Modelli di progettazione tabella
Questo articolo descrive alcuni modelli adatti all'uso con le soluzioni di servizio tabelle. Fornisce inoltre informazioni su come risolvere alcuni dei problemi e dei compromessi illustrati negli altri articoli sulla progettazione dell'archiviazione tabelle. Il diagramma seguente contiene un riepilogo delle relazioni tra i diversi modelli:
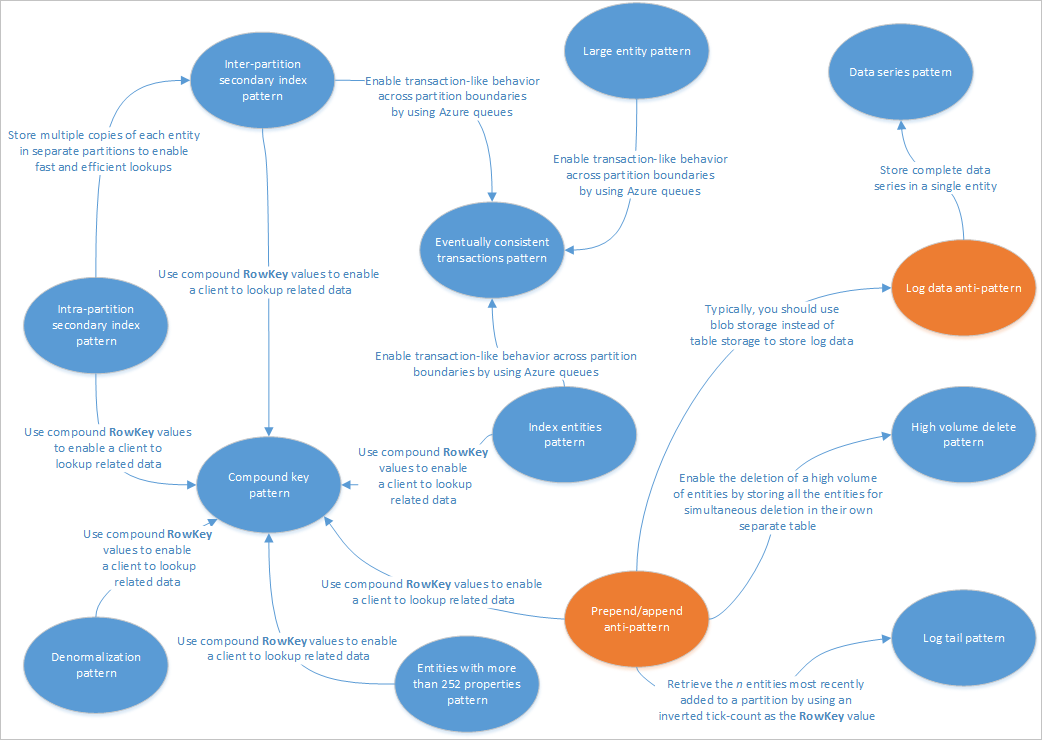
La mappa dei modelli nella figura precedente evidenzia alcune relazioni tra i modelli (blu) e gli anti-modelli (arancione) documentati in questa guida. Esistono molti altri modelli che vale la pena considerare. Ad esempio, uno degli scenari chiave per il servizio tabelle è l'uso del modello di vista materializzata dal modello Command Query Responsibility Segregation (CQRS).
Modello per indice secondario intrapartizione
Archivia più copie di ogni entità usando valori RowKey diversi (nella stessa partizione) per consentire ricerche rapide ed efficienti e ordinamenti alternativi usando valori RowKey diversi. Aggiornamenti tra copie possono essere mantenute coerenti usando transazioni EGT (Entity Group Transactions).
Contesto e problema
Il servizio tabelle indicizza automaticamente le entità usando i valori PartitionKey e RowKey. Questo consente a un'applicazione client di recuperare un'entità in modo efficiente mediante questi valori. Ad esempio, usando la struttura della tabella riportata di seguito, un'applicazione client può usare una query di tipo punto per recuperare una singola entità dipendente attraverso il nome del reparto e l'ID del dipendente (i valori PartitionKey e RowKey). Un client può anche recuperare entità ordinate per ID dipendente in ogni reparto.
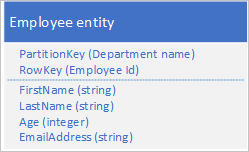
Se si desidera poter trovare un'entità dipendente anche in base al valore di un'altra proprietà, ad esempio l'indirizzo di posta elettronica, è necessario usare un'analisi della partizione meno efficiente per trovare una corrispondenza. Il motivo è che il servizio tabelle non fornisce indici secondari. Inoltre, non esiste un'opzione per richiedere un elenco di dipendenti ordinato in modo diverso rispetto all'ordine RowKey .
Soluzione
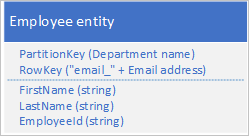
Per ovviare alla mancanza di indici secondari, è possibile archiviare più copie di ogni entità usando per ogni copia un valore RowKey diverso. Se si archivia un'entità con le strutture riportate di seguito, è possibile recuperare in modo efficiente entità dipendente in base all'ID dipendente o all'indirizzo di posta elettronica. I valori di prefisso per RowKey, "empid_" e "email_" consentono di eseguire query per un singolo dipendente o per un intervallo di dipendenti usando un intervallo di indirizzi di posta elettronica o ID dipendente.

I due criteri di filtro seguenti (uno che ricerca per ID dipendente e uno che ricerca per indirizzo di posta elettronica) specificano entrambi query di tipo punto:
- $filter=(PartitionKey eq 'Sales') e (RowKey eq 'empid_000223)
- $filter=(PartitionKey eq 'Sales') e (RowKey eq 'email_jonesj@contoso.com')
Se si esegue una query su un intervallo di entità dipendente, è possibile specificare un intervallo ordinato per ID dipendente o un intervallo ordinato per indirizzo di posta elettronica eseguendo la query sulle entità con il prefisso appropriato in RowKey.
Per trovare tutti i dipendenti nel reparto vendite con un ID dipendente compreso tra 000100 e 000199 usare: $filter=(PartitionKey eq 'Sales') and (RowKey ge 'empid_000100') and (RowKey le 'empid_000199')
Per trovare tutti i dipendenti del reparto vendite con un indirizzo di posta elettronica che inizia con la lettera "a" utilizzare: $filter = (PartitionKey eq "Sales") e (RowKey ge 'email_a') e (RowKey It'email_b')
La sintassi di filtro usata negli esempi precedenti proviene dall'API REST del servizio tabelle. Per altre informazioni, vedere Query Entities (Query su entità).
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
L'uso dell'archiviazione tabelle è relativamente economico, pertanto l'aumento dei costi dovuto all'archiviazione di dati duplicati non dovrebbe rappresentare una preoccupazione. È però consigliabile valutare sempre il costo del progetto in base ai requisiti di archiviazione previsti e aggiungere entità duplicate solo per supportare le query che verranno eseguite dall'applicazione client.
Poiché le entità di indice secondario vengono archiviate nella stessa partizione delle entità originali, è necessario assicurarsi di non superare gli obiettivi di scalabilità delle singole partizioni.
Per mantenere la coerenza tra entità duplicate è possibile usare transazioni ETG, che consentono di aggiornare le due copie dell'entità in modo atomico. A questo scopo è necessario archiviare tutte le copie di un'entità nella stessa partizione. Per altre informazioni, vedere la sezione Transazioni di gruppi di entità.
Il valore usato per RowKey deve essere univoco per ogni entità. Provare a usare valori di chiave composti.
Il riempimento dei valori numerici in RowKey (ad esempio l'ID dipendente 000223) rende possibile l'ordinamento e il filtro corretto in base ai limiti superiori e inferiori.
Non è necessario duplicare tutte le proprietà dell'entità. Se ad esempio le query che eseguono la ricerca di entità usando l'indirizzo di posta elettronica in RowKey non richiedono mai l'età del dipendente, queste entità potrebbero avere la struttura seguente:
È in genere preferibile archiviare dati duplicati e assicurarsi che sia possibile recuperare tutti i dati necessari con una singola query anziché usando una query per individuare un'entità e una seconda per cercare i dati richiesti.
Quando usare questo modello
Usare questo modello quando l'applicazione client deve recuperare le entità usando una serie di chiavi diverse, quando il client deve recuperare entità con criteri di ordinamento diversi e nei casi in cui è possibile identificare ogni entità attraverso una varietà di valori univoci. È però necessario assicurarsi che durante l'esecuzione di ricerche di entità con valori RowKey diversi non vengano superati i limiti di scalabilità della partizione.
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
- Modello per indice secondario interpartizione
- Modello per chiave composta
- Transazioni dei gruppi di entità
- Uso di tipi di entità eterogenei
Modello per indice secondario interpartizione
Archivia più copie di ogni entità usando valori RowKey diversi in partizioni separate o in tabelle separate per consentire ricerche rapide ed efficienti e ordinamenti alternativi usando valori RowKey diversi.
Contesto e problema
Il servizio tabelle indicizza automaticamente le entità usando i valori PartitionKey e RowKey. Questo consente a un'applicazione client di recuperare un'entità in modo efficiente mediante questi valori. Ad esempio, usando la struttura della tabella riportata di seguito, un'applicazione client può usare una query di tipo punto per recuperare una singola entità dipendente attraverso il nome del reparto e l'ID del dipendente (i valori PartitionKey e RowKey). Un client può anche recuperare entità ordinate per ID dipendente in ogni reparto.
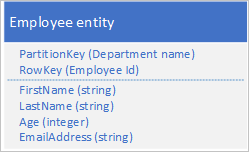
Se si desidera poter trovare un'entità dipendente anche in base al valore di un'altra proprietà, ad esempio l'indirizzo di posta elettronica, è necessario usare un'analisi della partizione meno efficiente per trovare una corrispondenza. Il motivo è che il servizio tabelle non fornisce indici secondari. Inoltre, non esiste un'opzione per richiedere un elenco di dipendenti ordinato in modo diverso rispetto all'ordine RowKey .
Si prevede un volume elevato di transazioni rispetto a queste entità e si vuole ridurre al minimo il rischio che il servizio tabelle limiti il client.
Soluzione
Per ovviare alla mancanza di indici secondari, è possibile archiviare più copie di ogni entità usando per ogni copia valori PartitionKey e RowKey diversi. Se si archivia un'entità con le strutture riportate di seguito, è possibile recuperare in modo efficiente entità dipendente in base all'ID dipendente o all'indirizzo di posta elettronica. I valori di prefisso per PartitionKey, "empid_" e "email_", consentono di identificare l'indice da usare per una query.

I due criteri di filtro seguenti (uno che ricerca per ID dipendente e uno che ricerca per indirizzo di posta elettronica) specificano entrambi query di tipo punto:
- $filter=(PartitionKey 'empid_Sales') e (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') e (RowKey eq 'jonesj@contoso.com')
Se si esegue una query su un intervallo di entità dipendente, è possibile specificare un intervallo ordinato per ID dipendente o un intervallo ordinato per indirizzo di posta elettronica eseguendo la query sulle entità con il prefisso appropriato in RowKey.
- Per trovare tutti i dipendenti del reparto vendite con un ID dipendente nell'intervallo compreso tra 000100 e 000199 ordinati in base all'ID dipendente, usare: $filter=(PartitionKey eq 'empid_Sales') and (RowKey ge '000100') and (RowKey le '000199')
- Per trovare tutti i dipendenti del reparto vendite con un indirizzo di posta elettronica che inizia con 'a' ordinato in base all’indirizzo di posta elettronica utilizzare: $filter = (PartitionKey eq ' email_Sales') e (RowKey ge 'a') e (RowKey lt "b")
La sintassi di filtro usata negli esempi precedenti proviene dall'API REST del servizio tabelle. Per altre informazioni, vedere Query Entities (Query su entità).
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
Per mantenere la coerenza finale tra le entità duplicate, è possibile usare il Modello per transazioni con coerenza finale per gestire le entità di indice primario e secondario.
L'uso dell'archiviazione tabelle è relativamente economico, pertanto l'aumento dei costi dovuto all'archiviazione di dati duplicati non dovrebbe rappresentare una preoccupazione. È però consigliabile valutare sempre il costo del progetto in base ai requisiti di archiviazione previsti e aggiungere entità duplicate solo per supportare le query che verranno eseguite dall'applicazione client.
Il valore usato per RowKey deve essere univoco per ogni entità. Provare a usare valori di chiave composti.
Il riempimento dei valori numerici in RowKey (ad esempio l'ID dipendente 000223) rende possibile l'ordinamento e il filtro corretto in base ai limiti superiori e inferiori.
Non è necessario duplicare tutte le proprietà dell'entità. Se ad esempio le query che eseguono la ricerca di entità usando l'indirizzo di posta elettronica in RowKey non richiedono mai l'età del dipendente, queste entità potrebbero avere la struttura seguente:
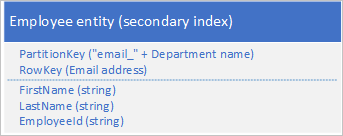
In genere è preferibile archiviare dati duplicati e assicurarsi di poter recuperare tutti i dati necessari con una singola query rispetto all'uso di una query per individuare un'entità usando l'indice secondario e un'altra per cercare i dati necessari nell'indice primario.
Quando usare questo modello
Usare questo modello quando l'applicazione client deve recuperare le entità usando una serie di chiavi diverse, quando il client deve recuperare entità con criteri di ordinamento diversi e nei casi in cui è possibile identificare ogni entità attraverso una varietà di valori univoci. Usare questo modello quando si vuole evitare il superamento dei limiti di scalabilità della partizione durante l'esecuzione di ricerche di entità con i diversi valori RowKey .
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
- Modello per transazioni con coerenza finale
- Modello per indice secondario intrapartizione
- Modello per chiave composta
- Transazioni dei gruppi di entità
- Uso di tipi di entità eterogenei
Modello per transazioni con coerenza finale
abilita un comportamento di coerenza finale tra i limiti della partizione o i limiti del sistema di archiviazione usando le code di Azure.
Contesto e problema
Le transazioni ETG consentono l'esecuzione di transazioni atomiche tra più entità che condividono la stessa chiave di partizione. Per motivi di scalabilità e prestazioni, si può scegliere di archiviare le entità con requisiti di coerenza in partizioni separate o in un sistema di archiviazione separato: in questo caso, non è possibile usare le transazioni ETG per mantenere la coerenza. Ad esempio, potrebbe essere necessario mantenere la coerenza finale tra:
- Entità archiviate in due partizioni diverse nella stessa tabella, in tabelle diverse o in account di archiviazione diversi.
- Un'entità archiviata nel servizio tabelle e un BLOB archiviato nel servizio BLOB.
- Un'entità archiviata nel servizio tabelle e un file in un file system.
- Entità archiviata nel servizio tabelle ancora indicizzata usando il servizio Ricerca cognitiva di Azure.
Soluzione
Usando le code di Azure, è possibile implementare una soluzione che offre coerenza finale tra due o più partizioni o sistemi di archiviazione. Per illustrare questo approccio, si supponga di avere l'esigenza di archiviare le entità relative ai dipendenti precedenti. Queste entità sono raramente oggetto di query e devono essere escluse da tutte le attività associate ai dipendenti correnti. Per implementare questo requisito, archiviare i dipendenti attivi nella tabella Current e nei vecchi dipendenti della tabella Archive . Per archiviare un dipendente è necessario eliminare l'entità dalla tabella dei dipendenti Correnti e aggiungerla a quella dei dipendenti Archiviati, ma non è possibile usare una transazione ETG per eseguire queste due operazioni. Per evitare il rischio che, a causa di un errore, un'entità venga visualizzata in entrambe le tabelle o in nessuna di esse, l'operazione di archiviazione deve garantire la coerenza finale. Il diagramma seguente illustra in sequenza i passaggi di questa operazione. Nel testo che segue sono disponibili maggiori dettagli per i percorsi di eccezione.
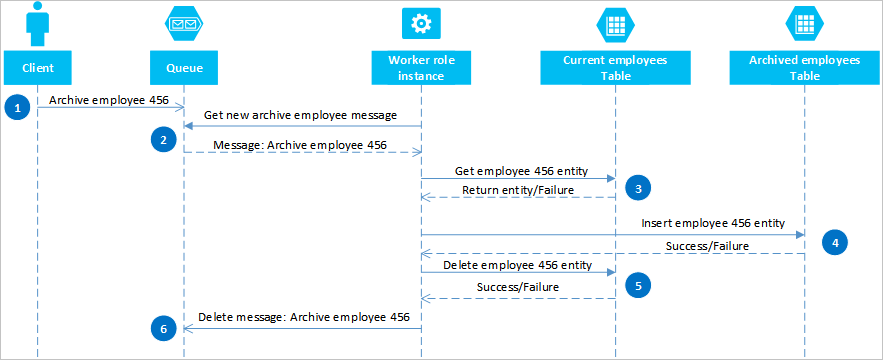
Un client avvia l'operazione di archiviazione inserendo un messaggio in una coda di Azure, in questo esempio per l'archiviazione del dipendente 456. Un ruolo di lavoro esegue il polling della coda per individuare i nuovi messaggi. Quando ne trova uno, legge il messaggio e lascia una copia nascosta nella coda. Successivamente, il ruolo di lavoro recupera una copia dell'entità dalla tabella dei dipendenti Correnti, inserisce una copia nella tabella dei dipendenti Archiviati e quindi elimina l'originale dalla tabella dei dipendenti Correnti. Infine, se nei passaggi precedenti non si sono verificati errori, il ruolo di lavoro elimina il messaggio nascosto dalla coda.
In questo esempio, il passaggio 4 inserisce il dipendente nella tabella dei dipendenti Archiviati . Potrebbe aggiungere il dipendente a un BLOB nel servizio BLOB o un file in un file system.
Ripristino da errori
È importante che le operazioni nei passaggi 4 e 5 siano idempotenti nei casi in cui il ruolo di lavoro deve riavviare l'operazione di archiviazione. Se si sta usando il servizio tabelle, per il passaggio 4 è consigliabile usare un'operazione "insert or replace"; per il passaggio 5 è consigliabile usare un'operazione "delete if exists" nella libreria client in uso. Se si sta usando un altro sistema di archiviazione, è consigliabile usare un'operazione idempotente appropriata.
Se il ruolo di lavoro non completa mai il passaggio 6, dopo un timeout il messaggio ricompare nella coda, pronto per una nuova elaborazione da parte del ruolo di lavoro. Il ruolo di lavoro può controllare quante volte un messaggio nella coda è stato letto e, se necessario, contrassegnarlo come messaggio non elaborabile da analizzare inviandolo a una coda separata. Per altre informazioni sulla lettura dei messaggi in coda e la verifica del numero di rimozioni dalla coda, vedere Get Messages.
Alcuni errori del servizio tabelle e del servizio di accodamento sono temporanei e l'applicazione client deve includere la logica di ripetizione dei tentativi appropriata per gestirli.
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
- Questa soluzione non prevede l'isolamento delle transazioni. Ad esempio, un client potrebbe leggere le tabelle dei dipendenti Correnti e Archiviati mentre il ruolo di lavoro è tra i passaggi 4 e 5 e ottenere una vista incoerente dei dati. Alla fine i dati saranno coerenti.
- È necessario assicurarsi che i passaggi 4 e 5 siano idempotenti per garantire la coerenza finale.
- È possibile ridimensionare la soluzione usando più code e istanze del ruolo di lavoro.
Quando usare questo modello
Usare questo modello quando si desidera garantire la coerenza finale tra entità esistenti in tabelle o partizioni diverse. È possibile estendere il modello per garantire la coerenza finale per le operazioni tra il servizio tabelle e il servizio BLOB e altre origini dati di archiviazione non Azure, quali database o file system.
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
- Transazioni dei gruppi di entità
- Unione o sostituzione
Nota
Se l'isolamento delle transazioni è importante per la soluzione, è consigliabile riprogettare le tabelle per consentire l'uso delle transazioni ETG.
Modello per entità di indice
mantiene le entità di indice per consentire ricerche efficienti che restituiscano elenchi di entità.
Contesto e problema
Il servizio tabelle indicizza automaticamente le entità usando i valori PartitionKey e RowKey. Consente a un'applicazione client di recuperare un'entità in modo efficiente mediante una query di tipo punto. Ad esempio, usando la struttura della tabella riportata di seguito, un'applicazione client può recuperare in modo efficiente una singola entità dipendente usando il nome del reparto e l'ID del dipendente (i valori PartitionKey e RowKey).

Se si desidera poter recuperare un elenco di entità dipendente anche in base al valore di un'altra proprietà non univoca, ad esempio il cognome, è necessario usare un'analisi della partizione meno efficiente per trovare una corrispondenza piuttosto che usare un indice per la ricerca diretta. Il motivo è che il servizio tabelle non fornisce indici secondari.
Soluzione
Per abilitare la ricerca in base al cognome con la struttura di entità illustrata in precedenza, è necessario mantenere elenchi di ID dipendente. Per recuperare le entità dipendente con un determinato cognome, ad esempio Jones, è necessario innanzitutto individuare l'elenco di ID relativi ai dipendenti con il cognome Jones e quindi recuperare tali entità dipendente. Per l'archiviazione degli elenchi di ID dipendente sono disponibili tre opzioni principali:
- Usare l'archiviazione BLOB.
- Creare entità di indice nella stessa partizione delle entità dipendente.
- Creare entità di indice in una tabella o una partizione separata.
Opzione 1: usare l'archiviazione BLOB
Per la prima opzione è necessario creare un BLOB per ogni cognome univoco e archiviare in ogni BLOB un elenco dei valori PartitionKey (reparto) e RowKey (ID dipendente) per i dipendenti con questo cognome. Quando si aggiunge o elimina un dipendente, è necessario verificare la coerenza finale tra il contenuto del BLOB pertinente e le entità dipendente.
Opzione 2: creare entità di indice nella stessa partizione
Per la seconda opzione, usare entità di indice che archiviano i dati seguenti:
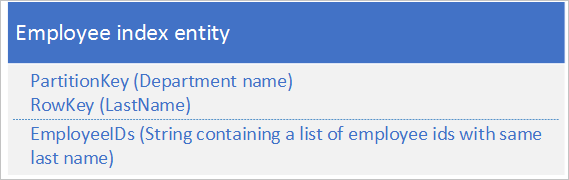
La proprietà EmployeeIDs contiene un elenco di ID dipendente per i dipendenti con il cognome archiviato in RowKey.
I passaggi seguenti illustrano il processo da seguire per aggiungere un nuovo dipendente se si usa la seconda opzione. In questo esempio si aggiunge un dipendente con ID 000152 e un cognome Jones nel reparto vendite:
- Recuperare l'entità indice con un valore PartitionKey "Sales" e il valore RowKey "Jones". Salvare l'ETag di questa entità da usare nel passaggio 2.
- Creare una transazione del gruppo di entità (cioè un'operazione batch) che inserisca la nuova entità dipendente (con valore PartitionKey "Sales" e valore RowKey "000152") e aggiorni l'entità di indice (con valore PartitionKey "Sales" e valore RowKey "Jones") aggiungendo il nuovo ID dipendente all'elenco nel campo EmployeeIDs. Per informazioni sulle transazioni di gruppi di entità, vedere Transazioni di gruppi di entità.
- Se la transazione del gruppo di entità ha esito negativo a causa di un errore di concorrenza ottimistica (un altro utente ha appena modificato l'entità di indice), è necessario ricominciare dal passaggio 1.
Se si usa la seconda opzione, è possibile adottare un approccio simile per l'eliminazione di un dipendente. Modificare il cognome del dipendente è un'operazione leggermente più complessa, in quanto è necessario eseguire una transazione del gruppo di entità che aggiorna tre entità: l'entità dipendente, l'entità di indice per il cognome precedente e l'entità di indice per il nuovo cognome. È necessario recuperare ogni entità prima di apportare qualsiasi modifica, per recuperare i valori ETag da usare in seguito per eseguire gli aggiornamenti usando la concorrenza ottimistica.
I passaggi seguenti illustrano il processo da seguire per cercare tutti i dipendenti di un reparto con un determinato cognome se si usa la seconda opzione. In questo esempio si cercano tutti i dipendenti del reparto vendite il cui cognome è Jones:
- Recuperare l'entità di indice con il valore PartitionKey "Sales" e il valore RowKey "Jones".
- Analizzare l'elenco di ID dipendente nel campo EmployeeIDs.
- Se sono necessarie informazioni aggiuntive su ognuno dei dipendenti (ad esempio gli indirizzi e-mail), recuperare ognuna delle entità dipendente usando il valore PartitionKey "Sales" e i valori RowKey dall'elenco dei dipendenti ottenuti nel passaggio 2.
Opzione 3: creare entità di indice in una tabella o una partizione separata
Per la terza opzione, usare entità di indice che archiviano i dati seguenti:

La proprietà EmployeeDetails contiene un elenco di ID dipendente e coppie di nomi di reparto per i dipendenti con il cognome archiviato RowKeyin .
Con la terza opzione non è possibile usare transazioni ETG per mantenere la coerenza, in quanto le entità di indice si trovano in una partizione separata rispetto alle entità dipendente. Verificare la coerenza finale tra le entità indice e le entità dipendente.
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
- Questa soluzione richiede almeno due query per recuperare le entità corrispondenti: una sulle entità di indice per ottenere l'elenco di valori RowKey e altre query per il recupero di ogni entità dell'elenco.
- Dato che una singola entità ha una dimensione massima di 1 MB, l'opzione 2 e l'opzione 3 nella soluzione presuppongono che l'elenco di ID dipendente per un determinato cognome non sia mai maggiore di 1 MB. Se è probabile che l'elenco di ID dipendente sia maggiore di 1 MB, usare l'opzione 1 e archiviare i dati dell'indice nell'archivio BLOB.
- Se si usa l'opzione 2 (uso di transazioni EGT per gestire l'aggiunta e l'eliminazione dei dipendenti e la modifica del cognome di un dipendente), è necessario valutare se il volume delle transazioni raggiungerà i limiti di scalabilità in una determinata partizione. In tal caso, è opportuno considerare una soluzione con coerenza finale (opzione 1 o 3) che gestisca le richieste di aggiornamento mediante code e consenta di archiviare le entità di indice in una partizione separata rispetto alle entità dipendente.
- L'opzione 2 di questa soluzione presuppone che si vogliano effettuare ricerche in base al cognome all'interno di un reparto, ad esempio recuperare un elenco di dipendenti del reparto vendite il cui cognome è Jones. Se si desidera poter cercare tutti i dipendenti il cui cognome è Jones nell'intera organizzazione, usare l'opzione 1 o l'opzione 3.
- È possibile implementare una soluzione basata su code che garantisca coerenza finale. Per altri dettagli, vedere Modello per transazioni con coerenza finale.
Quando usare questo modello
Usare questo criterio quando si desidera cercare un set di entità che condividono un valore della proprietà comune, ad esempio tutti i dipendenti con il cognome Jones.
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
- Modello per chiave composta
- Modello per transazioni con coerenza finale
- Transazioni dei gruppi di entità
- Uso di tipi di entità eterogenei
Modello di denormalizzazione
combina i dati correlati in una singola entità per consentire di recuperare tutti i dati necessari con un sola query di tipo punto.
Contesto e problema
In un database relazionale, in genere i dati vengono normalizzati per rimuovere i risultati duplicati nelle query che recuperano dati da più tabelle. Se si normalizzano i dati nelle tabelle di Azure, è necessario eseguire più round trip dal client al server per recuperare i dati correlati. Con la struttura della tabella mostrata di seguito, ad esempio, per recuperare i dettagli per un reparto sono necessari due round trip: uno per recuperare l'entità reparto che include l'ID del manager e una seconda richiesta per recuperare i dettagli sul manager in un'entità dipendente.

Soluzione
Anziché archiviare i dati in due entità separate, denormalizzare i dati e conservare una copia dei dettagli sul manager nell'entità reparto. Ad esempio:
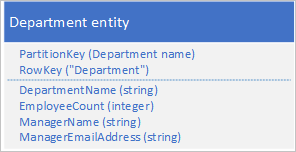
Archiviando le entità reparto con queste proprietà, è possibile recuperare tutti i dettagli necessari su un reparto mediante una query di tipo punto.
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
- Archiviare alcuni dati due volte comporta un aumento dei costi. Il miglioramento delle prestazioni (risultante dal minor numero di richieste al servizio di archiviazione) in genere compensa l'incremento marginale dei costi di archiviazione, che per altro è parzialmente compensato dalla riduzione del numero di transazioni necessarie per recuperare i dettagli relativi a un reparto.
- È necessario mantenere la coerenza tra le due entità in cui sono archiviate le informazioni sui manager. Il problema della coerenza può essere gestito usando transazioni ETG per aggiornare più entità in una singola transazione atomica: in questo caso, l'entità reparto e l'entità dipendente per il responsabile del reparto vengono archiviate nella stessa partizione.
Quando usare questo modello
Usare questo modello quando è necessario cercare spesso informazioni correlate. Questo modello riduce il numero di query che il client deve eseguire per recuperare i dati necessari.
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
- Modello per chiave composta
- Transazioni dei gruppi di entità
- Uso di tipi di entità eterogenei
Modello per chiave composta
Usare valori RowKey composti per consentire a un client di cercare i dati correlati con una singola query punto.
Contesto e problema
In un database relazionale è normale usare join nelle query per restituire dati correlati al client in una singola query. Ad esempio, si può usare l'ID dipendente per cercare un elenco di entità correlate che contengono i dati relativi alle prestazioni e alle valutazioni per tale dipendente.
Si supponga di archiviare le entità dipendente nel servizio tabelle usando la struttura seguente:
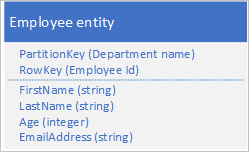
È inoltre necessario archiviare i dati cronologici relativi alle valutazioni e alle prestazioni per ogni anno che il dipendente ha lavorato presso l'organizzazione, nonché poter accedere a queste informazioni in base all'anno. Una possibilità consiste nel creare un'altra tabella di archiviazione delle entità con la struttura seguente:
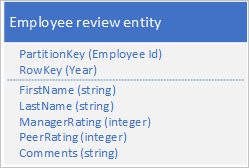
Si noti che con questo approccio è possibile decidere di duplicare alcune informazioni (ad esempio nome e cognome) nella nuova entità, in modo da poter recuperare i dati con una singola richiesta. Non è tuttavia possibile mantenere la coerenza assoluta, in quanto non si può usare una transazione EGT per aggiornare le entità in modo atomico.
Soluzione
Archiviare un nuovo tipo di entità nella tabella originale usando entità con la struttura seguente:
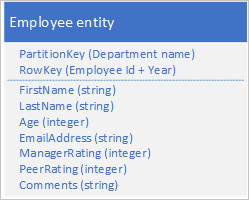
Si noti che ora il valore di RowKey è una chiave composta costituita dall'ID dipendente e dall'anno dei dati di valutazione, che consente di recuperare le prestazioni e le valutazioni del dipendente con una singola richiesta per una singola entità.
L'esempio seguente illustra come recuperare tutti i dati di valutazione per uno specifico dipendente (ad esempio il dipendente 000123 del reparto vendite):
$filter=(PartitionKey eq 'Sales') e (RowKey ge 'empid_000123') e (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comments
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
- È consigliabile usare un carattere separatore appropriato che semplifichi l'analisi del valore RowKey, ad esempio 000123_2012.
- Inoltre, si sta archiviando l'entità nella stessa partizione di altre entità che contengono dati correlati per lo stesso dipendente, dunque è possibile usare transazioni EGT per mantenere la coerenza assoluta.
- Per determinare se questo modello è appropriato, considerare la frequenza con cui si eseguiranno query sui dati. Ad esempio, se si accederà raramente ai dati di valutazione e spesso ai dati principali sul dipendente, è consigliabile conservarli come entità separate.
Quando usare questo modello
Usare questo modello quando è necessario archiviare una o più entità correlate su cui si eseguono query frequenti.
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
- Transazioni dei gruppi di entità
- Uso di tipi di entità eterogenei
- Modello per transazioni con coerenza finale
Modello della parte finale del log
recupera le e ntità aggiunte più di recente a una partizione in base a un valore RowKey che usa un ordinamento inverso di data e ora.
Contesto e problema
Un requisito comune è stato in grado di recuperare le entità create più di recente, ad esempio le 10 attestazioni spese più recenti inviate da un dipendente. Le query sulle tabelle supportano un'operazione di query $top per restituire le prime n entità di un set. Non esiste un'operazione di query equivalente per la restituzione delle ultime n entità di un set.
Soluzione
Archiviare le entità usando un valore RowKey che usa un ordinamento inverso di data e ora, in modo che la voce più recente sia sempre la prima della tabella.
Ad esempio, per poter recuperare le 10 richieste di spesa più recenti inviate da un dipendente, è possibile usare un valore di graduazione inverso derivato dalla data/ora corrente. L'esempio di codice C# seguente illustra un modo per creare un valore "invertedTicks" appropriato per un valore RowKey che ordina dal più recente al meno recente:
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
Per tornare al valore di data e ora, usare il codice seguente:
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
La query sulla tabella ha un aspetto simile al seguente:
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
- È necessario aggiungere zeri iniziali al valore di tick inverso per assicurarsi che il valore di stringa venga ordinato come previsto.
- È necessario tenere presenti gli obiettivi di scalabilità a livello di partizione. Fare attenzione a non creare partizioni critiche.
Quando usare questo modello
Usare questo modello quando si desidera accedere alle entità in ordine di data/ora inverso o quando è necessario accedere alle entità aggiunte più di recente.
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
Modello di eliminazione volume elevato
Abilitare l'eliminazione di un volume elevato di entità mediante l'archiviazione di tutte le entità per l'eliminazione simultanea nella relativa tabella separata; per eliminare le entità, eliminare la tabella.
Contesto e problema
Molte applicazioni eliminano vecchi dati non più necessari a un'applicazione client o che l'applicazione ha archiviato in un altro supporto di archiviazione. In genere questi dati vengono identificati da una data; è presente un requisito che prevede l'eliminazione dei record di tutte le richieste di accesso risalenti a oltre 60 giorni prima.
Una possibile progettazione consiste nell'usare la data e l'ora della richiesta di accesso in RowKey:
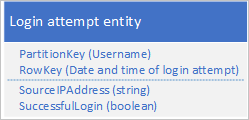
Questo approccio evita hotspot di partizione perché l'applicazione può inserire ed eliminare entità di accesso per ogni utente in una partizione separata, ma può rivelarsi dispendioso in termini di denaro e tempo se si dispone di un numero elevato di entità perché è necessario innanzitutto eseguire un'analisi di tabella per identificare tutte le entità da eliminare e successivamente eliminare ogni entità precedente. Si noti che è possibile ridurre il numero di round trip al server necessari per eliminare le entità precedenti raggruppando più richieste di eliminazione in EGT.
Soluzione
Usare una tabella separata per ogni giorno di tentativi di accesso. È possibile usare la progettazione di entità riportata sopra per evitare hotspot durante l'inserimento di entità; l'eliminazione di entità comporterà semplicemente l'eliminazione di una tabella al giorno (una singola operazione di archiviazione) invece della ricerca ed eliminazione di centinaia o migliaia di singole entità ogni giorno.
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
- La progettazione supporta altre modalità di uso dei dati da parte dell'applicazione, come la ricerca di entità specifiche, il collegamento con altri dati o la generazione di informazioni aggregate?
- La progettazione consente di evitare hotspot durante l'inserimento di nuove entità?
- Se si vuole riutilizzare lo stesso nome di tabella dopo l'eliminazione, prevedere un ritardo. È consigliabile usare sempre nomi di tabella univoci.
- Prevedere una limitazione delle richieste quando si usa per la prima volta una nuova tabella mentre il servizio tabelle apprende i modelli di accesso e le partizioni vengono distribuite in nodi. È necessario considerare la frequenza con cui è necessario creare nuove tabelle.
Quando usare questo modello
Usare questo modello quando si dispone di un volume elevato di entità che è necessario eliminare contemporaneamente.
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
- Transazioni dei gruppi di entità
- Modifica di entità
Modello di serie di dati
Archiviare serie di dati complete in un'unica entità per ridurre al minimo il numero di richieste effettuate.
Contesto e problema
Spesso un'applicazione archivia una serie di dati richiesti di frequente per recuperarli tutti simultaneamente. L'applicazione potrebbe, ad esempio, registrare il numero di messaggi immediati che ogni dipendente invia ogni ora e quindi usare queste informazioni per tracciare il numero di messaggi inviati da ogni utente nelle 24 ore precedenti. Una progettazione potrebbe essere l'archiviazione di 24 entità per ogni dipendente:
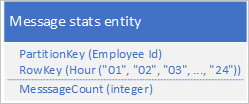
Con questa progettazione è possibile individuare e aggiornare l'entità da aggiornare per ogni dipendente ogni volta che l'applicazione deve aggiornare il valore del numero di messaggi. Tuttavia, per recuperare le informazioni allo scopo di tracciare un grafico dell'attività per le 24 ore precedenti, è necessario recuperare 24 entità.
Soluzione
Usare la progettazione seguente con una proprietà separata per archiviare il numero di messaggi per ogni ora:
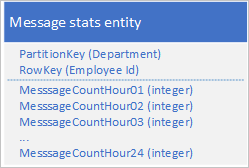
Con questa progettazione è possibile usare un'operazione di unione per aggiornare il numero di messaggi per un dipendente per un'ora specifica. A questo punto, è possibile recuperare tutte le informazioni necessarie per tracciare il grafico usando una richiesta per una singola entità.
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
- Se la serie di dati completa non rientra in una singola entità (un'entità può contenere fino a 252 proprietà), usare un archivio dati alternativo, ad esempio un BLOB.
- Se sono presenti più client che aggiornano un'entità contemporaneamente, sarà necessario usare il ETag per implementare la concorrenza ottimistica. Se si dispone di molti client, potrebbe verificarsi un conflitto elevato.
Quando usare questo modello
Usare questo modello quando è necessario aggiornare e recuperare una serie di dati associata a una singola entità.
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
- Modello di entità di grandi dimensioni
- Unione o sostituzione
- Modello per transazioni con coerenza finale (se si archiviano le serie di dati in un BLOB)
Modello di entità di grandi dimensioni
Usare più entità fisiche per archiviare entità logiche con più di 252 proprietà.
Contesto e problema
Una singola entità può avere più di 252 proprietà (escludendo le proprietà di sistema obbligatorie) e non è possibile memorizzare più di 1 MB di dati in totale. In un database relazionale è in genere possibile aggirare gli eventuali limiti sulle dimensioni di una riga aggiungendo una nuova tabella e applicando una relazione 1 a 1 tra di esse.
Soluzione
Usando il servizio tabelle, è possibile archiviare più entità per rappresentare un singolo oggetto aziendale di grandi dimensioni con più di 252 proprietà. Ad esempio, se si vuole archiviare un conteggio del numero di messaggi immediati inviati da ogni dipendente negli ultimi 365 giorni, è possibile usare la progettazione seguente che si avvale di due entità con schemi diversi:
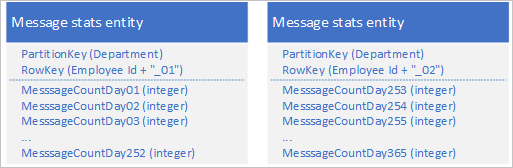
Per apportare una modifica che richiede l'aggiornamento di entrambe le entità per mantenerle sincronizzate tra loro, è possibile usare una transazione EGT. Diversamente, è possibile usare una singola operazione di unione per aggiornare il numero di messaggi per un giorno specifico. Per recuperare tutti i dati per un singolo dipendente, è necessario recuperare entrambe le entità, operazione che è possibile eseguire con due richieste efficienti che usano un valore PartitionKey e un valore RowKey.
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
- Il recupero di un'entità logica completa richiede almeno due transazioni di archiviazione, una per recuperare ogni entità fisica.
Quando usare questo modello
Usare questo modello quando è necessario archiviare entità le cui dimensioni o il cui numero di proprietà superano i limiti per una singola entità nel servizio tabelle.
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
- Transazioni dei gruppi di entità
- Unione o sostituzione
Modello di entità di grandi dimensioni
Usare l'archiviazione BLOB per archiviare valori di proprietà di grandi dimensioni.
Contesto e problema
Una singola entità non può memorizzare più di 1 MB di dati in totale. Se una o più proprietà archiviano valori che causano il superamento delle dimensioni totali dell'entità, non è possibile archiviare l'intera entità nel servizio tabelle.
Soluzione
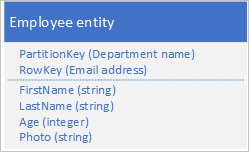
Se l'entità supera le dimensioni di 1 MB perché una o più proprietà contengono una grande quantità di dati, è possibile archiviare i dati nel servizio BLOB e quindi archiviare l'indirizzo del BLOB in una proprietà nell'entità. Ad esempio, è possibile archiviare la foto di un dipendente nell'archiviazione BLOB e archiviare un collegamento a foto nella proprietà Photo dell'entità del dipendente:
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
- Per mantenere la coerenza finale tra l'entità nel servizio tabelle e i dati nel servizio BLOB, usare il Modello per transazioni con coerenza finale per mantenere le identità.
- Il recupero di un'entità completa richiede almeno due transazioni di archiviazione: una per recuperare l'entità e un'altra per recuperare i dati BLOB.
Quando usare questo modello
Usare questo modello quando è necessario archiviare entità le cui dimensioni superano i limiti per una singola entità nel servizio tabelle.
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
Anti-modello prepend/append
Quando si dispone di un volume elevato di inserimenti, aumentare la scalabilità suddividendoli tra più partizioni.
Contesto e problema
L'anteposizione o l'aggiunta di entità alle entità archiviate determina in genere l'aggiunta da parte dell'applicazione di nuove entità alla prima o ultima partizione di una sequenza di partizioni. In questo caso, tutti gli inserimenti in un determinato momento vengono eseguiti nella stessa partizione, creando un hotspot che impedisce al servizio tabelle di bilanciare il carico degli inserimenti tra più nodi e causando il possibile raggiungimento degli obiettivi di scalabilità per partizione da parte dell'applicazione. Se ad esempio si dispone di un'applicazione che registra l'accesso alla rete e alle risorse da parte dei dipendenti, la struttura dell'entità mostrata sotto potrebbe determinare la trasformazione della partizione dell'ora corrente in un hotspot se il volume delle transazioni raggiunge l'obiettivo di scalabilità per una singola partizione:

Soluzione
La struttura di un'entità alternativa seguente evita gli hotspot in qualsiasi partizione specifica quando l'applicazione effettua la registrazione di eventi:
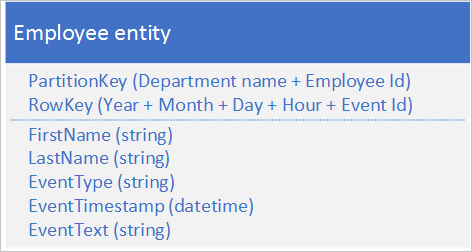
Si noti come in questo esempio entrambi i valori PartitionKey e RowKey siano chiavi composte. Il valore PartitionKey usa sia l'ID reparto che l'ID dipendente per distribuire la registrazione in più partizioni.
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
- La struttura chiave alternativa che evita la creazione di partizioni critiche negli inserimenti supporta in modo efficiente le query effettuate dall'applicazione client?
- Il volume delle transazioni previste è indicativo della probabilità che si raggiungano gli obiettivi di scalabilità per una singola partizione e si sia limitati dal servizio di archiviazione?
Quando usare questo modello
Evitare l'anti-modello prepend/append quando il volume delle transazioni determinerà probabilmente una limitazione da parte del servizio di archiviazione quando si accede a una partizione critica.
Modelli correlati e informazioni aggiuntive
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
Anti-modello dei dati di log
In genere è necessario usare il servizio BLOB invece del servizio tabelle per archiviare i dati di log.
Contesto e problema
Un caso di utilizzo comune per i dati di log è il recupero di una selezione di voci di log per un intervallo specifico di data/ora. Ad esempio, per trovare tutti i messaggi di errore e critici registrati dall'applicazione tra le ore 15.04 e le ore 15.06 in una data specifica senza usare la data e l'ora del messaggio del log per determinare la partizione in cui sono state salvate le entità, verrà creata una partizione critica perché in qualsiasi momento tutte le entità del log condividono lo stesso valore PartitionKey. Vedere la sezione Anti-modello prepend/append. Ad esempio, lo schema di entità seguente per un messaggio di log determina una partizione critica perché l'applicazione scrive tutti i messaggi di log nella partizione per la data e l'ora correnti:
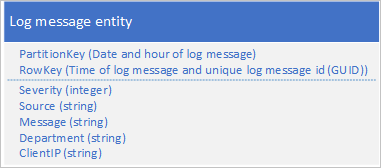
In questo esempio, il valore RowKey include la data e l'ora del messaggio di log per garantire che i messaggi di log vengano archiviati in ordine di data/ora e include un ID del messaggio nel caso in cui più messaggi di log condividano la stessa data e la stessa ora.
Un altro approccio prevede l'uso di un valore PartitionKey per assicurarsi che l'applicazione scriva i messaggi in un intervallo di partizioni. Ad esempio, se l'origine del messaggio di log consente di distribuire i messaggi in più partizioni, è possibile usare lo schema di entità seguente:
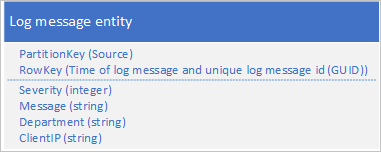
Tuttavia, il problema con questo schema risiede nel fatto che per recuperare tutti i messaggi di log per un intervallo di tempo specifico è necessario cercare ogni partizione nella tabella.
Soluzione
Nella sezione precedente è stato preso in esame il problema associato ai tentativi di usare il servizio tabelle per archiviare le voci di log e sono state proposte due progettazioni, entrambe insoddisfacenti. Una soluzione ha determinato una partizione critica che comporta il rischio di prestazioni insufficienti della scrittura dei messaggi di log; l'altra soluzione ha determinato prestazioni insufficienti delle query a causa del requisito di analizzare ogni partizione della tabella per recuperare i messaggi di log per un intervallo di tempo specifico. L'archiviazione BLOB offre una soluzione migliore per questo tipo di scenario ed è in questo modo che Analisi archiviazione di Azure archivia i dati di log raccolti.
Questa sezione illustra come Analisi archiviazione archivia i dati di log nell'archiviazione BLOB per esemplificare questo approccio all'archiviazione dei dati per la quale vengono in genere eseguite query per intervallo.
Analisi archiviazione archivia i messaggi di log in un formato delimitato in più BLOB. Il formato delimitato semplifica l'analisi dei dati nel messaggio di log da parte di un'applicazione client.
Analisi archiviazione usa una convenzione di denominazione per i BLOB che consente di localizzare uno BLOB o più BLOB che contengono i messaggi di log per i quali si sta effettuando la ricerca. Ad esempio, un BLOB denominato "queue/2014/07/31/1800/000001.log" contiene messaggi di log correlati al servizio di accodamento per l'ora che inizia alle 18.00 del 31 luglio 2014. "000001" indica che si tratta del primo file di log per il periodo. Analisi archiviazione registra inoltre i timestamp del primo e dell'ultimo messaggio di log archiviati nel file come parte dei metadati del BLOB. L'API per l'archiviazione BLOB consente di individuare i BLOB in un contenitore in base a un prefisso del nome: per individuare tutti i BLOB che contengono dati di log della coda per l'ora a partire dalle 18:00, è possibile usare il prefisso "queue/2014/07/31/1800".
Analisi archiviazione esegue il buffer dei messaggi di log e quindi aggiorna periodicamente il BLOB appropriato o ne crea uno nuovo con il batch di voci di log più recente. Ciò riduce il numero di scritture che deve eseguire nel servizio BLOB.
Se si implementa una soluzione simile nella propria applicazione, è necessario considerare come gestire il compromesso tra affidabilità (scrittura di ogni voce di log nell'archiviazione BLOB quando questa si verifica) e il costo e LA scalabilità (buffering degli aggiornamenti dell'applicazione e relativa scrittura nell'archiviazione BLOB in blocchi).
Considerazioni e problemi
Prima di decidere come archiviare i dati di log, considerare quanto segue:
- Se si crea una progettazione di tabella che consente di evitare potenziali partizioni critiche, è possibile che non si possa accedere ai dati di log in modo efficiente.
- Per elaborare i dati di log, spesso un client deve caricare molti record.
- Nonostante i dati di log siano spesso strutturati, l'archiviazione BLOB può essere una soluzione migliore.
Considerazioni sull'implementazione
Questa sezione illustra alcune considerazioni da tenere presente quando si implementano i modelli descritti nelle sezioni precedenti. La maggior parte di questa sezione usa esempi scritti in C# che usano la libreria client Archiviazione (versione 4.3.0 al momento della scrittura).
Recupero di entità
Come descritto nella sezione Progettazione per le query, la query più efficiente è una query di tipo punto. Tuttavia, in alcuni scenari potrebbe essere necessario recuperare più entità. In questa sezione vengono descritti alcuni approcci comuni al recupero di entità tramite la libreria client Archiviazione.
Esecuzione di una query di punto tramite la libreria client Archiviazione
Il modo più semplice per eseguire una query punto consiste nell'usare il metodo GetEntityAsync, come illustrato nel frammento di codice C# seguente che recupera un'entità con un valore PartitionKey "Sales" e una RowKey di valore "212":
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
Si noti come in questo esempio l'entità recuperata prevista sia di tipo EmployeeEntity.
Recupero di più entità usando LINQ
È possibile usare LINQ per recuperare più entità dal servizio tabelle quando si usa la libreria standard di tabelle di Microsoft Azure Cosmos DB.
dotnet add package Azure.Data.Tables
Per fare in modo che gli esempi seguenti funzionino, è necessario includere gli spazi dei nomi:
using System.Linq;
using Azure.Data.Tables
Il recupero di più entità può essere ottenuto specificando una query con una clausola di filtro . Per evitare un'analisi di tabella, è consigliabile includere sempre il valore PartitionKey nella clausola di filtro e, se possibile, il valore RowKey per evitare analisi di tabella e partizione. Il servizio tabelle supporta un set limitato di operatori di confronto (maggiore di, maggiore o uguale, minore di, minore o uguale, uguale o uguale) da usare nella clausola di filtro.
Nell'esempio seguente è employeeTable un oggetto TableClient . In questo esempio vengono trovati tutti i dipendenti il cui cognome inizia con "B" (presupponendo che RowKey archivii il cognome) nel reparto vendite (presupponendo che PartitionKey archivii il nome del reparto):
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
Si noti come la query specifichi sia un valore RowKey che un valore PartitionKey per garantire prestazioni migliori.
L'esempio di codice seguente mostra funzionalità equivalenti senza usare la sintassi LINQ:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Nota
I metodi query di esempio includono le tre condizioni di filtro.
Recupero di un numero elevato di entità da una query
Una query ottimale restituisce una singola entità in base a un valore PartitionKey e a un valore RowKey. In alcuni scenari, tuttavia, potrebbe essere presente il requisito di restituire molte entità dalla stessa partizione o anche da più partizioni.
È sempre necessario eseguire test completi delle prestazioni dell'applicazione in tali scenari.
Una query sul servizio tabelle può restituire un massimo di 1.000 entità contemporaneamente e può essere eseguita per un massimo di cinque secondi. Se il set di risultati contiene più di 1.000 entità, nel caso in cui la query non venga completata entro cinque secondi, o se la query supera il limite della partizione, il servizio tabelle restituisce un token di continuazione per consentire all'applicazione client di richiedere il successivo set di entità. Per altre informazioni sul funzionamento dei token di continuazione, vedere Timeout e paginazione delle query.
Se si usa la libreria client tabelle di Azure, può gestire automaticamente i token di continuazione man mano che restituisce entità dal servizio tabelle. L'esempio di codice C# seguente che usa la libreria client gestisce automaticamente i token di continuazione se il servizio tabelle li restituisce in una risposta:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
È anche possibile specificare il numero massimo di entità restituite per pagina. L'esempio seguente illustra come eseguire query sulle entità con maxPerPage:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
In scenari più avanzati, è possibile archiviare il token di continuazione restituito dal servizio in modo che il codice controlli esattamente quando vengono recuperate le pagine successive. L'esempio seguente illustra uno scenario di base di come il token può essere recuperato e applicato ai risultati impaginati:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
Usando i token di continuazione in modo esplicito è possibile controllare quando l'applicazione recupera il successivo segmento di dati. Ad esempio, se l'applicazione client consente agli utenti di spostarsi tra le entità archiviate in una tabella, un utente può decidere di non spostarsi tra tutte le entità recuperate dalla query in modo che l'applicazione usi solo un token di continuazione per recuperare il segmento successivo quando l'utente ha terminato il paging di tutte le entità nel segmento corrente. Questo approccio offre diversi vantaggi:
- Consente di limitare la quantità di dati da recuperare dal servizio tabelle e da spostare tramite la rete.
- Consente di eseguire operazioni di I/O asincrone in .NET.
- Consente di serializzare il token di continuazione in un archivio permanente in modo da poter proseguire in caso di arresto anomalo dell'applicazione.
Nota
Un token di continuazione in genere restituisce un segmento contenente al massimo 1.000 entità. Ciò avviene anche se si limita il numero di voci restituite da una query usando Take per restituire le prime n entità che corrispondono ai criteri di ricerca: il servizio tabelle può restituire un segmento contenente meno di n entità con un token di continuazione per consentire il recupero delle entità rimanenti.
Proiezione lato server
Una singola entità può avere fino a 255 proprietà e dimensioni fino a 1 MB. Quando si eseguono query sulla tabella e si recuperano entità, potrebbero non essere necessarie tutte le proprietà ed è possibile evitare di trasferire dati inutilmente (in modo da ridurre la latenza e i costi). È possibile usare la proiezione lato server per trasferire solo le proprietà necessarie. L'esempio seguente recupera solo la proprietà Email (insieme a PartitionKey, RowKey, Timestamp ed ETag) dalle entità selezionate dalla query.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
Si noti come il valore RowKey è disponibile anche se non è stato incluso nell'elenco delle proprietà da recuperare.
Modifica di entità
La libreria client Archiviazione consente di modificare le entità archiviate nel servizio tabelle inserendo, eliminando e aggiornando le entità. È possibile usare le transazioni EGT per eseguire in batch più operazioni di inserimento, aggiornamento ed eliminazione insieme allo scopo di ridurre il numero di round trip necessari e migliorare le prestazioni della soluzione.
Le eccezioni generate quando la libreria client Archiviazione esegue un contratto EGT in genere includono l'indice dell'entità che ha causato l'esito negativo del batch. Ciò è utile quando si esegue il debug di codice che usa le transazioni EGT.
È inoltre opportuno considerare l'influenza della progettazione sul modo in cui l'applicazione gestisce le operazioni di concorrenza e aggiornamento.
Gestione della concorrenza
Per impostazione predefinita, il servizio tabelle implementa controlli di concorrenza ottimistica a livello di singole entità per le operazioni Insert, Merge e Delete, sebbene sia possibile per un client forzare il servizio tabelle in modo da ignorare questi controlli. Per altre informazioni sulla gestione della concorrenza nel servizio tabelle, vedere Gestione della concorrenza in Archiviazione di Microsoft Azure.
Unione o sostituzione
Il metodo Replace della classe TableOperation sostituisce sempre l'entità completa nel servizio tabelle. Se non si include una proprietà nella richiesta quando tale proprietà è presente nell'entità archiviata, la richiesta rimuove la proprietà dall'entità archiviata. A meno che non si voglia rimuovere una proprietà in modo esplicito da un'entità archiviata, è necessario includere ogni proprietà nella richiesta.
È possibile usare il metodo Merge della classe TableOperation per ridurre la quantità di dati inviati al servizio tabelle quando si vuole aggiornare un'entità. Il metodo Merge sostituisce le eventuali proprietà nell'entità archiviata con i valori di proprietà dell'entità inclusa nella richiesta, ma lascia invariate le proprietà nell'entità archiviata che non sono incluse nella richiesta. Ciò è utile se si dispone di entità di grandi dimensioni e si desidera solo aggiornare un numero limitato di proprietà in una richiesta.
Nota
I metodi Replace e Merge hanno esito negativo se l'entità non esiste. In alternativa, se l'entità non esiste, è possibile usare i metodi InsertOrReplace e InsertOrMerge per creare una nuova entità.
Uso di tipi di entità eterogenei
Il servizio tabelle è un archivio di tabelle senza schema. Ciò significa che una singola tabella può archiviare entità di più tipi, offrendo una grande flessibilità di progettazione. L'esempio seguente illustra una tabella che archivia entità dipendente ed entità reparto:
| PartitionKey | RowKey | Timestamp: | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Ogni entità deve comunque avere i valori PartitionKey, RowKey e Timestamp, ma può avere qualsiasi set di proprietà. Inoltre, non esiste alcuna indicazione relativa al tipo di un'entità, a meno che non si scelga di memorizzare le informazioni in una posizione. Esistono due opzioni per identificare il tipo di entità:
- Anteporre il tipo di entità per il valore RowKey (o eventualmente il valore PartitionKey). Ad esempio, EMPLOYEE_000123 o DEPARTMENT_SALES come valori RowKey.
- Usare una proprietà separata per registrare il tipo di entità come illustrato nella tabella seguente.
| PartitionKey | RowKey | Timestamp: | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
La prima opzione che precede l'entità per il valore RowKeyè utile se sussiste la possibilità che due entità di tipi diversi abbiano lo stesso valore di chiave. Inoltre, raggruppa entità dello stesso tipo insieme nella partizione.
Le tecniche descritte in questa sezione sono particolarmente rilevanti per la discussione Relazioni di ereditarietà trattata all'inizio di questa Guida nell'articolo Modellazione di relazioni.
Nota
È necessario considerare l'inclusione di un numero di versione nel valore del tipo di entità per consentire alle applicazioni client di sviluppare oggetti POCO e usare versioni diverse.
Nella parte restante di questa sezione vengono descritte alcune delle funzionalità della libreria client Archiviazione che facilitano l'uso di più tipi di entità nella stessa tabella.
Recupero di tipi di entità eterogenei
Se si usa la libreria client Table, sono disponibili tre opzioni per l'uso di più tipi di entità.
Se si conosce il tipo dell'entità archiviata con valori RowKey e PartitionKey specifici, è possibile specificare il tipo di entità quando si recupera l'entità come illustrato nei due esempi precedenti che recuperano entità di tipo EmployeeEntity: Esecuzione di una query di punto usando la libreria client Archiviazione e Recupero di più entità usando LINQ.
La seconda opzione consiste nell'usare il tipo TableEntity (un contenitore delle proprietà) anziché un tipo di entità POCO concreto(questa opzione può anche migliorare le prestazioni perché non è necessario serializzare e deserializzare l'entità in tipi .NET). Il codice C# seguente recupera potenzialmente più entità di tipi diversi dalla tabella, ma restituisce tutte le entità come istanze di TableEntity . Usa quindi la proprietà EntityType per determinare il tipo di ogni entità:
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Per recuperare altre proprietà, è necessario utilizzare il metodo GetString sull'entitàdella classe TableEntity.
Modifica dei tipi di entità eterogenei
Per eliminare un'entità non è necessario conoscerne il tipo, che è comunque sempre noto quando l'entità viene inserita. Tuttavia, è possibile usare il tipo TableEntity per aggiornare un'entità senza conoscerne il tipo e senza usare una classe di entità POCO. L'esempio di codice seguente consente di recuperare una singola entità e controlla che la proprietà EmployeeCount esista prima di aggiornarla.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Controllo dell'accesso con le firme di accesso condiviso
È possibile usare i token di firma di accesso condiviso (SAS) per consentire alle applicazioni client di modificare le entità di tabella, ed eseguire query sulle stesse, senza la necessità di includere la chiave dell'account di archiviazione nel codice. In genere, l'uso di SAS nell'applicazione comporta tre vantaggi principali:
- Non è necessario distribuire la chiave dell'account di archiviazione in una piattaforma non sicura (ad esempio un dispositivo mobile) per consentire a tale dispositivo di accedere e modificare le entità nel servizio tabelle.
- È possibile scaricare una parte del lavoro eseguito dai ruoli Web e di lavoro nella gestione delle entità per i dispositivi client, ad esempio computer e dispositivi mobili degli utenti finali.
- È possibile assegnare un set vincolato e limitato nel tempo di autorizzazioni a un client (ad esempio, l'accesso di sola lettura a risorse specifiche).
Per altre informazioni sull'uso di token di firma di accesso condiviso con il servizio tabelle, vedere Uso delle firme di accesso condiviso.
Tuttavia, è comunque necessario generare i token delle firme di accesso condiviso che consentono a un'applicazione client di accedere alle entità nel servizio tabelle: questa operazione deve essere eseguita in un ambiente che dispone di un accesso sicuro alle chiavi dell'account di archiviazione. In genere, è possibile usare un ruolo Web o di lavoro per generare i token delle firme di accesso condiviso e distribuirli alle applicazioni client che richiedono l'accesso alle entità. Poiché la generazione e la distribuzione dei token delle firme di accesso condiviso ai client comportano comunque un sovraccarico, è consigliabile valutare il modo migliore di ridurre tale sovraccarico, soprattutto in scenari con volumi elevati.
È possibile generare un token delle firme di accesso condiviso che concede l'accesso a un sottoinsieme delle entità in una tabella. Per impostazione predefinita, viene creato un token della firma di accesso condiviso per un'intera tabella, ma è anche possibile specificare che il token della firma di accesso condiviso conceda l'accesso a un intervallo di valori PartitionKey o a un intervallo di valori PartitionKey e RowKey. Si potrebbe scegliere di generare token SAS per i singoli utenti del sistema in modo che il token SAS di ogni utente consenta di accedere solo alle proprie entità nel servizio tabelle.
Operazioni asincrone e parallele
A condizione che le richieste vengano distribuite in più partizioni, è possibile migliorare la velocità effettiva e la velocità di risposta del client usando le query parallele o asincrone. Ad esempio, si potrebbero avere due o più istanze del ruolo di lavoro che accedono alle tabelle in parallelo. Si potrebbero avere singoli ruoli di lavoro responsabili di specifici set di partizioni o semplicemente avere più istanze del ruolo di lavoro, ciascuna in grado di accedere a tutte le partizioni in una tabella.
All'interno di un'istanza del client, è possibile migliorare la velocità effettiva effettuando operazioni di archiviazione in modo asincrono. La libreria client Archiviazione semplifica la scrittura di query e modifiche asincrone. Ad esempio, è possibile iniziare con il metodo sincrono che recupera tutte le entità in una partizione come mostrato nel codice C# seguente:
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
È possibile modificare facilmente questo codice affinché la query venga eseguita in modo asincrono come segue:
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
In questo esempio asincrono è possibile visualizzare le modifiche seguenti dalla versione sincrona:
- La firma del metodo include ora il modificatore async e restituisce un'istanza Task.
- Anziché chiamare il metodo Query per recuperare i risultati, il metodo chiama ora il metodo QueryAsync e usa il modificatore await per recuperare i risultati in modo asincrono.
L'applicazione client può chiamare questo metodo più volte (con valori diversi per il parametro department ) e ogni query verrà eseguita su un thread separato.
È inoltre possibile inserire, aggiornare ed eliminare entità in modo asincrono. Nell'esempio C# seguente viene illustrato un metodo semplice e sincrono per inserire o sostituire un'entità dipendente:
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
È possibile modificare facilmente questo codice affinché l'aggiornamento venga eseguito in modo asincrono come segue:
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
In questo esempio asincrono è possibile visualizzare le modifiche seguenti dalla versione sincrona:
- La firma del metodo include ora il modificatore async e restituisce un'istanza Task.
- Invece di chiamare il metodo Execute per aggiornare l'entità, il metodo ora chiama il metodo ExecuteAsync e usa il modificatore await per recuperare i risultati in modo asincrono.
L'applicazione client può chiamare più metodi asincroni come questo e ogni chiamata al metodo verrà eseguita su un thread separato.