Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Azure Synapse Analytics Data Explorer (Anteprima) verrà ritirato il 7 ottobre 2025. Dopo questa data, i carichi di lavoro in esecuzione in Synapse Data Explorer verranno eliminati e i dati dell'applicazione associati andranno persi. È consigliabile eseguire la migrazione a Eventhouse in Microsoft Fabric.
Il programma Microsoft Cloud Migration Factory (CMF) è progettato per aiutare i clienti a eseguire la migrazione a Fabric. Il programma offre risorse pratiche per la tastiera a nessun costo per il cliente. Queste risorse vengono assegnate per un periodo di 6-8 settimane, con un ambito predefinito e concordato. Le nomination dei clienti vengono accettate dal team dell'account Microsoft o direttamente inviando una richiesta di assistenza al team CMF.
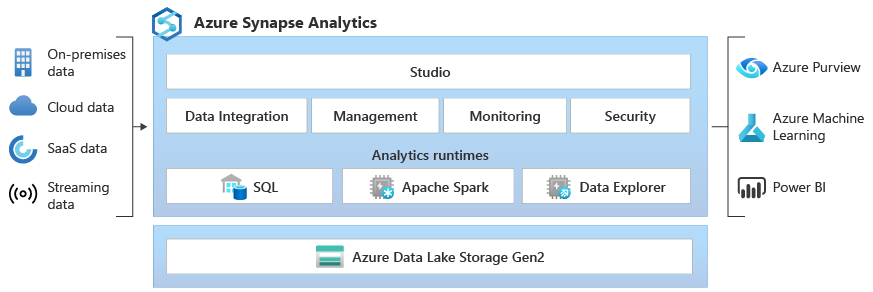
Esplora dati di Azure Synapse offre ai clienti un'esperienza di query interattiva per sbloccare informazioni dettagliate dai dati di log e telemetria. Per integrare i motori di runtime di analisi sql e Apache Spark esistenti, il runtime di analisi di Esplora dati è ottimizzato per l'analisi efficiente dei log usando una potente tecnologia di indicizzazione per indicizzare automaticamente i dati senza testo e semistrutturati comunemente trovati nei dati di telemetria.
Per altre informazioni, vedere il video seguente:
Che cosa rende Azure Synapse Data Explorer univoco?
Inserimento semplice - L'Esplora dati offre integrazioni predefinite per l'inserimento di dati no-code/low-code, l'inserimento di dati ad alta capacità e la memorizzazione nella cache dei dati da origini in tempo reale. I dati possono essere inseriti da origini come Hub eventi di Azure, Kafka, Azure Data Lake, agenti open source come Fluentd/Fluent Bit e un'ampia gamma di origini dati cloud e locali.
Nessuna modellazione dei dati complessa : con Esplora dati non è necessario creare modelli di dati complessi e non è necessario creare script complessi per trasformare i dati prima che venga usato.
Nessuna manutenzione dell'indice : non è necessario eseguire attività di manutenzione per ottimizzare i dati per le prestazioni delle query e non è necessaria alcuna manutenzione dell'indice. Con Data Explorer, tutti i dati non elaborati sono immediatamente disponibili, permettendo di eseguire query ad alte prestazioni e alta concorrenza sui dati in streaming e persistenti. È possibile usare queste query per creare dashboard e avvisi quasi in tempo reale e connettere i dati di analisi operativa al resto della piattaforma di analisi dei dati.
Democratizzazione dell'analisi dei dati - Data Explorer democratizza l'analisi dei Big Data e self-service con l'intuitivo linguaggio di query Kusto (KQL) che offre l'espressività e la potenza di SQL con la semplicità di Excel. KQL è altamente ottimizzato per l'esplorazione dei dati di telemetria non elaborati e delle serie temporali sfruttando la tecnologia di indicizzazione di testo di classe migliore di Esplora dati per una ricerca efficiente di testo libero ed espressione regolare e funzionalità di analisi complete per l'esecuzione di query su tracce\dati di testo e dati semistrutturati JSON, incluse matrici e strutture annidate. KQL offre supporto avanzato per serie temporali per la creazione, la modifica e l'analisi di più serie temporali con il supporto dell'esecuzione python nel motore per l'assegnazione dei punteggi dei modelli.
Tecnologia collaudata su scala petabyte : Esplora dati è un sistema distribuito con risorse di calcolo e archiviazione che può essere ridimensionato in modo indipendente, abilitando l'analisi su gigabyte o petabyte di dati.
Integrato: Azure Synapse Analytics offre interoperabilità tra i dati tra Esplora dati, Apache Spark e i motori SQL che consentono a data engineer, data scientist e analisti dei dati di accedere e collaborare in modo semplice e sicuro sugli stessi dati nel data lake.
Quando usare Esplora dati di Azure Synapse?
Utilizzare Data Explorer come piattaforma dati per sviluppare soluzioni di analisi dei log quasi in tempo reale e di analisi IoT per:
Consolidare e correlare i dati di log ed eventi provenienti da origini dati locali, cloud e di terze parti.
Accelerare il percorso delle operazioni di intelligenza artificiale (riconoscimento dei modelli, rilevamento anomalie, previsione e altro ancora).
Sostituire le soluzioni di ricerca log basate sull'infrastruttura per risparmiare sui costi e aumentare la produttività.
Creare soluzioni di analisi IoT per i dati IoT.
Creare soluzioni SaaS di analisi per offrire servizi ai clienti interni ed esterni.
Architettura del pool di Data Explorer
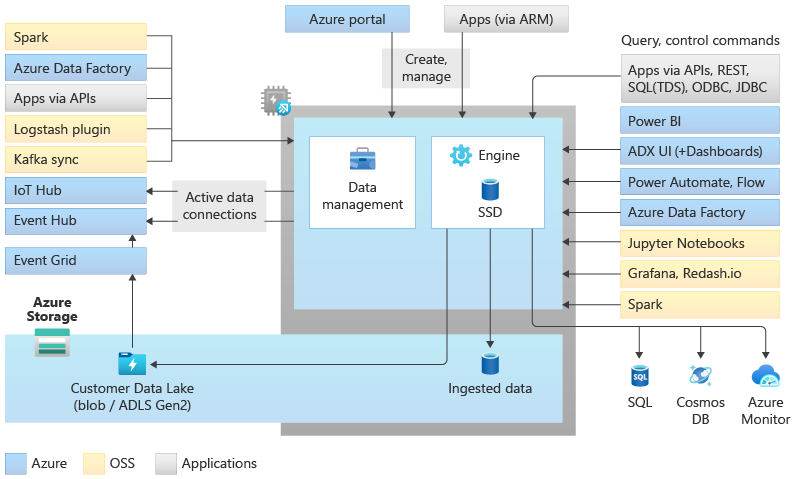
I pool di Esplora dati implementano un'architettura con scalabilità orizzontale separando le risorse di calcolo e archiviazione. In questo modo è possibile ridimensionare in modo indipendente ogni risorsa e, ad esempio, eseguire più calcoli di sola lettura sugli stessi dati. I pool di Esplora dati sono costituiti da un set di risorse di calcolo che eseguono il motore responsabile dell'indicizzazione automatica, della compressione, della memorizzazione nella cache e della gestione delle query distribuite. Possiedono anche un secondo set di risorse di calcolo che eseguono il servizio di gestione dei dati, responsabile dei lavori di sistema in background e dell'ingestione dati gestita e messa in coda. Tutti i dati vengono salvati in modo permanente in account di archiviazione BLOB gestiti usando un formato a colonne compresso.
I pool di Esplora dati supportano un ecosistema avanzato per l'inserimento di dati tramite connettori, SDK, API REST e altre funzionalità gestite. Offre diversi modi per usare i dati per query ad hoc, report, dashboard, avvisi, API REST e SDK.
Esistono molte funzionalità uniche che rendono Data Explore il miglior motore analitico per l'analisi dei log e delle serie temporali in Azure.
Le sezioni seguenti evidenziano i principali fattori di differenziazione.
L'indicizzazione di dati semistrutturati e di testo libero consente prestazioni elevate quasi in tempo reale e query simultanee elevate
Data Explorer indicizza dati semistrutturati (JSON) e dati non strutturati (testo libero), permettendo alle query di avere buone prestazioni su questo tipo di dati. Per impostazione predefinita, ogni campo viene indicizzato durante l'inserimento dei dati con l'opzione per usare criteri di codifica di basso livello per ottimizzare o disabilitare l'indice per campi specifici. L'ambito dell'indice è una singola partizione di dati.
L'implementazione dell'indice dipende dal tipo di campo, come indicato di seguito:
| Tipo di campo | Implementazione dell'indicizzazione |
|---|---|
| Stringa | Il motore genera un indice di termini invertito per i valori delle colonne di tipo stringa. Ogni valore stringa viene analizzato e suddiviso in termini normalizzati e un elenco ordinato di posizioni logiche, contenenti ordinali di record, viene registrato per ogni termine. L'elenco ordinato risultante di termini e le relative posizioni associate vengono archiviate come albero B non modificabile. |
|
Numerico DateTime TimeSpan |
Il motore compila un semplice indice forward basato su intervallo. L'indice registra i valori min/max per ogni blocco, per un gruppo di blocchi e per l'intera colonna all'interno della partizione di dati. |
| Dinamico | Il processo di inserimento enumera tutti gli elementi "atomici" all'interno del valore dinamico, ad esempio i nomi delle proprietà, i valori e gli elementi della matrice e li inoltra al generatore di indici. I campi dinamici hanno lo stesso indice di termini invertito dei campi stringa. |
Queste funzionalità di indicizzazione efficienti consentono a Esplora dati di rendere i dati disponibili quasi in tempo reale per query ad alte prestazioni e concorrenza elevata. Il sistema ottimizza automaticamente le partizioni di dati per migliorare ulteriormente le prestazioni.
Kusto Query Language (linguaggio di interrogazione Kusto)
KQL ha una community di grandi dimensioni e in crescita con l'adozione rapida di Azure Monitor Log Analytics e Application Insights, Microsoft Sentinel, Azure Data Explorer e altre offerte Microsoft. Il linguaggio è ben progettato con una sintassi facile da leggere e offre una transizione uniforme da semplici righe a query complesse di elaborazione dei dati. Ciò consente a Esplora dati di fornire supporto avanzato per IntelliSense e un set completo di costrutti di linguaggio e funzionalità predefinite per aggregazioni, serie temporali e analisi utente non disponibili in SQL per l'esplorazione rapida dei dati di telemetria.