Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La suddivisione in livelli nel cloud, una funzionalità facoltativa di Sincronizzazione file di Azure, riduce la quantità di spazio di archiviazione locale necessaria mantenendo le prestazioni di un file server locale.
Quando si abilita questa funzionalità, archivia solo i file a cui si accede di frequente (ad accesso frequente) nel server locale. I file a cui si accede raramente (ad accesso sporadico) vengono suddivisi in spazio dei nomi (struttura di file e cartelle) e nel contenuto del file. Lo spazio dei nomi viene archiviato localmente e il contenuto del file viene archiviato in una condivisione file Azure nel cloud.
Quando un utente apre un file a livelli, Sincronizzazione file di Azure richiama facilmente i dati del file dalla condivisione file Azure.
Funzionamento del cloud a livelli
Il tiering del cloud funziona monitorando i modelli di accesso ai file e suddividendo i file in livelli in base a criteri definiti.
Criteri di suddivisione in livelli nel cloud
Quando si abilita il tiering del cloud, ci sono due criteri che è possibile impostare per informare Sincronizzazione file di Azure su quando eseguire la tierizzazione dei file freddi: i criteri di spazio libero volume e i criteri date.
Criterio spazio disponibile volume
Il criterio di spazio libero del volume indica a Sincronizzazione file di Azure di spostare i file meno utilizzati nel cloud quando viene utilizzata una determinata quantità di spazio sul disco locale.
Ad esempio, se la capacità del disco locale è 200 GiB e si vuole che almeno 40 GiB della capacità del disco locale rimangano sempre liberi, impostare i criteri di spazio disponibile sul volume su 20%. Lo spazio libero del volume si applica a livello di volume anziché a livello di singole directory o endpoint server.
Criteri di data
Con i criteri di data, i file ad accesso sporadico vengono archiviati a livelli nel cloud se l'utente non vi ha eseguito l'accesso (operazioni di lettura e scrittura) per un numero x di giorni specificato. Ad esempio, se si nota che i file che hanno superato i 15 giorni senza l'accesso sono in genere file di archiviazione, è consigliabile impostare i criteri di data su 15 giorni.
Per altri esempi sul funzionamento dei criteri relativi alla data e allo spazio libero del volume, consultare Scegliere i criteri di tiering cloud di Sincronizzazione file di Azure.
Deduplicazione dei dati di Windows Server
A partire da Windows Server 2016, la deduplicazione dei dati è supportata nei volumi in cui è abilitata la suddivisione in livelli cloud. Per altre informazioni, vedere Plan per una distribuzione Sincronizzazione file di Azure.
Mappa termica a livelli cloud
Sincronizzazione file di Azure monitora l'accesso ai file (operazioni di lettura e scrittura) nel tempo e assegna un punteggio di calore a ogni file in base alla frequenza di accesso al file. Usa questi punteggi per compilare una "mappa termica" dello spazio dei nomi in ogni endpoint server. Questa mappa termica è un elenco di tutti i file di sincronizzazione in una posizione con cloud a livelli abilitati, ordinati in base al punteggio di calore. I file che sono stati aperti di recente e a cui si accede frequentemente sono considerati caldi, mentre i file a cui si accede raramente e che non vengono aperti da tempo sono considerati freddi.
Per determinare la posizione relativa di un singolo file in tale mappa termica, il sistema utilizza il massimo dei timestamp, nell'ordine seguente: MAX (Ora ultima accesso, ora ultima modifica, ora di creazione).
In genere, l'ora dell'ultimo accesso viene rilevata e disponibile. Tuttavia, quando si crea un nuovo endpoint server con il tiering del cloud abilitato, non vi è stato abbastanza tempo per osservare l'accesso ai file. Se non esiste un'ora di accesso valida, viene invece usata l'ora dell'ultima modifica per valutare la posizione relativa nella mappa termica.
I criteri di data funzionano allo stesso modo. Senza l'ora dell'ultimo accesso, la politica della data agisce sull'ora dell'ultima modifica. Se non è disponibile, si ripiega sulla data di creazione di un file. Nel corso del tempo, il sistema osserva più richieste di accesso ai file e inizia automaticamente a usare l'ora dell'ultimo accesso autotracciato.
Annotazioni
La suddivisione del cloud in livelli non dipende dalla funzionalità NTFS per tenere traccia dell'ultimo orario di accesso. Questa funzionalità NTFS è disattivata per impostazione predefinita. A causa delle considerazioni sulle prestazioni, non è consigliabile abilitare manualmente questa funzionalità. Il cloud a livelli tiene traccia dell'ora dell'ultimo accesso separatamente.
Considerazioni sulla scelta di un criterio di suddivisione in livelli nel cloud
I file ad accesso sporadico a cui si accede meno frequentemente sono più adatti per essere file a livelli, perché il richiamo dei dati richiede il download dal cloud. Sincronizzazione file di Azure riserva 10% di memoria totale per rendere persistenti i richiami al disco. Se 60% di questa memoria riservata è in uso, i richiami non vengono salvati in modo permanente sul disco. Se nel sistema sono presenti un numero elevato di file a livelli e viene eseguito un numero elevato di accessi, il sistema potrebbe raggiungere una soglia di memoria. Questa situazione può causare un'uscita di dati imprevista, riduzione delle prestazioni di I/O, rallentamenti del sistema e blocchi.
Richiamo proattivo
Quando un file viene creato o modificato, è possibile richiamare in modo proattivo il file nei server specificati. Il richiamo proattivo rende il file nuovo o modificato prontamente disponibile per l'utilizzo in ogni server specificato.
Ad esempio, una società distribuita a livello globale ha succursali negli Stati Uniti e in India. Al mattino negli Stati Uniti, gli information worker creano una nuova cartella e file per un nuovo progetto e lavorano tutto il giorno su di esso. Sincronizzazione file di Azure sincronizza la cartella e i file con la condivisione file Azure (endpoint cloud), che funge da hub centrale tra tutti i server registrati. I lavoratori dell'informazione in India continueranno a lavorare al progetto nel loro fuso orario. Quando arrivano al mattino, il server locale Sincronizzazione file di Azure abilitato in India deve avere questi nuovi file disponibili localmente, in modo che il team indiano possa lavorare in modo efficiente da una cache locale. L'abilitazione del richiamo proattivo indica al server di scaricare i file non appena vengono modificati o creati nella condivisione file Azure, anziché attendere che un utente tenti di aprirli.
Se i file richiamati al server non sono necessari in locale, il richiamo non necessario può aumentare il traffico in uscita e i costi. Pertanto, abilitare il richiamo proattivo solo quando si sa che la precompilazione della cache di un server con modifiche recenti provenienti dal cloud avrà un effetto positivo sugli utenti o sulle applicazioni che usano i file su quel server.
L'abilitazione del richiamo proattivo potrebbe comportare un aumento dell'utilizzo della larghezza di banda sul server e potrebbe causare la propagazione aggressiva di altri contenuti relativamente nuovi sul server locale a causa dell'aumento dei file recuperati. A sua volta, la suddivisione in livelli potrebbe portare troppo presto a un numero maggiore di richiami se i file a livelli vengono considerati ad accesso frequente dai server.
Per altre informazioni sul richiamo proattivo, vedere Deploy Sincronizzazione file di Azure.
Confronto tra caching a più livelli e comportamento dei file memorizzati nella cache locale
La suddivisione a livelli nel cloud rappresenta la separazione tra lo spazio dei nomi (la gerarchia di file e cartelle e le proprietà dei file) e il contenuto dei file.
File a livelli
Per i file a livelli, le dimensioni del disco sono pari a zero perché il contenuto del file stesso non viene archiviato in locale. Quando un file è soggetto a tiering, il filtro del file system di Sincronizzazione file di Azure (StorageSync.sys) sostituisce il file localmente con un puntatore chiamato reparse point. Il punto reparse rappresenta un URL del file nella condivisione file Azure. Un file a livelli ha entrambi l'attributo offline e l'attributo FILE_ATTRIBUTE_RECALL_ON_DATA_ACCESS impostati in NTFS in modo che le applicazioni di terze parti possano identificare in sicurezza i file a livelli.
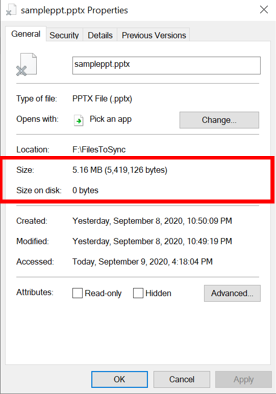
File memorizzato nella cache locale
Per i file archiviati in un file server locale, le dimensioni sul disco sono circa uguali alle dimensioni logiche del file, perché l'intero file (attributi di file e contenuto del file) viene archiviato localmente.
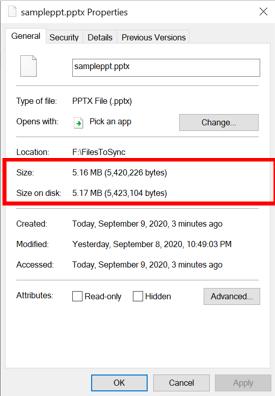
È anche possibile che un file venga suddiviso parzialmente in livelli o parzialmente richiamato. In un file parzialmente a livelli, solo parte del file viene archiviata su disco. È possibile che nel volume siano presenti dei file richiamati parzialmente se i file vengono letti parzialmente dalle applicazioni che supportano l'accesso in streaming ai file. Alcuni esempi sono i lettori multimediali e le utilità zip. Sincronizzazione file di Azure è efficiente e richiama solo le informazioni richieste dalla condivisione file Azure connessa.
Annotazioni
Size rappresenta le dimensioni logiche del file. Le dimensioni sul disco rappresentano le dimensioni fisiche del flusso di file archiviato sul disco.
Modalità spazio su disco insufficiente
I dischi con endpoint server possono esaurire spazio per vari motivi, anche quando è abilitata la suddivisione in livelli nel cloud. Di seguito sono elencati alcuni motivi per cui questa scelta è consigliabile:
- Copia manuale dei dati nel disco all'esterno del percorso dell'endpoint server
- Sincronizzazione lenta o ritardata che impedisce ai file di essere suddivisi in livelli
- Richiami eccessivi di file suddivisi in livelli
Quando si esaurisce lo spazio su disco, Sincronizzazione file di Azure potrebbe non funzionare correttamente e può anche diventare inutilizzabile. Anche se Sincronizzazione file di Azure non può impedire completamente queste occorrenze, la modalità spazio su disco insufficiente (disponibile nelle versioni dell'agente Sincronizzazione file di Azure a partire dalla versione 15.1) impedisce a un endpoint server di raggiungere questa situazione e aiuta il server a uscire più velocemente.
Per gli endpoint del server con tierizzazione cloud abilitata, se lo spazio disponibile sul volume scende al di sotto della soglia calcolata, il volume passa alla modalità di spazio su disco ridotto.
In modalità spazio su disco insufficiente, l'agente Sincronizzazione file di Azure esegue due operazioni in modo diverso:
Suddivisione in livelli proattivi: l'agente sincronizzazione file consente di archiviare i file in modo più proattivo nel cloud. L'agente di sincronizzazione verifica la presenza di file per il tiering ogni minuto anziché alla normale frequenza di ogni ora. La suddivisione in livelli dei criteri di spazio libero del volume in genere non viene eseguita durante la sincronizzazione del caricamento iniziale fino al completamento del caricamento completo. Tuttavia, in modalità spazio su disco insufficiente, la suddivisione in livelli viene abilitata durante la sincronizzazione del caricamento iniziale e i file vengono considerati per la suddivisione in livelli dopo il caricamento del singolo file nella condivisione file Azure.
Richiami non persistenti: quando un utente apre un file a livelli, i file richiamati dalla condivisione file Azure direttamente non vengono salvati in modo permanente sul disco. I richiami avviati dal
Invoke-StorageSyncFileRecallcmdlet sono un'eccezione a questa regola e vengono salvati in modo permanente su disco.
Quando lo spazio disponibile del volume supera la soglia, Sincronizzazione file di Azure ripristina automaticamente lo stato normale. La modalità di spazio su disco insufficiente si applica solo ai server con cloud tiering abilitato e rispetta sempre la politica di spazio libero sul volume.
Se un volume ha due endpoint server, uno con suddivisione in livelli abilitato e uno senza suddivisione in livelli, la modalità spazio su disco insufficiente si applica solo all'endpoint server in cui è abilitata la suddivisione in livelli.
Come viene calcolata la soglia per la modalità spazio su disco insufficiente?
Calcolare la soglia prendendo il minimo dei tre numeri seguenti:
- 10% delle dimensioni del volume in GiB
- Criteri di spazio libero del volume in GiB
- 20 GiB
La tabella seguente include alcuni esempi di come viene calcolata la soglia e quando il volume è in modalità spazio su disco insufficiente.
| Dimensioni del volume | 10% delle dimensioni del volume | Criterio spazio disponibile volume | Soglia = Min (10% della dimensione del volume, politica di spazio libero del volume, 20 GiB) | Spazio disponibile corrente nel volume | La modalità spazio su disco è insufficiente? | Motivo |
|---|---|---|---|---|---|---|
| 100 GiB | 10 GiB | 7% (7 GiB) | 7 GiB = Min (10 GiB, 7 GiB, 20 GiB) | 9% (9 GiB) | NO | Spazio disponibile corrente del volume (9 GiB) > Soglia (7 GiB) |
| 100 GiB | 10 GiB | 7% (7 GiB) | 7 GiB = Min (10 GiB, 7 GiB, 20 GiB) | 5% (5 GiB) | Sì | Soglia spazio disponibile volume corrente (5 GiB) < (7 GiB) |
| 300 GiB | 30 GiB | 8% (24 GiB) | 20 GiB = Min (30 GiB, 24 GiB, 20 GiB) | 7% (21 GB) | NO | Spazio disponibile corrente del volume (21 GiB) > Soglia (20 GiB) |
| 300 GiB | 30 GiB | 8% (24 GiB) | 20 GiB = Min (30 GiB, 24 GiB, 20 GiB) | 6% (18 GiB) | Sì | Spazio disponibile corrente del volume (18 GiB) < Soglia (20 GiB) |
Come funziona la modalità spazio su disco ridotto con la politica di spazio libero su volume?
La modalità a basso spazio su disco rispetta sempre la politica di spazio libero del volume. Il calcolo della soglia è progettato per assicurarsi che rispetti i criteri di spazio disponibile del volume impostati.
Qual è la causa più comune per la modalità disco insufficiente per l'endpoint server?
La causa principale della modalità disco insufficiente è la copia o lo spostamento di grandi quantità di dati nel disco in cui si trova un endpoint server abilitato per la suddivisione in livelli.
Come si esce dalla modalità spazio su disco insufficiente?
La modalità disco ridotto passa automaticamente al comportamento normale senza rendere permanenti i richiami e con un livello di frequenza maggiore dei file, senza richiedere alcun intervento da parte dell'utente. È possibile velocizzare manualmente il processo aumentando le dimensioni del volume o liberando spazio all'esterno dell'endpoint server.
Come è possibile verificare se un server è in modalità spazio su disco insufficiente?
- Se un endpoint server è in modalità spazio su disco insufficiente, il portale Azure lo visualizza nella scheda cloud tiering health della scheda Errors + troubleshooting dell'endpoint server.
- L'ID evento 19000 viene registrato nel registro eventi di telemetria ogni minuto per ogni endpoint server. Usare questo evento per determinare se l'endpoint server è in modalità spazio su disco insufficiente (IsLowDiskMode = true). È possibile trovare il registro eventi di telemetria in Visualizzatore eventi in
Applications and Services\Microsoft\FileSync\Agent.