Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Per stabilire la disponibilità elevata in una distribuzione SAP HANA locale, è possibile usare la replica di sistema SAP HANA oppure l'archiviazione condivisa.
Attualmente, in Macchine virtuali di Azure la replica di sistema SAP HANA in Azure è l'unica funzione per la disponibilità elevata supportata.
La replica di sistema SAP HANA è costituita da un nodo primario e da almeno un nodo secondario. Le modifiche ai dati nel nodo primario vengono replicate nel nodo secondario in modo sincrono o asincrono.
Questo articolo descrive come distribuire e configurare le macchine virtuali, installare il framework del cluster, nonché installare e configurare la replica di sistema SAP HANA.
Prima di iniziare, leggere le note e i documenti SAP seguenti:
- Nota SAP 1928533. La nota include:
- Elenco delle dimensioni delle macchine virtuali di Azure supportate per la distribuzione di software SAP.
- Informazioni importanti sulla capacità per le dimensioni delle macchine virtuali di Azure.
- Software SAP, sistemi operativi e combinazioni di database supportati.
- Versioni del kernel SAP richieste per Windows e Linux in Microsoft Azure.
- Nota SAP 2015553, che elenca i prerequisiti per le distribuzioni di software SAP supportate da SAP in Azure.
- La nota SAP 2205917 ha consigliato le impostazioni del sistema operativo per SUSE Linux Enterprise Server 12 (SLES 12) per le applicazioni SAP.
- La nota SAP 2684254 ha consigliato le impostazioni del sistema operativo per SUSE Linux Enterprise Server 15 (SLES 15) per le applicazioni SAP.
- La nota SAP 2235581 ha sistemi operativi supportati da SAP HANA
- La nota SAP 2178632 contiene informazioni dettagliate su tutte le metriche di monitoraggio segnalate per SAP in Azure.
- La nota SAP 2191498 contiene la versione dell'agente host SAP per Linux necessaria in Azure.
- La nota SAP 2243692 contiene informazioni sulle licenze SAP per Linux in Azure.
- La nota SAP 1984787 contiene informazioni generali su SUSE Linux Enterprise Server 12.
- La nota SAP 1999351 contiene altre informazioni sulla risoluzione dei problemi per l'estensione di monitoraggio avanzato di Azure per SAP.
- La nota SAP 401162 contiene informazioni su come evitare errori "indirizzo già in uso" quando si configura la replica di sistema HANA.
- WIKI di supporto della community SAP, che contiene tutte le note SAP necessarie per Linux.
- Piattaforme IaaS certificate per SAP HANA.
- Guida alla pianificazione e all'implementazione di macchine virtuali di Azure per SAP in Linux.
- Guida Distribuzione di Macchine virtuali di Azure per SAP in Linux.
- Guida Distribuzione di DBMS in macchine virtuali di Azure per SAP in Linux.
-
Guide alle procedure consigliate per SUSE Linux Enterprise Server per applicazioni SAP 15 e guide alle procedure consigliate per SUSE Linux Enterprise Server per applicazioni SAP 12:
- Configurazione di un'infrastruttura ottimizzata per le prestazioni per la replica di sistema SAP HANA (SLES per applicazioni SAP). La guida contiene tutte le informazioni necessarie per configurare la replica di sistema SAP HANA per lo sviluppo locale. Usare la guida per le indicazioni di base.
- Configurazione di un'infrastruttura ottimizzata per i costi per la replica di sistema SAP HANA (SLES per applicazioni SAP).
Pianificare la disponibilità elevata per SAP HANA
Per ottenere la disponibilità elevata, installare SAP HANA in due macchine virtuali. I dati vengono replicati tramite la replica di sistema HANA.
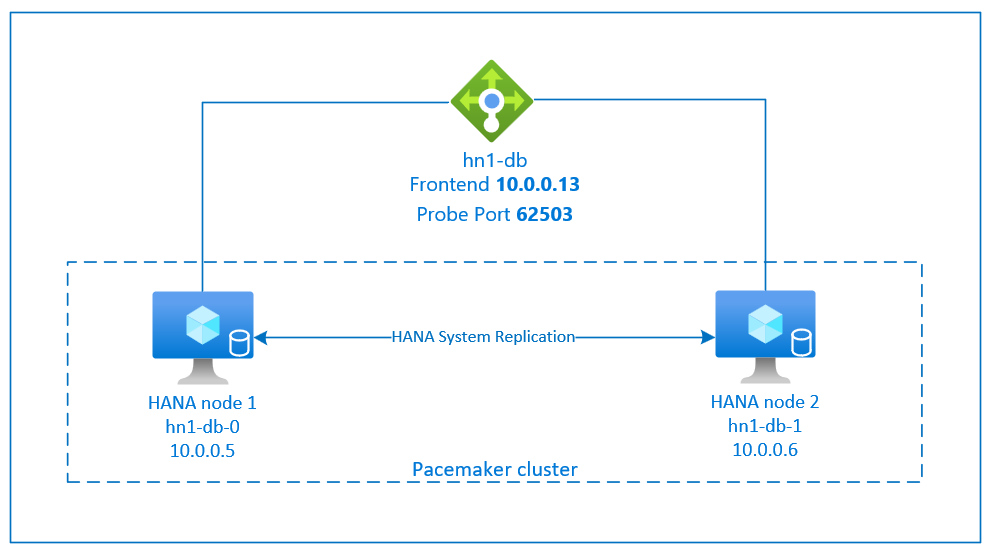
La procedura di configurazione della replica di sistema SAP HANA usa un nome host virtuale dedicato e indirizzi IP virtuali. In Azure è necessario un bilanciamento del carico per distribuire un indirizzo IP virtuale.
La figura precedente mostra un bilanciamento del carico di esempio con queste configurazioni:
- Indirizzo IP front-end: 10.0.0.13 per HN1-db
- Porta probe: 62503
Preparare l'infrastruttura
L'agente delle risorse per SAP HANA è incluso in SUSE Linux Enterprise Server for SAP Applications. Un'immagine per SUSE Linux Enterprise Server per applicazioni SAP 12 o 15 è disponibile in Azure Marketplace. È possibile usare l'immagine per distribuire nuove macchine virtuali.
Distribuire macchine virtuali Linux manualmente tramite il portale di Azure
Questo documento presuppone che sia già stato distribuito un gruppo di risorse, una rete virtuale di Azure e una subnet.
Distribuire macchine virtuali per SAP HANA. Scegliere un'immagine SLES appropriata supportata per il sistema HANA. È possibile distribuire una macchina virtuale in una delle opzioni di disponibilità: set di scalabilità di macchine virtuali, zona di disponibilità o set di disponibilità.
Importante
Assicurarsi che il sistema operativo selezionato sia certificato SAP per SAP HANA nei tipi di macchina virtuale specifici che si prevede di usare nella distribuzione. È possibile cercare i tipi di VM certificati SAP HANA e le relative versioni del sistema operativo in Piattaforme IaaS certificate per SAP HANA. Assicurarsi di esaminare ogni voce dei tipi di macchina virtuale per ottenere l'elenco completo delle versioni di sistema operativo supportate da SAP HANA per lo specifico tipo di macchina virtuale.
Configurare il servizio di bilanciamento del carico di Azure
Durante la configurazione della macchina virtuale, è possibile creare o selezionare il servizio di bilanciamento del carico esistente nella sezione Rete. Seguire questa procedura per configurare il servizio di bilanciamento del carico standard per la configurazione a disponibilità elevata del database HANA.
Seguire la procedura descritta in Creare il servizio di bilanciamento del carico per configurare un servizio di bilanciamento del carico standard per un sistema SAP a disponibilità elevata usando il portale di Azure. Durante la configurazione del servizio di bilanciamento del carico, considerare i punti seguenti:
- Configurazione IP front-end: creare un indirizzo IP front-end. Selezionare la stessa rete virtuale e il nome della subnet delle macchine virtuali di database.
- Pool back-end: creare un pool back-end e aggiungere macchine virtuali di database.
-
Regole in ingresso: creare una regola di bilanciamento del carico. Seguire la stessa procedura per entrambe le regole di bilanciamento del carico.
- Indirizzo IP front-end: selezionare un indirizzo IP front-end.
- Pool back-end: selezionare un pool back-end.
- Porte a disponibilità elevata: selezionare questa opzione.
- Protocollo: selezionare TCP.
-
Probe di integrità: creare un probe di integrità con i dettagli seguenti:
- Protocollo: selezionare TCP.
- Porta: ad esempio, 625<instance-no.>.
- Intervallo: immettere 5.
- Soglia probe: immettere 2.
- Timeout di inattività (minuti): immettere 30.
- Abilita IP mobile: selezionare questa opzione.
Nota
La proprietà di configurazione del probe di integrità numberOfProbes, altrimenti nota come soglia non integra nel portale, non viene rispettata. Per controllare il numero di probe consecutivi riusciti o non riusciti, impostare la proprietà probeThreshold su 2. Non è attualmente possibile impostare questa proprietà usando il portale di Azure, quindi usare l'interfaccia della riga di comando di Azure o il comando di PowerShell.
Per altre informazioni sulle porte necessarie per SAP HANA, leggere il capitolo Connections to Tenant Databases (Connessioni a database tenant) della guida SAP HANA Tenant Databases (Database tenant SAP HANA) o la nota SAP 2388694.
Nota
Se vengono inserite macchine virtuali che non hanno indirizzi IP pubblici in un pool back-end di un’istanza standard interna (nessun indirizzo IP pubblico) di Azure Load Balancer, la configurazione predefinita è che non è presente connettività Internet in uscita. È possibile eseguire passaggi aggiuntivi per consentire il routing agli endpoint pubblici. Per informazioni dettagliate su come ottenere la connettività in uscita, vedere Connettività degli endpoint pubblici per le macchine virtuali usando Load Balancer Standard di Azure negli scenari a disponibilità elevata SAP.
Importante
- Non abilitare i timestamp TCP nelle macchine virtuali di Azure che si trovano dietro Azure Load Balancer. Se si abilitano i timestamp TCP, i probe di integrità hanno esito negativo. Impostare il parametro
net.ipv4.tcp_timestampssu0. Per informazioni dettagliate, vedere Probe di integrità di Load Balancer o la nota SAP 2382421. - Per impedire a saptune di modificare il valore impostato manualmente da
net.ipv4.tcp_timestampsa0a1, aggiornare la versione di saptune alla versione 3.1.1 o successiva. Per ulteriori dettagli, vedere saptune 3.1.1 – Devo fare l’aggiornamento?.
Creare un cluster Pacemaker
Seguire i passaggi descritti in Configurare Pacemaker su SUSE Linux Enterprise Server in Azure per creare un cluster Pacemaker di base per questo server HANA. È possibile usare lo stesso cluster Pacemaker per SAP HANA e SAP NetWeaver (A)SCS.
Installare SAP HANA
Nei passaggi descritti in questa sezione vengono usati i prefissi seguenti:
- [T]: il passaggio si applica a tutti i nodi.
- [1]: il passaggio si applica solo al nodo 1.
- [2]: il passaggio si applica solo al nodo 2 del cluster Pacemaker.
Sostituire <placeholders> con i valori per l'installazione di SAP HANA.
[A] Configurare il layout dei dischi usando l’utilità di gestione dei volumi logici (LVM).
È consigliabile usare LVM per i volumi che archiviano file di log e dati. L'esempio seguente presuppone che le macchine virtuali abbiano quattro dischi dati collegati, usati per creare due volumi.
Eseguire questo comando per generare un elenco di tutti i dischi disponibili:
ls /dev/disk/azure/scsi1/lun*Output di esempio:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Creare i volumi fisici per tutti i dischi da usare:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Creare un gruppo di volumi per i file di dati. Usare un gruppo di volumi per i file di log e uno per la directory condivisa di SAP HANA:
sudo vgcreate vg_hana_data_<HANA SID> /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_<HANA SID> /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_<HANA SID> /dev/disk/azure/scsi1/lun3Creare i volumi logici.
Quando si usa
lvcreatesenza l'opzione-i, viene creato un volume lineare. È consigliabile creare un volume con striping per migliorare le prestazioni di I/O. Allineare le dimensioni di striping ai valori che sono descritti in configurazioni di archiviazione delle macchine virtuali SAP HANA. L'argomento-ideve essere il numero dei volumi fisici sottostanti e l'argomento-Iè la dimensione della striscia.Ad esempio, se per il volume di dati vengono usati due volumi fisici, l'argomento switch
-iè impostato su 2 e le dimensioni di striping per il volume di dati sono pari a 256KiB. Un volume fisico viene usato per il volume di log, quindi non viene usata alcuna opzione-io-Iin modo esplicito per i comandi del volume di log.Importante
Quando si usano più volumi fisici per ogni volume di dati, di log o condiviso, usare l'opzione
-ie impostarla sul numero del volume fisico sottostante. Quando si crea un volume con striping, usare l'opzione-Iper specificare le dimensioni di striping.Per le configurazioni di archiviazione consigliate, incluse le dimensioni di striping e il numero di dischi, vedere Configurazioni di archiviazione della macchina virtuale SAP HANA.
sudo lvcreate <-i number of physical volumes> <-I stripe size for the data volume> -l 100%FREE -n hana_data vg_hana_data_<HANA SID> sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_<HANA SID> sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_<HANA SID> sudo mkfs.xfs /dev/vg_hana_data_<HANA SID>/hana_data sudo mkfs.xfs /dev/vg_hana_log_<HANA SID>/hana_log sudo mkfs.xfs /dev/vg_hana_shared_<HANA SID>/hana_sharedCreare le directory di montaggio e copiare l'identificatore univoco universale (UUID) di tutti i volumi logici:
sudo mkdir -p /hana/data/<HANA SID> sudo mkdir -p /hana/log/<HANA SID> sudo mkdir -p /hana/shared/<HANA SID> # Write down the ID of /dev/vg_hana_data_<HANA SID>/hana_data, /dev/vg_hana_log_<HANA SID>/hana_log, and /dev/vg_hana_shared_<HANA SID>/hana_shared sudo blkidModificare il file /etc/fstab per creare voci
fstabper i tre volumi logici:sudo vi /etc/fstabInserire le righe seguenti nel file /etc/fstab:
/dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_data_<HANA SID>-hana_data> /hana/data/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_log_<HANA SID>-hana_log> /hana/log/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_shared_<HANA SID>-hana_shared> /hana/shared/<HANA SID> xfs defaults,nofail 0 2Montare i nuovi volumi:
sudo mount -a
[A] Configurare il layout del disco usando dischi semplici.
Per sistemi demo, è possibile inserire i dati e i file di log HANA in un solo disco.
Creare una partizione in /dev/disk/azure/scsi1/lun0 e formattarla usando XFS:
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstabNel file /etc/fstab Inserire la riga seguente:
/dev/disk/by-uuid/<UUID> /hana xfs defaults,nofail 0 2Creare la directory di destinazione e montare il disco:
sudo mkdir /hana sudo mount -a
[T] Configurare la risoluzione dei nomi host per tutti gli host.
È possibile usare un server DNS o modificare il file /etc/hosts in tutti i nodi. Questo esempio mostra come usare il file /etc/hosts. Sostituire gli indirizzi IP e i nomi host nei comandi seguenti.
Modifica il file etc/hosts:
sudo vi /etc/hostsInserire le righe seguenti nel file /etc/hosts. Modificare gli indirizzi IP e i nomi host in base all'ambiente.
10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Installare SAP HANA, seguendo la documentazione di SAP.
Configurare la replica di sistema di SAP HANA 2.0
Nei passaggi descritti in questa sezione vengono usati i prefissi seguenti:
- [T]: il passaggio si applica a tutti i nodi.
- [1]: il passaggio si applica solo al nodo 1.
- [2]: il passaggio si applica solo al nodo 2 del cluster Pacemaker.
Sostituire <placeholders> con i valori per l'installazione di SAP HANA.
[1] Creare il database tenant.
Se si usa SAP HANA 2.0 o SAP HANA MDC, creare un database tenant per il sistema SAP NetWeaver.
Eseguire il comando seguente come <SID HANA>adm:
hdbsql -u SYSTEM -p "<password>" -i <instance number> -d SYSTEMDB 'CREATE DATABASE <SAP SID> SYSTEM USER PASSWORD "<password>"'[1] Configurare la replica di sistema nel primo nodo:
Prima di tutto, eseguire il backup dei database come <SID HANA>adm:
hdbsql -d SYSTEMDB -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SYS>')" hdbsql -d <HANA SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for HANA SID>')" hdbsql -d <SAP SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SAP SID>')"Copiare quindi i file dell’infrastruttura a chiave pubblica (PKI) del sistema nel sito secondario:
scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/SSFS_<HANA SID>.DAT hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/ scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/SSFS_<HANA SID>.KEY hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/Creare il sito primario:
hdbnsutil -sr_enable --name=<site 1>[2] Configurare la replica di sistema nel secondo nodo:
Registrare il secondo nodo per avviare la replica di sistema.
Eseguire il comando seguente come <SID HANA>adm:
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
Implementare agenti di risorse HANA
SUSE fornisce due diversi pacchetti software per l'agente di risorse Pacemaker per gestire SAP HANA. I pacchetti software SAPHanaSR e SAPHanaSR-angi usano una sintassi e parametri leggermente diversi e non sono compatibili. Per informazioni dettagliate e differenze tra SAPHanaSR e SAPHanaSR-angi, vedere le note sulla versione di SUSE e la documentazione . Questo documento illustra entrambi i pacchetti in schede separate nelle rispettive sezioni.
Avviso
Non sostituire il pacchetto SAPHanaSR da SAPHanaSR-angi in un cluster già configurato. L'aggiornamento da SAPHanaSR a SAPHanaSR-angi richiede una procedura specifica. Per altri dettagli, vedere il post di blog di SUSE: Come eseguire l'aggiornamento a SAPHanaSR-angi.
- [T] Installare i pacchetti di disponibilità elevata SAP HANA:
Importante
SAPHanaSR-angi ha un requisito di versione minima di SAP HANA 2.0 SPS 05 e SUSE SLES for SAP Applications 15 SP4 o versione successiva.
Eseguire il comando seguente per installare i pacchetti di disponibilità elevata:
sudo zypper install SAPHanaSR-angi
Configurare i provider SAP HANA HA/DR
I provider SAP HANA HA/DR ottimizzano l'integrazione con il cluster e migliorano il rilevamento quando è necessario un failover del cluster. Lo script hook principale è SAPHanaSR (per il pacchetto SAPHanaSR) / susHanaSR (per SAPHanaSR-angi). È consigliabile configurare l'hook Python SAPHanaSR/susHanaSR. Per HANA 2.0 SPS 05 e versioni successive, è consigliabile implementare sia SAPHanaSR/susHanaSR che gli hook susChkSrv.
L'hook susChkSrv estende la funzionalità del provider PRINCIPALE SAPHanaSR/susHanaSR HA. Agisce quando si verifica un arresto anomalo del processo HDbindexserver di HANA. Se un singolo processo si arresta in modo anomalo, in genere HANA tenta di riavviarlo. Il riavvio del processo indexserver può richiedere molto tempo, durante il quale il database HANA non risponde.
Con susChkSrv implementato, viene eseguita un'azione immediata e configurabile. L'azione attiva un failover nel periodo di timeout configurato, anziché attendere il riavvio del processo hdbindexserver nello stesso nodo.
- [A] Arrestare HANA in entrambi i nodi.
Eseguire il codice seguente come <adm sap-sid>:
sapcontrol -nr <instance number> -function StopSystem
[A] Installare gli hook di replica di sistema HANA. Gli hook devono essere installati in entrambi i nodi del database HANA.
Suggerimento
L'hook Python SAPHanaSR può essere implementato solo per HANA 2.0. Il pacchetto SAPHanaSR deve essere almeno della versione 0.153.
L'hook Python SAPHanaSR-angi può essere implementato solo per HANA 2.0 SPS 05 e versioni successive.
Per l'hook python susChkSrv è necessario installare SAP HANA 2.0 SPS 05 e SAPHanaSR versione 0.161.1_BF o versione successiva.[A] Regolare global.ini in ogni nodo del cluster.
Se si sceglie di non usare l'hook susChkSrv consigliato, rimuovere l'intero
[ha_dr_provider_suschksrv]blocco dai parametri seguenti. È possibile modificare il comportamento disusChkSrvusando il parametroaction_on_lost. Valori validi:ignore|stop|kill|fence.[ha_dr_provider_sushanasr] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = fence [trace] ha_dr_sushanasr = info ha_dr_suschksrv = infoSe si punta il percorso del parametro al percorso predefinito
/usr/share/SAPHanaSR-angi, il codice hook Python viene aggiornato automaticamente tramite gli aggiornamenti del sistema operativo o gli aggiornamenti dei pacchetti. HANA usa gli aggiornamenti del codice hook al successivo riavvio. Con un percorso personalizzato facoltativo, ad esempio/hana/shared/myHooks, è possibile separare gli aggiornamenti del sistema operativo dalla versione hook usata.[A] Il cluster richiede la configurazione sudoers in ogni nodo del cluster per <sap-sid>adm. In questo esempio lo si ottiene creando un nuovo file.
Eseguire il comando indicato di seguito come utente ROOT. Sostituire <sid con ID di sistema SAP minuscolo> , <SID> per ID sistema SAP maiuscolo e <siteA/B> con i nomi dei siti HANA scelti.
cat << EOF > /etc/sudoers.d/20-saphana # Needed for susHanaSR and susChkSrv Python hooks Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HELPER_TAKEOVER = /usr/bin/SAPHanaSR-hookHelper --sid=<SID> --case=checkTakeover Cmnd_Alias HELPER_FENCE = /usr/bin/SAPHanaSR-hookHelper --sid=<SID> --case=fenceMe <sid>adm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB, HELPER_TAKEOVER, HELPER_FENCE EOFPer informazioni dettagliate sull'implementazione dell'hook di replica di sistema SAP HANA, vedere Configurare i provider HA/DR di HANA.
[A] Avviare HANA in entrambi i nodi. Eseguire il comando seguente come <adm sap-sid>:
sapcontrol -nr <instance number> -function StartSystem[1] Verificare l'installazione dell'hook. Eseguire il comando seguente come <adm sap-sid>nel sito di replica del sistema HANA attivo:
cdtrace grep HADR.*load.*susHanaSR nameserver_*.trc grep susHanaSR.init nameserver_*.trc # Example output # ha_dr_provider HADRProviderManager.cpp(00083) : loading HA/DR Provider 'susHanaSR' from /usr/share/SAPHanaSR-angi
-
[1] Verificare l'installazione dell'hook susChkSrv.
Eseguire il comando seguente come <adm sap-sid>nelle macchine virtuali HANA:
cdtrace egrep '(LOST:|STOP:|START:|DOWN:|init|load|fail)' nameserver_suschksrv.trc # Example output # 2022-11-03 18:06:21.116728 susChkSrv.init() version 0.7.7, parameter info: action_on_lost=fence stop_timeout=20 kill_signal=9 # 2022-11-03 18:06:27.613588 START: indexserver event looks like graceful tenant start # 2022-11-03 18:07:56.143766 START: indexserver event looks like graceful tenant start (indexserver started)
Creare le risorse cluster SAP HANA
- [1] Creare prima di tutto la risorsa topologia HANA.
Eseguire i comandi seguenti in uno dei nodi del cluster Pacemaker:
sudo crm configure property maintenance-mode=true
# Replace <placeholders> with your instance number and HANA system ID
sudo crm configure primitive rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaTopology \
op monitor interval="50" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="<HANA SID>" InstanceNumber="<instance number>"
sudo crm configure clone cln_SAPHanaTopology_<HANA SID>_HDB<instance number> rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" interleave="true"
- [1] Creare quindi le risorse HANA:
# Replace <placeholders> with your instance number and HANA system ID.
sudo crm configure primitive rsc_SAPHanaController_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaController \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op demote interval="0" timeout="320" \
op monitor interval="60" role="Promoted" timeout="700" \
op monitor interval="61" role="Unpromoted" timeout="700" \
params SID="<HANA SID>" InstanceNumber="<instance number>" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false" \
meta priority=100
sudo crm configure clone msl_SAPHanaController_<HANA SID>_HDB<instance number> rsc_SAPHanaController_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" interleave="true" promotable="true"
SAPHanaSR-angi aggiunge un nuovo agente di risorse SAPHanaFilesystem per monitorare l'accesso in lettura/scrittura a /hana/shared/SID. Il sistema operativo monta il file system /hana/shared/SID con ogni host con voci in /etc/fstab. SAPHanaFilesystem e Pacemaker non montano il file system per HANA.
È consigliabile implementare SAPHanaFilesystem se si usa NFS per la posizione /hana/shared/SID. Quando /hana/shared/SID si trova in un dispositivo a blocchi, ad esempio un disco gestito di Azure, l'uso di SAPHanaFilesystem è facoltativo.
# Replace <placeholders> with your instance number and HANA system ID.
sudo crm configure primitive rsc_SAPHanaFilesystem_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaFilesystem \
op start interval="0" timeout="10" \
op stop interval="0" timeout="20" \
op monitor interval="120" timeout="120" \
params SID="<HANA SID>" InstanceNumber="<instance number>" ON_FAIL_ACTION="fence"
sudo crm configure clone cln_SAPHanaFilesystem_<HANA SID>_HDB<instance number> rsc_SAPHanaFilesystem_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" interleave="true"
- [1] Continuare con le risorse del cluster per indirizzi IP virtuali, impostazioni predefinite e vincoli.
# Replace <placeholders> with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer.
sudo crm configure primitive rsc_ip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
op start timeout=60s on-fail=fence \
op monitor interval="10s" timeout="20s" \
params ip="<front-end IP address>"
sudo crm configure primitive rsc_nc_<HANA SID>_HDB<instance number> azure-lb port=625<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
sudo crm configure group g_ip_<HANA SID>_HDB<instance number> rsc_ip_<HANA SID>_HDB<instance number> rsc_nc_<HANA SID>_HDB<instance number>
sudo crm configure colocation col_saphana_ip_<HANA SID>_HDB<instance number> 4000: g_ip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHanaController_<HANA SID>_HDB<instance number>:Promoted
sudo crm configure order ord_SAPHana_<HANA SID>_HDB<instance number> Optional: cln_SAPHanaTopology_<HANA SID>_HDB<instance number> \
msl_SAPHanaController_<HANA SID>_HDB<instance number>
# Clean up the HANA resources. The HANA resources might have failed because of a known issue.
sudo crm resource cleanup rsc_SAPHanaController_<HANA SID>_HDB<instance number>
sudo crm configure property priority-fencing-delay=30
sudo crm configure property maintenance-mode=false
sudo crm configure rsc_defaults resource-stickiness=1000
sudo crm configure rsc_defaults migration-threshold=5000
Importante
È consigliabile impostare AUTOMATED_REGISTER su false solo mentre si completano test di failover completi, per impedire a un'istanza primaria non riuscita di eseguire automaticamente la registrazione come secondaria. Al termine dei test di failover, impostare AUTOMATED_REGISTER su true, in modo che dopo l'acquisizione, la replica di sistema riprende automaticamente.
Assicurarsi che lo stato del cluster sia OK e che tutte le risorse siano avviate. Non è importante il nodo su cui sono in esecuzione le risorse.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Configurare la replica di sistema attiva/abilitata per la lettura HANA in un cluster Pacemaker
In SAP HANA 2.0 SPS 01 e versioni successive, SAP consente un'installazione attiva/abilitata per la lettura per la replica di sistema SAP HANA. In questo scenario, i sistemi secondari della replica di sistema SAP HANA possono essere usati attivamente per carichi di lavoro a elevato utilizzo di lettura.
Per supportare questa configurazione in un cluster, è necessario un secondo indirizzo IP virtuale in modo che i client possano accedere al database SAP HANA abilitato per la lettura secondario. Per assicurarsi che il sito di replica secondario sia ancora accessibile dopo un'acquisizione, il cluster deve spostare l'indirizzo IP virtuale con la risorsa SAPHana secondaria.
Questa sezione descrive i passaggi aggiuntivi necessari per gestire una replica di sistema attiva/abilitata per la lettura di HANA in un cluster a disponibilità elevata SUSE che usa un secondo indirizzo IP virtuale.
Prima di procedere, assicurarsi di aver configurato completamente il cluster a disponibilità elevata SUSE che gestisce il database SAP HANA come descritto nelle sezioni precedenti.
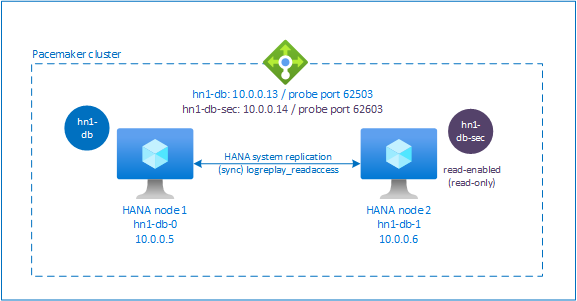
Configurare il servizio di bilanciamento del carico per la replica di sistema attiva/abilitata per la lettura
Per procedere con passaggi aggiuntivi per effettuare il provisioning del secondo indirizzo IP virtuale, assicurarsi di aver configurato Azure Load Balancer come descritto in Distribuire manualmente macchine virtuali Linux tramite il portale di Azure.
Per il servizio di bilanciamento del carico standard, completare questi passaggi aggiuntivi sullo stesso bilanciamento del carico creato in precedenza.
- Creare un secondo pool di indirizzi IP front-end:
- Aprire il servizio di bilanciamento del carico, selezionare Pool di indirizzi IP front-end e quindi Aggiungi.
- Immettere il nome del secondo pool di indirizzi IP front-end (ad esempio, hana-secondaryIP).
- Impostare Assegnazione su Statico e immettere l'indirizzo IP (ad esempio 10.0.0.14).
- Seleziona OK.
- Dopo aver creato il nuovo pool di indirizzi IP front-end, annotare l'indirizzo IP front-end.
- Creare un probe di integrità:
- Nel servizio di bilanciamento del carico, selezionare Probe integrità e quindi Aggiungi.
- Immettere il nome del nuovo probe di integrità (ad esempio, hana-secondaryhp).
- Selezionare TCP come protocollo e la porta 626<numero istanza>. Lasciare il valore di Intervallo impostato su 5 e il valore di Soglia di non integrità impostato su 2.
- Seleziona OK.
- Creare le regole del servizio di bilanciamento del carico:
- Nel servizio di bilanciamento del carico, selezionare Regole di bilanciamento del carico e quindi Aggiungi.
- Immettere il nome della nuova regola di bilanciamento del carico (ad esempio, hana-secondarylb).
- Selezionare l'indirizzo IP front-end, il pool back-end e il probe di integrità creati in precedenza (ad esempio, hana-secondaryIP, hana-backend e hana-secondaryhp).
- Selezionare Porte a disponibilità elevata.
- Aumentare il timeout di inattività a 30 minuti.
- Assicurarsi di selezionare Abilita l'indirizzo IP mobile.
- Seleziona OK.
Configurare la replica di sistema attiva/abilitata per la lettura di HANA
I passaggi per configurare la replica di sistema HANA sono descritti in Configurare la replica di sistema SAP HANA 2.0. Se si distribuisce uno scenario secondario abilitato per la lettura, quando si configura la replica di sistema nel secondo nodo, eseguire il comando seguente come <SID HANA>adm:
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> --operationMode=logreplay_readaccess
Aggiungere una risorsa indirizzo IP virtuale secondario
È possibile configurare il secondo indirizzo IP virtuale e il vincolo di coubicazione appropriato usando i comandi seguenti:
crm configure property maintenance-mode=true
crm configure primitive rsc_secip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
op monitor interval="10s" timeout="20s" \
params ip="<secondary IP address>"
crm configure primitive rsc_secnc_<HANA SID>_HDB<instance number> azure-lb port=626<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
crm configure group g_secip_<HANA SID>_HDB<instance number> rsc_secip_<HANA SID>_HDB<instance number> rsc_secnc_<HANA SID>_HDB<instance number>
crm configure colocation col_saphana_secip_<HANA SID>_HDB<instance number> 4000: g_secip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHanaController_<HANA SID>_HDB<instance number>:Unpromoted
crm configure property maintenance-mode=false
Assicurarsi che lo stato del cluster sia OK e che tutte le risorse siano avviate. Il secondo indirizzo IP virtuale viene eseguito nel sito secondario insieme alla risorsa secondaria SAPHana.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# Resource Group: g_secip_HN1_HDB03:
# rsc_secip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
# rsc_secnc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Nella sezione successiva viene descritto il set tipico di test di failover da eseguire.
Considerazioni quando si testa un cluster HANA configurato con un database secondario abilitato per la lettura:
Quando si esegue la migrazione della risorsa cluster
SAPHana_<HANA SID>_HDB<instance number>ahn1-db-1, il secondo indirizzo IP virtuale passa ahn1-db-0. Se è stato configuratoAUTOMATED_REGISTER="false"e la replica di sistema HANA non viene registrata automaticamente, il secondo indirizzo IP virtuale viene eseguito suhn1-db-0perché il server è disponibile e i servizi del cluster sono online.Quando si verifica un arresto anomalo del server, le seconde risorse IP virtuali (
rsc_secip_<HANA SID>_HDB<instance number>) e la risorsa porta del servizio di bilanciamento del carico di Azure (rsc_secnc_<HANA SID>_HDB<instance number>) vengono eseguite nel server primario insieme alle risorse IP virtuali primarie. Mentre il server secondario è inattivo, le applicazioni connesse a un database HANA abilitato per la lettura si connettono al database HANA primario. Il comportamento è previsto perché non si desidera che le applicazioni connesse a un database HANA abilitato per la lettura non siano inaccessibili mentre il server secondario non è disponibile.Quando il server secondario è disponibile e i servizi del cluster sono online, le risorse di secondo indirizzo IP virtuale e porta passano automaticamente al server secondario, anche se la replica di sistema HANA potrebbe non essere registrata come secondaria. Assicurarsi di registrare il database HANA secondario come abilitato per la lettura prima di avviare i servizi cluster in tale server. È possibile configurare la risorsa cluster dell'istanza di HANA per registrare automaticamente il database secondario impostando il parametro
AUTOMATED_REGISTER="true".Durante il failover e il fallback, le connessioni esistenti per le applicazioni, che quindi usano il secondo IP virtuale per connettersi al database HANA, potrebbero essere interrotte.
Testare la configurazione del cluster
Questa sezione descrive come testare la configurazione. Ogni test presuppone che sia stato eseguito l'accesso come radice e che il master SAP HANA sia in esecuzione nella macchina virtuale hn1-db-0.
Test della migrazione
Prima di iniziare il test, assicurarsi che in Pacemaker non vi siano azioni non riuscite (eseguire crm_mon -r), che non siano presenti vincoli di posizione imprevisti (ad esempio rimasti da un test di migrazione precedente) e che HANA si trovi nello stato di sincronizzazione, ad esempio eseguendo SAPHanaSR-showAttr.
hn1-db-0:~ # SAPHanaSR-showAttr
Global cib-update dcid prim sec sid topology
--------------------------------------------------
global 0.130728.2 1 SITE1 - HN1 ScaleUp
Resource promotable
-----------------------------------------
msl_SAPHanaController_HN1_HDB03 true
cln_SAPHanaTopology_HN1_HDB03
Site lpt lss mns opMode srHook srMode srPoll srr
-----------------------------------------------------------------------
SITE1 1722604101 4 hn1-db-0 logreplay PRIM sync PRIM P
SITE2 30 4 hn1-db-1 logreplay SWAIT sync SOK S
Host clone_state roles score site sra srah version vhost
---------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED master1:master:worker:master 150 SITE1 - - 2.00.074.00 hn1-db-0
hn1-db-1 DEMOTED master1:master:worker:master 100 SITE2 - 2.00.074.00 hn1-db-1
Host clone_state roles score site sra srah version vhost
------------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED master1:master:worker:master 150 SITE1 - - 2.00.074.00 hn1-db-0
hn1-db-1 SITE2 hn1-db-1
È possibile eseguire la migrazione del nodo master SAP HANA eseguendo il comando seguente:
crm resource move msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1 force
Il cluster dovrebbe eseguire la migrazione del nodo master SAP HANA e del gruppo che contiene l'indirizzo IP virtuale in hn1-db-1.
Al termine della migrazione, l'output crm_mon -r sarà simile all'esempio seguente:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Failed Actions:
* rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none',
last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms
Con AUTOMATED_REGISTER="false", il cluster non riavvia il database HANA non riuscito o lo registra nel nuovo database primario in hn1-db-0. In questo caso, configurare l'istanza di HANA come secondaria eseguendo questo comando:
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr <instance number> -function StopWait 600 10
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
La migrazione crea vincoli di posizione che devono essere eliminati di nuovo:
# Switch back to root and clean up the failed state
exit
hn1-db-0:~ # crm resource clear msl_SAPHana_<HANA SID>_HDB<instance number>
È anche necessario eseguire la pulizia dello stato della risorsa nodo secondario:
hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Monitorare lo stato della risorsa HANA usando crm_mon -r. Quando HANA viene avviato in hn1-db-0, l'output è simile all'esempio seguente:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Blocco della comunicazione di rete
Stato delle risorse prima dell'avvio del test:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Eseguire una regola del firewall per bloccare la comunicazione in uno dei nodi.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Quando i nodi del cluster non possono comunicare tra loro, esiste il rischio di uno scenario split-brain. In tali situazioni, i nodi del cluster tenteranno di recintarsi l'uno dall'altro contemporaneamente, comportando una gara di recinzione.
Quando si configura un dispositivo di isolamento, è consigliabile configurare la proprietà pcmk_delay_max. Pertanto, in caso di scenario split-brain, il cluster introduce un ritardo casuale fino al valore di pcmk_delay_max, all'azione di isolamento in ogni nodo. Il nodo con il ritardo più breve verrà selezionato per l'isolamento.
Inoltre, per assicurarsi che il nodo che esegue il master HANA abbia la priorità e vinca la gara di recinzione in uno scenario split-brain, è consigliabile impostare la proprietà priority-fencing-delay nella configurazione del cluster. Abilitando la proprietà priority-fencing-delay, il cluster può introdurre un ulteriore ritardo nell'azione di isolamento, in particolare nel nodo che ospita la risorsa master HANA, consentendo al nodo di vincere la gara di isolamento.
Eseguire il comando seguente per eliminare la regola del firewall.
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Testare l'isolamento SBD
È possibile testare la configurazione di SBD terminando il processo inquisitor:
hn1-db-0:~ # ps aux | grep sbd
root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor
root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8
root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd
root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c
root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker
root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster
root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd
hn1-db-0:~ # kill -9 1912
Il nodo del cluster <HANA SID>-db-<database 1> viene riavviato. Il servizio Pacemaker potrebbe non essere riavviato. Assicurarsi di riavviarlo.
Testare un failover manuale
È possibile testare un failover manuale arrestando il servizio Pacemaker nel nodo hn1-db-0:
service pacemaker stop
Dopo il failover, è possibile avviare nuovamente il servizio. Se si imposta AUTOMATED_REGISTER="false", la risorsa SAP HANA nel nodo hn1-db-0 non viene avviata come secondaria.
In questo caso, configurare l'istanza di HANA come secondaria eseguendo questo comando:
service pacemaker start
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
# Switch back to root and clean up the failed state
exit
crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Test SUSE
Importante
Assicurarsi che il sistema operativo selezionato sia dotato di certificazione SAP per SAP HANA sugli specifici tipi di macchina virtuale che si ha in programma di usare. È possibile cercare i tipi di VM certificati SAP HANA e le relative versioni del sistema operativo in Piattaforme IaaS certificate per SAP HANA. Assicurarsi di esaminare ogni voce dei tipi di macchina virtuale che si ha in programma di usare, per ottenere l'elenco completo delle versioni di sistema operativo supportate da SAP HANA per il tipo di macchina virtuale.
Eseguire tutti i test case elencati nella guida allo scenario di ottimizzazione delle prestazioni della replica di sistema SAP HANA o dello scenario di ottimizzazione dei costi della replica di sistema SAP HANA, a seconda dello scenario. Le guide sono elencate in Procedure consigliate per SLES per SAP.
I test seguenti sono una copia delle descrizioni dei test della guida di SUSE Linux Enterprise Server for SAP Applications 12 SP1 per lo scenario di ottimizzazione delle prestazioni della replica di sistema SAP HANA. Per una versione aggiornata, fare riferimento alla guida. Assicurarsi sempre che HANA sia sincronizzato prima di avviare il test e che la configurazione di Pacemaker sia corretta.
Nelle descrizioni dei test seguenti si presuppone PREFER_SITE_TAKEOVER="true" e AUTOMATED_REGISTER="false".
Nota
I test seguenti sono progettati per essere eseguiti in sequenza. Ogni test dipende dallo stato di uscita del test precedente.
Test 1: arrestare il database primario nel nodo 1.
Lo stato delle risorse prima dell'avvio del test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Eseguire i comandi seguenti come <hana sid>adm nel nodo
hn1-db-0:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB stopPacemaker rileva l'istanza HANA arrestata ed esegue il failover nell'altro nodo. Al termine del failover, l'istanza HANA nel nodo
hn1-db-0viene arrestata perché Pacemaker non registra automaticamente il nodo come nodo secondario HANA.Eseguire i comandi seguenti per registrare il nodo
hn1-db-0come secondario e pulire la risorsa per la quale si è verificato un errore:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Lo stato delle risorse dopo il test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 2: arrestare il database primario nel nodo 2.
Lo stato delle risorse prima dell'avvio del test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Eseguire i comandi seguenti come <hana sid>adm nel nodo
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB01> HDB stopPacemaker rileva l'istanza HANA arrestata ed esegue il failover nell'altro nodo. Al termine del failover, l'istanza HANA nel nodo
hn1-db-1viene arrestata perché Pacemaker non registra automaticamente il nodo come nodo secondario HANA.Eseguire i comandi seguenti per registrare il nodo
hn1-db-1come secondario e pulire la risorsa per la quale si è verificato un errore:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Lo stato delle risorse dopo il test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 3: provocare un arresto anomalo del database primario nel nodo 1.
Lo stato delle risorse prima dell'avvio del test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Eseguire i comandi seguenti come <hana sid>adm nel nodo
hn1-db-0:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker rileva l'istanza HANA arrestata ed esegue il failover nell'altro nodo. Al termine del failover, l'istanza HANA nel nodo
hn1-db-0viene arrestata perché Pacemaker non registra automaticamente il nodo come nodo secondario HANA.Eseguire i comandi seguenti per registrare il nodo
hn1-db-0come secondario e pulire la risorsa per la quale si è verificato un errore:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Lo stato delle risorse dopo il test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 4: provocare un arresto anomalo del database primario nel nodo 2.
Lo stato delle risorse prima dell'avvio del test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Eseguire i comandi seguenti come <hana sid>adm nel nodo
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker rileva l'istanza HANA arrestata ed esegue il failover nell'altro nodo. Al termine del failover, l'istanza HANA nel nodo
hn1-db-1viene arrestata perché Pacemaker non registra automaticamente il nodo come nodo secondario HANA.Eseguire i comandi seguenti per registrare il nodo
hn1-db-1come secondario e pulire la risorsa per la quale si è verificato un errore.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Lo stato delle risorse dopo il test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 5: provocare un arresto anomalo del nodo del sito primario (nodo 1).
Lo stato delle risorse prima dell'avvio del test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Eseguire i comandi seguenti come utente ROOT nel nodo
hn1-db-0:hn1-db-0:~ # echo 'b' > /proc/sysrq-triggerPacemaker rileva il nodo del cluster terminato e isola il nodo. Quando il nodo è isolato, Pacemaker attiva un'operazione di acquisizione dell'istanza HANA. Quando il nodo isolato viene riavviato, Pacemaker non si avvia automaticamente.
Eseguire i comandi seguenti per avviare Pacemaker, pulire i messaggi SBD per il nodo
hn1-db-0, registrare il nodohn1-db-0come secondario e pulire la risorsa per la quale si è verificato un errore:# run as root # list the SBD device(s) hn1-db-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-0 clear hn1-db-0:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Lo stato delle risorse dopo il test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 6: provocare un arresto anomalo del nodo del sito secondario (nodo 2).
Lo stato delle risorse prima dell'avvio del test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Eseguire i comandi seguenti come utente ROOT nel nodo
hn1-db-1:hn1-db-1:~ # echo 'b' > /proc/sysrq-triggerPacemaker rileva il nodo del cluster terminato e isola il nodo. Quando il nodo è isolato, Pacemaker attiva un'operazione di acquisizione dell'istanza HANA. Quando il nodo isolato viene riavviato, Pacemaker non si avvia automaticamente.
Eseguire i comandi seguenti per avviare Pacemaker, pulire i messaggi SBD per il nodo
hn1-db-1, registrare il nodohn1-db-1come secondario e pulire la risorsa per la quale si è verificato un errore:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Lo stato delle risorse dopo il test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0 </code></pre>Test 7: arrestare il database secondario nel nodo 2.
Lo stato delle risorse prima dell'avvio del test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Eseguire i comandi seguenti come <hana sid>adm nel nodo
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB stopPacemaker rileva l'istanza HANA arrestata e contrassegna la risorsa come in errore nel nodo
hn1-db-1. Pacemaker riavvia automaticamente l'istanza HANA.Eseguire il comando seguente per pulire lo stato di errore:
# run as root hn1-db-1>:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Lo stato delle risorse dopo il test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 8: provocare un arresto anomalo del database secondario nel nodo 2.
Lo stato delle risorse prima dell'avvio del test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Eseguire i comandi seguenti come <hana sid>adm nel nodo
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker rileva l'istanza HANA arrestata e contrassegna la risorsa come in errore nel nodo
hn1-db-1. Eseguire il comando seguente per pulire lo stato di errore. Pacemaker riavvia quindi automaticamente l'istanza HANA.# run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> HN1-db-1Lo stato delle risorse dopo il test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 9: provocare un arresto anomalo del nodo del sito secondario (nodo 2) che esegue il database HANA secondario.
Lo stato delle risorse prima dell'avvio del test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Eseguire i comandi seguenti come utente ROOT nel nodo
hn1-db-1:hn1-db-1:~ # echo b > /proc/sysrq-triggerPacemaker rileva il nodo del cluster terminato e isola il nodo. Quando il nodo isolato viene riavviato, Pacemaker non si avvia automaticamente.
Eseguire i comandi seguenti per avviare Pacemaker, pulire i messaggi SBD per il nodo
hn1-db-1e pulire la risorsa per la quale si è verificato un errore:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Lo stato delle risorse dopo il test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 10: provocare un arresto anomalo del server di indicizzazione del database primario
Questo test è rilevante solo quando è stato configurato l'hook susChkSrv come descritto in Implementare gli agenti di risorse HANA.
Lo stato delle risorse prima dell'avvio del test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Eseguire i comandi seguenti come utente ROOT nel nodo
hn1-db-0:hn1-db-0:~ # killall -9 hdbindexserverQuando il server index viene terminato, l'hook susChkSrv rileva l'evento e attiva un'azione per recinto il nodo 'hn1-db-0' e avvia un processo di acquisizione.
Eseguire i comandi seguenti per registrare il nodo
hn1-db-0come secondario e pulire la risorsa per la quale si è verificato un errore:# run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Lo stato delle risorse dopo il test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1È possibile eseguire un test case comparabile causando l'arresto anomalo del server di indicizzazione nel nodo secondario. In caso di arresto anomalo del server index, l'hook susChkSrv riconosce l'occorrenza e avvia un'azione per la isolamento del nodo secondario.