Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Azure Vision nei Foundry Tools è uno strumento Microsoft Foundry che consente di elaborare immagini e restituire informazioni in base alle caratteristiche visive. Questa esercitazione descrive come usare Visione per analizzare le immagini in Azure Synapse Analytics.
Questa esercitazione illustra l'uso dell'analisi del testo con SynapseML per:
- Estrarre le funzionalità visive dal contenuto dell'immagine
- Riconoscere i caratteri dalle immagini (OCR)
- Analizzare il contenuto delle immagini e generare un'anteprima
- Rilevare e identificare contenuti specifici del dominio in un'immagine
- Generare tag correlati a un'immagine
- È possibile generare una descrizione di un'intera immagine in un linguaggio leggibile dall'utente
Analizza immagine
Estrae un set completo di funzionalità visive basate sul contenuto dell'immagine, ad esempio oggetti, visi, contenuto per adulti e descrizioni di testo generate automaticamente.
Input di esempio

# Create a dataframe with the image URLs
df = spark.createDataFrame([
("<replace with your file path>/dog.jpg", )
], ["image", ])
# Run the Vision service. Analyze Image extracts information from/about the images.
analysis = (AnalyzeImage()
.setLinkedService(ai_service_name)
.setVisualFeatures(["Categories","Color","Description","Faces","Objects","Tags"])
.setOutputCol("analysis_results")
.setImageUrlCol("image")
.setErrorCol("error"))
# Show the results of what you wanted to pull out of the images.
display(analysis.transform(df).select("image", "analysis_results.description.tags"))
Risultati previsti
["dog","outdoor","fence","wooden","small","brown","building","sitting","front","bench","standing","table","walking","board","beach","holding","bridge"]
Riconoscimento ottico dei caratteri (OCR)
Estrarre testo stampato, testo scritto a mano, cifre e simboli di valuta da immagini, ad esempio foto di segni stradali e prodotti, nonché da documenti come fatture, bollette, rapporti finanziari, articoli e altro ancora. È ottimizzato per estrarre testo da immagini complesse e documenti PDF a più pagine con lingue miste. Supporta il rilevamento di testo stampato e scritto a mano nella stessa immagine o documento.
Input di esempio

df = spark.createDataFrame([
("<replace with your file path>/ocr.jpg", )
], ["url", ])
ri = (ReadImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("ocr"))
display(ri.transform(df))
Risultati previsti
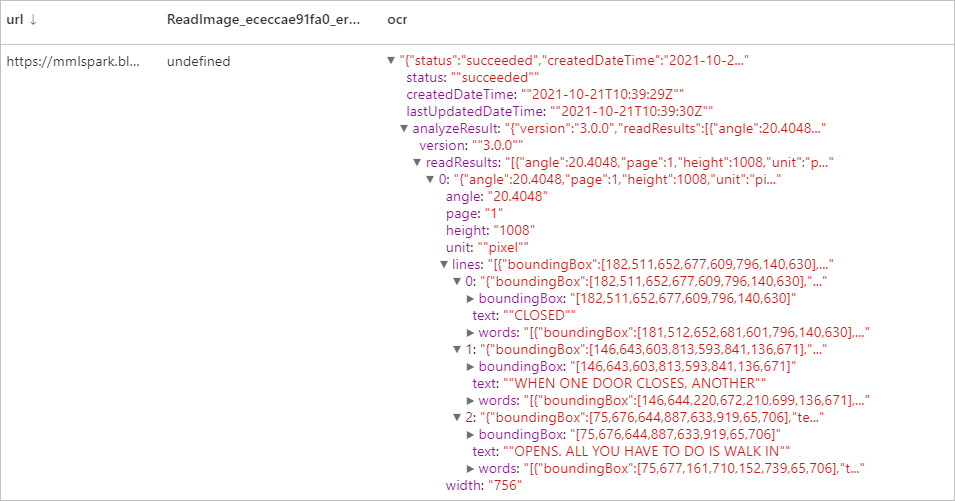
Generare anteprime
È possibile analizzare i contenuti di un'immagine per generare un'anteprima appropriata per tale immagine. Il servizio Visione genera prima di tutto un'anteprima di qualità elevata e quindi analizza gli oggetti inclusi nell'immagine per determinare l'area di interesse. Visione ritaglia l’immagine per soddisfare i requisiti dell'area di interesse. L'anteprima generata può essere visualizzata con proporzioni diverse da quelle dell'immagine originale, in base alle esigenze specifiche.
Input di esempio

df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
gt = (GenerateThumbnails()
.setLinkedService(ai_service_name)
.setHeight(50)
.setWidth(50)
.setSmartCropping(True)
.setImageUrlCol("url")
.setOutputCol("thumbnails"))
thumbnails = gt.transform(df).select("thumbnails").toJSON().first()
import json
img = json.loads(thumbnails)["thumbnails"]
displayHTML("<img src='data:image/jpeg;base64," + img + "'>")
Risultati previsti

Aggiungi tag a immagine
Genera un elenco di parole o tag rilevanti per il contenuto dell'immagine fornita. I tag vengono restituiti in base a migliaia di oggetti riconoscibili, esseri viventi, paesaggi o azioni presenti nelle immagini. I tag possono contenere hint per evitare ambiguità o fornire contesto, ad esempio il tag "ascomycete" può essere accompagnato dall'hint "fungo".
Continuare a usare l'immagine di Satya come esempio.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
ti = (TagImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("tags"))
display(ti.transform(df))
Risultato previsto
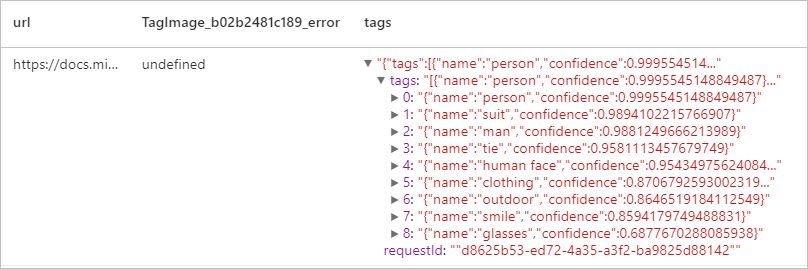
Descrivi immagine
È possibile generare una descrizione di un'intera immagine in un linguaggio leggibile dall'utente, con frasi complete. Gli algoritmi del servizio di Visione generano descrizioni diverse in base agli oggetti identificati nell'immagine. Tutte le descrizioni vengono valutate e per ognuna viene generato un punteggio di attendibilità. Viene quindi restituito un elenco dei punteggi di attendibilità in ordine decrescente.
Continuare a usare l'immagine di Satya come esempio.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
di = (DescribeImage()
.setLinkedService(ai_service_name)
.setMaxCandidates(3)
.setImageUrlCol("url")
.setOutputCol("descriptions"))
display(di.transform(df))
Risultato previsto
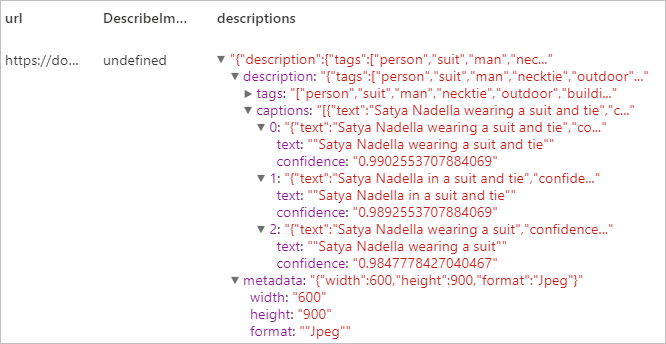
Riconoscere contenuto specifico di dominio
È possibile usare modelli di dominio per rilevare e identificare contenuti specifici del dominio in un'immagine, ad esempio celebrità e luoghi di interesse. Se ad esempio un'immagine contiene persone, Visione può usare un modello di dominio per le celebrità per determinare se le persone rilevate nell'immagine corrispondono a celebrità note.
Continuare a usare l'immagine di Satya come esempio.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
celeb = (RecognizeDomainSpecificContent()
.setLinkedService(ai_service_name)
.setModel("celebrities")
.setImageUrlCol("url")
.setOutputCol("celebs"))
display(celeb.transform(df))
Risultato previsto
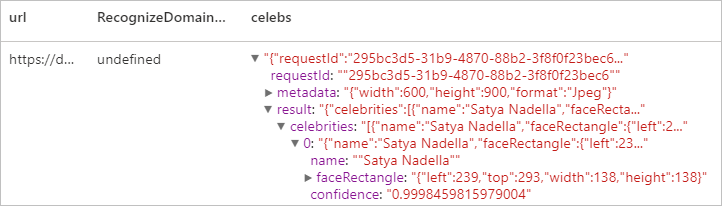
Pulire le risorse
Per assicurarsi che l'istanza di Spark venga arrestata, terminare tutte le sessioni connesse (notebook). Il pool si arresta quando viene raggiunto il tempo di inattività specificato nel pool di Apache Spark. Si può anche selezionare Termina sessione sulla barra di stato nella parte destra superiore del notebook.
