Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa guida introduttiva si userà la procedura guidata Importare e vettorializzare i dati nel portale di Azure per iniziare a usare la vettorizzazione integrata. La procedura guidata suddivide il contenuto e chiama un modello di incorporamento per vettorizzare i blocchi al momento dell'indicizzazione e della query.
Questa guida rapida utilizza PDF testuali provenienti dal repository azure-search-sample-data. Tuttavia, è possibile usare le immagini e completare questa guida introduttiva.
Prerequisiti
Un account Azure con una sottoscrizione attiva. Creare un account gratuito.
Un servizio ricerca di intelligenza artificiale di Azure. È consigliabile usare il livello Basic o superiore.
Origine dati supportata.
Modello di incorporamento supportato.
Familiarità con la procedura guidata. Consulta le procedure guidate per l'importazione dati nel portale di Azure.
Origini dati supportate
La procedura guidata Importa e vettorizza datisupporta un'ampia gamma di origini dati di Azure. Tuttavia, questa guida introduttiva illustra solo le origini dati che lavorano con file completi, descritte nella tabella seguente.
| Fonte dati supportata | Descrizione |
|---|---|
| Archiviazione BLOB di Azure | Questa origine dati funziona con BLOB e tabelle. È necessario usare un account standard per le prestazioni (utilizzo generico v2). I livelli di accesso possono essere frequenti, rari o freddi. |
| Azure Data Lake Storage (ADLS) Gen2 | Si tratta di un account di archiviazione di Azure con uno spazio dei nomi gerarchico abilitato. Per verificare di avere Data Lake Storage, controllare la scheda Proprietà nella pagina Panoramica .
|
| OneLake | Questa fonte di dati è attualmente in anteprima. Per informazioni sulle limitazioni e sulle scorciatoie supportate, vedere Indicizzazione di OneLake. |
Modelli di incorporamento supportati
Per la vettorizzazione integrata, è necessario usare uno dei modelli di incorporamento seguenti in una piattaforma di intelligenza artificiale di Azure. Le istruzioni di distribuzione vengono fornite in una sezione successiva.
| Fornitore | Modelli supportati |
|---|---|
| Azure OpenAI in Azure AI Foundry Models1, 2 | text-embedding-ada-002 text-embedding-3-small text-embedding-3-large |
| Risorsa multiservizio di Azure AI3 | Per testo e immagini: Visione multimodale AI di Azure4 |
| Catalogo dei modelli di Azure AI Foundry | Per il testo: Cohere-embed-v3-english Cohere-embed-v3-multilingual Per le immagini: Facebook-DinoV2-Image-Embeddings-ViT-Base Facebook-DinoV2-incorporazioni-di-immagini-ViT-Giant |
1 L'endpoint della risorsa OpenAI di Azure deve avere un sottodominio personalizzato, ad esempio https://my-unique-name.openai.azure.com. Se la risorsa è stata creata nel portale di Azure, questo sottodominio viene generato automaticamente durante l'installazione delle risorse.
2 Le risorse OpenAI di Azure (con accesso ai modelli di incorporamento) create nel portale di Azure AI Foundry non sono supportate. Solo le risorse OpenAI di Azure create nel portale di Azure sono compatibili con la competenza incorporamento OpenAI di Azure.
3 Ai fini della fatturazione, è necessario collegare la risorsa multiservizio di Intelligenza artificiale di Azure al set di competenze nel servizio Ricerca intelligenza artificiale di Azure. A meno che non si usi una connessione senza chiave (anteprima) per creare il set di competenze, entrambe le risorse devono trovarsi nella stessa area.
4 Il modello di incorporamento multimodale Vision AI di Azure è disponibile in regioni selezionate.
Requisiti dell'endpoint pubblico
Ai fini di questa guida introduttiva, tutte le risorse precedenti devono avere l'accesso pubblico abilitato in modo che i nodi portale di Azure possano accedervi. In caso contrario, la procedura guidata ha esito negativo. Dopo l'esecuzione della procedura guidata, è possibile abilitare i firewall e gli endpoint privati nei componenti di integrazione per la sicurezza. Per altre informazioni, vedere Proteggere le connessioni nelle procedure guidate di importazione.
Se gli endpoint privati sono già presenti e non possono essere disabilitati,è possibile eseguire in alternativa il rispettivo flusso end-to-end da uno script o programma in una macchina virtuale. La macchina virtuale deve appartenere alla stessa rete virtuale dell’endpoint privato. Ecco un esempio di codice Python per la vettorializzazione integrata. Nello stesso repository GitHub sono disponibili esempi in altri linguaggi di programmazione.
Accesso in base al ruolo
È possibile usare Microsoft Entra ID con assegnazioni di ruolo o l'autenticazione basata su chiave con stringhe di connessione con accesso completo. Per le connessioni di Ricerca intelligenza artificiale di Azure ad altre risorse, è consigliabile assegnare ruoli. Questa guida introduttiva presuppone ruoli.
I servizi di ricerca gratuiti supportano connessioni basate sui ruoli per Azure Cognitive Search. Tuttavia, non supportano le identità gestite nelle connessioni in uscita ad Archiviazione di Azure o a Visione artificiale di Azure. Questa mancanza di supporto richiede l'autenticazione basata su chiave sulle connessioni tra i servizi di ricerca gratuiti e altre risorse di Azure. Per connessioni più sicure, usare il livello Basic o superiore e quindi abilitare i ruoli e configurare un'identità gestita.
Per configurare l'accesso basato sui ruoli consigliato:
Nel servizio di ricerca abilitare i ruoli e configurare un'identità gestita assegnata dal sistema.
Assegnare i ruoli seguenti a se stessi:
Collaboratore servizi di ricerca
Collaboratore ai dati dell'indice di ricerca
Lettore di dati dell'indice di ricerca
Nella piattaforma di origine dati e nel provider di modelli di incorporamento creare assegnazioni di ruolo che consentono al servizio di ricerca di accedere a dati e modelli. Vedere Preparare i dati di esempio e Preparare i modelli di incorporamento.
Nota
Se non è possibile proseguire con la procedura guidata perché le opzioni non sono disponibili (ad esempio, non è possibile selezionare un'origine dati o un modello di incorporamento), rivedere le assegnazioni di ruolo. I messaggi di errore indicano che i modelli o le distribuzioni non esistono, quando la causa reale è che il servizio di ricerca non dispone dell'autorizzazione per accedervi.
Verificare lo spazio
Se si inizia con il servizio gratuito, sono limitati a tre indici, origini dati, set di competenze e indicizzatori. I limiti di base sono 15. Questa guida introduttiva crea uno di ogni oggetto, quindi assicurarsi di disporre di spazio per gli elementi aggiuntivi prima di iniziare.
Preparare i dati di esempio
Questa sezione ti indirizza al contenuto che funziona per questa guida introduttiva. Prima di procedere, assicurarsi di aver completato i prerequisiti per l'accesso in base al ruolo.
Accedere al portale di Azure e selezionare l'account di archiviazione di Azure.
Nel riquadro sinistro selezionareContenitori>.
Creare un contenitore e quindi caricare i documenti PDF del piano sanitario usati per questa guida rapida.
Per assegnare i ruoli:
Nel riquadro sinistro selezionare Controllo di accesso (IAM).
Seleziona Aggiungi>Aggiungi assegnazione ruolo.
In Ruoli di funzione lavorativa selezionare Lettore Dati Blob di Archiviazione e quindi selezionare Avanti.
In Membri selezionare Identità gestita e quindi selezionare Seleziona membri.
Selezionare la sottoscrizione e l'identità gestita del servizio di ricerca.
(Facoltativo) Sincronizzare le eliminazioni nel contenitore con le eliminazioni nell'indice di ricerca. Per configurare l'indicizzatore per il rilevamento dell'eliminazione:
Abilitare l'eliminazione temporanea nell'account di archiviazione. Se si usa l'eliminazione temporanea nativa, il passaggio successivo non è obbligatorio.
Aggiungere metadati personalizzati che un indicizzatore può analizzare per determinare quali BLOB sono contrassegnati per l'eliminazione. Assegnare alla proprietà personalizzata un nome descrittivo. Ad esempio, è possibile denominare la proprietà "IsDeleted" e impostarla su false. Ripeti questo passaggio per ogni blob nel contenitore. Quando si vuole eliminare il BLOB, modificare la proprietà su true. Per altre informazioni, vedere Rilevamento delle modifiche e dell'eliminazione durante l'indicizzazione da Archiviazione di Azure.
Preparare il modello di incorporamento
La procedura guidata può usare i modelli di incorporamento distribuiti da Azure OpenAI, Azure AI Vision o dal catalogo dei modelli nel portale di Azure AI Foundry. Prima di procedere, assicurarsi di aver completato i prerequisiti per l'accesso in base al ruolo.
La procedura guidata supporta text-embedding-ada-002, text-embedding-3-large e text-embedding-3-small. Internamente, la procedura guidata chiama la competenza AzureOpenAIEmbedding per connettersi ad Azure OpenAI.
Accedere al portale di Azure e selezionare la risorsa OpenAI di Azure.
Per assegnare i ruoli:
Nel riquadro sinistro selezionare Controllo di accesso (IAM).
Seleziona Aggiungi>Aggiungi assegnazione ruolo.
In Ruoli della funzione lavorativa, selezionare Utente OpenAI di Servizi cognitivi e quindi selezionare Avanti.
In Membri selezionare Identità gestita e quindi selezionare Seleziona membri.
Selezionare la sottoscrizione e l'identità gestita del servizio di ricerca.
Per distribuire un modello di embedding:
Accedere al portale di Azure AI Foundry e selezionare la risorsa OpenAI di Azure.
Nel riquadro sinistro selezionare Catalogo modelli.
Distribuire un modello di incorporamento supportato.
Avviare la procedura guidata
Per avviare la procedura guidata per la ricerca vettoriale:
Accedere al portale di Azure e selezionare il servizio Ricerca intelligenza artificiale di Azure.
Nella pagina Panoramica selezionare Importa e vettorizza dati.

Selezionare l'origine dati: Archiviazione BLOB di Azure, ADLS Gen2 o OneLake.
Selezionare RAG.


Connettersi ai dati
Il passaggio successivo consiste nel connettersi a un'origine dati da usare per l'indice di ricerca.
Nella pagina Connetti ai dati specificare la sottoscrizione di Azure.
Selezionare l'account di archiviazione e il contenitore che forniscono i dati di esempio.
Se hai abilitato l'eliminazione temporanea e hai eventualmente aggiunto metadati personalizzati in Preparare i dati di esempio, seleziona la casella di controllo Abilita il tracciamento delle eliminazioni.
Nelle esecuzioni successive dell'indicizzazione, l'indice di ricerca viene aggiornato per rimuovere tutti i documenti di ricerca basati su blob eliminati logicamente su Azure Storage.
I BLOB supportano l'eliminazione temporanea di BLOB nativi o l'eliminazione temporanea usando metadati personalizzati.
Se hai configurato i tuoi BLOB per l'eliminazione temporanea, specifica la coppia nome-valore della proprietà dei metadati. Ti consigliamo IsDeleted. Se IsDeleted è impostato su true in un BLOB, l'indicizzatore elimina il documento di ricerca corrispondente nella successiva esecuzione dell'indicizzatore.
La procedura guidata non verifica la validità delle impostazioni di Archiviazione di Azure né genera un errore se i requisiti non sono soddisfatti. Al contrario, il rilevamento dell'eliminazione non funziona e l'indice di ricerca probabilmente raccoglierà documenti orfani nel corso del tempo.
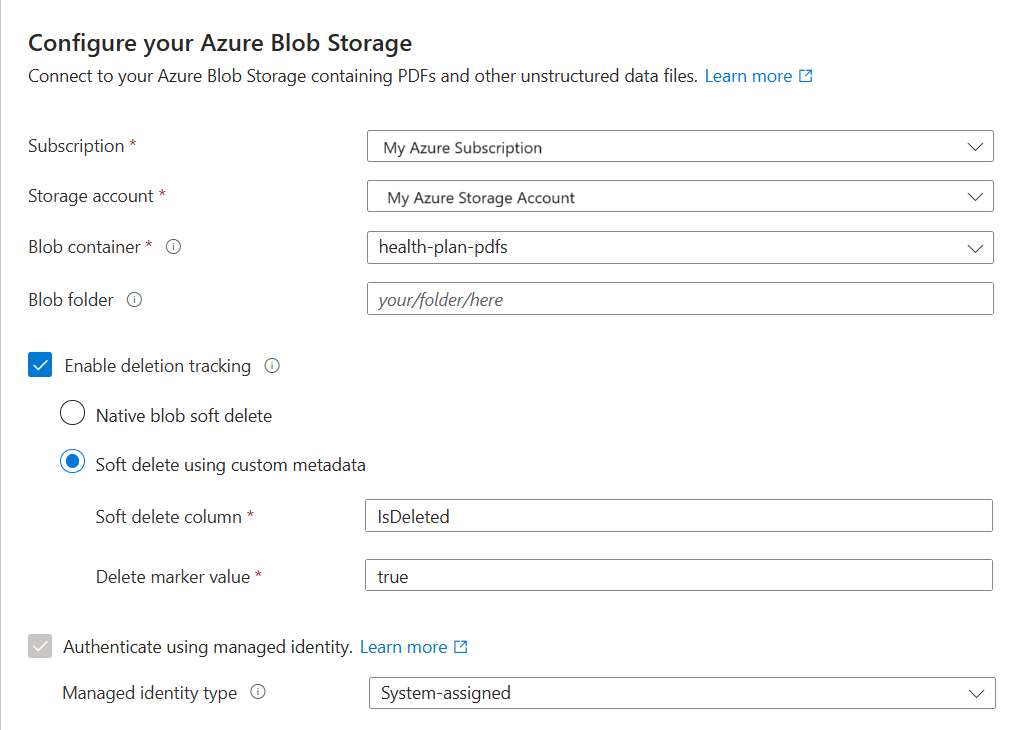
Selezionare la casella di controllo Autentica con identità gestita .
Per il tipo di identità gestita, selezionare Assegnata dal sistema.
L'identità deve avere un ruolo di lettore di dati BLOB di archiviazione in Archiviazione di Azure.
Non ignorare questo passaggio, Si verifica un errore di connessione durante l'indicizzazione se la procedura guidata non riesce a connettersi a Azure Storage.
Selezionare Avanti.
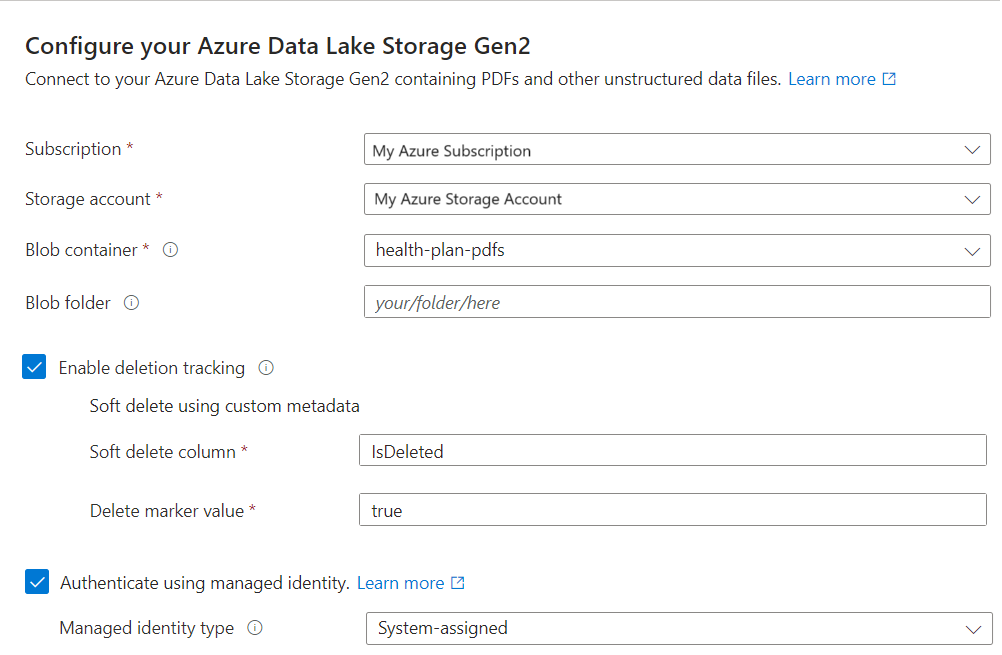
Vettorizzare il testo
In questo passaggio si specifica un modello di incorporamento per vettorizzare i dati in blocchi. La suddivisione in blocchi è incorporata e non configurabile. Le impostazioni valide sono:
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
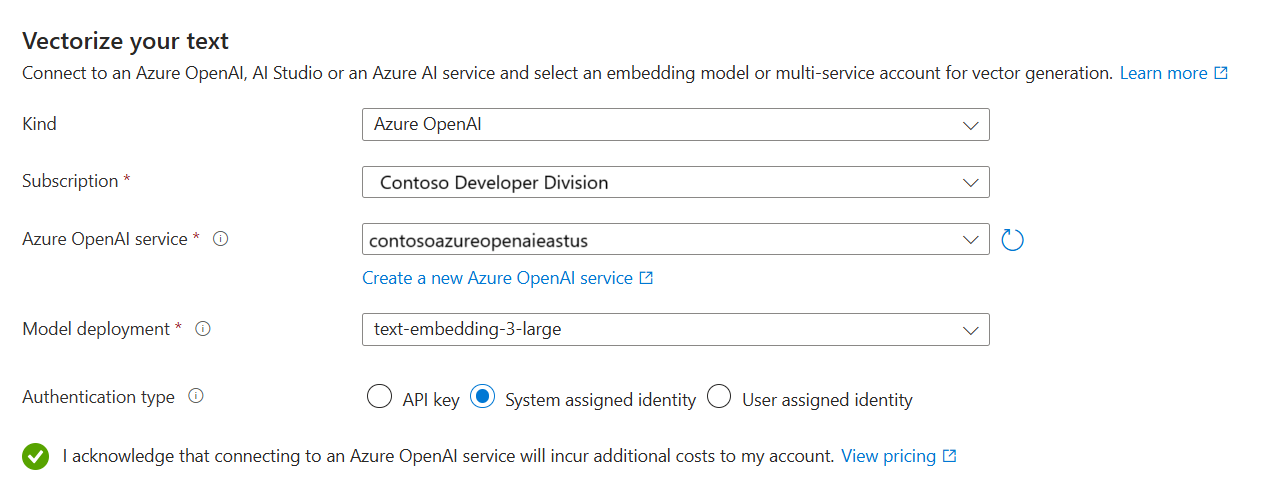
Nella pagina Vectorize your text (Vettorializza il testo ) selezionare l'origine del modello di incorporamento:
OpenAI di Azure
Catalogo dei modelli di Azure AI Foundry
Visione artificiale di Azure (tramite una risorsa multiservizio dei servizi di intelligenza artificiale di Azure nella stessa area di Ricerca di intelligenza artificiale di Azure)
Specificare la sottoscrizione di Azure.
A seconda della risorsa, effettuare la selezione seguente:
Per Azure OpenAI selezionare il modello distribuito in Preparare il modello di incorporamento.
Per il catalogo dei modelli di AI Foundry selezionare il modello distribuito in Preparare il modello di incorporamento.
Per gli incorporamenti in modalità multiservizio di Visione artificiale, selezionare la risorsa multiservizio.
Per il tipo di autenticazione selezionare Identità assegnata dal sistema.
- L'identità deve avere un ruolo Utente dei Servizi Cognitivi nella risorsa multi-servizio di Azure AI.
Selezionare la casella di controllo che riconosce gli effetti di fatturazione dell'uso di queste risorse.
Selezionare Avanti.
Vettorizzare e arricchire le immagini
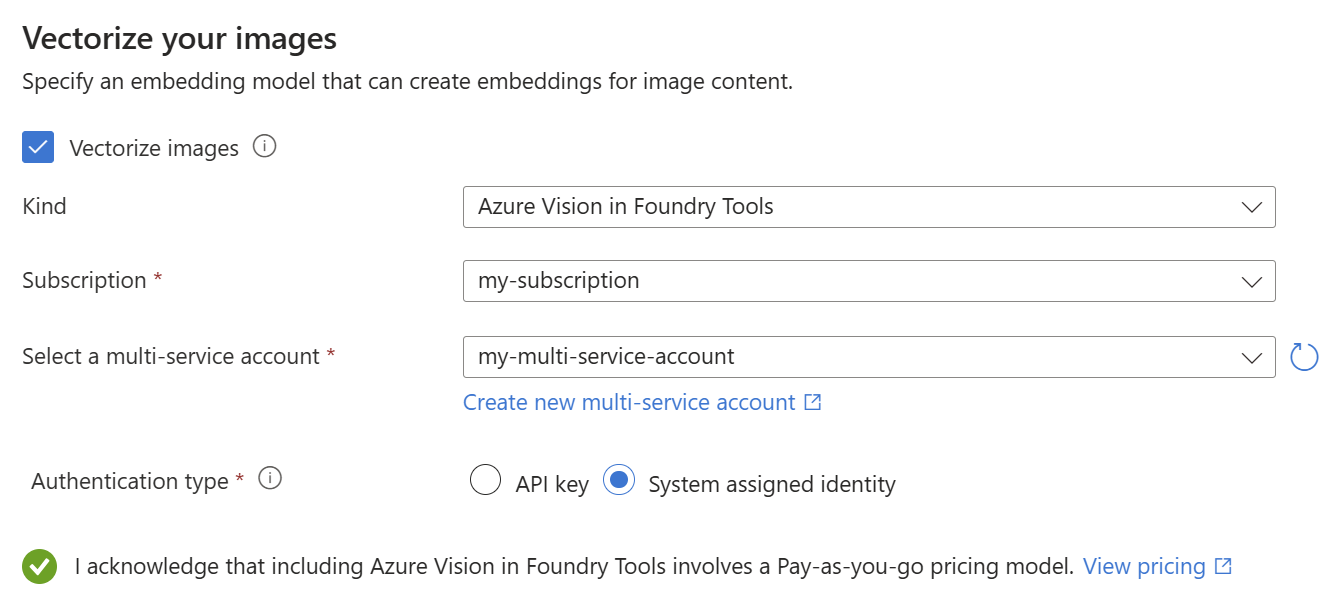
I PDF del piano sanitario includono un logo aziendale, ma per il resto, non sono presenti immagini. È possibile ignorare questo passaggio se si usano i documenti di esempio.
Tuttavia, se si usa contenuto che include immagini utili, è possibile applicare l'intelligenza artificiale in due modi:
Usare un modello di incorporamento di immagini supportato dal catalogo o dall'API di embedding multimodale di Visione AI di Azure per vettorizzare le immagini.
Usare il riconoscimento ottico dei caratteri (OCR) per riconoscere il testo nelle immagini. Questa opzione richiama la competenza OCR per leggere il testo dalle immagini.
Azure AI Search e le risorse di Intelligenza Artificiale di Azure devono trovarsi nella stessa area o essere configurate per connessioni di fatturazione senza chiave.
Nella pagina Vettorializza le immagini specificare il tipo di connessione che deve essere stabilita dalla procedura guidata. Per la vettorizzazione delle immagini, la procedura guidata può connettersi ai modelli di incorporamento nel portale di Azure AI Foundry o in Azure AI Vision.
Specificare la sottoscrizione.
Per il catalogo dei modelli di Azure AI Foundry, specificare il progetto e la distribuzione. Per altre informazioni, vedere Preparare i modelli di incorporamento.
(Facoltativo) Crackare immagini binarie, come file di documenti scansionati, e usa OCR per riconoscere il testo.
Selezionare la casella di controllo che riconosce gli effetti di fatturazione dell'uso di queste risorse.
Selezionare Avanti.
Aggiungi classificazione semantica
Nella pagina Impostazioni avanzate è possibile aggiungere facoltativamente la classificazione semantica per riclassificare i risultati alla fine dell'esecuzione della query. La riclassificazione propone per prime le corrispondenze più rilevanti dal punto di vista semantico.
Mappare nuovi campi
Punti chiave su questo passaggio:
Lo schema dell'indice fornisce campi vettoriali e non vettoriali per i dati suddivisi in blocchi.
È possibile aggiungere campi, ma non è possibile eliminare o modificare i campi generati.
La modalità di analisi dei documenti crea blocchi (un documento di ricerca per blocco).
Nella pagina Impostazioni avanzate è possibile aggiungere facoltativamente nuovi campi, presupponendo che l'origine dati fornisca metadati o campi che non vengono prelevati al primo passaggio. Per impostazione predefinita, la procedura guidata genera i campi descritti nella tabella seguente.
| Campo | Si applica a | Descrizione |
|---|---|---|
| chunk_id | Vettori di testo e immagine | Campo stringa generato. Ricercabile, recuperabile e ordinabile. Questa è la chiave del documento per l'indice. |
| parent_id | Vettori di testo | Campo stringa generato. Recuperabile e filtrabile. Identifica il documento padre da cui ha origine il blocco. |
| blocco | Vettori di testo e immagine | Campo stringa. Versione leggibile per gli esseri umani del blocco di dati. Ricercabile e recuperabile, ma non filtrabile, facetable o ordinabile. |
| titolo | Vettori di testo e immagine | Campo stringa. Titolo o numero di pagina leggibile del documento o della pagina. Ricercabile e recuperabile, ma non filtrabile, facetable o ordinabile. |
| vettore di testo | Vettori di testo | Collezione(Edm.single). Rappresentazione vettoriale del blocco. Ricercabile e recuperabile, ma non filtrabile, facetable o ordinabile. |
Non è possibile modificare i campi generati o i relativi attributi, ma è possibile aggiungere nuovi campi se l'origine dati li fornisce. Ad esempio, Archiviazione BLOB di Azure fornisce una raccolta di campi di metadati.
Selezionare Aggiungi campo.
Selezionare un campo di origine nei campi disponibili, immettere un nome di campo per l'indice e accettare (o eseguire l'override) del tipo di dati predefinito.
Nota
I campi dei metadati sono ricercabili, ma non recuperabili, filtrabili, visualizzabili o ordinabili.
Se si vuole ripristinare lo schema nella versione originale, selezionare Reimposta.
Pianificare l'indicizzazione
Nella pagina Impostazioni avanzate è anche possibile specificare una pianificazione di esecuzione facoltativa per l'indicizzatore. Dopo aver scelto un intervallo dall'elenco a discesa, selezionare Avanti.
Completare la procedura guidata
Nella pagina Verifica la configurazione specificare un prefisso per gli oggetti creati dalla procedura guidata. Un prefisso comune consente di rimanere organizzati.
Seleziona Crea.
Al termine della configurazione, la procedura guidata crea gli oggetti seguenti:
Connessione a una fonte di dati.
Indice con campi vettoriali, vettorizzatori, profili vettoriali e algoritmi vettoriali. Non è possibile progettare o modificare l'indice predefinito durante il flusso di lavoro della procedura guidata. Gli indici sono conformi all'API REST 2024-05-01-preview.
Set di competenze con la competenza Divisione testo per la suddivisione in blocchi e una competenza di incorporamento per la vettorializzazione. La competenza di incorporamento è la competenza AzureOpenAIEmbeddingModel per Azure OpenAI o la competenza AML per il catalogo dei modelli di Azure AI Foundry. Il set di abilità include anche la configurazione delle proiezioni di indice che mappa i dati di un documento nell'origine dati ai blocchi corrispondenti in un indice "figlio".
Indicizzatore con mapping dei campi e mapping dei campi di output (se applicabile).
Suggerimento
Gli oggetti creati dalla procedura guidata hanno definizioni JSON configurabili. Per visualizzare o modificare queste definizioni, selezionare Gestione ricerche nel riquadro sinistro, in cui è possibile visualizzare gli indici, gli indicizzatori, le origini dati e i set di competenze.
Controllare i risultati
Explorer di ricerca accetta stringhe di testo come input e successivamente vettorializza il testo per l'esecuzione di query vettoriali.
Nel portale di Azure, passare a Gestione ricerca>Indici, e quindi selezionare il tuo indice.
Selezionare Opzioni query e quindi selezionare Nascondi valori vettoriali nei risultati della ricerca. Questo passaggio rende i risultati più leggibili.
Dal menu Visualizza selezionare Visualizzazione JSON in modo da poter immettere testo per la query vettoriale nel parametro di
textquery vettoriale.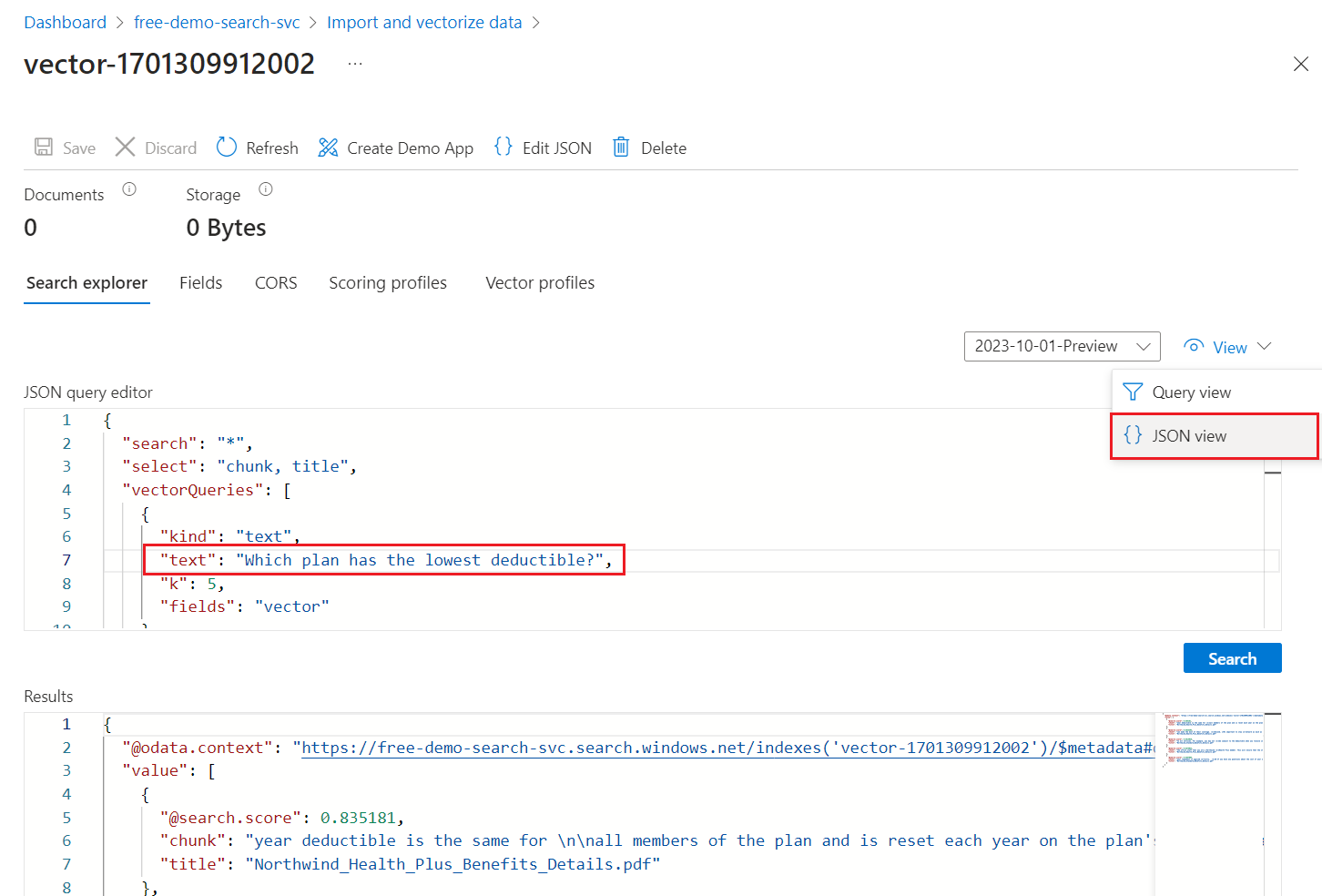
La query predefinita è una ricerca vuota (
"*"), ma include parametri per la restituzione delle corrispondenze di numero. Si tratta di una query ibrida che esegue query di testo e vettoriali in parallelo. Include anche la classificazione semantica e specifica i campi da restituire nei risultati tramite l'istruzioneselect.{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }Sostituire entrambi i segnaposto asterisco (
*) con una domanda correlata ai piani sanitari, ad esempioWhich plan has the lowest deductible?.{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }Per eseguire la query, selezionare Cerca.
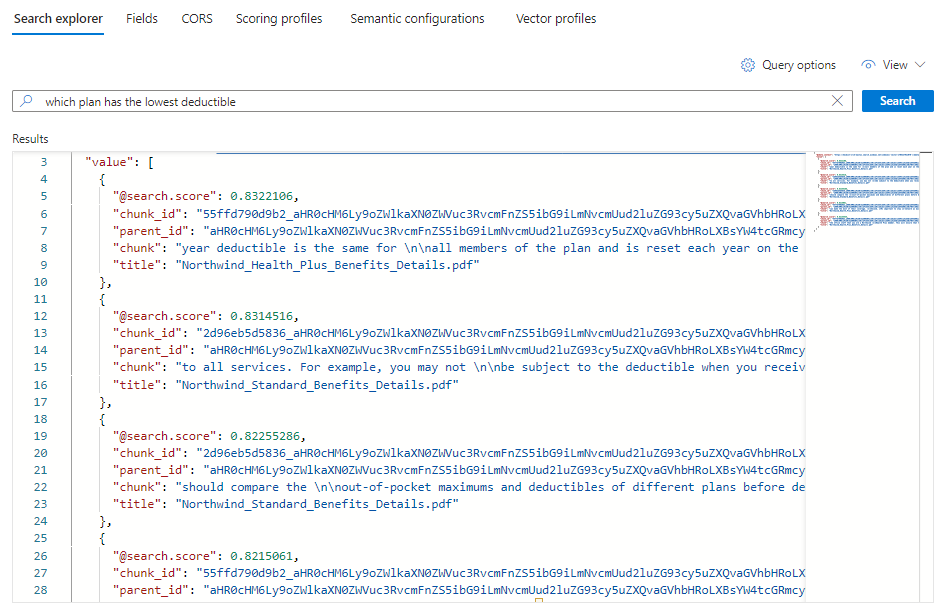
Ogni documento è un blocco del PDF originale. Il campo
titlemostra il file PDF da cui proviene il blocco. Ognunochunkè lungo. È possibile copiare e incollarne uno in un editor di testo per leggere l'intero valore.Per visualizzare tutti i blocchi di un documento specifico, aggiungere un filtro per il
title_parent_idcampo per un PDF specifico. È possibile controllare la scheda Campi dell'indice per verificare che il campo sia filtrabile.{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }
Eseguire la pulizia
Azure AI Search è una risorsa fatturabile. Se non è più necessario, eliminarlo dalla sottoscrizione per evitare addebiti.
Passaggio successivo
In questa guida introduttiva è stata presentata la procedura guidata Importa e vettorizza dati, che crea tutti gli oggetti necessari per la vettorializzazione integrata. Per esplorare in dettaglio ogni passaggio, vedere Configurare la vettorizzazione integrata in Ricerca di intelligenza artificiale di Azure.