Opzioni di configurazione per ridurre al minimo la latenza di rete con le applicazioni SAP
Importante
Nel novembre 2021 sono state apportate modifiche significative al modo in cui i gruppi di posizionamento di prossimità devono essere usati con il carico di lavoro SAP nelle distribuzioni di zona.
Le applicazioni SAP basate sull'architettura SAP NetWeaver o SAP S/4HANA sono sensibili alla latenza di rete tra il livello applicazione SAP e il livello di database SAP. Questa riservatezza è il risultato della maggior parte della logica di business in esecuzione nel livello dell'applicazione. Poiché il livello dell'applicazione SAP esegue la logica di business, invia query al livello di database a una frequenza elevata, con una frequenza di migliaia o decine di migliaia al secondo. Nella maggior parte dei casi, la natura di queste query è semplice. Spesso possono essere eseguiti nel livello di database in 500 microsecondi o meno.
Il tempo impiegato nella rete per inviare tale query dal livello applicazione al livello di database e ricevere il risultato restituito ha un impatto significativo sul tempo necessario per l'esecuzione dei processi aziendali. Questa sensibilità alla latenza di rete è il motivo per cui è consigliabile ottenere una certa latenza di rete minima nei progetti di distribuzione SAP. Vedere La nota SAP #1100926 - Domande frequenti: Prestazioni di rete per indicazioni su come classificare la latenza di rete.
In molte aree di Azure il numero di data center è cresciuto. Allo stesso tempo, i clienti, in particolare per i sistemi SAP di fascia alta, usano famiglie di macchine virtuali più speciali, ad esempio la famiglia Mv2 o Mv3 e versioni successive. Questi tipi di macchine virtuali di Azure non sono sempre disponibili in ognuno dei data center che raccolgono in un'area di Azure. Questi fatti possono creare opportunità per ottimizzare la latenza di rete tra il livello dell'applicazione SAP e il livello SAP DBMS.
Azure offre diverse opzioni di distribuzione per i carichi di lavoro SAP. Per il tipo di distribuzione scelto sono disponibili opzioni per ottimizzare la latenza di rete, se necessario. Le informazioni dettagliate su ogni opzione sono descritte accuratamente nelle sezioni seguenti in questo articolo:
- Gruppi di posizionamento di prossimità
- Set di scalabilità di macchine virtuali con orchestrazione flessibile
Gruppi di posizionamento di prossimità
I gruppi di posizionamento di prossimità consentono il raggruppamento di diversi tipi di VM in una singola colonna vertebrale di rete, garantendo una latenza di rete bassa ottimale tra di esse. Quando la prima macchina virtuale viene distribuita in un gruppo di posizionamento di prossimità, tale macchina virtuale viene associata a una colonna dorsale di rete specifica. Come tutte le altre macchine virtuali che verranno distribuite nello stesso gruppo di posizionamento di prossimità, tali macchine virtuali vengono raggruppate nella stessa colonna vertebrale di rete. Come interessante come questa prospettiva suona, l'uso del costrutto introduce anche alcune restrizioni e insidie:
- Non è possibile presupporre che tutti i tipi di vm di Azure siano disponibili in ogni data center di Azure o in ogni colonna vertebrale di rete. Di conseguenza, la combinazione di diversi tipi di vm all'interno di un gruppo di posizionamento di prossimità può essere notevolmente limitata. Queste restrizioni si verificano perché l'hardware host necessario per eseguire un determinato tipo di macchina virtuale potrebbe non essere presente nel data center o nella colonna vertebrale di rete a cui è stato assegnato il gruppo di posizionamento di prossimità
- Quando si ridimensionano parti delle macchine virtuali che si trovano all'interno di un gruppo di posizionamento di prossimità, non è possibile presupporre automaticamente che in tutti i casi il nuovo tipo di macchina virtuale sia disponibile nello stesso data center o nella colonna vertebrale di rete a cui è stato assegnato il gruppo di posizionamento di prossimità
- Poiché Azure rimuove l'hardware, potrebbe forzare determinate macchine virtuali di un gruppo di posizionamento di prossimità in un altro data center di Azure o in un'altra colonna dorsale di rete. Per informazioni dettagliate su questo caso, leggere il documento Gruppi di posizionamento di prossimità
Importante
In seguito alle potenziali restrizioni, i gruppi di posizionamento di prossimità devono essere usati solo:
- Quando necessario in determinati scenari (vedere più avanti)
- Quando la latenza di rete tra il livello dell'applicazione e il livello DBMS è troppo elevata e influisce sul carico di lavoro
- Solo in caso di granularità di un singolo sistema SAP e non di un intero panorama di sistema o di un panorama SAP completo
- In modo da mantenere i diversi tipi di vm e il numero di macchine virtuali all'interno di un gruppo di posizionamento di prossimità a un minimo
Gli scenari in cui è possibile usare i gruppi di posizionamento di prossimità per ottimizzare la latenza di rete:
- Si vogliono distribuire le risorse critiche del carico di lavoro SAP in zone di disponibilità diverse e, d'altra parte, è necessario che le macchine virtuali del livello applicazione vengano distribuite in domini di errore diversi usando i set di disponibilità in ognuna delle zone. In questo caso, come descritto più avanti nel documento, i gruppi di posizionamento di prossimità sono l'associazione necessaria.
- Si distribuisce il carico di lavoro SAP con i set di disponibilità. Dove il livello di database SAP, il livello applicazione SAP e le macchine virtuali ASCS/SCS vengono raggruppati in tre set di disponibilità diversi. In questo caso, si vuole assicurarsi che i set di disponibilità non vengano distribuiti nell'area di Azure completa perché ciò potrebbe dipendere dall'area di Azure, comportando una latenza di rete che potrebbe influire negativamente sul carico di lavoro SAP.
- I gruppi di posizionamento di prossimità consentono di raggruppare le macchine virtuali per ottenere la latenza di rete più bassa possibile tra i servizi ospitati nelle macchine virtuali. Ad esempio, la latenza all'interno di una zona di disponibilità da sola non soddisfa i requisiti dell'applicazione.
Per quanto riguarda lo scenario di distribuzione n. 2, in molte aree, in particolare le aree senza zone di disponibilità e la maggior parte delle aree con zone di disponibilità, la latenza di rete indipendente dalla posizione in cui le macchine virtuali sono accettabili. Anche se alcune aree di Azure non possono offrire un'esperienza sufficientemente valida senza collocare i tre diversi set di disponibilità senza l'uso dei gruppi di posizionamento di prossimità.
Che cosa sono i gruppi di posizionamento di prossimità?
Un gruppo di posizionamento di prossimità di Azure è un costrutto logico. Quando viene definito un gruppo di posizionamento di prossimità, viene associato a un'area di Azure e a un gruppo di risorse di Azure. Quando le macchine virtuali vengono distribuite, viene fatto riferimento a un gruppo di posizionamento di prossimità tramite:
- La prima macchina virtuale di Azure distribuita in una colonna vertebrale di rete con molte unità di calcolo di Azure e bassa latenza di rete. Tale colonna vertebrale di rete corrisponde spesso a un singolo data center di Azure. È possibile considerare la prima macchina virtuale come una "macchina virtuale con ambito" distribuita in un'unità di scala di calcolo basata su algoritmi di allocazione di Azure che alla fine vengono combinati con i parametri di distribuzione.
- Tutte le macchine virtuali successive distribuite che fanno riferimento al gruppo di posizionamento di prossimità verranno distribuite nella stessa colonna vertebrale di rete della prima macchina virtuale.
Nota
Se non è stato distribuito alcun hardware host che potrebbe eseguire un tipo di macchina virtuale specifico nella colonna vertebrale di rete in cui è stata posizionata la prima macchina virtuale, la distribuzione del tipo di macchina virtuale richiesto non avrà esito positivo. Verrà visualizzato un messaggio di errore di allocazione che indica che la macchina virtuale non può essere supportata all'interno del perimetro del gruppo di posizionamento di prossimità.
Per ridurre il rischio di quanto sopra, è consigliabile usare l'opzione per la finalità durante la creazione del gruppo di posizionamento di prossimità. L'opzione di finalità consente di elencare i tipi di macchina virtuale che si intende includere nel gruppo di posizionamento di prossimità. Questo elenco di tipi di vm verrà visualizzato per trovare il data center migliore che ospita questi tipi di vm. Se viene trovato un data center di questo tipo, il PPG verrà creato ed è ambito per il data center che soddisfa i requisiti dello SKU della macchina virtuale. Se non è stato trovato un data center di questo tipo, la creazione del gruppo di posizionamento di prossimità avrà esito negativo. Per altre informazioni, vedere la documentazione PPG - Usare la finalità per specificare le dimensioni delle macchine virtuali. Tenere presente che le situazioni di capacità effettive non vengono prese in considerazione nei controlli attivati dall'opzione di finalità. Di conseguenza, potrebbero esserci ancora errori di allocazione radicati nella capacità insufficiente disponibile.
A un singolo gruppo di risorse di Azure possono essere assegnati più gruppi di posizionamento di prossimità. Tuttavia, un gruppo di posizionamento di prossimità può essere assegnato a un solo gruppo di risorse di Azure.
Per altre informazioni ed esempi di distribuzione di gruppi di posizionamento di prossimità, vedere la documentazione disponibile.
Gruppi di posizionamento di prossimità con distribuzioni di zona
È importante fornire una latenza di rete ragionevolmente bassa tra il livello applicazione SAP e il livello DBMS. Nella maggior parte dei casi una distribuzione a livello di zona soddisfa questo requisito. Per un set limitato di scenari, una distribuzione di zona da sola potrebbe non soddisfare i requisiti di latenza dell'applicazione. Tali situazioni richiedono il posizionamento delle macchine virtuali il più vicino possibile e consentono una latenza di rete ragionevolmente bassa, è possibile definire un gruppo di posizionamento di prossimità di Azure per un sistema SAP di questo tipo.
Evitare di creare un bundle di diversi sistemi di produzione SAP o non di produzione in un singolo gruppo di posizionamento di prossimità. Evitare bundle di sistemi SAP perché più sistemi si raggruppano in un gruppo di posizionamento di prossimità, maggiore è la probabilità:
- È necessario un tipo di macchina virtuale non disponibile nella colonna vertebrale di rete a cui è stato assegnato il gruppo di posizionamento di prossimità.
- Che queste risorse di macchine virtuali non di tipo mainstream, ad esempio le macchine virtuali serie M, potrebbero essere eventualmente non riempite quando è necessario espandere il numero di macchine virtuali in un gruppo di posizionamento di prossimità nel corso del tempo.
In base a molti miglioramenti distribuiti da Microsoft nelle aree di Azure per ridurre la latenza di rete all'interno di una zona di disponibilità di Azure, le linee guida per la distribuzione quando si usano gruppi di posizionamento di prossimità per le distribuzioni di zona sono simili alle seguenti:
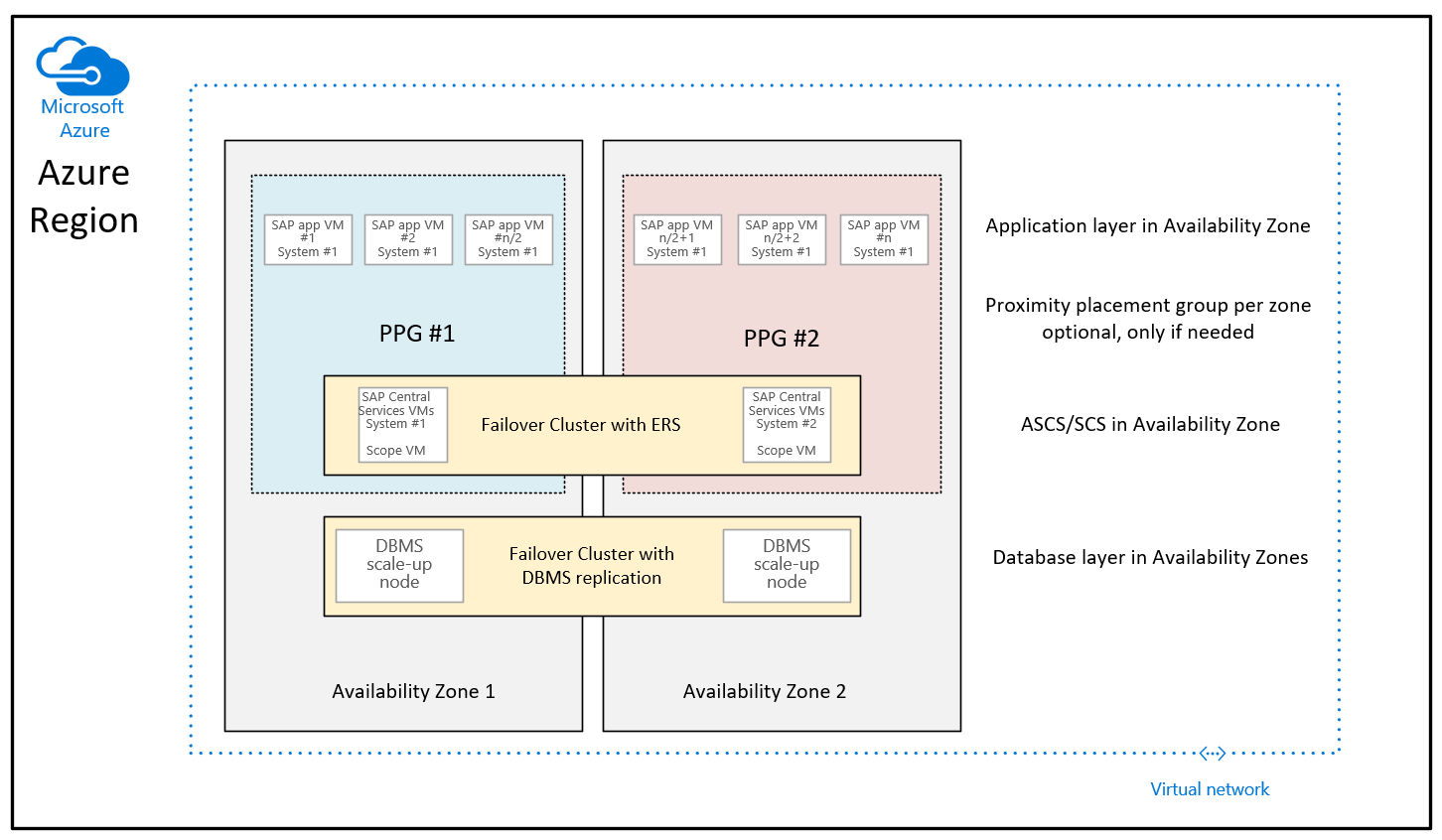
La differenza rispetto alla raccomandazione data finora è che le macchine virtuali di database nelle due zone non fanno più parte dei gruppi di posizionamento di prossimità. I gruppi di posizionamento di prossimità per zona hanno ora come ambito la distribuzione della macchina virtuale che esegue le istanze di SAP ASCS/SCS. Ciò significa anche che per le aree in cui le zone di disponibilità vengono raccolte da più data center, l'istanza ASCS/SCS e il livello applicazione potrebbe essere eseguito in una colonna vertebrale di rete e le macchine virtuali del database potrebbero essere eseguite in un'altra colonna vertebrale di rete. Anche se con i miglioramenti apportati alla rete, la latenza di rete tra il livello dell'applicazione SAP e il livello DBMS dovrebbe comunque essere sufficiente per ottenere prestazioni e velocità effettiva sufficienti. Il vantaggio di questa nuova configurazione è che è possibile ridimensionare le macchine virtuali o passare a nuovi tipi di vm con il livello DBMS o/e il livello applicazione del sistema SAP.
Per il caso speciale dell'uso di Azure NetApp Files per l'ambiente DBMS e delle funzionalità correlate ad Azure NetApp Files del gruppo di volumi di applicazioni di Azure NetApp Files per SAP HANA e la necessità di gruppi di posizionamento di prossimità, vedere il documento Volumi NFS v4.1 in Azure NetApp Files per SAP HANA.
Gruppi di posizionamento di prossimità con distribuzioni del set di disponibilità
In questo caso, lo scopo è usare gruppi di posizionamento di prossimità per collocare le macchine virtuali distribuite tramite set di disponibilità diversi. In questo scenario di utilizzo non si usa una distribuzione controllata in diverse zone di disponibilità in un'area. Si vuole invece distribuire il sistema SAP usando i set di disponibilità. Di conseguenza, è disponibile almeno un set di disponibilità per le macchine virtuali DBMS, le macchine virtuali ASCS/SCS e le macchine virtuali del livello applicazione. Poiché non è possibile specificare in fase di distribuzione di una macchina virtuale un set di disponibilità E una zona di disponibilità, non è possibile controllare dove verranno allocate le macchine virtuali nei diversi set di disponibilità. Ciò potrebbe comportare alcune aree di Azure che la latenza di rete tra macchine virtuali diverse potrebbe comunque essere troppo elevata per offrire un'esperienza di prestazioni sufficientemente buona. L'architettura risultante sarà quindi simile alla seguente:
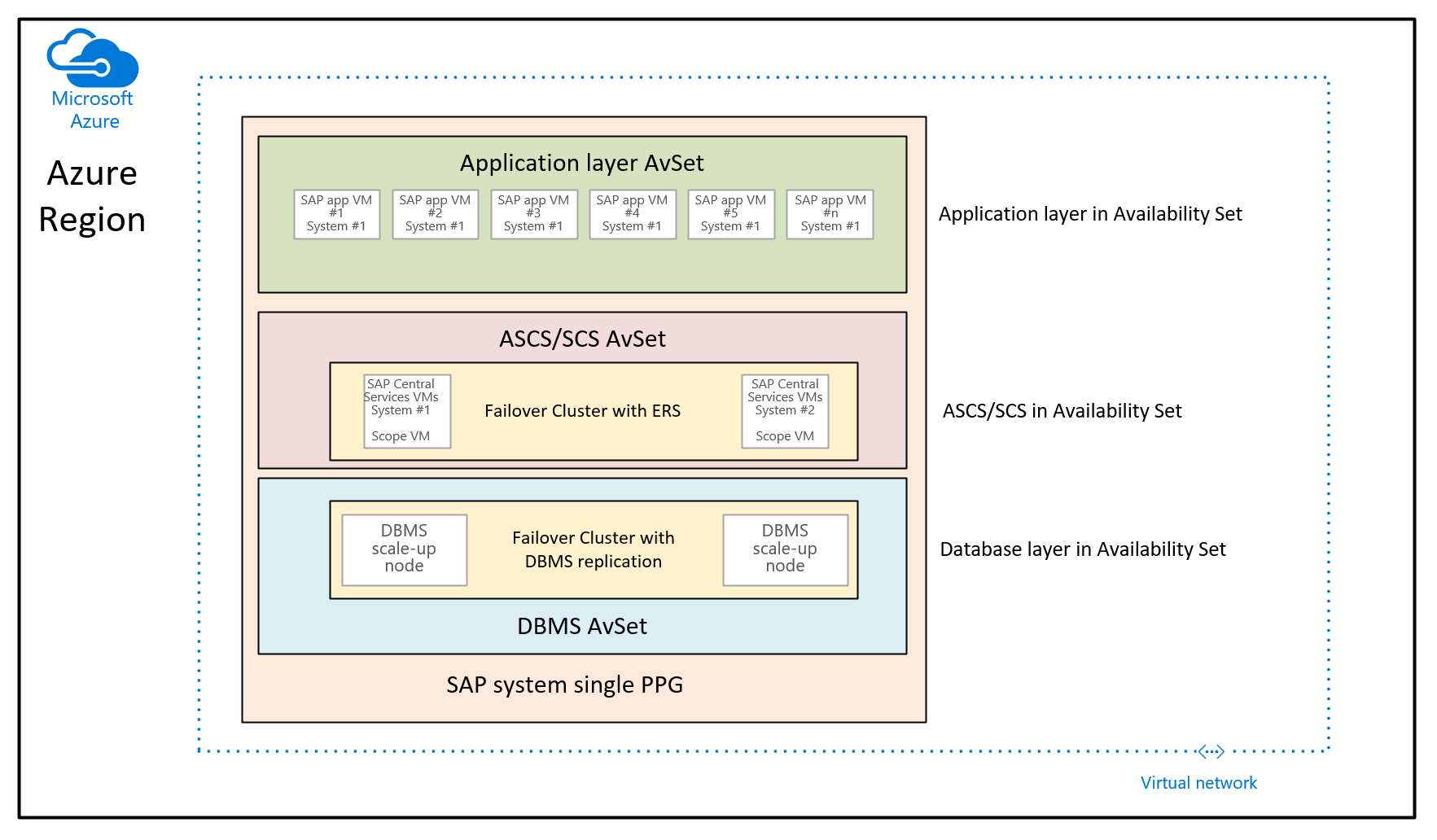
In questo grafico viene assegnato un singolo gruppo di posizionamento di prossimità a un singolo sistema SAP. Questo PPG viene assegnato ai tre set di disponibilità. Il gruppo di posizionamento di prossimità ha quindi come ambito la distribuzione delle prime macchine virtuali del livello di database nel set di disponibilità DBMS. Questa raccomandazione di architettura colloca tutte le macchine virtuali nella stessa colonna vertebrale di rete. Introduce le restrizioni indicate in precedenza in questo articolo. Pertanto, l'architettura del gruppo di posizionamento di prossimità deve essere usata in modo sparse.
Combinare set di disponibilità e zone di disponibilità con gruppi di posizionamento di prossimità
Uno dei problemi relativi all'uso delle zone di disponibilità per le distribuzioni di sistema SAP è che non è possibile distribuire il livello applicazione SAP usando i set di disponibilità all'interno della zona di disponibilità specifica. Si vuole distribuire il livello applicazione SAP nelle stesse zone delle macchine virtuali SAP ASCS/SCS. Fare riferimento a una zona di disponibilità e a un set di disponibilità quando si distribuisce una singola macchina virtuale finora non è possibile. Ma solo distribuendo una macchina virtuale che indica una zona di disponibilità, si perde la possibilità di assicurarsi che le macchine virtuali a livello di applicazione siano distribuite in domini di aggiornamento e di errore diversi.
Usando i gruppi di posizionamento di prossimità, è possibile ignorare questa restrizione. Ecco la sequenza di distribuzione:
- Creare un gruppo di posizionamento di prossimità.
- Distribuire la macchina virtuale di ancoraggio, consigliata come macchina virtuale ASCS/SCS, facendo riferimento a una zona di disponibilità.
- Creare un set di disponibilità che faccia riferimento al gruppo di posizionamento di prossimità di Azure. Vedere il comando più avanti in questo articolo.
- Distribuire le macchine virtuali a livello di applicazione facendo riferimento al set di disponibilità e al gruppo di posizionamento di prossimità.
Importante
È importante comprendere che non è garantito che i dischi delle macchine virtuali a livello di applicazione vengano allocati nella stessa zona di disponibilità delle macchine virtuali vengono indirizzati all'uso del gruppo di posizionamento di prossimità. Il risultato della distribuzione illustrata nei passaggi successivi potrebbe essere che le macchine virtuali vengono allocate nella stessa colonna vertebrale di rete e con la stessa zona di disponibilità della macchina virtuale di ancoraggio. Tuttavia, i dischi respctive (disco rigido virtuale di base e dischi di archiviazione a blocchi di Azure montati) potrebbero non essere allocati nella stessa colonna dorsale di rete o anche nella stessa zona di disponibilità. I dischi di tali macchine virtuali possono invece essere allocati in uno qualsiasi dei data center dell'area specifica. Anche se i dischi della macchina virtuale di ancoraggio distribuiti definendo una zona verranno distribuiti nella stessa zona in cui è stata distribuita la macchina virtuale.
Anziché distribuire la prima macchina virtuale come illustrato nella sezione precedente, si fa riferimento a una zona di disponibilità e al gruppo di posizionamento di prossimità quando si distribuisce la macchina virtuale:
New-AzVm -ResourceGroupName "ppgexercise" -Name "centralserviceszone1" -Location "westus2" -OpenPorts 80,3389 -Zone "1" -ProximityPlacementGroup "collocate" -Size "Standard_E8s_v4"
Una corretta distribuzione di questa macchina virtuale ospiterà l'istanza ASCS/SCS del sistema SAP in un'unica zona di disponibilità. In questo caso, la macchina virtuale e il disco rigido virtuale di base della macchina virtuale e i dischi di archiviazione a blocchi di Azure potenzialmente montati vengono allocati all'interno della stessa zona di disponibilità. L'ambito del gruppo di posizionamento di prossimità è fisso a una delle spine di rete nella zona di disponibilità definita.
Nel passaggio successivo è necessario creare i set di disponibilità da usare per il livello applicazione del sistema SAP.
Definire e creare il gruppo di posizionamento di prossimità. Il comando per la creazione del set di disponibilità richiede un riferimento aggiuntivo all'ID del gruppo di posizionamento di prossimità (non al nome). È possibile ottenere l'ID del gruppo di posizionamento di prossimità usando questo comando:
Get-AzProximityPlacementGroup -ResourceGroupName "ppgexercise" -Name "collocate"
Quando si crea il set di disponibilità, è necessario prendere in considerazione parametri aggiuntivi quando si usano dischi gestiti (impostazione predefinita, se non diversamente specificato) e gruppi di posizionamento di prossimità:
New-AzAvailabilitySet -ResourceGroupName "ppgexercise" -Name "ppgavset" -Location "westus2" -ProximityPlacementGroupId "/subscriptions/my very long ppg id string" -sku "aligned" -PlatformUpdateDomainCount 3 -PlatformFaultDomainCount 2
Idealmente, è consigliabile usare tre domini di errore. Tuttavia, il numero di domini di errore supportati può variare da un'area all'altra. In questo caso, il numero massimo di domini di errore possibili per le aree specifiche è due. Per distribuire le macchine virtuali a livello di applicazione, è necessario aggiungere un riferimento al nome del set di disponibilità e al nome del gruppo di posizionamento di prossimità, come illustrato di seguito:
New-AzVm -ResourceGroupName "ppgexercise" -Name "appinstance1" -Location "westus2" -OpenPorts 80,3389 -AvailabilitySetName "myppgavset" -ProximityPlacementGroup "collocate" -Size "Standard_E16s_v4"
Nota
I dischi delle macchine virtuali distribuite nel set di disponibilità precedente non devono essere allocati nella stessa zona di disponibilità della macchina virtuale. Anche se si è ottenuto che le macchine virtuali a livello di applicazione vengono distribuite in domini di errore diversi nella stessa colonna dorsale di rete della macchina virtuale di ancoraggio, i dischi, anche se allocati in domini di errore diversi possono essere allocati in posizioni diverse in un ambito a livello di area.
Il risultato di questa distribuzione è:
- Un servizio centrale per il sistema SAP che si trova in una o più zone di disponibilità specifiche.
- Livello dell'applicazione SAP che si trova attraverso i set di disponibilità nella stessa colonna vertebrale di rete della VM o delle macchine virtuali SAP Central Services (ASCS/SCS).
Nota
Poiché si distribuiscono macchine virtuali DBMS e ASCS/SCS in una zona e le seconde MACCHINE virtuali DBMS e ASCS/SCS in un'altra zona per creare configurazioni a disponibilità elevata, è necessario un gruppo di posizionamento di prossimità diverso per ognuna delle zone. Lo stesso vale per qualsiasi set di disponibilità usato.
Modificare le configurazioni del gruppo di posizionamento di prossimità di un sistema esistente
Se sono stati implementati gruppi di posizionamento di prossimità a partire dalle raccomandazioni fornite finora e si vuole adattare alla nuova configurazione, è possibile farlo con i metodi descritti in questi articoli:
- Distribuire macchine virtuali in gruppi di posizionamento di prossimità usando l'interfaccia della riga di comando di Azure.
- Distribuire macchine virtuali in gruppi di posizionamento di prossimità usando PowerShell.
È anche possibile usare questi comandi per i casi in cui si ricevono errori di allocazione nei casi in cui non è possibile passare a un nuovo tipo di macchina virtuale con una macchina virtuale esistente nel gruppo di posizionamento di prossimità.
Set di scalabilità di macchine virtuali con orchestrazione flessibile
Per evitare le limitazioni associate al gruppo di posizionamento di prossimità, è consigliabile distribuire il carico di lavoro SAP tra zone di disponibilità usando un set di scalabilità flessibile con FD=1. Questa strategia di distribuzione garantisce che le macchine virtuali distribuite in ogni zona non siano limitate a un singolo data center o colonna dorsale di rete e che tutti i componenti di sistema SAP, ad esempio database, ASCS/ERS e il livello applicazione siano inclusi nell'ambito di una zona. Con tutti i componenti di sistema SAP con ambito a livello di zona, la latenza di rete tra componenti diversi di un singolo sistema SAP deve essere sufficiente per garantire prestazioni e velocità effettiva soddisfacenti. Il vantaggio principale di questa nuova opzione di distribuzione con set di scalabilità flessibile con FD=1 è che offre maggiore flessibilità nel ridimensionare le macchine virtuali o passare a nuovi tipi di vm per tutti i livelli del sistema SAP. Inoltre, il set di scalabilità alloca le macchine virtuali in più domini di errore all'interno di una singola zona, ideale per l'esecuzione di più macchine virtuali del livello applicazione in ogni zona. Per altre informazioni, vedere il documento set di scalabilità di macchine virtuali per il carico di lavoro SAP.
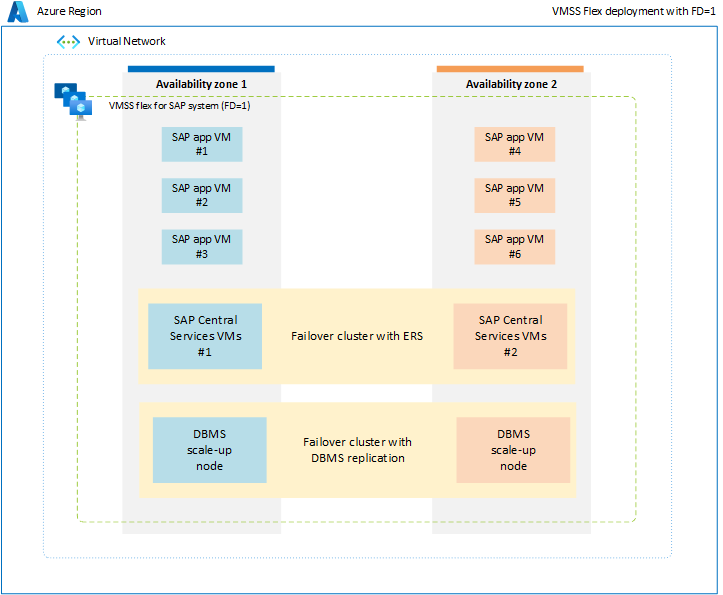
In un ambiente non di produzione o non a disponibilità elevata è possibile distribuire tutti i componenti di sistema SAP, inclusi il database, ASCS e il livello applicazione, all'interno di una singola zona usando un set di scalabilità flessibile con FD=1.
Opzioni di distribuzione consigliate in precedenza
Questa sezione include informazioni dettagliate sulle opzioni di distribuzione consigliate in precedenza per ottimizzare la latenza di rete per SAP. Con le nuove funzionalità e la crescita di Azure nel tempo, i dettagli all'interno di questa sezione devono essere applicati solo in rari casi.
Gruppi di posizionamento di prossimità per l'intero sistema SAP con distribuzioni di zona
L'utilizzo del gruppo di posizionamento di prossimità consigliato finora è simile a questo grafico.

Si crea un gruppo di posizionamento di prossimità (PPG) in ognuna delle due zone di disponibilità in cui è stato distribuito il sistema SAP. Tutte le macchine virtuali di una zona specifica fanno parte del singolo gruppo di posizionamento di prossimità di tale zona specifica. Si inizia in ogni zona con la distribuzione della macchina virtuale DBMS per definire l'ambito del PPG e quindi distribuire la macchina virtuale ASCS nella stessa zona e ppg. In un terzo passaggio si crea un set di disponibilità di Azure, si assegna il set di disponibilità al ppg con ambito e si distribuisce il livello applicazione SAP. Il vantaggio di questa configurazione era che tutti i componenti sono ben allineati sotto la stessa colonna vertebrale di rete. Il grande svantaggio è che la flessibilità nel ridimensionamento delle macchine virtuali può essere limitata.
In base a molti miglioramenti distribuiti da Microsoft nelle aree di Azure per ridurre la latenza di rete all'interno di una zona di disponibilità di Azure, sono disponibili le linee guida per la distribuzione corrente per le distribuzioni di zona in questo articolo.
Gruppi di posizionamento di prossimità e istanze Large di HANA
Se alcuni sistemi SAP si basano su istanze Large di HANA per il livello di database, è possibile riscontrare miglioramenti significativi nella latenza di rete tra l'unità istanze Large di HANA e le macchine virtuali di Azure quando si usano unità di istanze Large di HANA distribuite nelle righe o negli indicatori della revisione 4. Un miglioramento è rappresentato dal fatto che le unità di istanze Large di HANA, distribuite con un gruppo di posizionamento di prossimità. È possibile usare il gruppo di posizionamento di prossimità per distribuire le macchine virtuali a livello di applicazione. Di conseguenza, queste macchine virtuali verranno distribuite nello stesso data center che ospita l'unità istanze Large di HANA.
Per determinare se l'unità istanze Large di HANA viene distribuita in un timbro o una riga della revisione 4, vedere l'articolo Controllo delle istanze Large di Azure HANA tramite portale di Azure. Nella panoramica degli attributi dell'unità istanze Large di HANA è anche possibile determinare il nome del gruppo di posizionamento di prossimità perché è stato creato quando è stata distribuita l'unità istanze Large di HANA. Il nome visualizzato nella panoramica degli attributi è il nome del gruppo di posizionamento di prossimità in cui distribuire le macchine virtuali del livello applicazione.
Rispetto ai sistemi SAP che usano solo macchine virtuali di Azure, quando si usano istanze Large di HANA, si ha meno flessibilità per decidere quanti gruppi di risorse di Azure usare. Tutte le unità di istanze Large di HANA di un tenant di istanze Large di HANA sono raggruppate in un singolo gruppo di risorse, come descritto in questo articolo. A meno che non si distribuisca in tenant diversi per separare, ad esempio, sistemi di produzione e non di produzione o altri sistemi, tutte le unità di istanze Large di HANA verranno distribuite in un tenant di istanze Large di HANA. Questo tenant ha una relazione uno-a-uno con un gruppo di risorse. Tuttavia, verrà definito un gruppo di posizionamento di prossimità separato per ognuna delle singole unità.
Di conseguenza, le relazioni tra i gruppi di risorse di Azure e i gruppi di posizionamento di prossimità per un singolo tenant saranno come illustrato di seguito:

Passaggi successivi
Vedere la documentazione:
- Carichi di lavoro SAP in Azure: elenco di controllo per la pianificazione e la distribuzione
- Distribuire macchine virtuali in gruppi di posizionamento di prossimità usando l'interfaccia della riga di comando di Azure
- Distribuire macchine virtuali in gruppi di posizionamento di prossimità usando PowerShell
- Considerazioni sulla distribuzione DBMS di macchine virtuali di Azure per un carico di lavoro SAP