Avvio rapido: inserire dati con Azure Synapse Pipelines (Anteprima)
Questo avvio rapido illustra come caricare dati da un'origine dati nel pool Esplora dati di Azure Synapse.
Prerequisiti
Una sottoscrizione di Azure. Creare un account Azure gratuito.
Creare un pool Esplora dati usando Synapse Studio o il portale di Azure
Creare un database di Esplora dati.
Nel riquadro sinistro di Synapse Studio selezionare Dati.
Selezionare + (Aggiungi nuova risorsa) >Pool Esplora dati e usare le informazioni seguenti:
Impostazione Valore suggerito Descrizione Nome pool contosodataexplorer Nome del pool Esplora dati da usare Nome TestDatabase Il nome del database deve essere univoco all'interno del cluster. Periodo di conservazione predefinito 365 Intervallo di tempo (in giorni) per cui è garantito che i dati rimangano disponibili per le query. L'intervallo di tempo viene misurato dal momento in cui i dati vengono inseriti. Periodo cache predefinito 31 L'intervallo di tempo (in giorni) per cui mantenere i dati sottoposti frequentemente a query disponibili nell'archiviazione su unità SSD o nella RAM, invece che nell'archiviazione a lungo termine. Selezionare Crea per creare il database. Per la creazione è in genere necessario meno di un minuto.
Crea una tabella
- Nel riquadro sinistro di Synapse Studio selezionare Sviluppo.
- In Script KQL selezionare + (Aggiungi nuova risorsa) >Script KQL. Nel riquadro a destra è possibile assegnare un nome allo script.
- Nel menu Connetti a selezionare contosodataexplorer.
- Nel menu Usa database selezionare TestDatabase.
- Incollare il comando seguente e selezionare Esegui per creare una tabella.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Suggerimento
Verificare che la tabella è stata creata correttamente. Nel riquadro a sinistra selezionare Dati, selezionare il contosodataexplorer nel menu Altro e quindi selezionare Aggiorna. In contosodataexplorer espandere Tabelle e assicurarsi che la tabella StormEvents venga visualizzata nell'elenco.
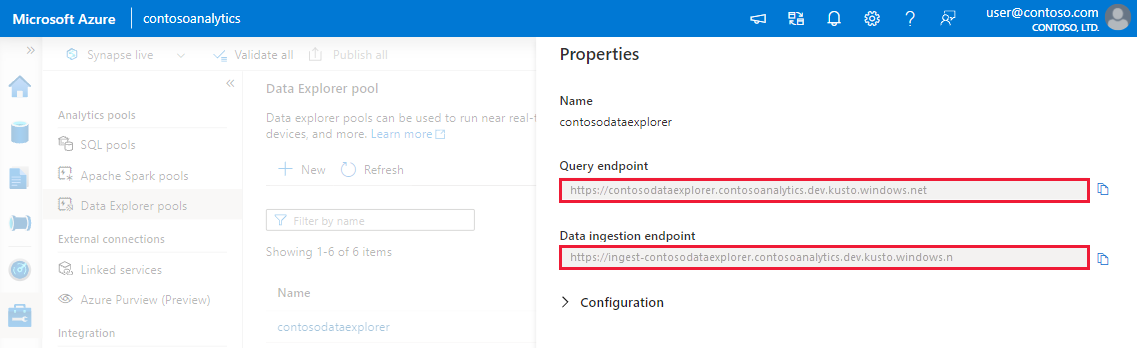
Ottenere gli endpoint di query e inserimento dati. Per configurare il servizio collegato, è necessario l'endpoint Query.
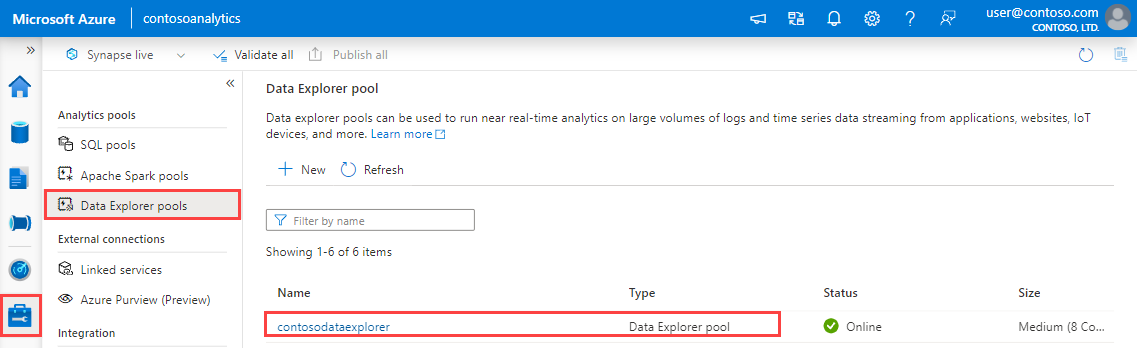
Nel riquadro sinistro di Synapse Studio selezionare Gestisci>Pool Esplora dati.
Selezionare il pool Esplora dati da usare per visualizzarne i dettagli.
Prendere nota degli endpoint di query e inserimento dati. Usare l'endpoint Query come cluster durante la configurazione delle connessioni al pool Esplora dati. Quando si configurano gli SDK per l'inserimento dati, usare l'endpoint di inserimento dati.
Creare un servizio collegato
In Azure Synapse Analytics si usano i servizi collegati per definire le informazioni di connessione ad altri servizi. In questa sezione si creerà un servizio collegato per Esplora dati di Azure.
Nel riquadro sinistro di Synapse Studio selezionare Gestisci>Servizi collegati.
Selezionare + Nuovo.

Selezionare il servizio Esplora dati di Azure dalla raccolta, quindi selezionare Continua.

Nella pagina Nuovi servizi collegati usare le informazioni seguenti:
Impostazione Valore suggerito Description Name contosodataexplorerlinkedservice Nome del nuovo servizio collegato di Esplora dati di Azure. Authentication method Identità gestita Metodo di autenticazione per il nuovo servizio. Metodo di selezione dell'account Immetti manualmente Metodo per specificare l'endpoint Query. Endpoint https://contosodataexplorer.contosoanalytics.dev.kusto.windows.net Endpoint Query annotato in precedenza. Database TestDatabase Database in cui si desidera inserire i dati. 
Seleziona Verifica connessione per verificare le impostazioni, quindi selezionare Crea.
Creare una pipeline per inserire dati
Una pipeline contiene il flusso logico per un'esecuzione di un set di attività. In questa sezione verrà creata una pipeline contenente un'attività di copia che inserisce i dati dall’origine preferita in un pool Esplora dati.
Nel riquadro sinistro di Synapse Studio selezionare Integra.
Selezionare +>Pipeline. Nel riquadro a destra è possibile assegnare un nome alla pipeline.

In Attività>Sposta e trasforma, trascinare Copia dati nel canvas della pipeline.
Selezionare l'attività di copia e passare alla scheda Origine. Selezionare o creare un nuovo set di dati di origine come origine da cui copiare i dati.
Passare alla scheda Sink. Selezionare Nuovo per creare un nuovo set di dati sink.

Selezionare il set di dati Esplora dati di Azure dalla raccolta, quindi selezionare Continua.
Nel riquadro Imposta proprietà usare le informazioni seguenti, quindi selezionare OK.
Impostazione Valore suggerito Description Name AzureDataExplorerTable Nome della nuova pipeline. Servizio collegato contosodataexplorerlinkedservice Servizio collegato creato in precedenza. Tabella StormEvents Tabella creata in precedenza. 
Per convalidare la pipeline, selezionare Convalida sulla barra degli strumenti. Il risultato dell'output di convalida della pipeline viene visualizzato sul lato destro della pagina.
Eseguire il debug della pipeline e pubblicarla
Dopo aver completato la configurazione della pipeline, è possibile eseguire il debug prima di pubblicare gli artefatti per verificare che tutto sia corretto.
Selezionare Debug nella barra degli strumenti. Lo stato dell'esecuzione della pipeline verrà visualizzato nella scheda Output nella parte inferiore della finestra.
Una volta che la pipeline viene eseguita correttamente, sulla barra degli strumenti superiore selezionare Pubblica tutto. Questa azione pubblica le entità create (set di dati e pipeline) create nel servizio Synapse Analytics.
Attendere fino alla visualizzazione del messaggio Pubblicazione riuscita. Per visualizzare i messaggi di notifica, selezionare il pulsante a forma di campana in alto a destra.
Attivare e monitorare la pipeline
In questa sezione si attiverà manualmente la pipeline pubblicata nel passaggio precedente.
Selezionare Aggiungi trigger nella barra degli strumenti, quindi selezionare Attiva adesso. Nella pagina Esecuzione della pipeline selezionare OK.
Passare alla scheda Monitora nella barra laterale sinistra. Viene visualizzata un'esecuzione della pipeline attivata da un trigger manuale.
Al termine dell'esecuzione della pipeline, selezionare il collegamento nella colonna Nome pipeline per visualizzare i dettagli dell'esecuzione attività o per eseguire di nuovo la pipeline. In questo esempio è presente una sola attività, quindi nell'elenco viene visualizzata una sola voce.
Per informazioni dettagliate sull'operazione di copia, selezionare il collegamento Dettagli (icona a forma di occhiali) nella colonna Nome attività. È possibile monitorare dettagli come il volume dei dati copiati dall'origine al sink, la velocità effettiva dei dati, i passaggi di esecuzione con la durata corrispondente e le configurazioni usate.
Per tornare alla visualizzazione delle esecuzioni di pipeline, selezionare il collegamento Tutte le esecuzioni della pipeline in alto. Selezionare Aggiorna per aggiornare l'elenco.
Verificare che i dati siano scritti correttamente nel pool Esplora dati.