Configurazione a disponibilità elevata in SUSE usando il dispositivo di fencing
In questo articolo verranno illustrati i passaggi per configurare la disponibilità elevata (HA) in istanze large di HANA nel sistema operativo SUSE usando il dispositivo di fencing.
Nota
Questa guida è derivata dal test della configurazione nell'ambiente Istanze large di Microsoft HANA. Il team di gestione dei servizi Microsoft per istanze large di HANA non supporta il sistema operativo. Per la risoluzione dei problemi o il chiarimento sul livello del sistema operativo, contattare SUSE.
Il team di Gestione servizi Microsoft esegue la configurazione e supporta completamente il dispositivo di fencing. Può aiutare a risolvere i problemi del dispositivo di fencing.
Prerequisiti
Per configurare la disponibilità elevata usando il clustering SUSE, è necessario:
- Effettuare il provisioning di istanze large di HANA.
- Installare e registrare il sistema operativo con le patch più recenti.
- Connettere i server di istanze large DI HANA al server SMT per ottenere patch e pacchetti.
- Configurare il protocollo di ora di rete (server di ora NTP).
- Leggere e comprendere la documentazione più recente di SUSE sulla configurazione di disponibilità elevata.
Dettagli di configurazione
Questa guida usa la configurazione seguente:
- Sistema operativo: SLES 12 SP1 per SAP
- Istanze di grandi dimensioni di HANA: 2xS192 (4 socket, 2 TB)
- Versione di HANA: HANA 2.0 SP1
- Nomi server: sapprdhdb95 (node1) e sapprdhdb96 (node2)
- Dispositivo di isolamento: basato su iSCSI
- NTP in uno dei nodi dell'istanza large di HANA
Quando si configurano istanze large DI HANA con la replica del sistema HANA, è possibile richiedere al team di Gestione servizi Microsoft di configurare il dispositivo di isolamento. Eseguire questa operazione al momento del provisioning.
Se si è un cliente esistente con istanze large di HANA già sottoposto a provisioning, è comunque possibile configurare il dispositivo di fencing. Fornire le informazioni seguenti al team di Gestione servizi Microsoft nel modulo di richiesta di servizio (SRF). È possibile ottenere SRF tramite Technical Account Manager o il contatto Microsoft per l'onboarding di istanze large di HANA.
- Nome server e indirizzo IP server (ad esempio, myhanaserver1 e 10.35.0.1)
- Posizione (ad esempio, Stati Uniti orientali)
- Nome del cliente (ad esempio, Microsoft)
- IDENTIFICATORe di sistema HANA (SID) (ad esempio, H11)
Dopo aver configurato il dispositivo di protezione, il team di Gestione servizi Microsoft fornisce il nome SBD e l'indirizzo IP dell'archiviazione iSCSI. È possibile usare queste informazioni per configurare la configurazione della fencing.
Seguire la procedura descritta nelle sezioni seguenti per configurare la disponibilità elevata usando il dispositivo di fencing.
Identificare il dispositivo SBD
Nota
Questa sezione si applica solo ai clienti esistenti. Se sei un nuovo cliente, il team di Gestione servizi Microsoft ti darà il nome del dispositivo SBD, quindi ignora questa sezione.
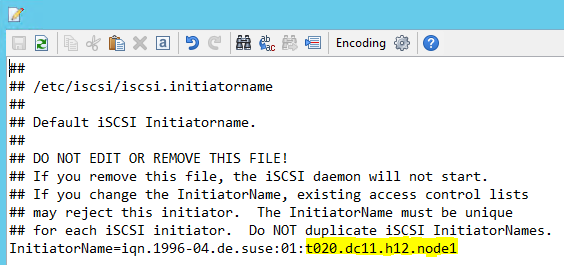
Modificare /etc/iscsi/initiatorname.isci to:
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>Microsoft Service Management fornisce questa stringa. Modificare il file in entrambi i nodi. Tuttavia, il numero di nodo è diverso in ogni nodo.
Modificare /etc/iscsi/iscsid.conf impostando
node.session.timeo.replacement_timeout=5enode.startup = automatic. Modificare il file in entrambi i nodi.Eseguire il comando di individuazione seguente in entrambi i nodi.
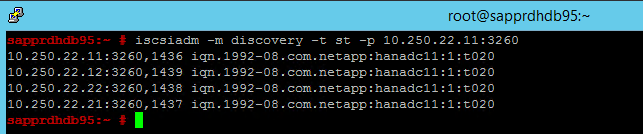
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260I risultati mostrano quattro sessioni.
Eseguire il comando seguente in entrambi i nodi per accedere al dispositivo iSCSI.
iscsiadm -m node -lI risultati mostrano quattro sessioni.

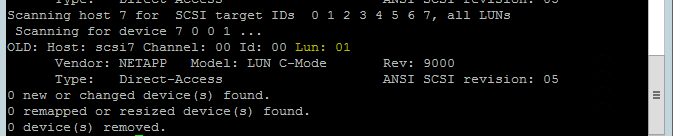
Usare il comando seguente per eseguire lo script di rescan-scsi-bus.sh rescan. Questo script mostra i nuovi dischi creati per l'utente. Eseguirlo in entrambi i nodi.
rescan-scsi-bus.shI risultati devono mostrare un numero LUN maggiore di zero(ad esempio: 1, 2 e così via).
Per ottenere il nome del dispositivo, eseguire il comando seguente in entrambi i nodi.
fdisk –lNei risultati scegliere il dispositivo con le dimensioni di 178 MiB.

Inizializzare il dispositivo SBD
Usare il comando seguente per inizializzare il dispositivo SBD in entrambi i nodi.
sbd -d <SBD Device Name> create
Usare il comando seguente in entrambi i nodi per verificare cosa è stato scritto nel dispositivo.
sbd -d <SBD Device Name> dump
Configurare il cluster SUSE HA
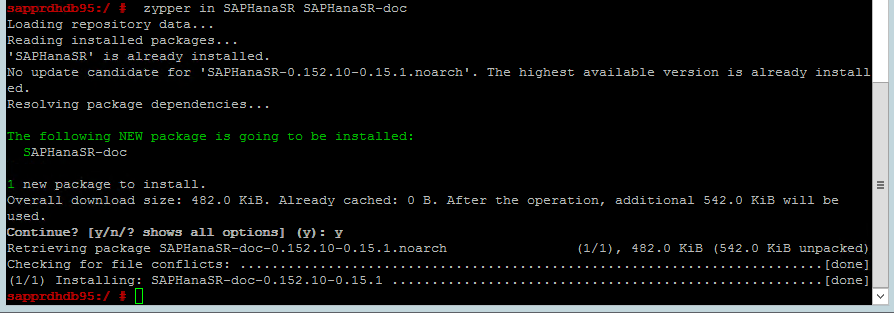
Usare il comando seguente per verificare se i modelli ha_sles e SAPHanaSR-doc vengono installati in entrambi i nodi. Se non sono installati, installarli.
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc
Configurare il cluster usando il comando o la
ha-cluster-initprocedura guidata yast2. In questo esempio viene usata la procedura guidata yast2. Eseguire questo passaggio solo nel nodo primario.Passare a yast2>Clustera disponibilità> elevata.
Nella finestra di dialogo visualizzata sull'installazione del pacchetto hawk selezionare Annulla perché il pacchetto halk2 è già installato.
Nella finestra di dialogo visualizzata per continuare selezionare Continua.
Il valore previsto è il numero di nodi distribuiti (in questo caso, 2). Selezionare Avanti.
Aggiungere i nomi dei nodi e quindi selezionare Aggiungi file suggeriti.
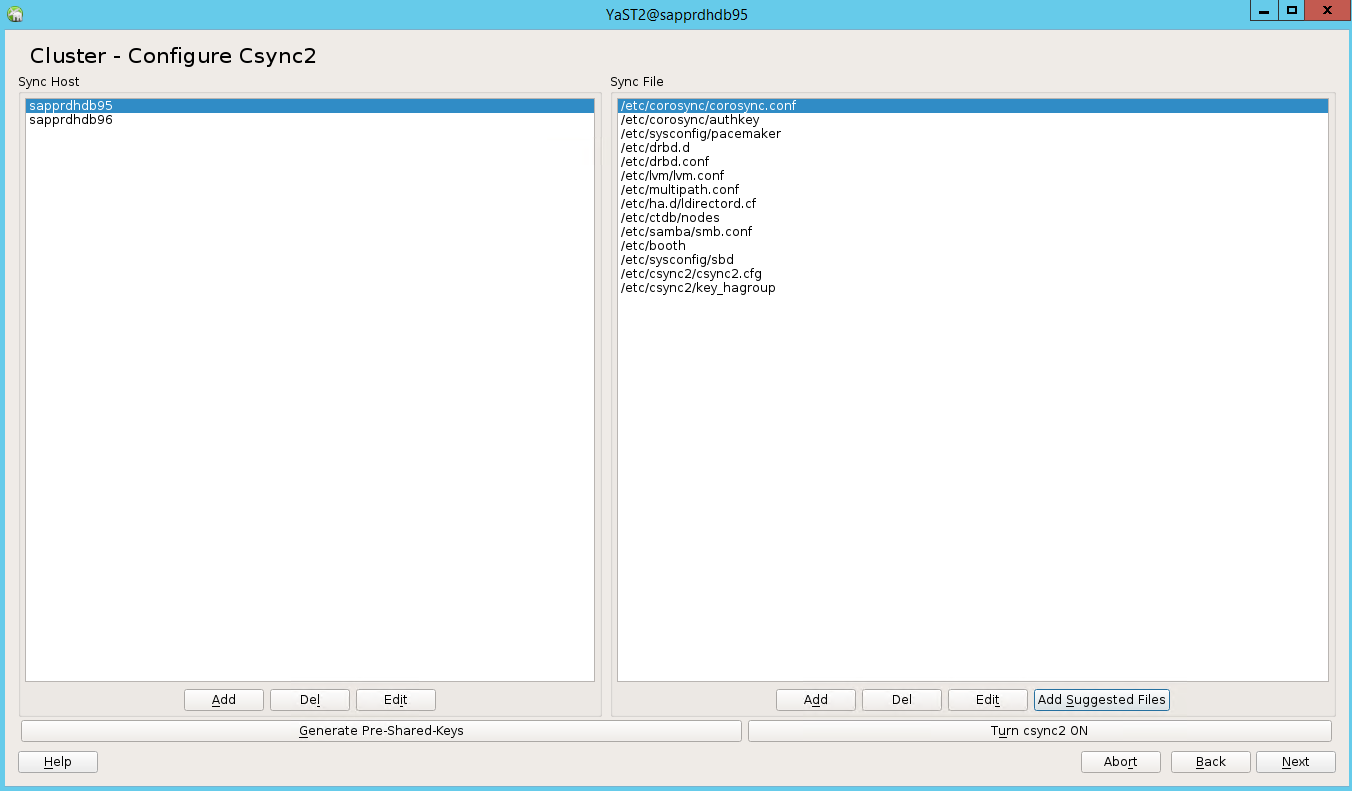
Selezionare Attiva csync2.
Selezionare Genera chiavi pre-condivise.
Nel messaggio popup visualizzato selezionare OK.
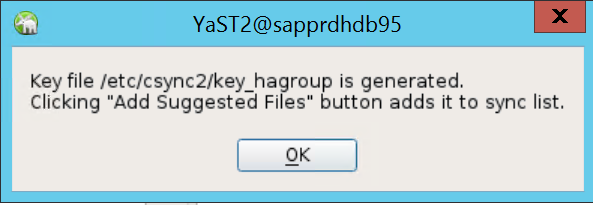
L'autenticazione viene eseguita usando gli indirizzi IP e le chiavi precondividi in Csync2. Il file di chiave viene generato con
csync2 -k /etc/csync2/key_hagroup.Copiare manualmente il file key_hagroup in tutti i membri del cluster dopo la creazione. Assicurarsi di copiare il file da node1 a node2. Fare quindi clic su Avanti.
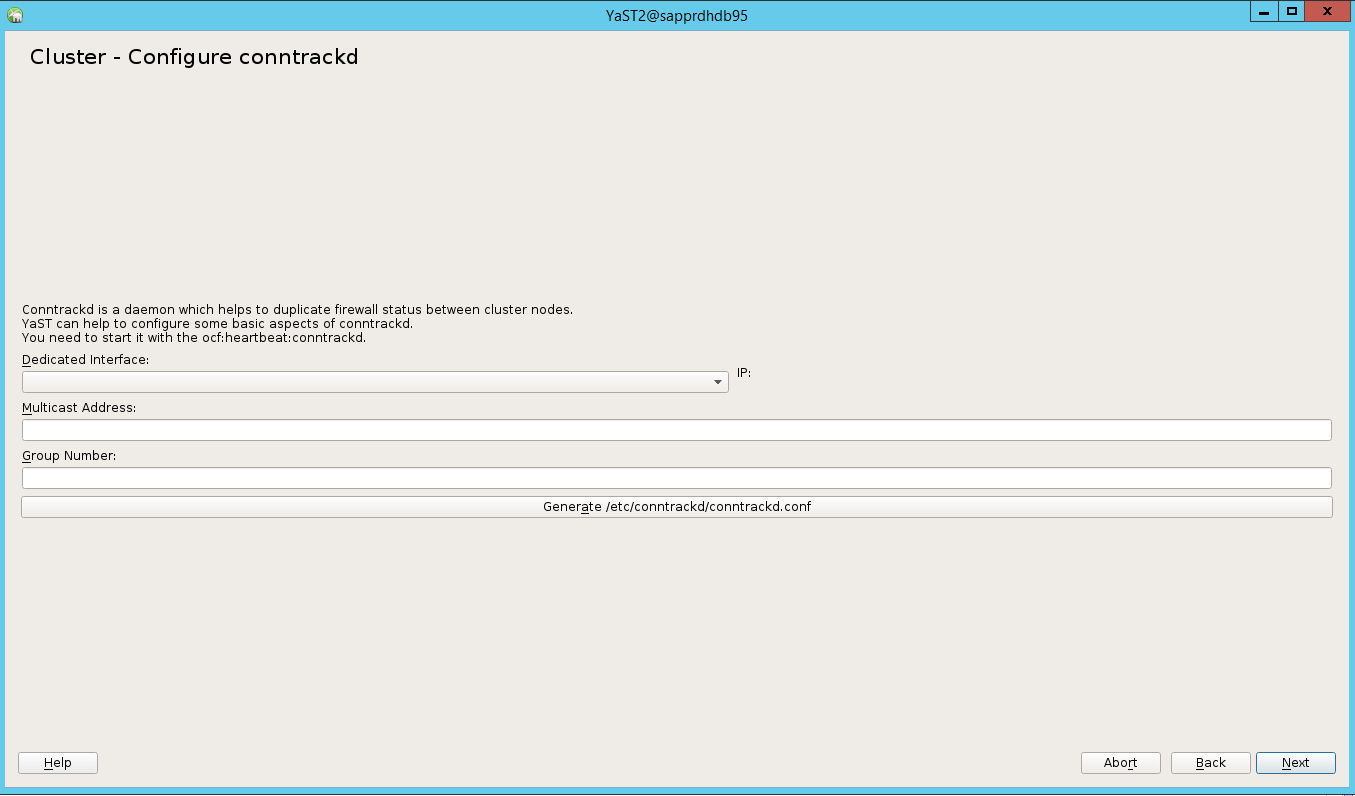
Nell'opzione predefinita, l'avvio è disattivato. Impostarlo su Attivato, quindi il servizio pacemaker viene avviato all'avvio. È possibile effettuare la scelta in base ai requisiti di configurazione.
Selezionare Avanti e la configurazione del cluster è completata.
Configurare il watchdog softdog
Aggiungere la riga seguente a /etc/init.d/boot.local in entrambi i nodi.
modprobe softdog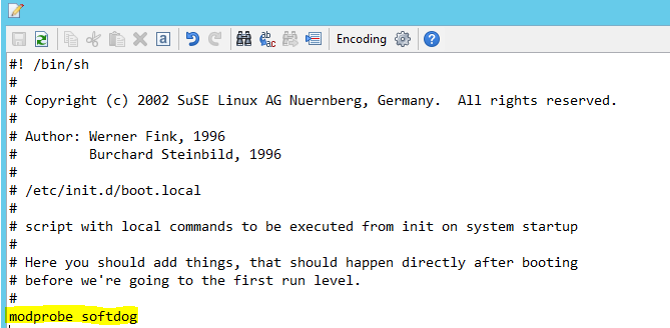
Usare il comando seguente per aggiornare il file /etc/sysconfig/sbd in entrambi i nodi.
SBD_DEVICE="<SBD Device Name>"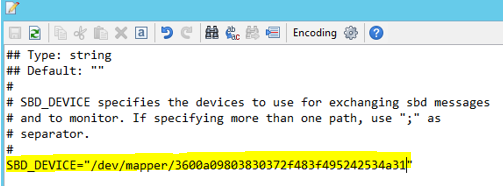
Caricare il modulo kernel in entrambi i nodi eseguendo il comando seguente.
modprobe softdog
Usare il comando seguente per assicurarsi che softdog sia in esecuzione in entrambi i nodi.
lsmod | grep dog
Usare il comando seguente per avviare il dispositivo SBD in entrambi i nodi.
/usr/share/sbd/sbd.sh start
Usare il comando seguente per testare il daemon SBD in entrambi i nodi.
sbd -d <SBD Device Name> listI risultati mostrano due voci dopo la configurazione in entrambi i nodi.

Inviare il messaggio di test seguente a uno dei nodi.
sbd -d <SBD Device Name> message <node2> <message>Nel secondo nodo (node2), usare il comando seguente per controllare lo stato del messaggio.
sbd -d <SBD Device Name> list
Per adottare la configurazione SBD, aggiornare il file /etc/sysconfig/sbd come segue in entrambi i nodi.
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""Usare il comando seguente per avviare il servizio pacemaker nel nodo primario (node1).
systemctl start pacemaker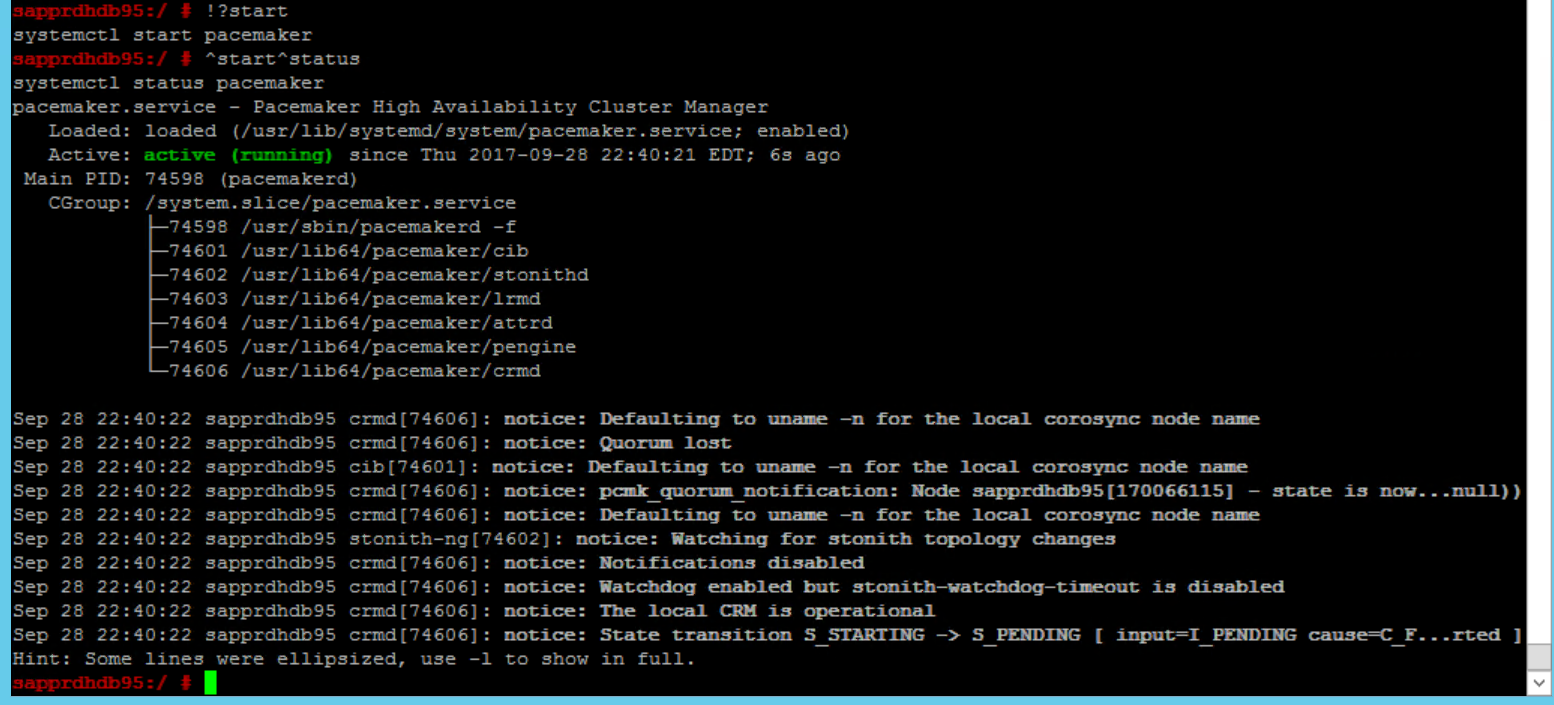
Se il servizio pacemaker ha esito negativo, vedere la sezione Scenario 5: Il servizio Pacemaker ha esito negativo più avanti in questo articolo.
Aggiungere il nodo al cluster
Eseguire il comando seguente in node2 per consentire al nodo di partecipare al cluster.
ha-cluster-join
Se viene visualizzato un errore durante l'aggiunta del cluster, vedere la sezione Scenario 6: Node2 non può partecipare al cluster più avanti in questo articolo.
Convalidare il cluster
Usare i comandi seguenti per controllare e avviare facoltativamente il cluster per la prima volta in entrambi i nodi.
systemctl status pacemaker systemctl start pacemaker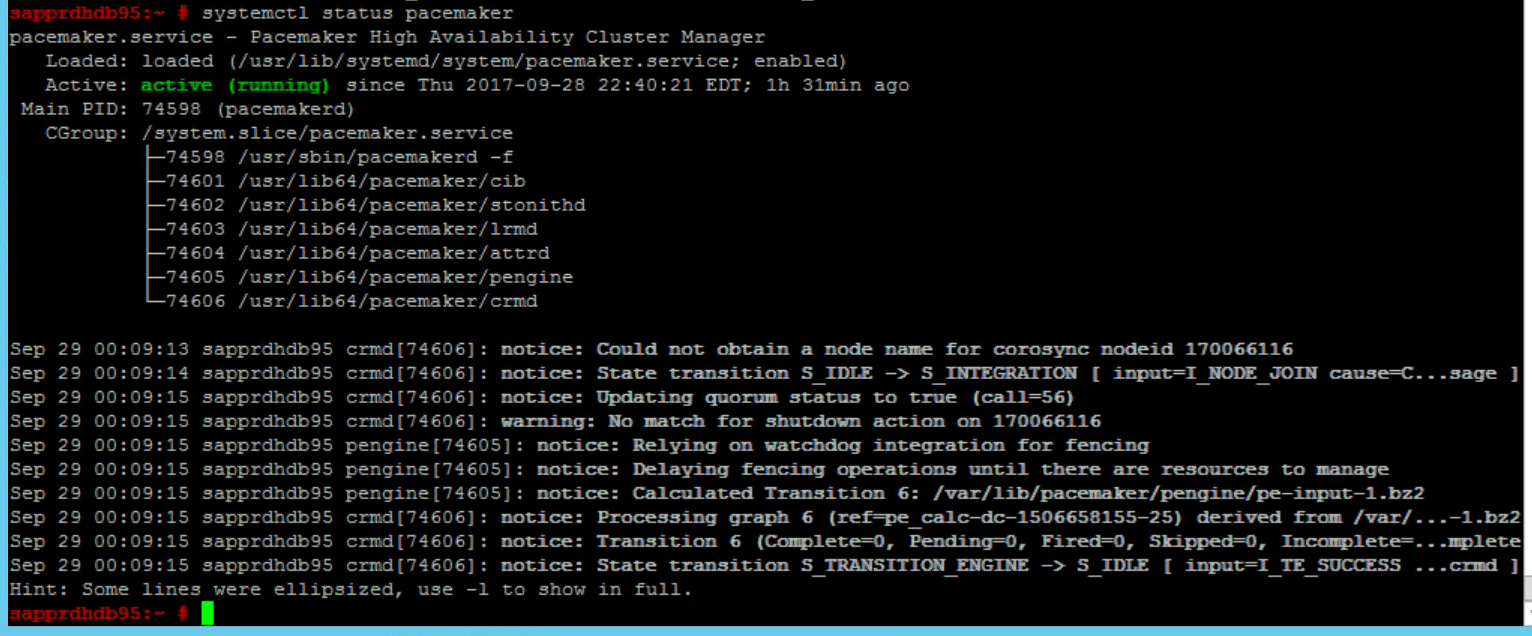
Eseguire il comando seguente per assicurarsi che entrambi i nodi siano online. È possibile eseguirlo in uno dei nodi del cluster.
crm_mon
È anche possibile accedere a hawk per controllare lo stato del cluster:
https://\<node IP>:7630. L'utente predefinito è hacluster e la password è linux. Se necessario, è possibile modificare la password usando ilpasswdcomando .
Configurare le proprietà e le risorse del cluster
Questa sezione descrive i passaggi per configurare le risorse del cluster. In questo esempio vengono configurate le risorse seguenti. È possibile configurare il resto (se necessario) facendo riferimento alla guida SUSE HA.
- Bootstrap del cluster
- Dispositivo di fencing
- Indirizzo IP virtuale
Eseguire la configurazione solo nel nodo primario .
Creare il file bootstrap del cluster e configurarlo aggiungendo il testo seguente.
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"Usare il comando seguente per aggiungere la configurazione al cluster.
crm configure load update crm-bs.txt
Configurare il dispositivo di fencing aggiungendo la risorsa, creando il file e aggiungendo testo come indicato di seguito.
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"Usare il comando seguente per aggiungere la configurazione al cluster.
crm configure load update crm-sbd.txtAggiungere l'indirizzo IP virtuale per la risorsa creando il file e aggiungendo il testo seguente.
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"Usare il comando seguente per aggiungere la configurazione al cluster.
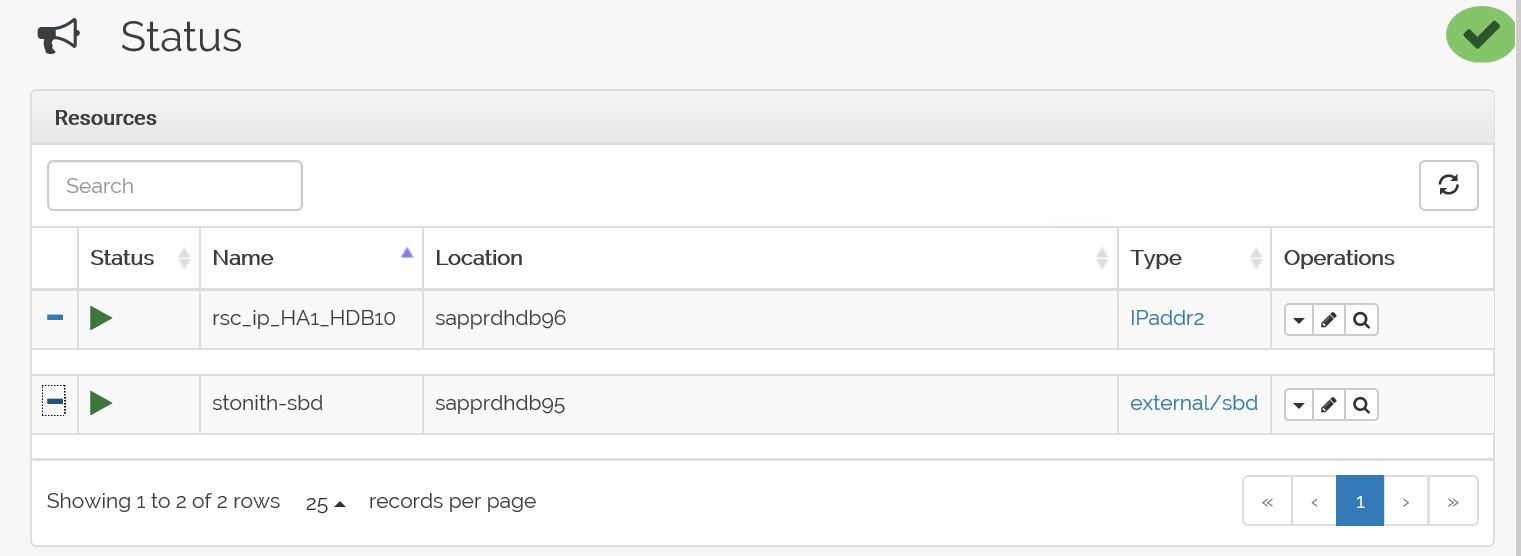
crm configure load update crm-vip.txtUsare il
crm_moncomando per convalidare le risorse.I risultati mostrano le due risorse.

È anche possibile controllare lo stato all'indirizzo> IP https://< node:7630/cib/live/state.
Testare il processo di failover
Per testare il processo di failover, usare il comando seguente per arrestare il servizio pacemaker in node1.
Service pacemaker stopLe risorse hanno eseguito il failover su node2.
Arrestare il servizio pacemaker in node2 e le risorse hanno eseguito il failover su node1.
Ecco lo stato prima del failover:
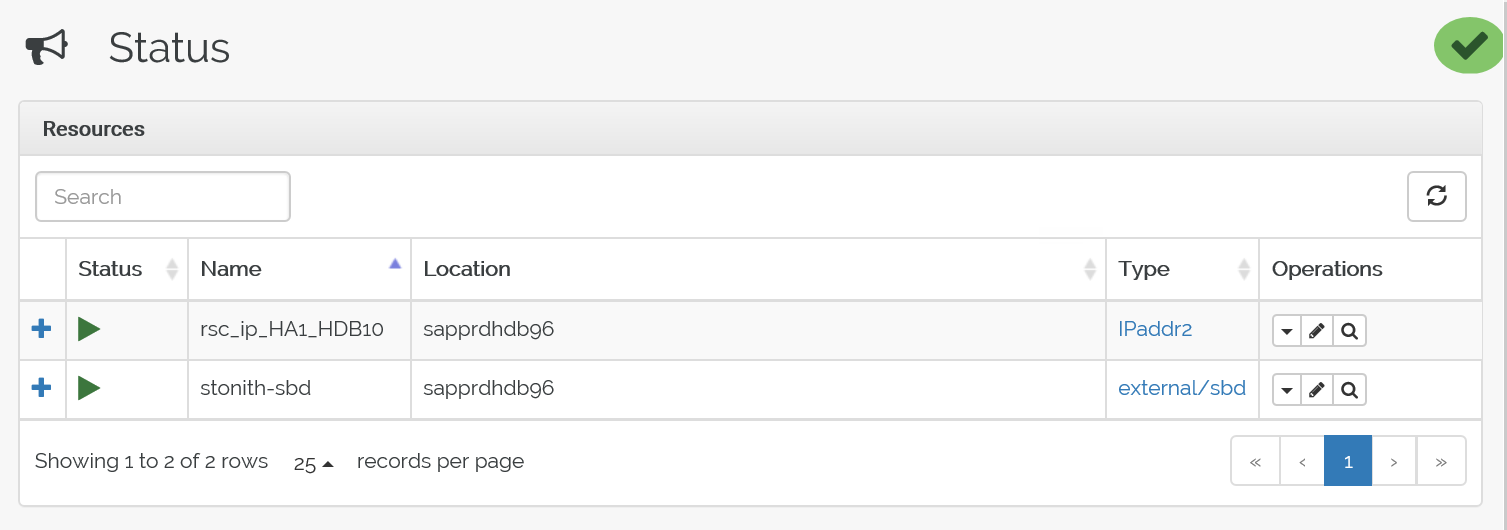
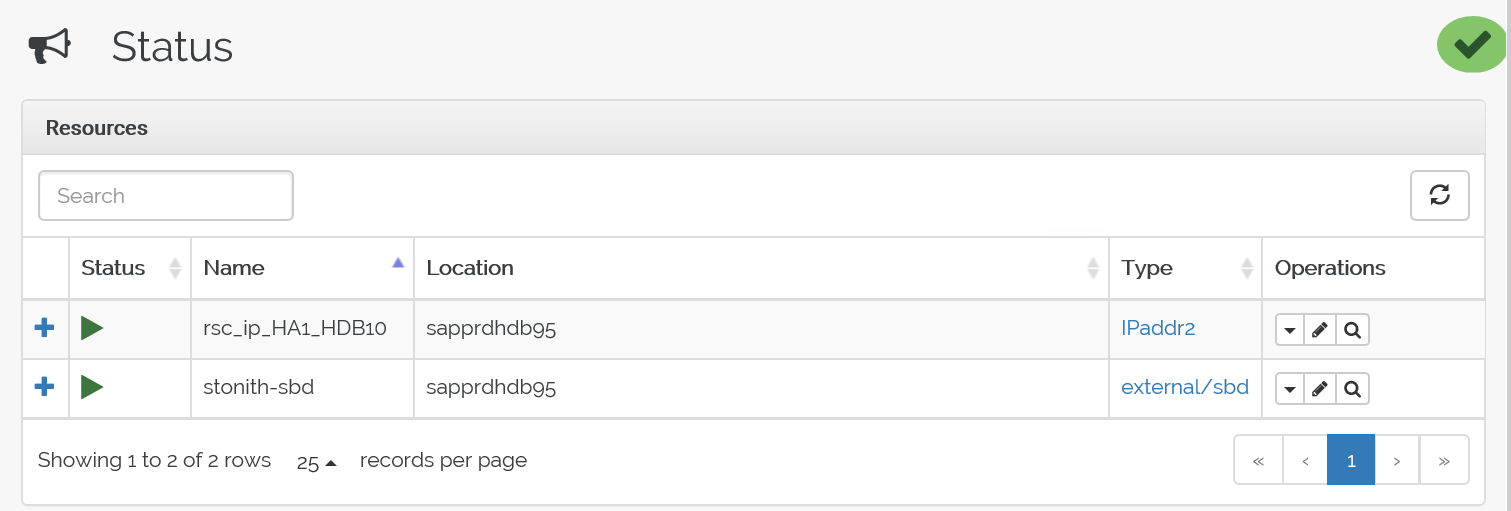
Ecco lo stato dopo il failover:

Risoluzione dei problemi
Questa sezione descrive gli scenari di errore che potrebbero verificarsi durante l'installazione.
Scenario 1: Nodo del cluster non online
Se uno dei nodi non viene visualizzato online in Cluster Manager, è possibile provare questa procedura per portarla online.
Usare il comando seguente per avviare il servizio iSCSI.
service iscsid startUsare il comando seguente per accedere a tale nodo iSCSI.
iscsiadm -m node -lL'output previsto è simile al seguente:
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
Scenario 2: Yast2 non mostra la visualizzazione grafica
La schermata grafica yast2 viene usata per configurare il cluster a disponibilità elevata in questo articolo. Se yast2 non viene aperto con la finestra grafica come illustrato e genera un errore Qt, seguire questa procedura per installare i pacchetti necessari. Se si apre con la finestra grafica, è possibile ignorare la procedura.
Ecco un esempio dell'errore Qt:

Ecco un esempio dell'output previsto:
Assicurarsi di aver eseguito l'accesso come utente "root" e di aver configurato SMT per scaricare e installare i pacchetti.
Passare a Yast>Software>Management>Dependencies e quindi selezionare Installa pacchetti consigliati.
Nota
Eseguire i passaggi in entrambi i nodi, in modo che sia possibile accedere alla visualizzazione grafica yast2 da entrambi i nodi.
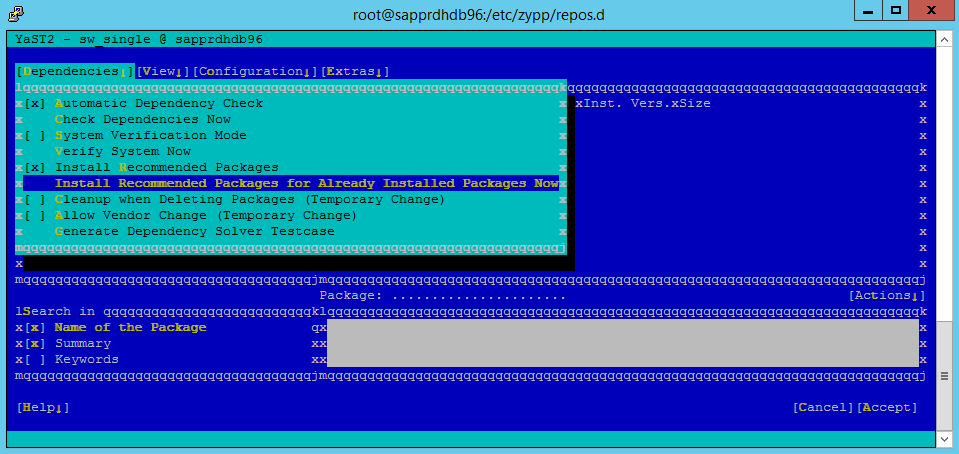
Lo screenshot seguente mostra la schermata prevista.
In Dipendenze selezionare Installa pacchetti consigliati.
Esaminare le modifiche e selezionare OK.
L'installazione del pacchetto procede.
Selezionare Avanti.
Quando viene visualizzata la schermata Installazione completata , selezionare Fine.
Usare i comandi seguenti per installare i pacchetti libqt4 e libyui-qt.
zypper -n install libqt4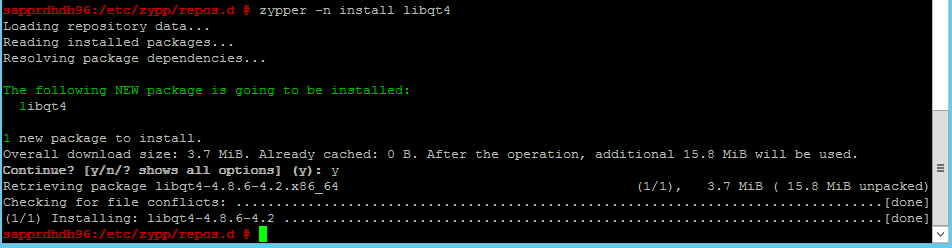
zypper -n install libyui-qt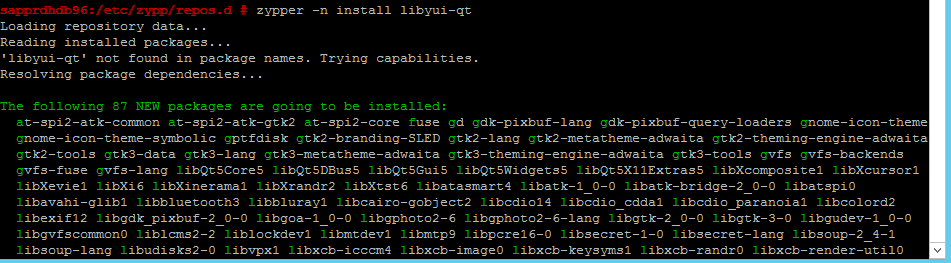

Yast2 può ora aprire la visualizzazione grafica.
Scenario 3: Yast2 non mostra l'opzione a disponibilità elevata
Per visualizzare l'opzione a disponibilità elevata nel centro di controllo yast2, è necessario installare gli altri pacchetti.
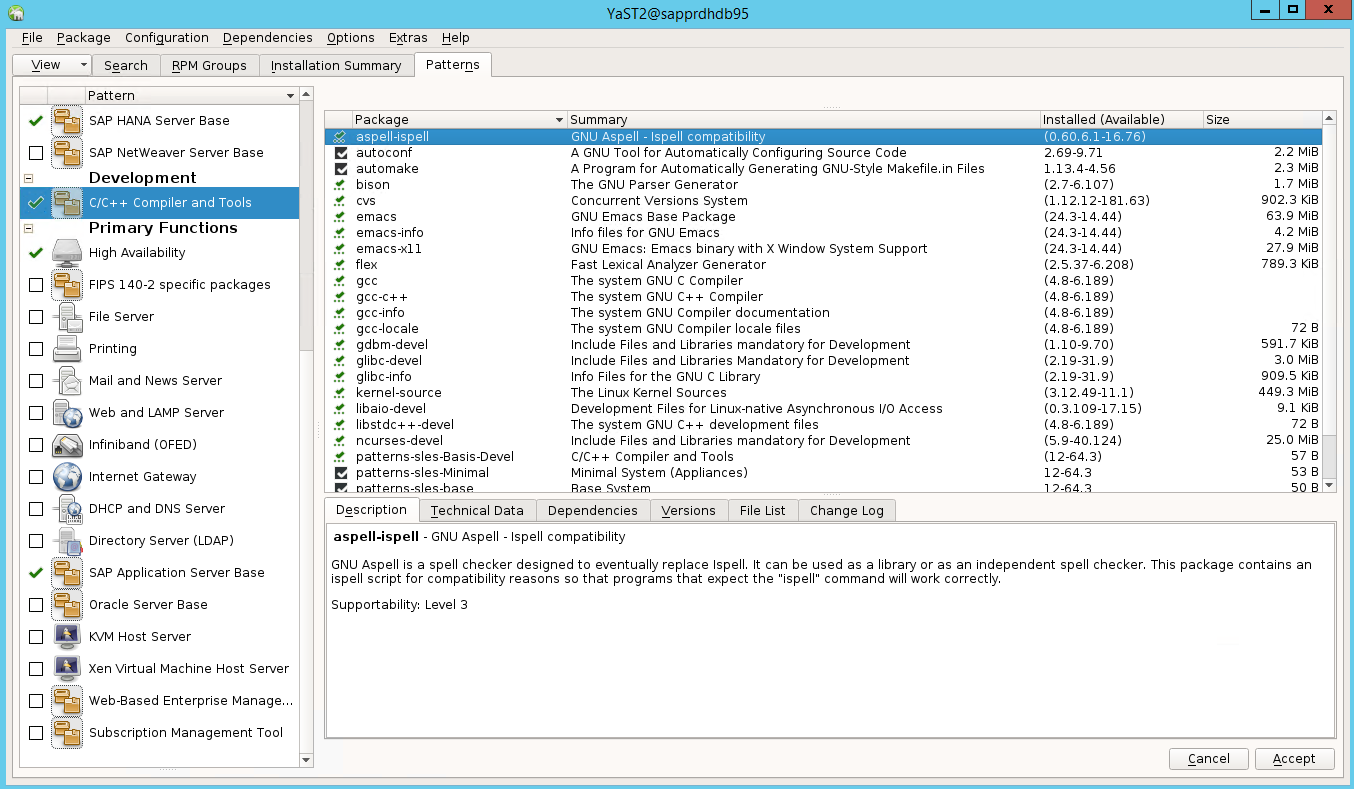
Passare a Yast2>Software>Management. Selezionare Quindi Aggiornamentoonlinesoftware>.
Selezionare i modelli per gli elementi seguenti. Selezionare Quindi Accetta.
- SAP HANA server base (Base server SAP HANA)
- Compilatore e strumenti C/C++
- Disponibilità elevata
- Base del server applicazioni SAP
Nell'elenco dei pacchetti modificati per risolvere le dipendenze selezionare Continua.
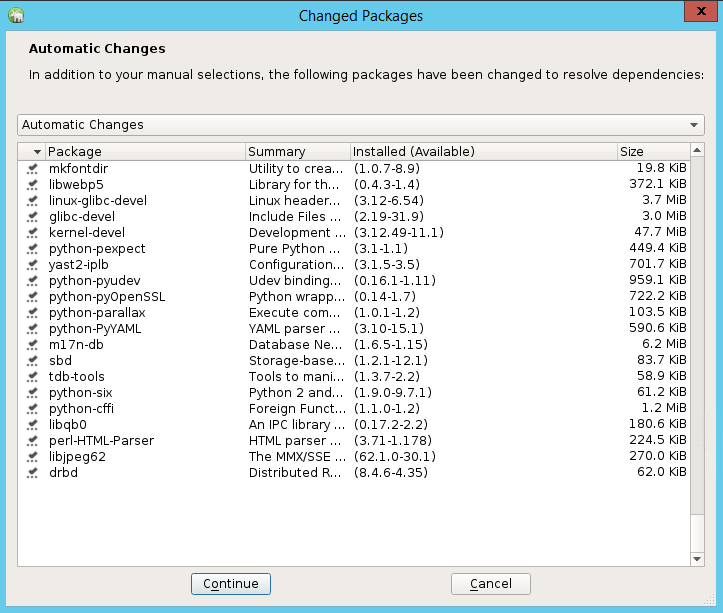
Nella pagina Esecuzione dello stato dell'installazione selezionare Avanti.
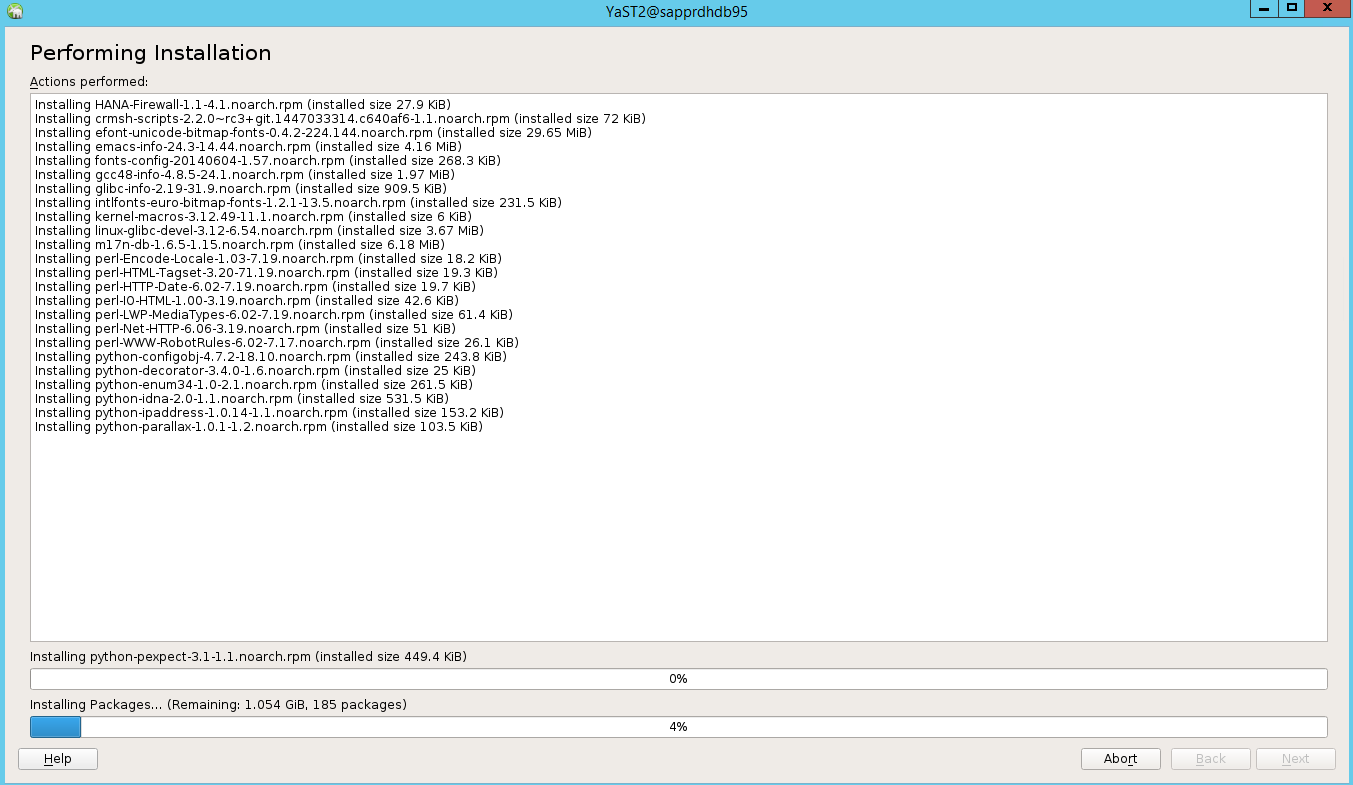
Al termine dell'installazione, viene visualizzato un report di installazione. Selezionare Fine.
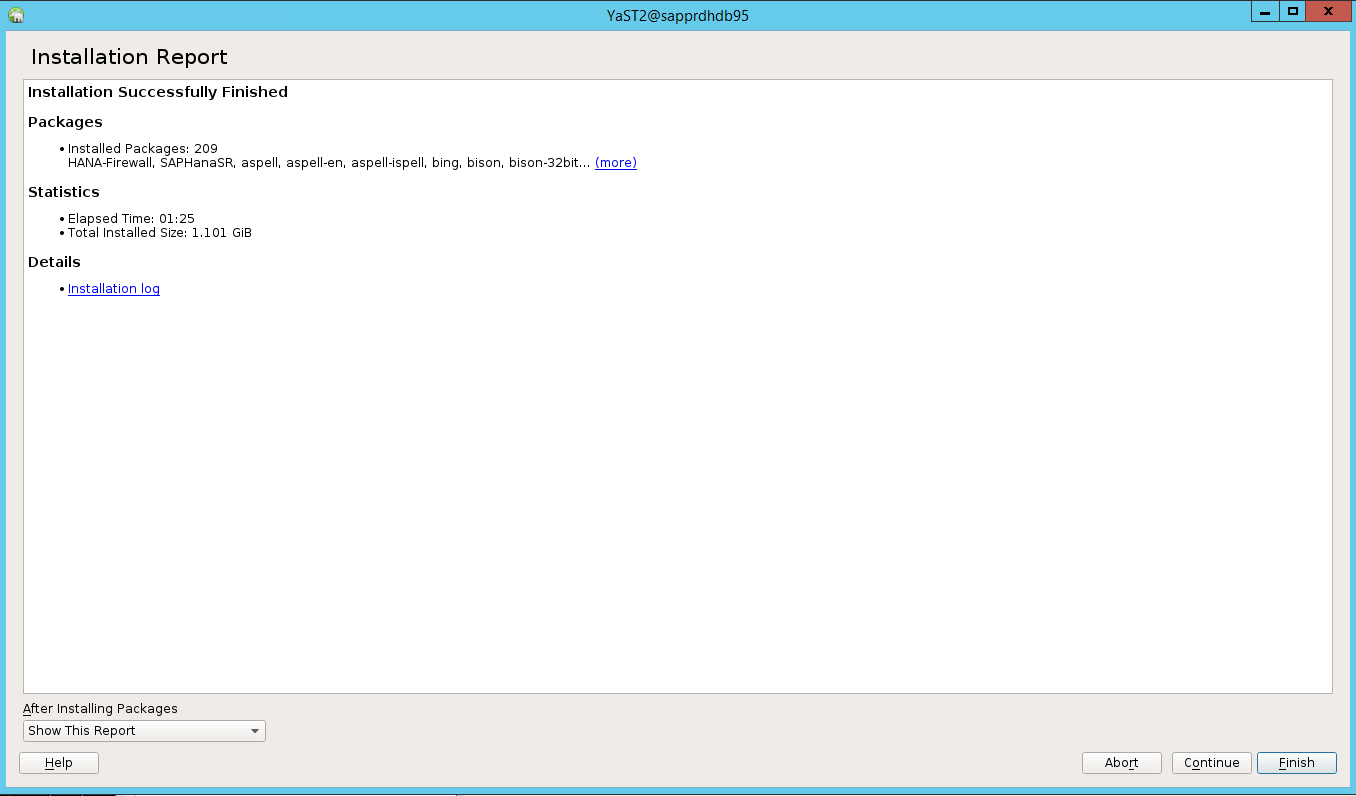
Scenario 4: l'installazione di HANA non riesce con l'errore degli assembly gcc
Se l'installazione di HANA ha esito negativo, potrebbe verificarsi l'errore seguente.
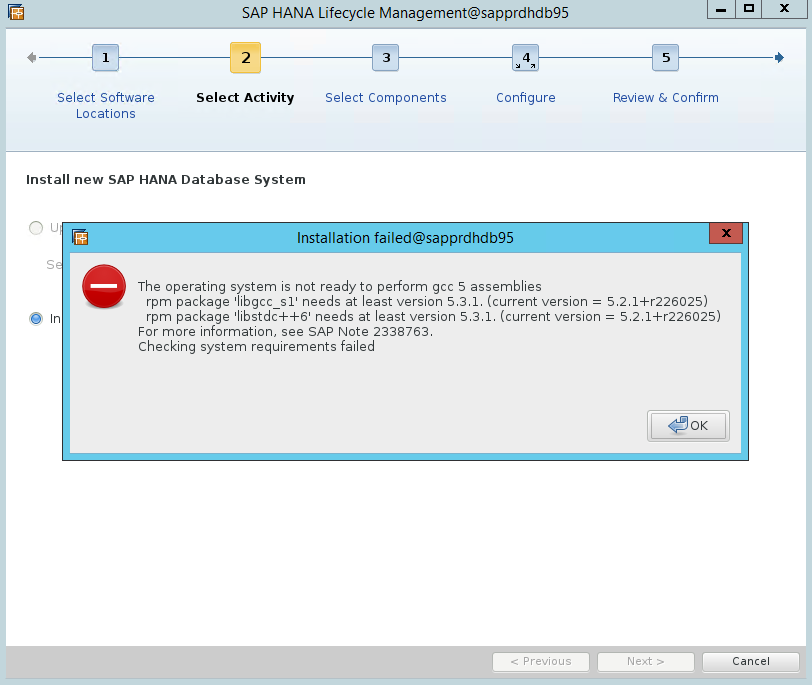
Per risolvere il problema, installare le librerie libgcc_sl e libstdc++6, come illustrato nello screenshot seguente.
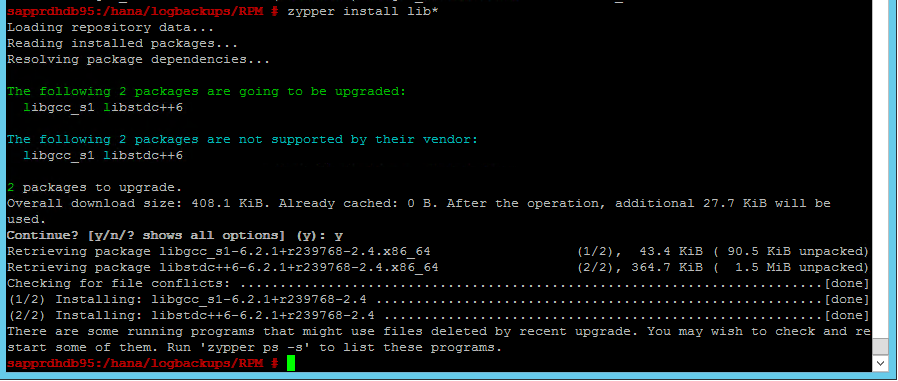
Scenario 5: Il servizio Pacemaker ha esito negativo
Le informazioni seguenti sono visualizzate se il servizio pacemaker non può iniziare.
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
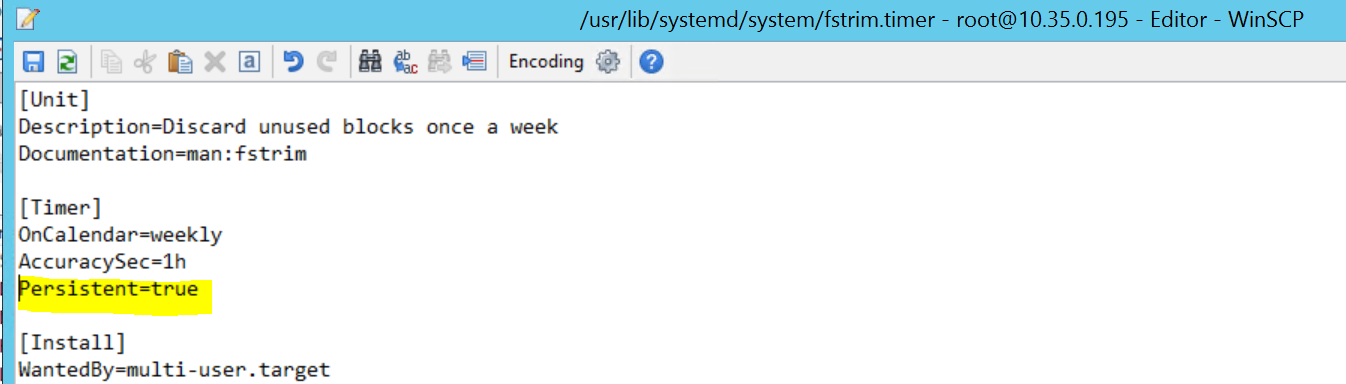
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
Per correggerlo, eliminare la riga seguente dal file /usr/lib/systemd/system/fstrim.timer:
Persistent=true
Scenario 6: Node2 non può partecipare al cluster
L'errore seguente viene visualizzato se si verifica un problema con l'aggiunta di node2 al cluster esistente tramite il comando ha-cluster-join .
ERROR: Can’t retrieve SSH keys from <Primary Node>
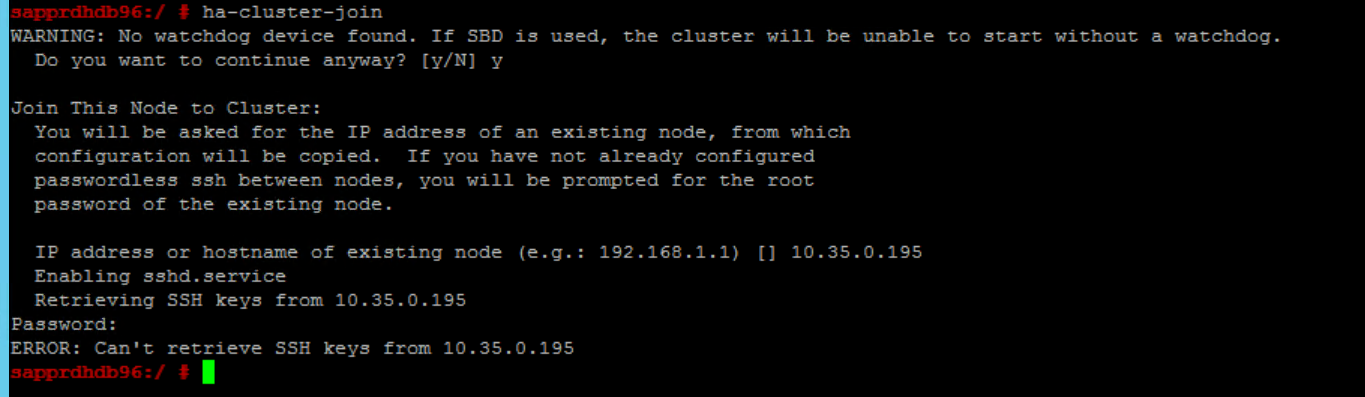
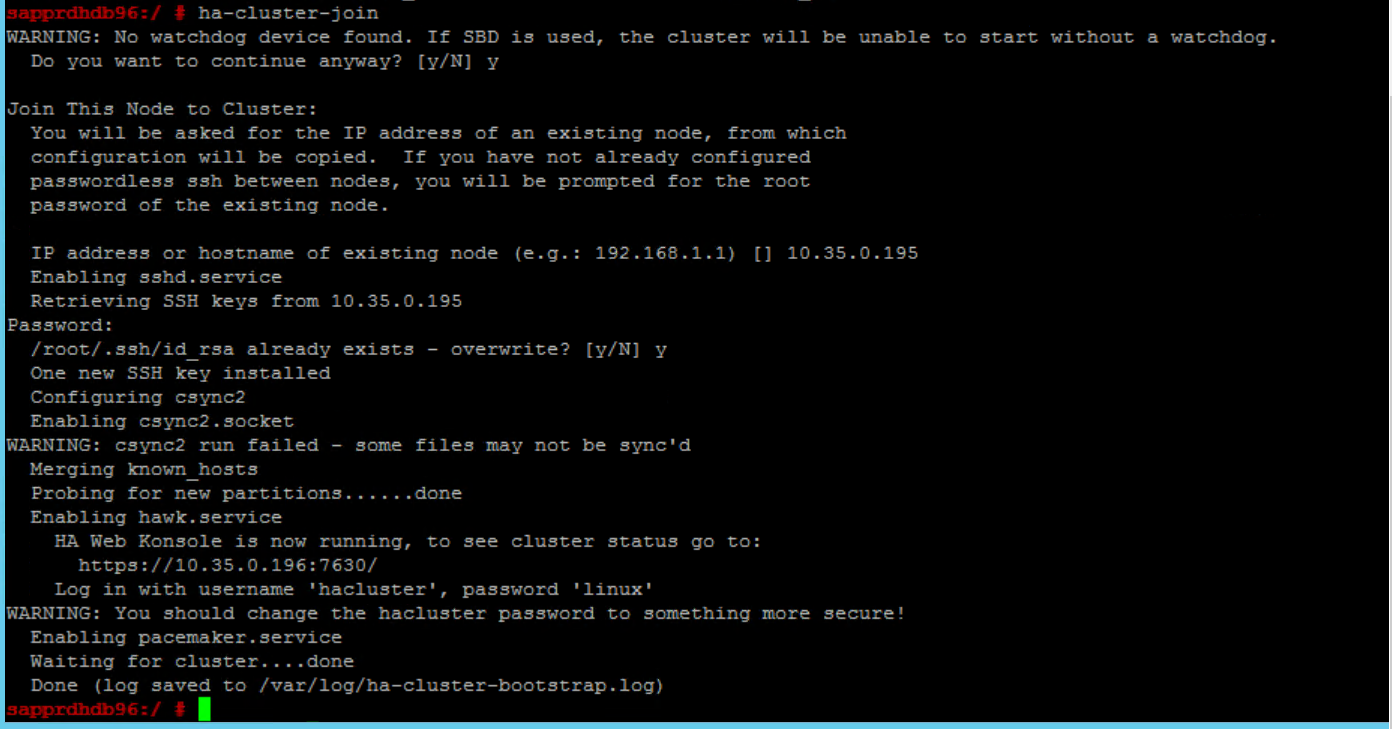
Per correggerlo:
Eseguire i comandi seguenti in entrambi i nodi.
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

Verificare che node2 venga aggiunto al cluster.
Passaggi successivi
Per altre informazioni sulla configurazione della disponibilità elevata di SUSE, vedere gli articoli seguenti:
- Scenario ottimizzato per le prestazioni di SAP HANA SR (sito Web SUSE)
- Fencing e dispositivi di fencing (sito Web SUSE)
- Prepararsi per l'uso del cluster Pacemaker per SAP HANA - Parte 1: Nozioni di base (blog SAP)
- Essere preparati per l'uso del cluster Pacemaker per SAP HANA - Parte 2: Errore di entrambi i nodi (blog SAP)
- Backup e ripristino del sistema operativo
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per