Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Analisi di flusso di Azure supporta Azure SQL Database come output per la query di streaming. Questo articolo illustra come usare database SQL come output per il processo di Analisi di flusso nell'portale di Azure.
Prerequisiti
Creare un processo di Analisi di flusso.
Creare un database Azure SQL in cui il processo di Analisi di flusso scriverà l'output.
Scrivere in una nuova tabella in database SQL
Questa sezione descrive come configurare il processo per scrivere in una tabella nel database di Azure SQL che non è ancora stato creato.
Nel processo di Analisi di flusso selezionare Output in Topologia processo. Fare clic su Aggiungi e scegliere database SQL.

Selezionare un alias di output che verrà usato nella query del processo. Specificare il nome del database e la modalità di autenticazione. Altre informazioni sulle opzioni di configurazione dell'output SQL sono disponibili.
Immettere un nome di tabella che si vuole creare nel database di Azure SQL. Fare clic su Save (Salva). Nota: il salvataggio di questo output non crea la tabella nel database SQL. I passaggi successivi forniscono altri dettagli sulla creazione della tabella.
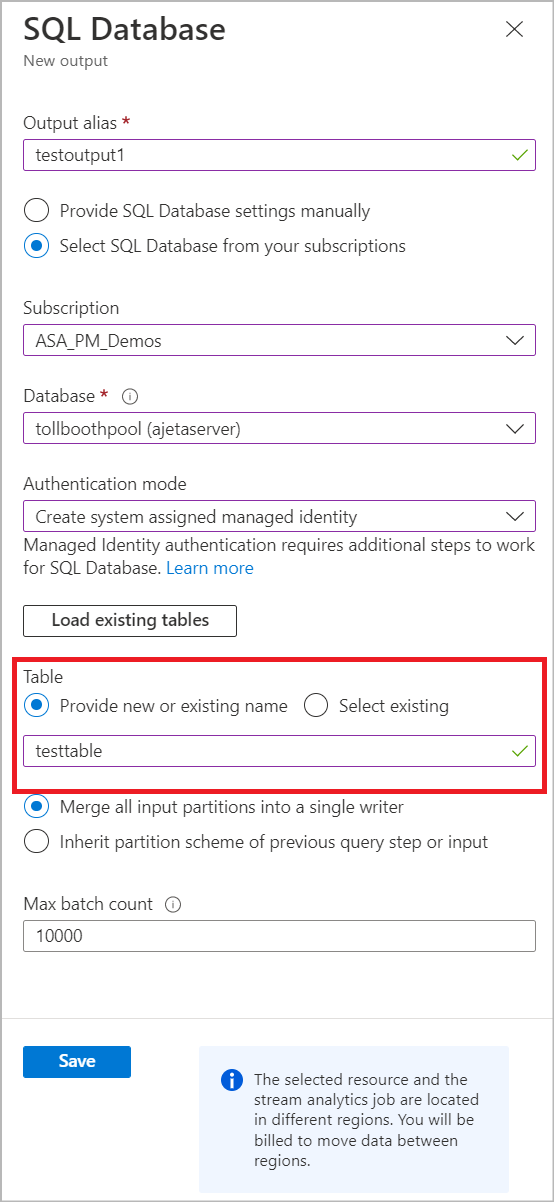
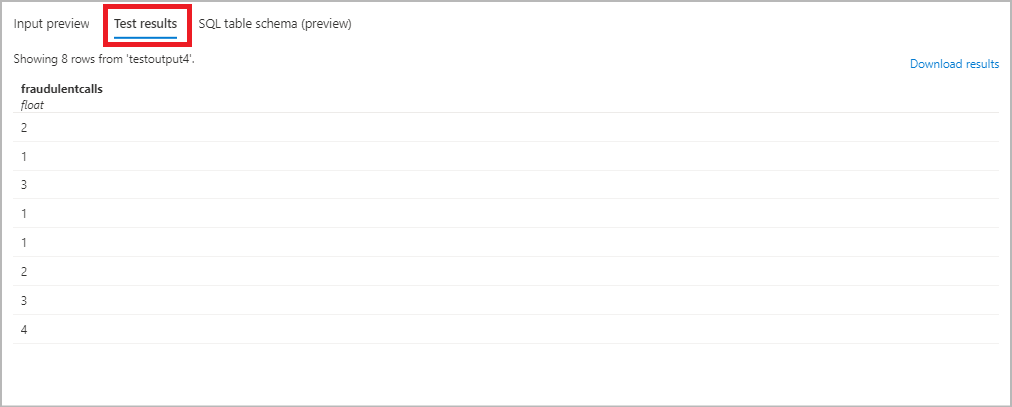
Selezionare Query in Topologiaprocesso e usare l'alias nella query per scrivere l'output nel nome della tabella specificato nel passaggio precedente. Fare clic su Test query per testare la logica di query e visualizzare i risultati del test che mostra lo schema dell'output che verrà prodotto dal processo. Nota: per testare la query, è necessario disporre di dati di streaming in ingresso nell'origine di input oppure è possibile caricare dati di esempio per eseguire il test della query. Per altre informazioni sulla query di Analisi di flusso di test, vedere Analisi di flusso.

Fare clic su Schema tabella SQL per visualizzare il nome e il tipo di colonna. Fare clic su Crea tabella e la tabella verrà creata nel database SQL.

Se la query di Analisi di flusso viene modificata per produrre uno schema diverso, è necessario modificare la definizione della tabella nel database SQL. Ciò garantisce che il processo di Analisi di flusso non verifichi errori di conversione dei dati durante il tentativo di scrittura nel sink.
Dopo aver completato la query, selezionare Panoramica e Avviare il processo. È quindi possibile passare alla tabella database SQL per visualizzare l'output della query di streaming.





Selezionare una tabella esistente da database SQL
Questa sezione descrive come configurare il processo per scrivere in una tabella già esistente nel database di Azure SQL.
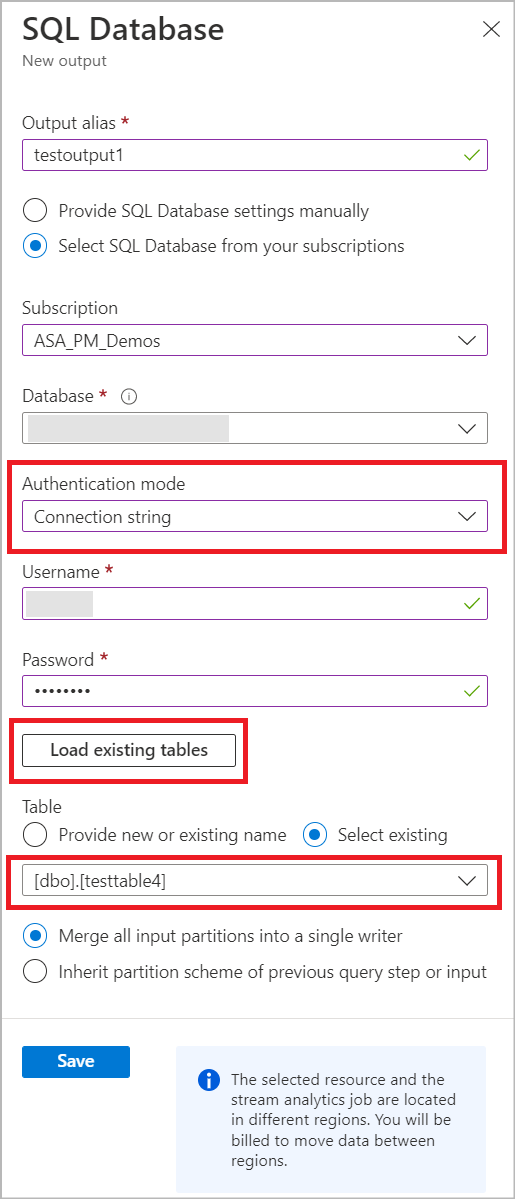
Nel processo di Analisi di flusso selezionare Output in Topologia processo. Fare clic su Aggiungi e scegliere database SQL.
Selezionare un alias di output che verrà usato nella query del processo. Specificare il nome del database e la modalità di autenticazione. Altre informazioni sulle opzioni di configurazione dell'output SQL sono disponibili.
È possibile selezionare una tabella esistente dal database SQL selezionato immettendo i dettagli di autenticazione SQL. Verrà caricato un elenco di nomi di tabella dal database. Selezionare il nome della tabella dall'elenco o immettere manualmente il nome della tabella e Salva.
Selezionare Query in Topologia processo e usare il nome alias nella query per scrivere l'output nella tabella selezionata. Fare clic su Test query per testare la logica di query e visualizzare i risultati del test. Nota: per testare la query, è necessario disporre di dati di streaming in ingresso in Hub eventi/hub IoT oppure è possibile caricare dati di esempio per eseguire query di test. Per altre informazioni sulla query di Analisi di flusso di test, vedere Analisi di flusso.
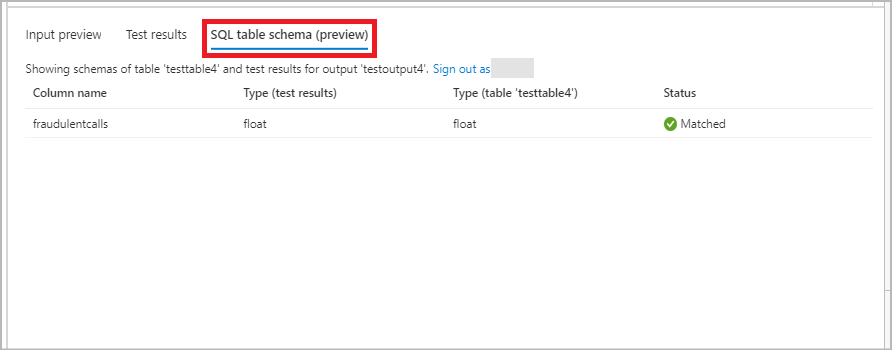
Nella scheda Schema tabella SQL è possibile visualizzare un nome di colonna e il relativo tipo dai dati in ingresso e nella tabella selezionata. È possibile visualizzare lo stato se il tipo di dati in ingresso e la tabella SQL selezionata corrispondono o meno. Se non è una corrispondenza, verrà richiesto di aggiornare la query in modo che corrisponda allo schema della tabella.
Dopo aver completato la query, selezionare Panoramica e Avviare il processo. È quindi possibile passare alla tabella database SQL per visualizzare l'output della query di streaming.


Motivi comuni di mancata corrispondenza dei tipi di dati
È importante assicurarsi che l'output del processo di Analisi di flusso corrisponda ai nomi delle colonne e ai tipi di dati previsti dalla tabella database SQL. Se si verifica una mancata corrispondenza, il processo verrà eseguito in errori di conversione dei dati e riprovare continuamente fino a quando non viene modificata la definizione della tabella SQL. È possibile modificare il comportamento del processo per eliminare tale output che causa errori di conversione dei dati e procedere al successivo. Di seguito sono descritti i motivi di mancata corrispondenza dello schema più comuni.
- Mancata corrispondenza dei tipi di tipo: i tipi di query e di destinazione non sono compatibili. Le righe non verranno inserite nella destinazione. Usare una funzione di conversione , ad esempio TRY_CAST() per allineare i tipi nella query. L'opzione alternativa consiste nel modificare la tabella di destinazione nel database SQL.
- Intervallo: l'intervallo di tipi di destinazione è notevolmente inferiore a quello usato nella query. Le righe con valori out-of-range potrebbero non essere inseriti nella tabella di destinazione o troncati. È consigliabile modificare la colonna di destinazione in un intervallo di tipi più grande.
- Implicito: i tipi di query e di destinazione sono diversi ma compatibili. I dati verranno convertiti in modo implicito, ma ciò potrebbe causare la perdita o gli errori dei dati. Usare una funzione di conversione , ad esempio TRY_CAST() per allineare i tipi nella query o modificare la tabella di destinazione.
- Record: questo tipo non è ancora supportato per questo output. Il valore verrà sostituito dalla stringa 'record'. È consigliabile analizzare i dati o usare una funzione definita dall'utente per la conversione in stringa.
- Matrice: questo tipo non è ancora supportato in modo nativo nel database di Azure SQL. Il valore verrà sostituito dalla stringa 'record'. È consigliabile analizzare i dati o usare una funzione definita dall'utente per la conversione in stringa.
- Colonna mancante dalla tabella di destinazione: questa colonna manca dalla tabella di destinazione. I dati non verranno inseriti. Aggiungere questa colonna alla tabella di destinazione, se necessario.
Passaggi successivi
- Usare i dati di riferimento SQL come origine di input
- Informazioni di riferimento sul linguaggio di query di Analisi di flusso di Azure
- Esempi di query per modelli di uso comune di Analisi di flusso
- Informazioni sugli input per Analisi di flusso di Azure
- Informazioni sugli output di Analisi di flusso di Azure