Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
È possibile implementare i modelli di Machine Learning come funzione definita dall'utente (UDF, User-Defined Function) nei processi di Analisi di flusso di Azure per eseguire punteggi e stime in tempo reale sui dati di input del flusso. Azure Machine Learning consente di usare qualsiasi strumento open source diffuso, ad esempio TensorFlow, scikit-learn o PyTorch, per preparare, eseguire il training e distribuire modelli.
Prerequisiti
Completare i passaggi seguenti prima di aggiungere un modello di Machine Learning come funzione al processo di Analisi di flusso di Azure:
Usare Azure Machine Learning per distribuire il modello come servizio Web.
L'endpoint di Machine Learning deve avere un swagger associato che aiuti Stream Analytics a comprendere lo schema dell'input e dell'output. È possibile usare questa definizione di swagger di esempio come riferimento per assicurarsi di averla configurata correttamente.
Assicurarsi che il servizio Web accetti e restituisca i dati serializzati JSON.
Distribuire il modello nel servizio Azure Kubernetes per distribuzioni di produzione su larga scala. Se il servizio Web non è in grado di gestire il numero di richieste provenienti dal tuo lavoro, le prestazioni del processo di Stream Analytics verranno compromesse, il che influisce sulla latenza. I modelli distribuiti nelle istanze di Azure Container sono supportati solo se si usa il portale di Azure.
Aggiungere un modello di apprendimento automatico al tuo lavoro
È possibile aggiungere funzioni di Azure Machine Learning al processo di Analisi di flusso direttamente dal portale di Azure o Visual Studio Code.
Portale di Azure
Accedi al tuo processo Stream Analytics nel portale Azure e seleziona Funzioni sotto Topologia del processo. Quindi, selezionare Azure Machine Learning Service dal menu a discesa + Aggiungi.
Compilare il modulo della funzione del servizio Azure Machine Learning immettendo i valori di proprietà seguenti:
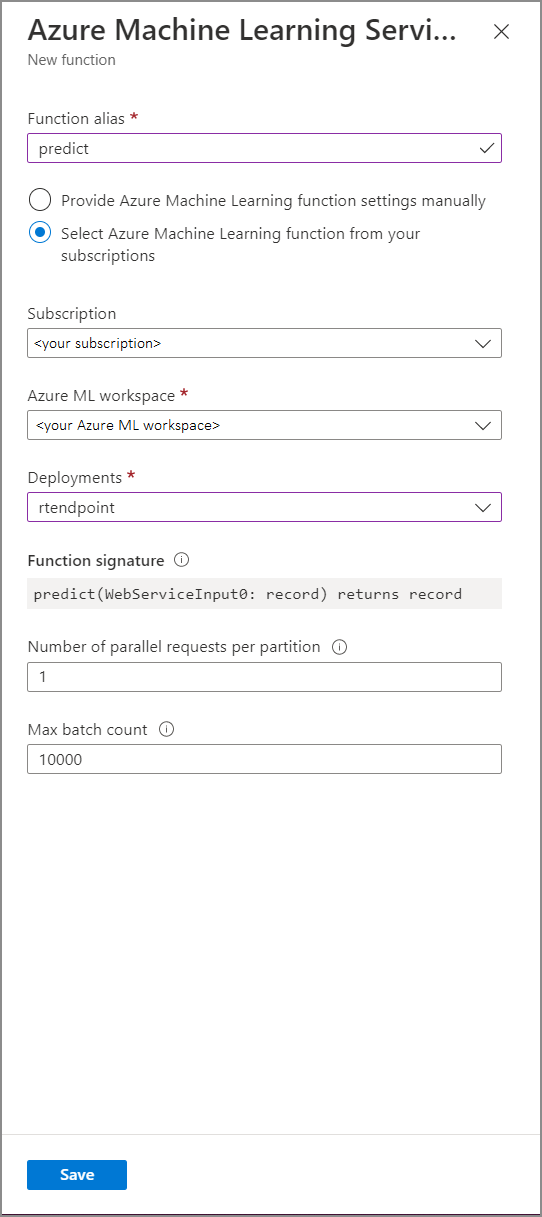
La tabella seguente descrive ogni proprietà delle funzioni del servizio Azure Machine Learning in Analisi di flusso.
| Proprietà | Descrizione |
|---|---|
| Alias di funzione | Immettere un nome per richiamare la funzione nella query. |
| Abbonamento | La sottoscrizione di Azure. |
| Azure Machine Learning workspace (Area di lavoro di Azure Machine Learning) | L'area di lavoro di Azure Machine Learning usata per distribuire il modello come servizio Web. |
| Endpoint | Il servizio Web che ospita il modello. |
| Firma della funzione | La firma del servizio Web dedotta dalla specifica dello schema dell'API. Se non è possibile caricare la firma, verificare di aver specificato l'input e l'output di esempio nello script di assegnazione dei punteggi per la generazione automatica dello schema. |
| Numero di richieste parallele per partizione | Si tratta di una configurazione avanzata per ottimizzare il throughput ad alta scalabilità. Questo numero rappresenta le richieste simultanee inviate da ogni partizione del processo al servizio Web. I processi con sei unità di streaming (SU, Streaming Unit) o meno hanno una partizione. I processi con 12 unità di streaming hanno due partizioni, quelli con 18 unità di streaming ne hanno tre e così via. Se, ad esempio, il processo ha due partizioni e si imposta questo parametro sul valore quattro, saranno presenti otto richieste simultanee dal processo al servizio Web. |
| Numero massimo di batch | Questa è una configurazione avanzata per ottimizzare la larghezza di banda su vasta scala. Questo numero rappresenta il numero massimo di eventi raggruppati in una singola richiesta inviata al servizio Web. |
Chiamata dell'endpoint di Machine Learning dalla tua Query
Quando la query di Azure Stream Analytics richiama un UDF di Azure Machine Learning, il processo crea una richiesta serializzata JSON per il servizio Web. La richiesta si basa su uno schema specifico per il modello che Analisi del flusso deduce dallo Swagger dell'endpoint.
Avviso
Gli endpoint di Machine Learning non vengono chiamati quando si esegue il test con l'editor di query portale di Azure perché il processo non è in esecuzione. Per testare la chiamata dell'endpoint dal portale, è necessario eseguire il processo di Analisi di flusso.
La query di Analisi di flusso di Azure seguente rappresenta un esempio di come richiamare una funzione definita dall'utente di Azure Machine Learning:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Se i dati di input inviati alla funzione definita dall'utente di Machine Learning non sono coerenti con lo schema previsto, l'endpoint restituirà una risposta con codice di errore 400, che farà passare il lavoro di Analisi del flusso in uno stato di errore. È consigliabile abilitare i log delle risorse per il job, per consentire di eseguire facilmente il debug e risolvere tali problemi. È quindi fortemente consigliabile che si:
- Convalidare che l'input per la funzione definita dall'utente ML non sia nullo
- Validare il tipo di ciascun campo che rappresenta un input per la UDF di ML per assicurarsi che corrisponda a quello previsto dall'endpoint.
Nota
Le funzioni definite dall'utente ML vengono valutate per ogni riga di una determinata fase di query, anche quando vengono chiamate tramite un'espressione condizionale (ad esempio CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END). Se necessario, usare la clausola WITH per creare percorsi divergenti, chiamando la funzione definita dall'utente ML solo se necessario, prima di usare UNION per unire nuovamente i percorsi.
Passare più parametri di input alla funzione definita dall'utente
Gli esempi di input ai modelli di Machine Learning più comuni sono le matrici NumPy e DataFrame. È possibile creare una matrice usando una funzione definita dall'utente JavaScript e creare un DataFrame serializzato JSON usando la clausola WITH.
Creare una matrice di input
È possibile creare una funzione definita dall'utente JavaScript in grado di accettare un numero N di input e di creare una matrice che può essere usata come input per la funzione definita dall'utente di Azure Machine Learning.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
Dopo aver aggiunto la UDF JavaScript al processo, è possibile invocare la UDF di Azure Machine Learning utilizzando la query seguente:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
Di seguito è riportata una richiesta JSON di esempio:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Creare un DataFrame Pandas o PySpark
È possibile usare la clausola WITH per creare un DataFrame serializzato JSON che può essere passato come input alla funzione definita dall'utente di Azure Machine Learning, come illustrato di seguito.
La query seguente crea un DataFrame selezionando i campi necessari e utilizza il DataFrame come input per la UDF di Azure Machine Learning.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
Di seguito è riportata una richiesta JSON di esempio dalla query precedente:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Ottimizzare le prestazioni degli UDF di Azure Machine Learning
Quando si distribuisce il modello nel servizio Azure Kubernetes, è possibile profilare il modello per determinare l'utilizzo delle risorse. È anche possibile abilitare App Insights per le distribuzioni al fine di comprendere la frequenza delle richieste, i tempi di risposta e le percentuali di errore.
In uno scenario con velocità effettiva degli eventi elevata, potrebbe essere necessario modificare i parametri seguenti in Analisi di flusso di Azure per ottenere prestazioni ottimali con latenze end-to-end minime:
- Numero massimo di batch.
- Numero di richieste parallele per partizione.
Determinare le dimensioni corrette della batch
Dopo aver implementato il servizio web, devi inviare una richiesta di esempio con dimensioni batch variabili a partire da 50 e aumentandola in incrementi di centinaia. Ad esempio, 200, 500, 1000, 2000 e così via. Si noterà che dopo una determinata dimensione di batch, aumenterà la latenza della risposta. Il punto dopo il quale la latenza della risposta aumenta dovrebbe corrispondere al numero massimo di batch del processo.
Determinare il numero di richieste parallele per partizione
In condizioni di scalabilità ottimale, il processo di Analisi di flusso di Azure dovrebbe essere in grado di inviare più richieste parallele al servizio Web e ottenere una risposta entro pochi millisecondi. La latenza della risposta del servizio web può influire direttamente sulla latenza e sulle prestazioni del job di Stream Analytics. Se la chiamata dal processo al servizio Web impiega molto tempo, è probabile che si verifichi un aumento del ritardo limite e anche del numero di eventi di input con backlog.
È possibile ottenere una bassa latenza assicurandosi che sia stato effettuato il provisioning del cluster servizio Azure Kubernetes (AKS) con il numero corretto di nodi e repliche. È fondamentale che il servizio Web disponga di disponibilità elevata e restituisca risposte con esito positivo. Se il processo riceve un errore che può essere ritentato, ad esempio una risposta servizio non disponibile (503), verrà eseguito automaticamente un nuovo tentativo con ritardo esponenziale. Se il processo riceve uno di questi errori come risposta dall'endpoint, il processo passerà a uno stato non riuscito.
- Richiesta non valida (400)
- Conflitto (409)
- Non trovato (404)
- Non autorizzato (401)
Limiti
Se si usa un servizio endpoint gestito di Azure ML, Analisi di flusso può attualmente accedere solo agli endpoint con accesso alla rete pubblica abilitato. Altre informazioni sono disponibili nella pagina relativa agli endpoint privati di Azure ML.