Blocchi di documenti di grandi dimensioni per soluzioni di ricerca vettoriale in Azure AI Search
Il partizionamento di documenti di grandi dimensioni in blocchi più piccoli consente di rimanere al di sotto dei limiti massimi di input dei token dei modelli di incorporamento. Ad esempio, la lunghezza massima del testo di input per il modello text-embedding-ada-002 di Azure OpenAI è di 8.191 token. Dato che ogni token è composto da circa quattro caratteri di testo per i modelli OpenAI comuni, questo limite massimo equivale a circa 6.000 parole di testo. Se si usano questi modelli per generare incorporamenti, è fondamentale che il testo di input rimanga al di sotto del limite. Il partizionamento del contenuto in blocchi garantisce che i dati possano essere elaborati dai modelli di incorporamento e che non si perdano informazioni a causa del troncamento.
È consigliabile usare la vettorizzazione integrata per la suddivisione in blocchi e l'incorporamento dei dati predefiniti. La vettorizzazione integrata dipende da indicizzatori, set di competenze, dalla competenza Divisione testo e da una competenza di incorporamento come azure OpenAI Embedding. Se non è possibile usare la vettorizzazione integrata, questo articolo descrive alcuni approcci per la suddivisione in blocchi del contenuto.
Tecniche comuni di suddivisione in blocchi
La suddivisione in blocchi è necessaria solo se i documenti di origine sono troppo grandi per le dimensioni massime di input imposte dai modelli.
Ecco alcune tecniche comuni di suddivisione in blocchi, a partire dal metodo più diffuso:
Blocchi a dimensione fissa: definire una dimensione fissa sufficiente per i paragrafi semanticamente significativi (ad esempio 200 parole) che consenta una certa sovrapposizione (ad esempio il 10-15% del contenuto) per produrre blocchi validi come input per i generatori di vettori di incorporamento.
Blocchi di dimensioni variabili in base al contenuto: partizionare i dati in base alle caratteristiche del contenuto, ad esempio segni di punteggiatura di fine frase, marcatori di fine riga o usare funzionalità nelle librerie NLP (elaborazione del linguaggio naturale). È anche possibile usare la struttura del linguaggio Markdown per suddividere i dati.
Personalizzare o eseguire l'iterazione su una delle tecniche precedenti. Ad esempio, quando si gestiscono documenti di grandi dimensioni, è possibile usare blocchi di dimensioni variabili, ma anche aggiungere anche il titolo del documento a blocchi dal centro del documento per evitare la perdita di contesto.
Considerazioni sulla sovrapposizione del contenuto
Quando si suddividono in blocchi i dati, la sovrapposizione di una piccola quantità di testo tra blocchi può contribuire a mantenere il contesto. È consigliabile iniziare con una sovrapposizione di circa il 10%. Ad esempio, data una dimensione di blocco fissa di 256 token, si inizierebbe a testare con una sovrapposizione di 25 token. La quantità effettiva di sovrapposizione varia a seconda del tipo di dati e del caso d'uso specifico, ma è stato rilevato che il 10-15% funziona per molti scenari.
Fattori per la suddivisione in blocchi dei dati
Quando si tratta di creare una suddivisione in blocchi dei dati, considerare questi fattori:
Forma e densità dei documenti. Se sono necessari testo o passaggi intatti, blocchi di dimensioni maggiori e una suddivisione in blocchi variabili che conservano la struttura delle frasi possono produrre risultati migliori.
Query utente: blocchi più grandi e strategie sovrapposte consentono di preservare il contesto e la ricchezza semantica per le query destinate a informazioni specifiche.
I modelli di linguaggio di grandi dimensioni (LLM) hanno linee guida sulle prestazioni per le dimensioni dei blocchi. è necessario impostare una dimensione di blocco ottimale per tutti i modelli in uso. Ad esempio, se si usano modelli per il riepilogo e gli incorporamenti, scegliere una dimensione di blocco ottimale che funzioni per entrambi.
Come la suddivisione in blocchi rientra nel flusso di lavoro
Se si dispone di documenti di grandi dimensioni, è necessario inserire un passaggio di suddivisione in blocchi nei flussi di lavoro di indicizzazione e query che suddivida il testo di grandi dimensioni. Quando si usa l< vettorizzazione integrata, viene applicata una strategia di suddivisione in blocchi predefinita usando la competenza di suddivisione testo. È anche possibile applicare una strategia di suddivisione in blocchi personalizzata usando una competenza personalizzata. Alcune librerie che offrono la suddivisione in blocchi includono:
La maggior parte delle librerie fornisce tecniche comuni di suddivisione in blocchi per dimensioni fisse, dimensioni variabili o una combinazione. È anche possibile specificare una sovrapposizione che duplica una piccola quantità di contenuto in ogni blocco per la conservazione del contesto.
Esempi di suddivisione in blocchi
Gli esempi seguenti illustrano come vengono applicate strategie di suddivisione in blocchi al file PDF NASA's Earth at Night e-book :
Esempio di competenza Dividi testo
La suddivisione dei dati integrata tramite la competenza di suddivisione del testo è disponibile a livello generale.
Questa sezione descrive la suddivisione in blocchi di dati predefiniti usando un approccio basato sulle competenze e i parametri delle competenze di suddivisione del testo.
Un notebook di esempio per questo esempio è disponibile nel repository azure-search-vector-samples.
Impostare textSplitMode per suddividere il contenuto in blocchi più piccoli:
pages(impostazione predefinita). I blocchi sono costituiti da più frasi.sentences. I blocchi sono costituiti da singole frasi. Ciò che costituisce una "frase" dipende dalla lingua. In inglese viene usata la punteggiatura di fine frase standard, ad esempio.o!. Il linguaggio è controllato dal parametrodefaultLanguageCode.
Il parametro pages aggiunge parametri aggiuntivi:
maximumPageLengthdefinisce il numero massimo di caratteri 1 o token 2 in ogni blocco. Il separatore di testo evita di suddividere le frasi, quindi il conteggio effettivo dei caratteri dipende dal contenuto.pageOverlapLengthdefinisce il numero di caratteri dalla fine della pagina precedente inclusi all'inizio della pagina successiva. Se impostato, deve essere inferiore alla metà della lunghezza massima della pagina.maximumPagesToTakedefinisce il numero di pagine/blocchi da acquisire da un documento. Il valore predefinito è 0, ovvero l'acquisizione di tutte le pagine o blocchi dal documento.
1 I caratteri non sono allineati alla definizione di un token. Il numero di token misurati dall'LLM potrebbe essere diverso dalle dimensioni del carattere misurate dalla competenza Suddivisione testo.
2 La suddivisione in blocchi dei token è disponibile nell'anteprima 2024-09-01 e include parametri aggiuntivi per specificare un tokenizer e tutti i token che non devono essere suddivisi durante la suddivisione in blocchi.
La tabella seguente mostra come la scelta dei parametri influisce sul numero totale di blocchi dall'e-book Earth at Night:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Totale conteggio blocchi |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
N/D | N/D | 13361 |
L'uso di un textSplitMode di pages comporta la maggior parte dei blocchi con conteggi totali dei caratteri vicini a maximumPageLength. Il numero di caratteri blocchi varia a causa delle differenze in base alla posizione in cui i limiti delle frasi rientrano all'interno del blocco. La lunghezza del token di blocco varia a causa delle differenze nel contenuto del blocco.
Gli istogrammi seguenti mostrano in che modo la distribuzione della lunghezza del carattere di blocco viene confrontata con la lunghezza del token di blocco per gpt-35-turbo quando si usa un textSplitMode di pages, un maximumPageLength di 2000 e un pageOverlapLength di 500 nell'e-book Earth at Night:

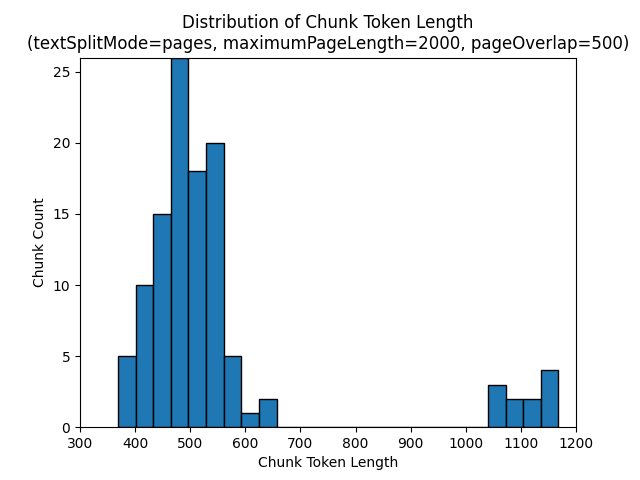
L'uso di una textSplitMode di sentences comporta un numero elevato di blocchi costituiti da singole frasi. Questi blocchi sono significativamente più piccoli di quelli prodotti da pages e il numero di token dei blocchi corrisponde più strettamente ai conteggi dei caratteri.
Gli istogrammi seguenti mostrano in che modo la distribuzione della lunghezza del carattere di blocco viene confrontata con la lunghezza del token di blocco per gpt-35-turbo quando si usa un textSplitMode di sentences nell'e-book Earth at Night:


La scelta ottimale dei parametri dipende dal modo in cui verranno usati i blocchi. Per la maggior parte delle applicazioni, è consigliabile iniziare con i parametri predefiniti seguenti:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
Esempio di suddivisione in blocchi di dati LangChain
LangChain fornisce caricatori di documenti e separatori di testo. Questo esempio illustra come caricare un PDF, ottenere i conteggi dei token e configurare un separatore di testo. Il recupero dei conteggi dei token consente di prendere una decisione informata sul dimensionamento dei blocchi.
Un notebook di esempio per questo esempio è disponibile nel repository azure-search-vector-samples.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
L'output indica 200 documenti o pagine nel PDF.
Per ottenere un conteggio dei token stimato per queste pagine, usare TikToken.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
L'output indica che nessuna pagina ha zero token, che la lunghezza media del token per pagina è 189 token e che il numero massimo di token di qualsiasi pagina è 1.583.
Conoscere le dimensioni medie e massime del token permette di avere informazioni dettagliate sull'impostazione delle dimensioni dei blocchi. Anche se è possibile usare la raccomandazione standard di 2000 caratteri con una sovrapposizione di 500 caratteri, in questo caso è opportuno abbassare il valore in base al numero di token del documento di esempio. In effetti, l'impostazione di un valore di sovrapposizione troppo grande può comportare la mancata visualizzazione di sovrapposizioni.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
L'output per due blocchi consecutivi mostra il testo del primo blocco sovrapposto al secondo blocco. L'output viene modificato leggermente per la leggibilità.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Competenza personalizzata
Un esempio di generazione di blocchi e incorporamento a dimensione fissa illustra sia la generazione di blocchi che l'incorporamento vettoriale usando modelli di incorporamento di OpenAI di Azure. Questo esempio usa una competenza personalizzata di Azure AI Search nel repository Power Skills per eseguire il wrapping del passaggio di suddivisione in blocchi.