Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Azure Synapse Analytics Data Explorer (Anteprima) verrà ritirato il 7 ottobre 2025. Dopo questa data, i carichi di lavoro in esecuzione in Synapse Data Explorer verranno eliminati e i dati dell'applicazione associati andranno persi. È consigliabile eseguire la migrazione a Eventhouse in Microsoft Fabric.
Il programma Microsoft Cloud Migration Factory (CMF) è progettato per aiutare i clienti a eseguire la migrazione a Fabric. Il programma offre risorse pratiche per la tastiera a nessun costo per il cliente. Queste risorse vengono assegnate per un periodo di 6-8 settimane, con un ambito predefinito e concordato. Le nomination dei clienti vengono accettate dal team dell'account Microsoft o direttamente inviando una richiesta di assistenza al team CMF.
L'inserimento dati è il processo usato per caricare i record di dati da una o più origini per importare dati in una tabella nel pool di Esplora dati di Azure Synapse. Una volta inseriti, i dati diventano disponibili per le query.
Il servizio di gestione dei dati di Esplora dati di Azure Synapse, responsabile dell'inserimento dati, implementa il processo seguente:
- Esegue il pull dei dati in batch o in streaming da un'origine esterna e legge le richieste da una coda di Azure in sospeso.
- Il flusso di dati batch nello stesso database e nella stessa tabella è ottimizzato per la velocità effettiva di inserimento.
- I dati iniziali vengono convalidati e il formato viene convertito, se necessario.
- Ulteriori modifiche ai dati, tra cui lo schema corrispondente, l'organizzazione, l'indicizzazione, la codifica e la compressione dei dati.
- I dati vengono salvati in modo permanente nell'archiviazione in base ai criteri di conservazione impostati.
- I dati inseriti vengono confermati nel motore, dove sono disponibili per le interrogazioni.
Formati di dati, proprietà e autorizzazioni supportati
Proprietà di inserimento: proprietà che influiscono sulla modalità di inserimento dei dati( ad esempio, assegnazione di tag, mapping, ora di creazione).
Autorizzazioni: per inserire i dati, il processo richiede autorizzazioni a livello di ingestor del database. Altre azioni, ad esempio query, possono richiedere autorizzazioni di amministratore del database, utente del database o amministratore tabella.
Invio in batch e inserimenti in streaming
L'inserimento in batch esegue l'invio in batch dei dati ed è ottimizzato per una velocità effettiva di inserimento elevata. Questo metodo è il tipo di inserimento preferito e più efficiente. I dati vengono raggruppati in base alle proprietà di inserimento. I batch di dati di piccole dimensioni vengono uniti e ottimizzati per ottenere risultati di query veloci. I criteri di inserimento in batch possono essere impostati su database o tabelle. Per impostazione predefinita, il valore massimo di invio in batch è 5 minuti, 1000 elementi o una dimensione totale di 1 GB. Il limite di dimensioni dei dati per un comando di inserimento batch è di 4 GB.
L'ingestione in streaming è l'inserimento continuo di dati da un'origine di streaming. Consente una latenza quasi in tempo reale per set di dati di piccole dimensioni per tabella. I dati vengono inizialmente inseriti nell'archivio righe, quindi spostati negli extent dell'archivio colonne.
Metodi e strumenti di ingestione
Esplora dati di Azure Synapse supporta diversi metodi di inserimento, ognuno con scenari di destinazione specifici. Questi metodi includono strumenti di inserimento, connettori e plug-in per servizi diversi, pipeline gestite, inserimento a livello di codice tramite SDK e accesso diretto all'inserimento.
Inserimento di dati tramite pipeline gestite
Per le organizzazioni che desiderano affidare l'amministrazione (regolazione, tentativi, monitoraggio, avvisi e altro ancora) a un servizio esterno, il ricorso a un connettore è verosimilmente la soluzione più opportuna. L'inserimento in coda è appropriato per volumi di dati di grandi dimensioni. Azure Synapse Data Explorer supporta le seguenti pipeline di Azure:
- Hub eventi: Un flusso di dati che trasferisce eventi dai servizi a Esplora dati di Azure Synapse. Per altre informazioni, vedere Inserire dati dall'hub eventi in Esplora dati di Azure Synapse.
- Pipeline di Synapse: un servizio di integrazione dei dati completamente gestito per i carichi di lavoro analitici nelle pipeline di Synapse si connette con più di 90 origini supportate per offrire un trasferimento dati efficiente e resiliente. Le pipeline di Synapse preparano, trasformano e arricchiscono i dati per fornire informazioni dettagliate che possono essere monitorate in diversi tipi di modi. Questo servizio può essere usato come soluzione una tantum, in una sequenza temporale periodica o attivato da eventi specifici.
Inserimento a livello di codice tramite SDK
Azure Synapse Data Explorer offre SDK che possono essere usati per le query e l'ingestione dei dati. L'inserimento a livello di codice è ottimizzato per ridurre i costi di inserimento (COG), riducendo al minimo le transazioni di archiviazione durante e seguendo il processo di inserimento.
Prima di iniziare, utilizzate i seguenti passaggi per ottenere gli endpoint del pool di Data Explorer necessari per configurare l'inserimento programmatico.
Nel riquadro sinistro di Synapse Studio selezionare Gestisci>Pool di Esplora dati.
Selezionare il pool di Esplora dati da usare per visualizzarne i dettagli.
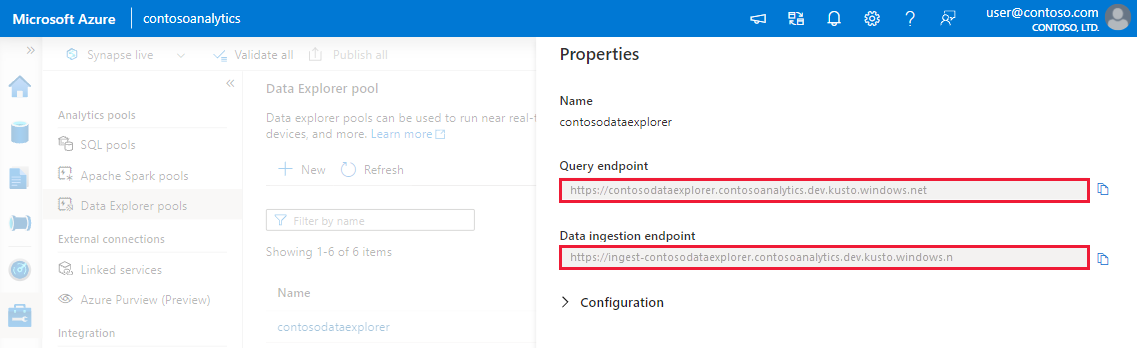
Prendere nota degli endpoint di query e inserimento dati. Usare l'endpoint Query come cluster durante la configurazione delle connessioni al pool di Data Explorer. Quando si configurano gli SDK per l'inserimento dati, usare l'endpoint di inserimento dati.
SDK disponibili e progetti open source
Attrezzi
- Inserimento con un clic: consente di inserire rapidamente i dati creando e modificando le tabelle da un'ampia gamma di tipi di origine. L'inserimento con un clic suggerisce automaticamente tabelle e strutture di mapping basate sull'origine dati in Esplora dati di Azure Synapse. L'inserimento con un clic può essere usato per l'inserimento monouso o per definire l'inserimento continuo tramite Griglia di eventi nel contenitore in cui sono stati inseriti i dati.
Comandi di controllo di acquisizione del Linguaggio di Query Kusto
Esistono diversi metodi in base ai quali i dati possono essere inseriti direttamente nel motore tramite i comandi KQL (Kusto Query Language). Poiché questo metodo ignora i servizi di gestione dati, è appropriato solo per l'esplorazione e la creazione di prototipi. Non usare questo metodo negli scenari di produzione o di volumi elevati.
Inserimento inline: viene inviato un comando di controllo .ingest inline al motore, con i dati da inserire come parte del testo del comando stesso. Questo metodo è destinato a scopi di test improvvisati.
Inserimento dalla query: un comando di controllo .set, .append, .set-or-append o .set-or-replace viene inviato al motore, con i dati specificati indirettamente come risultati di una query o di un comando.
it-IT: Inserimento dall'archiviazione (pull): un comando di controllo .ingest into viene inviato al motore, con i dati archiviati in una risorsa di archiviazione esterna (ad esempio, Archiviazione BLOB di Azure) accessibile dal motore e specificato dal comando.
Per un esempio di uso dei comandi di controllo di inserimento, vedere Analizzare con Esplora dati.
Processo di ingestione
Dopo aver scelto il metodo di inserimento più adatto alle proprie esigenze, seguire questa procedura:
Impostare i criteri di conservazione
I dati inseriti in una tabella in Esplora dati di Azure Synapse sono soggetti ai criteri di conservazione effettivi della tabella. A meno che non sia impostato in modo esplicito in una tabella, i criteri di conservazione effettivi derivano dai criteri di conservazione del database. La conservazione dei dati ad accesso frequente è una funzione delle dimensioni del cluster e della tua politica di conservazione. L'inserimento di dati superiori allo spazio disponibile costringerà i primi dati a essere trasferiti in conservazione a lungo termine.
Assicurarsi che i criteri di conservazione del database siano appropriati per le proprie esigenze. In caso contrario, eseguirne l'override in modo esplicito a livello di tabella. Per altre informazioni, vedere Criteri di conservazione.
Creare una tabella
Per inserire i dati, è necessario creare una tabella in anticipo. Usare una delle opzioni seguenti:
Crea una tabella con un comando. Per un esempio di utilizzo del comando create a table, vedere Analizzare con Esplora dati.
Creare una tabella usando l'inserimento con un clic.
Annotazioni
Se un record è incompleto o non è possibile analizzare un campo come tipo di dati richiesto, le colonne della tabella corrispondenti verranno popolate con valori Null.
Creare il mapping dello schema
Il mapping dello schema consente di associare i campi dati di origine alle colonne della tabella di destinazione. Il mapping consente di acquisire dati da origini diverse nella stessa tabella, in base agli attributi definiti. Sono supportati diversi tipi di mapping, sia orientati alle righe (CSV, JSON e AVRO) che orientati alle colonne (Parquet). Nella maggior parte dei metodi, i mapping possono anche essere pre-creati nella tabella e a cui viene fatto riferimento dal parametro del comando di inserimento.
Impostare i criteri di aggiornamento (facoltativo)
Alcuni dei mapping dei formati di dati (Parquet, JSON e Avro) supportano trasformazioni semplici e utili in fase di inserimento. Quando lo scenario richiede un'elaborazione più complessa in fase di inserimento, usare i criteri di aggiornamento, che consentono l'elaborazione leggera usando i comandi del linguaggio di query Kusto. I criteri di aggiornamento eseguono automaticamente estrazione e trasformazioni sui dati inseriti nella tabella originale e inseriscono i dati risultanti in una o più tabelle di destinazione. Impostare i criteri di aggiornamento.