Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
✔️ Si applica a: condivisioni file SMB e NFS classiche create con il provider di risorse Microsoft.Storage
✔️ Si applica a: Condivisioni file create con il provider di risorse Microsoft.FileShares (anteprima)
File di Azure può soddisfare i requisiti di prestazioni per la maggior parte delle applicazioni e dei casi d'uso. Questo articolo illustra i diversi fattori che possono influire sulle prestazioni delle condivisioni file e come ottimizzare le prestazioni delle condivisioni file di Azure per il carico di lavoro.
Glossario sulle prestazioni di archiviazione
Prima di leggere questo articolo, è utile comprendere alcuni termini chiave relativi alle prestazioni di archiviazione:
Operazioni di I/O al secondo (IOPS)
Le operazioni di I/O o input/output al secondo misurano il numero di operazioni del file system al secondo. Il termine "I/O" è intercambiabile con i termini "operazione" e "transazione" nella documentazione di File di Azure.
Dimensioni di I/O
Le dimensioni di I/O, talvolta definite dimensioni del blocco, sono le dimensioni della richiesta usata da un'applicazione per eseguire una singola operazione di input/output (I/O) nella risorsa di archiviazione. A seconda dell'applicazione, le dimensioni di I/O possono variare da dimensioni ridotte, ad esempio 4 KiB a dimensioni maggiori. Le dimensioni di I/O svolgono un ruolo importante nella velocità effettiva raggiungibile.
Velocità effettiva
La velocità effettiva misura il numero di bit letti o scritti nella risorsa di archiviazione al secondo ed è espressa in mebibyte al secondo (MiB/s). Per calcolare la velocità effettiva, moltiplicare le operazioni di I/O per le dimensioni di I/O. Ad esempio, 10.000 operazioni di I/O al secondo _ dimensioni di I/O di 1 MiB = 10 GiB/s, mentre 10.000 IOPS _ dimensioni di I/O di 4 KiB = 38 MiB/s.
Latency
La latenza è un sinonimo di ritardo e viene misurata in millisecondi (ms). Esistono due tipi di latenza: latenza end-to-end e latenza del servizio. Per altre informazioni, vedere Latenza.
Profondità della coda
La profondità della coda è il numero di richieste di I/O in sospeso che possono essere gestite contemporaneamente da una risorsa di archiviazione. Per altre informazioni, vedere Profondità della coda.
Scelta di un livello multimediale in base ai modelli di utilizzo
File di Azure offre due livelli di supporto di archiviazione che consentono di bilanciare le prestazioni e il prezzo: SSD e HDD. È possibile selezionare il livello multimediale della condivisione file a livello di account di archiviazione e, dopo aver creato un account di archiviazione in un determinato livello multimediale, non è possibile passare all'altro senza eseguire manualmente la migrazione a una nuova condivisione file.
Quando si sceglie tra condivisioni file SSD e HDD, è importante comprendere i requisiti del modello di utilizzo previsto che si prevede di eseguire in File di Azure. Se sono necessarie grandi quantità di operazioni di I/O al secondo, velocità di trasferimento dei dati veloci o bassa latenza, è consigliabile scegliere condivisioni file SSD.
La tabella seguente riepiloga gli obiettivi di prestazioni previsti tra le condivisioni file SSD e HDD. Per informazioni dettagliate, vedere Obiettivi di scalabilità e prestazioni di File di Azure.
| Requisiti del modello di utilizzo | SSD | HDD |
|---|---|---|
| Latenza di scrittura (millisecondi a cifra singola) | Sì | Sì |
| Latenza di lettura (millisecondi a cifra singola) | Sì | NO |
Le condivisioni file SSD offrono un modello di provisioning che garantisce il profilo di prestazioni seguente in base alle dimensioni della condivisione. Per altre informazioni, vedere il modello v1 con provisioning.
Migliori pratiche prestazionali
Se si valutano i requisiti di prestazioni per un carico di lavoro nuovo o esistente, la comprensione dei modelli di utilizzo consente di ottenere prestazioni prevedibili.
Sensibilità alla latenza: I carichi di lavoro sensibili alla latenza di lettura e con visibilità elevata per gli utenti finali sono più adatti per le condivisioni file SSD, che possono offrire una latenza nell'ordine di singoli millisecondi per le operazioni di lettura e scrittura (< 2 ms per dimensioni di I/O ridotte).
Requisiti di I/O al secondo e velocità effettiva: Le condivisioni file SSD supportano limiti di operazioni di I/O al secondo e velocità effettiva maggiori rispetto alle condivisioni file HDD. Per altre informazioni, vedere Obiettivi di scalabilità delle condivisioni file.
Durata e frequenza del carico di lavoro: I carichi di lavoro brevi (minuti) e non frequenti (orari) hanno meno probabilità di raggiungere i limiti di prestazioni superiori delle condivisioni file HDD rispetto ai carichi di lavoro a esecuzione prolungata. Nelle condivisioni file SSD, è utile considerarne la durata del carico di lavoro per determinare il profilo di prestazioni corretto da usare in base allo spazio di archiviazione, alle operazioni di I/O al secondo e alla velocità effettiva provisionata. Un errore comune consiste nell'eseguire test delle prestazioni solo per pochi minuti, con risultati spesso fuorvianti. Per ottenere una vista realistica delle prestazioni, assicurarsi di eseguire i test con una frequenza e una durata sufficientemente elevate.
Parallelizzazione del carico di lavoro: Per i carichi di lavoro che eseguono operazioni in parallelo, ad esempio tramite più thread, processi o istanze dell'applicazione nello stesso client, le condivisioni file SSD offrono un vantaggio chiaro rispetto alle condivisioni file HDD: SMB multicanale. Per altre informazioni, vedere Migliorare le prestazioni delle condivisioni file di Azure SMB.
Distribuzione delle operazioni API: i carichi di lavoro pesanti dei metadati, ad esempio i carichi di lavoro che eseguono operazioni di lettura su un numero elevato di file, rappresentano una soluzione migliore per le condivisioni file SSD. Vedere Carichi di lavoro intensi per metadati o spazi dei nomi.
Posizionamento di zona: usare il posizionamento di zona per selezionare la zona di disponibilità specifica in cui risiede l'account di archiviazione. In questo modo è possibile inserire le macchine virtuali nella stessa zona di disponibilità dell'archiviazione, riducendo la latenza fino al 30%. Questa funzionalità è attualmente disponibile solo per gli account di archiviazione SSD che usano l'archiviazione con ridondanza locale nelle aree supportate.
Latenza
Quando si pensa alla latenza, è importante comprendere innanzitutto come viene determinata la latenza con File di Azure. Le misurazioni più comuni sono la latenza associata alle metriche di latenza end-to-end e latenza del servizio. L'uso di queste metriche di transazione consente di identificare i problemi di latenza lato client e/o di rete determinando il tempo che il traffico dell'applicazione trascorre in transito da e verso il client.
La latenza end-to-end (SuccessE2ELatency) è il tempo totale necessario per eseguire un round trip completo dal client, attraverso la rete, al servizio File di Azure e di nuovo al client.
Latenza del servizio (SuccessServerLatency) è il tempo necessario affinché una transazione completi un ciclo solo all'interno di Azure Files. Ciò non include la latenza di rete o del client.
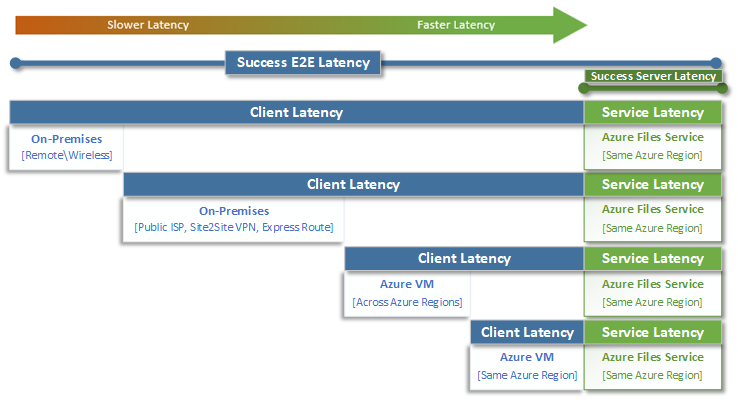
La differenza tra i valori SuccessE2ELatency e SuccessServerLatency è la latenza probabilmente causata dalla rete e/o dal client.
Spesso la latenza del client viene confusa con la latenza del servizio (in questo caso, con le prestazioni di File di Azure). Ad esempio, se la latenza del servizio segnala una bassa latenza e la latenza end-to-end segnala una latenza molto elevata per le richieste, ciò suggerisce che il transito si verifica sempre da e verso il client e non nel servizio File di Azure.
Inoltre, come illustrato nel diagramma, più lontano si sta lontano dal servizio, più lenta è l'esperienza di latenza e più difficile è raggiungere i limiti di scalabilità delle prestazioni con qualsiasi servizio cloud. Ciò è particolarmente vero quando si accede a File di Azure dall'ambiente locale. Sebbene le opzioni come ExpressRoute siano ideali per l'ambiente locale, non corrispondono ancora alle prestazioni di un'applicazione (calcolo e archiviazione) in esecuzione esclusivamente nella stessa area di Azure.
Suggerimento
L'uso di una macchina virtuale in Azure per testare le prestazioni tra l'ambiente locale e Azure è un modo efficace e pratico per applicare le funzionalità di rete della connessione ad Azure. I circuiti ExpressRoute sottodimensionati o instradati in modo non corretto o i gateway VPN possono rallentare significativamente i carichi di lavoro in esecuzione in File di Azure.
Profondità coda
La profondità della coda è il numero di richieste di I/O in sospeso che possono essere eseguite da una risorsa di archiviazione. Poiché i dischi usati dai sistemi di archiviazione si sono evoluti da spindle HDD (IDE, SATA, SAS) a dispositivi a stato solido (SSD, NVMe), possono supportare una maggiore profondità della coda. Un carico di lavoro costituito da un singolo client che interagisce serialmente con un singolo file all'interno di un set di dati di grandi dimensioni è un esempio di profondità ridotta della coda. Al contrario, un carico di lavoro che supporta il parallelismo con più thread e più file può raggiungere facilmente una profondità elevata della coda. Poiché File di Azure è un servizio file distribuito che si estende su migliaia di nodi del cluster di Azure ed è progettato per eseguire carichi di lavoro su larga scala, è consigliabile creare e testare carichi di lavoro con una profondità elevata della coda.
Ci sono diversi modi di raggiungere una profondità elevata della coda in combinazione con client, file e thread. Per determinare la profondità della coda per il carico di lavoro, moltiplicare il numero di client per il numero di file (client _ file _ thread = profondità della coda).
La tabella seguente illustra le varie combinazioni utilizzabili per ottenere una maggiore profondità della coda. Superare la profondità ottimale della coda, pari a 64, è una scelta possibile ma non consigliata. In tal caso, non si noterà un miglioramento delle prestazioni e si rischia di aumentare la latenza a causa della saturazione TCP.
| Client | File | Thread | Profondità della coda |
|---|---|---|---|
| 1 | 1 | 1 | 1 |
| 1 | 1 | 2 | 2 |
| 1 | 2 | 2 | 4 |
| 2 | 2 | 2 | 8 |
| 2 | 2 | 4 | 16 |
| 2 | 4 | 4 | 32 |
| 1 | 8 | 8 | 64 |
| 4 | 4 | 2 | 64 |
Suggerimento
Per ottenere limiti di prestazioni superiori, assicurarsi che il carico di lavoro o il test di benchmarking sia multithread con più file.
Applicazioni a thread singolo e multithread
File di Azure è più adatto per le applicazioni multithread. Il modo più semplice per comprendere l'impatto del multithreading sulle prestazioni per un carico di lavoro consiste nell'esaminare lo scenario tramite I/O. L'esempio seguente mostra un carico di lavoro che deve copiare 10.000 file di piccole dimensioni il più rapidamente possibile in o da una condivisione file di Azure.
Questa tabella suddivide il tempo necessario (in millisecondi) per creare un singolo file di 16 KiB in una condivisione file di Azure, in base a un'applicazione a thread singolo che scrive in dimensioni del blocco di 4 KiB.
| Operazione di I/O | Creare | Scrittura di 4 KiB | Scrittura di 4 KiB | Scrittura di 4 KiB | Scrittura di 4 KiB | Close | Totale |
|---|---|---|---|---|---|---|---|
| Thread 1 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
In questo esempio sono necessari circa 14 ms per creare un singolo file di 16 KiB da sei operazioni. Se un'applicazione a thread singolo vuole spostare 10.000 file in una condivisione file di Azure, ciò si traduce in 140.000 ms (14 ms * 10.000) o 140 secondi perché ogni file viene spostato in sequenza uno alla volta. Tenere presente che il tempo necessario per soddisfare ogni richiesta è determinato principalmente dalla prossimità tra calcolo e archiviazione, come illustrato nella sezione precedente.
Usando otto thread anziché uno, il carico di lavoro precedente può ridursi da 140.000 ms (140 secondi) fino a 17.500 ms (17,5 secondi). Come illustrato nella tabella seguente, quando si spostano otto file in parallelo anziché uno alla volta, è possibile spostare la stessa quantità di dati nell'87,5% di tempo in meno.
| Operazione di I/O | Creare | Scrittura di 4 KiB | Scrittura di 4 KiB | Scrittura di 4 KiB | Scrittura di 4 KiB | Close | Totale |
|---|---|---|---|---|---|---|---|
| Thread 1 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 2 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 3 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 4 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 5 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 6 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 7 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 8 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |