2 - Creare e caricare l'indice di ricerca con Python
Continuare a compilare il sito Web abilitato per la ricerca seguendo questa procedura:
- Creare una risorsa di ricerca
- Creare un nuovo indice
- Importare dati con Python usando lo script di esempio e Azure SDK azure-search-documents.
Creare una risorsa di Ricerca intelligenza artificiale di Azure
Creare una nuova risorsa di ricerca dalla riga di comando usando l'interfaccia della riga di comando di Azure o Azure PowerShell. È anche possibile recuperare una chiave di query usata per l'accesso in lettura all'indice e ottenere la chiave di amministrazione predefinita usata per l'aggiunta di oggetti.
È necessario che nel dispositivo sia installata l'interfaccia della riga di comando di Azure o Azure PowerShell . Se non si è un amministratore locale nel dispositivo, scegliere Azure PowerShell e usare il Scope parametro per l'esecuzione come utente corrente.
Nota
Questa attività non richiede le estensioni di Visual Studio Code per l'interfaccia della riga di comando di Azure e Azure PowerShell. Visual Studio Code riconosce gli strumenti da riga di comando senza le estensioni.
In Terminale in Visual Studio Code selezionare Nuovo terminale.
Connessione ad Azure:
az loginPrima di creare un nuovo servizio di ricerca, elencare i servizi esistenti per la sottoscrizione:
az resource list --resource-type Microsoft.Search/searchServices --output tableSe si dispone di un servizio che si vuole usare, prendere nota del nome e quindi passare alla sezione successiva.
Creare un nuovo servizio di ricerca. Usare il comando seguente come modello, sostituendo valori validi per il gruppo di risorse, il nome del servizio, il livello, l'area, le partizioni e le repliche. L'istruzione seguente usa il gruppo di risorse "cognitive-search-demo-rg" creato in un passaggio precedente e specifica il livello "gratuito". Se la sottoscrizione di Azure ha già un servizio di ricerca gratuito, specificare invece un livello fatturabile, ad esempio "basic".
az search service create --name my-cog-search-demo-svc --resource-group cognitive-search-demo-rg --sku free --partition-count 1 --replica-count 1Ottenere una chiave di query che concede l'accesso in lettura a un servizio di ricerca. Viene effettuato il provisioning di un servizio di ricerca con due chiavi di amministrazione e una chiave di query. Sostituire i nomi validi per il gruppo di risorse e il servizio di ricerca. Copiare la chiave di query in Blocco note in modo da poterla incollare nel codice client in un passaggio successivo:
az search query-key list --resource-group cognitive-search-demo-rg --service-name my-cog-search-demo-svcOttenere una chiave API dell'amministratore del servizio di ricerca. Una chiave API amministratore fornisce l'accesso in scrittura al servizio di ricerca. Copiare una delle chiavi di amministrazione in Blocco note in modo che sia possibile usarla nel passaggio di importazione bulk che crea e carica un indice:
az search admin-key show --resource-group cognitive-search-demo-rg --service-name my-cog-search-demo-svc
Preparare lo script di importazione bulk per la ricerca
Lo script usa Azure SDK per Ricerca intelligenza artificiale di Azure:
In Visual Studio Code aprire il
bulk_upload.pyfile nella sottodirectory ,search-website-functions-v4/bulk-uploadsostituire le variabili seguenti con i propri valori per l'autenticazione con Azure Search SDK:- YOUR-edizione Standard ARCH-edizione Standard RVICE-NAME
- YOUR-edizione Standard ARCH-edizione Standard RVICE-ADMIN-API-KEY
import sys import json import requests import pandas as pd from azure.core.credentials import AzureKeyCredential from azure.search.documents import SearchClient from azure.search.documents.indexes import SearchIndexClient from azure.search.documents.indexes.models import SearchIndex from azure.search.documents.indexes.models import ( ComplexField, CorsOptions, SearchIndex, ScoringProfile, SearchFieldDataType, SimpleField, SearchableField, ) # Get the service name (short name) and admin API key from the environment service_name = "YOUR-SEARCH-SERVICE-NAME" key = "YOUR-SEARCH-SERVICE-ADMIN-API-KEY" endpoint = "https://{}.search.windows.net/".format(service_name) # Give your index a name # You can also supply this at runtime in __main__ index_name = "good-books" # Search Index Schema definition index_schema = "./good-books-index.json" # Books catalog books_url = "https://raw.githubusercontent.com/Azure-Samples/azure-search-sample-data/main/good-books/books.csv" batch_size = 1000 # Instantiate a client class CreateClient(object): def __init__(self, endpoint, key, index_name): self.endpoint = endpoint self.index_name = index_name self.key = key self.credentials = AzureKeyCredential(key) # Create a SearchClient # Use this to upload docs to the Index def create_search_client(self): return SearchClient( endpoint=self.endpoint, index_name=self.index_name, credential=self.credentials, ) # Create a SearchIndexClient # This is used to create, manage, and delete an index def create_admin_client(self): return SearchIndexClient(endpoint=endpoint, credential=self.credentials) # Get Schema from File or URL def get_schema_data(schema, url=False): if not url: with open(schema) as json_file: schema_data = json.load(json_file) return schema_data else: data_from_url = requests.get(schema) schema_data = json.loads(data_from_url.content) return schema_data # Create Search Index from the schema # If reading the schema from a URL, set url=True def create_schema_from_json_and_upload(schema, index_name, admin_client, url=False): cors_options = CorsOptions(allowed_origins=["*"], max_age_in_seconds=60) scoring_profiles = [] schema_data = get_schema_data(schema, url) index = SearchIndex( name=index_name, fields=schema_data["fields"], scoring_profiles=scoring_profiles, suggesters=schema_data["suggesters"], cors_options=cors_options, ) try: upload_schema = admin_client.create_index(index) if upload_schema: print(f"Schema uploaded; Index created for {index_name}.") else: exit(0) except: print("Unexpected error:", sys.exc_info()[0]) # Convert CSV data to JSON def convert_csv_to_json(url): df = pd.read_csv(url) convert = df.to_json(orient="records") return json.loads(convert) # Batch your uploads to Azure Search def batch_upload_json_data_to_index(json_file, client): batch_array = [] count = 0 batch_counter = 0 for i in json_file: count += 1 batch_array.append( { "id": str(i["book_id"]), "goodreads_book_id": int(i["goodreads_book_id"]), "best_book_id": int(i["best_book_id"]), "work_id": int(i["work_id"]), "books_count": i["books_count"] if i["books_count"] else 0, "isbn": str(i["isbn"]), "isbn13": str(i["isbn13"]), "authors": i["authors"].split(",") if i["authors"] else None, "original_publication_year": int(i["original_publication_year"]) if i["original_publication_year"] else 0, "original_title": i["original_title"], "title": i["title"], "language_code": i["language_code"], "average_rating": int(i["average_rating"]) if i["average_rating"] else 0, "ratings_count": int(i["ratings_count"]) if i["ratings_count"] else 0, "work_ratings_count": int(i["work_ratings_count"]) if i["work_ratings_count"] else 0, "work_text_reviews_count": i["work_text_reviews_count"] if i["work_text_reviews_count"] else 0, "ratings_1": int(i["ratings_1"]) if i["ratings_1"] else 0, "ratings_2": int(i["ratings_2"]) if i["ratings_2"] else 0, "ratings_3": int(i["ratings_3"]) if i["ratings_3"] else 0, "ratings_4": int(i["ratings_4"]) if i["ratings_4"] else 0, "ratings_5": int(i["ratings_5"]) if i["ratings_5"] else 0, "image_url": i["image_url"], "small_image_url": i["small_image_url"], } ) # In this sample, we limit batches to 1000 records. # When the counter hits a number divisible by 1000, the batch is sent. if count % batch_size == 0: client.upload_documents(documents=batch_array) batch_counter += 1 print(f"Batch sent! - #{batch_counter}") batch_array = [] # This will catch any records left over, when not divisible by 1000 if len(batch_array) > 0: client.upload_documents(documents=batch_array) batch_counter += 1 print(f"Final batch sent! - #{batch_counter}") print("Done!") if __name__ == "__main__": start_client = CreateClient(endpoint, key, index_name) admin_client = start_client.create_admin_client() search_client = start_client.create_search_client() schema = create_schema_from_json_and_upload( index_schema, index_name, admin_client, url=False ) books_data = convert_csv_to_json(books_url) batch_upload = batch_upload_json_data_to_index(books_data, search_client) print("Upload complete")Aprire un terminale integrato in Visual Studio per la sottodirectory della directory del progetto ed
search-website-functions-v4/bulk-uploadeseguire il comando seguente per installare le dipendenze.python3 -m pip install -r requirements.txt
Eseguire lo script di importazione bulk per la ricerca
Continuare a usare il terminale integrato in Visual Studio per la sottodirectory della directory del progetto,
search-website-functions-v4/bulk-upload, per eseguire il comando bash seguente per eseguire lobulk_upload.pyscript:python3 bulk-upload.pyDurante l'esecuzione del codice, nella console viene visualizzato lo stato di avanzamento.
Al termine del caricamento, l'ultima istruzione stampata nella console è "Done! Caricamento completato".
Esaminare il nuovo indice di ricerca
Al termine del caricamento, l'indice di ricerca è pronto per l'uso. Esaminare il nuovo indice in portale di Azure.
In portale di Azure trovare il servizio di ricerca creato nel passaggio precedente.
A sinistra selezionare Indici e quindi selezionare l'indice dei libri validi.
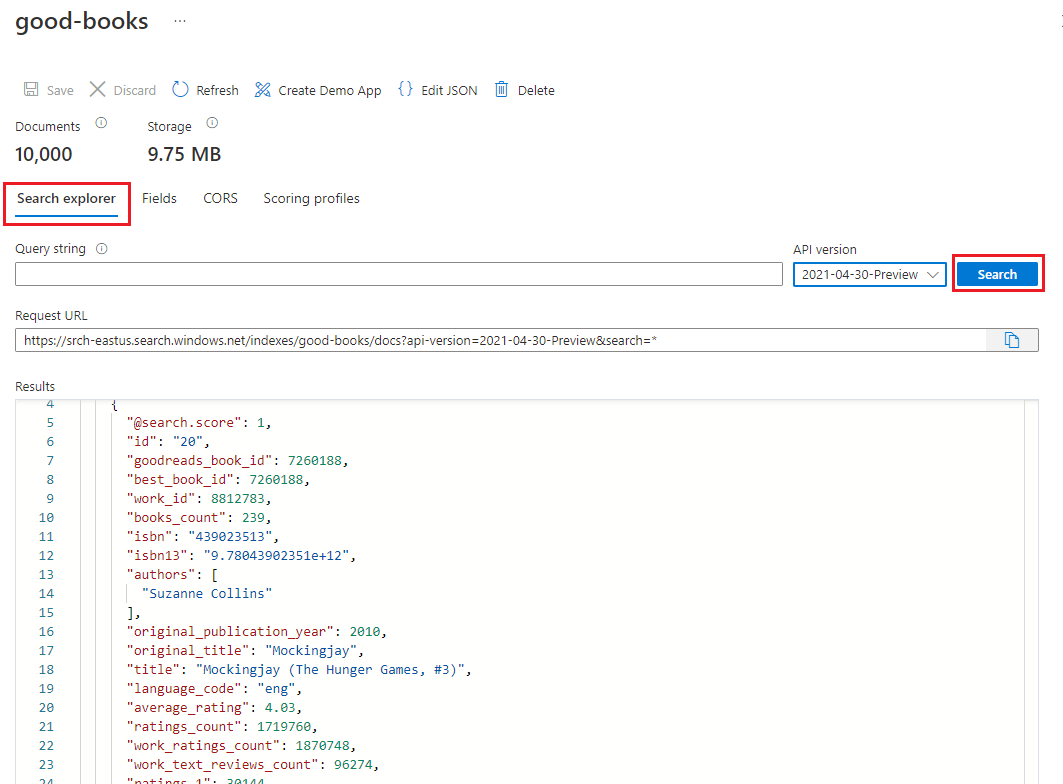
Per impostazione predefinita, l'indice viene aperto nella scheda Esplora ricerche . Selezionare Cerca per restituire documenti dall'indice.


Rollback delle modifiche al file di importazione bulk
Usare il comando git seguente nel terminale integrato di Visual Studio Code nella bulk-insert directory per eseguire il rollback delle modifiche. Non sono necessari per continuare l'esercitazione e non è consigliabile salvare o eseguire il push di questi segreti nel repository.
git checkout .
Copiare il nome della risorsa di ricerca
Prendere nota del nome della risorsa di ricerca. È necessario per connettere l'app per le funzioni di Azure alla risorsa di ricerca.
Attenzione
Anche se si potrebbe essere tentati di usare la chiave di amministrazione della ricerca nella funzione di Azure, questo non segue il principio dei privilegi minimi. La funzione di Azure userà la chiave di query per conformarsi ai privilegi minimi.