZE per procedere con la risoluzione dei problemi e ottimizzare la query.
Nota
Si noti che la query è stata eseguita 22 volte durante l'intervallo e i log mostrati contengono registrazioni acquisite durante tale periodo.
Identificare una query con esecuzione lenta in una stored procedure
Una volta implementate le guide alla risoluzione dei problemi e l'estensione auto_explain, lo scenario viene descritto con l'aiuto di un esempio.
Supponiamo che l'utilizzo della CPU raggiunga il 90% e si voglia determinare la causa del picco. Per eseguire il debug dello scenario, seguire questa procedura:
Non appena ricevi un avviso di uno scenario CPU, nel menu delle risorse dell'istanza del server flessibile di Azure Database per PostgreSQL interessata, nella sezione Monitoraggio, seleziona Guide alla risoluzione dei problemi.
Selezionare la scheda CPU. Si apre la guida alla risoluzione dei problemi di Ottimizzazione dell'uso elevato della CPU.
Nell'elenco a discesa Periodo di analisi (ora locale) selezionare l'intervallo di tempo su cui concentrarsi l'analisi.
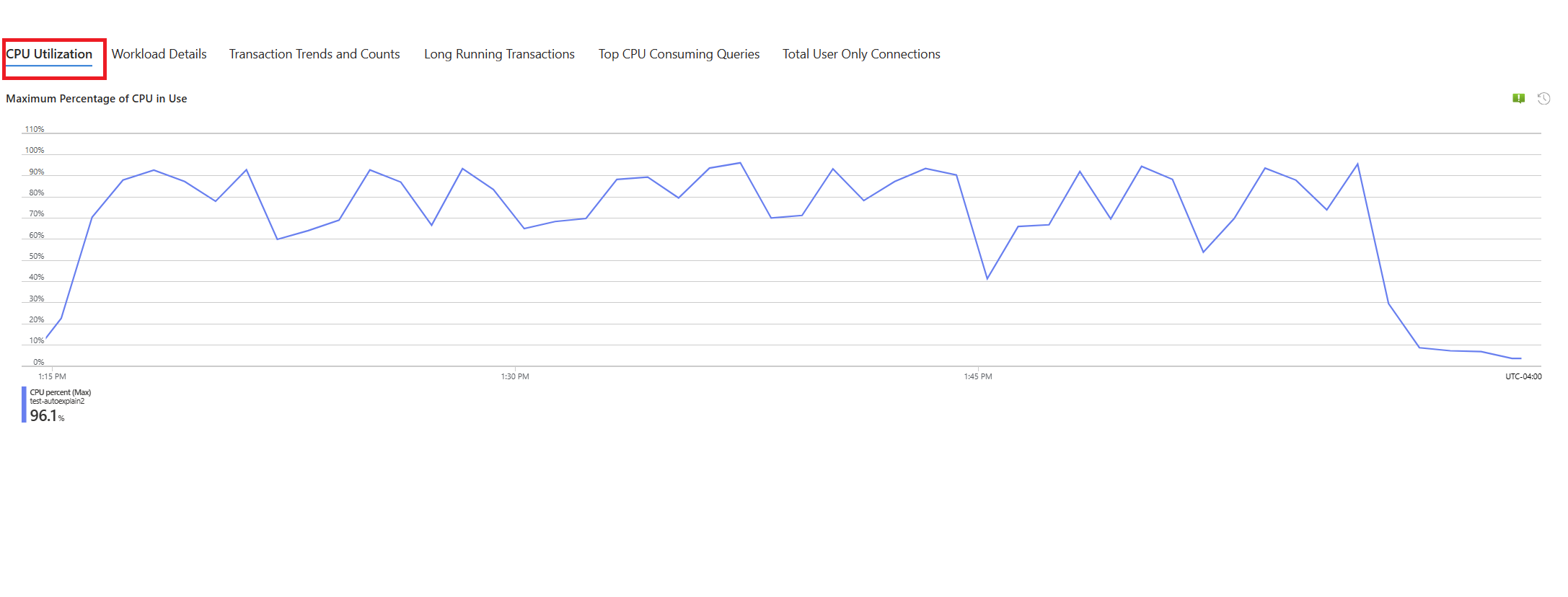
Selezionare la scheda Query. Vengono visualizzati i dettagli di tutte le query eseguite nell'intervallo in cui è stato rilevato un utilizzo della CPU al 90%. Dallo snapshot, sembra che la query con il tempo di esecuzione medio più lento durante l'intervallo di tempo sia di circa 2,6 minuti e che sia stata eseguita 22 volte durante l'intervallo. È probabile che la causa dei picchi di CPU risieda in questa query.
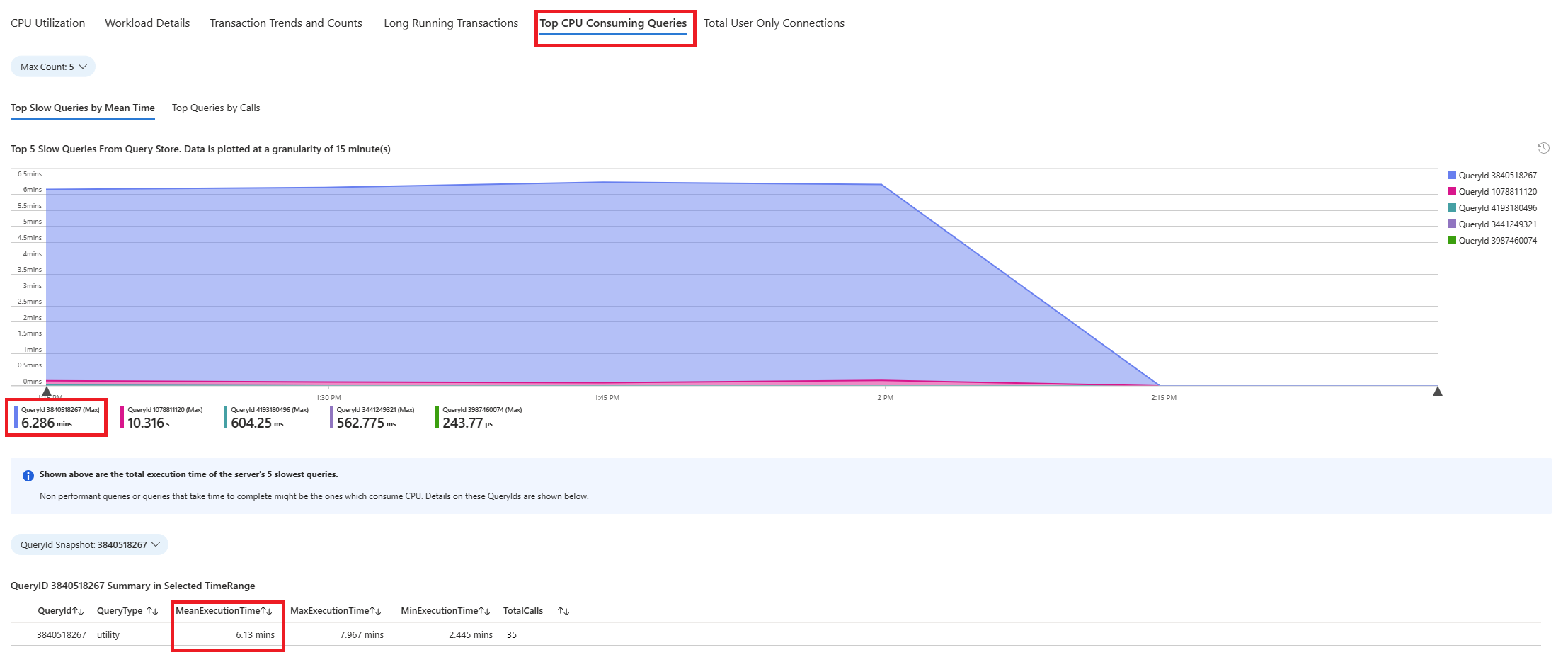
Connettersi al database azure_sys ed eseguire la query per recuperare il testo effettivo usando lo script seguente.


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- Nell'esempio considerato, la query lenta individuata era una stored procedure:
call autoexplain_test ();
- Per comprendere quale piano di esecuzione esatto è stato generato, utilizzare i log di Azure Database per PostgreSQL. Ogni volta che l'esecuzione della query viene completata in tale intervallo di tempo, l'estensione
auto_explaindeve scrivere una voce nei log. Nel menu delle risorse, nella sezione Monitoraggio selezionare Log. Quindi, in Intervallo di tempo:, selezionare l'intervallo di tempo su cui incentrare l'analisi.

- Eseguire la query seguente per recuperare l'output explain analyze per la query identificata.
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
La procedura include più query, evidenziate di seguito. L'output explain analyze di ogni query usata nella stored procedure viene registrato per un'analisi approfondita e la risoluzione dei problemi. Il tempo di esecuzione delle query registrate può essere usato per identificare le query più lente che fanno parte della stored procedure.
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
Nota
A scopo dimostrativo, viene visualizzato solo l'output EXPLAIN ANALYZE di alcune query usate nella procedura. L'idea è di raccogliere l'output EXPLAIN ANALYZE di tutte le query dai log, quindi di identificare la più lenta e provare a ottimizzarla.
Contenuti correlati
- Risolvere i problemi di utilizzo elevato della CPU in Database di Azure per PostgreSQL.
- Risolvere i problemi di utilizzo elevato di IOPS in Azure Database per PostgreSQL.
- Risolvere i problemi di utilizzo elevato della memoria in Database di Azure per PostgreSQL.
- Parametri del server in Database di Azure per PostgreSQL.
- Ottimizzazione di Autovacuum in Azure Database per PostgreSQL.