Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questo Avvio rapido si creerà un'area di lavoro Synapse ed è possibile seguire le altre esercitazioni per creare un pool SQL dedicato e un pool Apache Spark serverless.
Prerequisiti
- Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Per completare i passaggi di questa esercitazione, è necessario avere accesso a un gruppo di risorse per il quale si dispone del ruolo di proprietario. Creare l'area di lavoro Synapse in questo gruppo di risorse.
Creare un'area di lavoro Synapse nel portale di Azure
Avviare il processo
- Aprire il portale di Azure, quindi nella barra di ricerca immettere Synapse senza premere Invio.
- Nei risultati della ricerca, in Servizi, selezionare Azure Synapse Analytics.
- Selezionare Crea per creare un’area di lavoro.
Scheda Informazioni di base > Dettagli progetto
Specificare i seguenti campi:
- Sottoscrizione - selezionare una sottoscrizione qualsiasi.
- Gruppo di risorse - usare un gruppo di risorse qualsiasi.
- Gruppo di risorse gestite - lasciare vuoto questo campo.
Scheda Informazioni di base > Dettagli dell’area di lavoro
Specificare i seguenti campi:
- Nome dell’area di lavoro - selezionare un nome univoco globale qualsiasi. In questa esercitazione si userà myworkspace.
- Area - Selezionare l'area in cui sono state inserite le applicazioni/i servizi client (ad esempio, Macchina virtuale di Azure, Power BI, Azure Analysis Services) e le risorse di archiviazione che contengono i dati (ad esempio Azure Data Lake Storage, la risorsa di archiviazione analitica di Azure Cosmos DB).
Nota
Un'area di lavoro non condivisa con le applicazioni client o l'archiviazione può essere la causa radice di numerosi problemi di prestazioni. Se i dati o i client vengono inseriti in diverse aree, è possibile creare aree di lavoro separate in regioni differenti co-locate con i dati e i client.
In Selezionare Data Lake Storage Gen2:
In Nome account selezionare Crea nuovo e assegnare al nuovo account di archiviazione il nome contosolake o simile, in quanto deve essere univoco.
Suggerimento
Se viene visualizzato un errore che indica che “Il provider di risorse di Azure Synapse (Microsoft.Synapse) deve essere registrato con la sottoscrizione selezionata, aprire il portale di Azure e selezionare Sottoscrizioni. Selezionare la propria sottoscrizione. Nell'elenco Impostazioni, selezionare Provider di risorse. Cercare Microsoft.Synapse, selezionarlo e selezionare Registra.
In Nome file systemselezionare Crea nuovo e denominarlo utenti. Verrà creato un contenitore denominato utenti. L'area di lavoro userà questo account di archiviazione come account di archiviazione "primario" per le tabelle Spark e i log delle applicazioni Spark.
Selezionare la casella Assegnare a se stessi il ruolo Collaboratore ai dati dei BLOB di archiviazione nell'account Data Lake Storage Gen2.
Completamento del processo
Selezionare Rivedi e crea>Crea. L'area di lavoro sarò pronta entro pochi minuti.
Nota
Per abilitare funzionalità dell'area di lavoro da un pool SQL dedicato (in precedenza SQL Data Warehouse), vedere Come abilitare un'area di lavoro per il pool SQL dedicato (in precedenza SQL Data Warehouse).
Aprire Synapse Studio
Dopo aver creato l'area di lavoro di Azure Synapse, è possibile aprire Synapse Studio in due modi:
Aprire l'area di lavoro di Synapse nel portale di Azure e nella sezione Panoramica dell'area di lavoro di Synapse selezionare Apri nella casella Apri Synapse Studio.
Passare a
https://web.azuresynapse.nete accedere alla propria area di lavoro.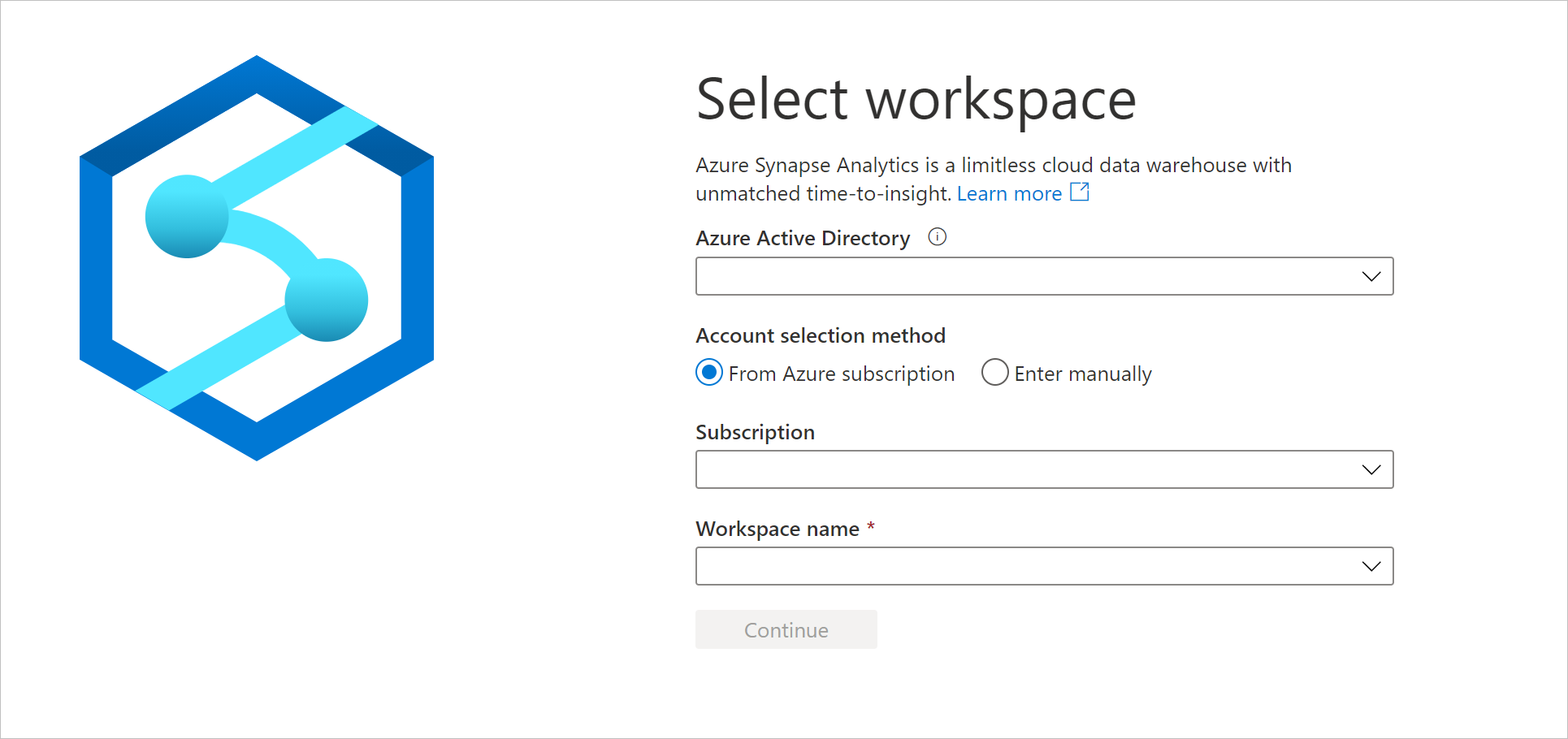
Nota
Per accedere all'area di lavoro sono disponibili due metodi di selezione account. Uno tramite la sottoscrizione di Azure, l'altro tramite Immetti manualmente. Se si ha il ruolo di Synapse Azure o ruoli di Azure di livello superiore, entrambi i metodi sono disponibili per accedere all'area di lavoro. Se non si hanno i ruoli di Azure correlati e si ha il ruolo RBAC di Synapse, il metodo Immetti manualmente è l'unico disponibile per accedere all'area di lavoro. Per altre informazioni sul controllo degli accessi in base al ruolo di Synapse, vedere Informazioni sul controllo degli accessi in base al ruolo di Synapse (RBAC).
Inserire dati di esempio nell'account di archiviazione primario
In diversi esempi contenuti in questa guida introduttiva si farà uso di un piccolo set di dati di esempio di 100.000 righe contenente informazioni sui taxi di NYC. Per iniziare, inserire il set nell'account di archiviazione primario creato per l'area di lavoro.
- Scaricare il set di dati NYC Taxi - green trip nel computer:
- Passare al percorso originale del set di dati facendo clic sul collegamento precedente, scegliere un anno specifico e scaricare i record Green taxi trip in formato Parquet.
- Rinominare il file scaricato come NYCTripSmall.parquet.
- In Synapse Studio passare all'hub Dati.
- Selezionare Collegato.
- Nella categoria Azure Data Lake Storage Gen2 verrà visualizzato un elemento con un nome simile a myworkspace ( Primary - contosolake ).
- Selezionare il contenitore denominato users (Primary).
- Selezionare Carica seguito dal file
NYCTripSmall.parquetscaricato.
Una volta caricato, il file Parquet è disponibile tramite due URI equivalenti:
https://contosolake.dfs.core.windows.net/users/NYCTripSmall.parquetabfss://users@contosolake.dfs.core.windows.net/NYCTripSmall.parquet
Suggerimento
Negli esempi che seguono in questa esercitazione assicurarsi di sostituire contosolake nell'interfaccia utente con il nome dell'account di archiviazione primario selezionato per l'area di lavoro.