Esercitazione: creare una definizione di processo Apache Spark in Synapse Studio
Questa esercitazione illustra come usare Synapse Studio per creare definizioni di processi Apache Spark e quindi inviarle a un pool di Apache Spark serverless.
Questa esercitazione illustra le attività seguenti:
- Creare una definizione di processo Apache Spark per PySpark (Python)
- Creare una definizione di processo Apache Spark per Spark (Scala)
- Creare una definizione di processo Apache Spark per .NET Spark(C#/F#)
- Creare una definizione di processo importando un file JSON
- Esportare un file di definizione di processo Apache Spark a un percorso locale
- Inviare una definizione di processo Apache Spark come processo batch
- Aggiungere una definizione di processo Apache Spark a una pipeline
Prerequisiti
Prima di iniziare l'esercitazione, verificare che siano soddisfatti i requisiti seguenti:
- Un'area di lavoro di Azure Synapse Analytics. Per le istruzioni, vedere Creare un'area di lavoro di Azure Synapse Analytics.
- Un pool di Apache Spark serverless.
- Account di archiviazione Azure Data Lake Storage Gen2. È necessario essere il Collaboratore dei dati del BLOB di archiviazione del file system di ADLS Gen2 che si desidera usare. Se non lo si è, è necessario aggiungere l'autorizzazione manualmente.
- Se non si vuole usare l'account di archiviazione predefinito dell'area di lavoro, collegare l'account di archiviazione di ADLS Gen2 richiesto in Synapse Studio.
Creare una definizione di processo Apache Spark per PySpark (Python)
In questa sezione viene creata una definizione di processo Apache Spark per PySpark (Python).
Aprire Synapse Studio.
È possibile passare ai file di esempio per la creazione di definizioni di processo Apache Spark per scaricare i file di esempio per python.zip, quindi decomprimere il pacchetto compresso ed estrarre i file wordcount.py e shakespeare.txt.
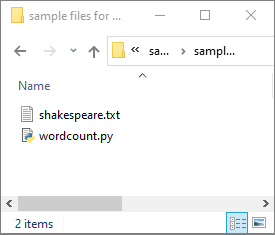
Selezionare Dati ->Collegati ->Azure Data Lake Storage Gen2, quindi caricare wordcount.py e shakespeare.txt nel file system di ADLS Gen2.
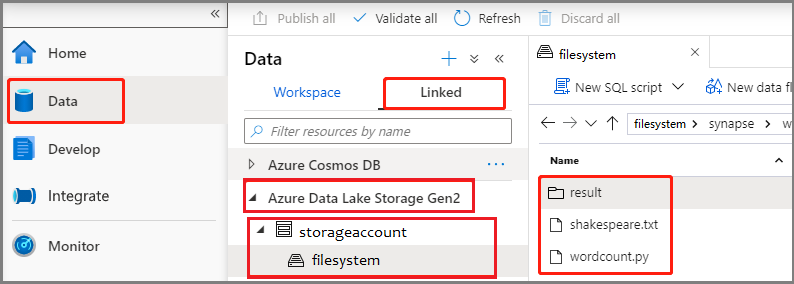
Selezionare l'hub Sviluppo, fare clic sull'icona '+' e selezionare Definizione di processo Spark per creare una nuova definizione di processo Spark.
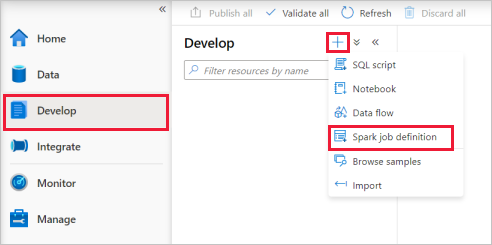
Selezionare PySpark (Python) nell'elenco a discesa del linguaggio nella finestra principale della definizione di processo Apache Spark.
Immettere le informazioni per la definizione di processo Apache Spark.
Proprietà Descrizione Nome definizione processo Specificare un nome per la definizione di processo Apache Spark. Questo nome può essere aggiornato in qualsiasi momento fino a quando non viene pubblicato.
Esempio:job definition sampleFile di definizione principale File principale usato per il processo. Selezionare un file PY dalla risorsa di archiviazione. È possibile selezionare Carica file per caricare il file in un account di archiviazione.
Esempio:abfss://…/path/to/wordcount.pyArgomenti della riga di comando Argomenti facoltativi per il processo.
Campione:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Nota: due argomenti per la stessa definizione di processo di esempio sono separati da uno spazio.File di riferimento File aggiuntivi usati come riferimento nel file di definizione principale. È possibile selezionare Carica file per caricare il file in un account di archiviazione. Pool Spark Il processo verrà inviato al pool di Apache Spark selezionato. Versione di Spark Versione di Apache Spark in esecuzione nel pool di Apache Spark. Executors Numero di executor da assegnare al pool di Apache Spark specificato per il processo. Dimensioni executor Numero di core e memoria da usare per gli executor indicati nel pool di Apache Spark specificato per il processo. Dimensioni driver Numero di core e memoria da usare per il driver indicato nel pool di Apache Spark specificato per il processo. Configurazione di Apache Spark Personalizzare le configurazioni aggiungendo le proprietà seguenti. Se non si aggiunge una proprietà, Azure Synapse userà il valore predefinito, se applicabile. 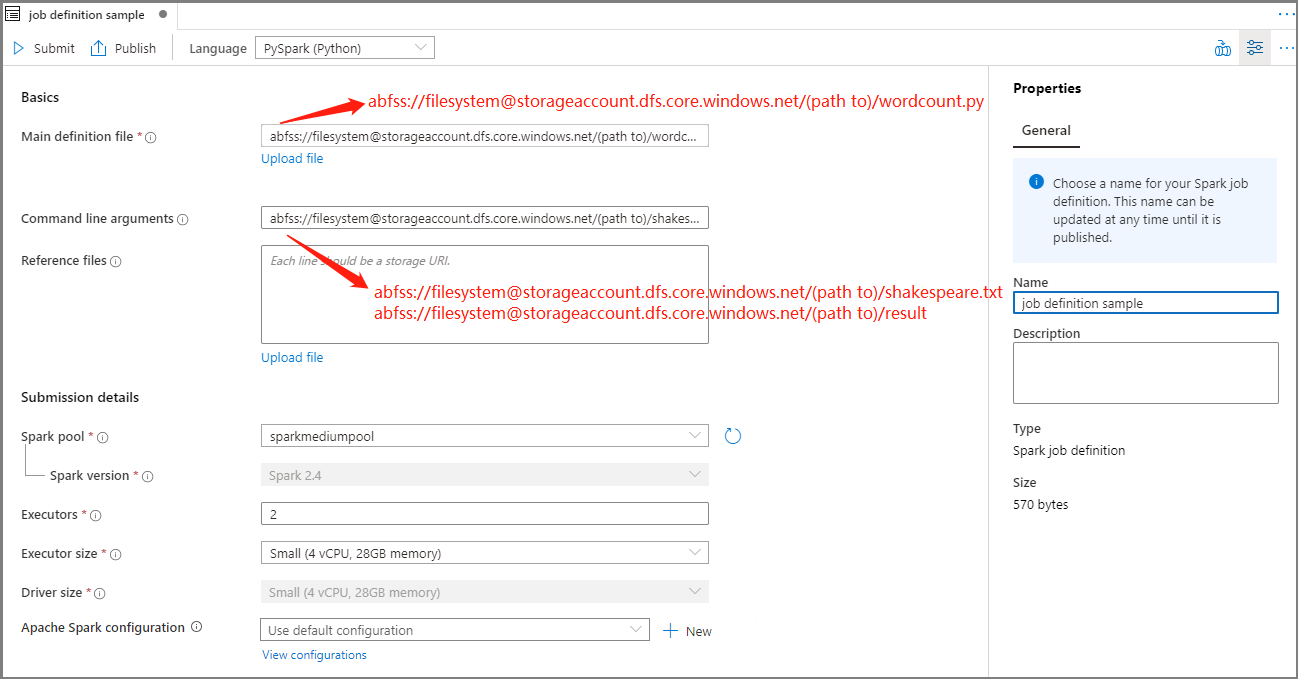
Selezionare Pubblica per salvare la definizione di processo Apache Spark.

Creare una definizione di processo Apache Spark per Apache Spark (Scala)
In questa sezione viene creata una definizione di processo Apache Spark per Apache Spark (Scala).
Aprire Azure Synapse Studio.
È possibile passare ai file di esempio per la creazione di definizioni di processo Apache Spark per scaricare i file di esempio per scala.zip, quindi decomprimere il pacchetto compresso ed estrarre i file wordcount.jar e shakespeare.txt.
Selezionare Dati ->Collegati ->Azure Data Lake Storage Gen2, quindi caricare wordcount.jar e shakespeare.txt nel file system di ADLS Gen2.
Selezionare l'hub Sviluppo, fare clic sull'icona '+' e selezionare Definizione di processo Spark per creare una nuova definizione di processo Spark. L'immagine di esempio è identica a quella del passaggio 4 di Creare una definizione di processo Apache Spark (Python) per PySpark.
Selezionare Spark (Scala) nell'elenco a discesa del linguaggio nella finestra principale della definizione di processo Apache Spark.
Immettere le informazioni per la definizione di processo Apache Spark. È possibile copiare le informazioni di esempio.
Proprietà Descrizione Nome definizione processo Specificare un nome per la definizione di processo Apache Spark. Questo nome può essere aggiornato in qualsiasi momento fino a quando non viene pubblicato.
Esempio:scalaFile di definizione principale File principale usato per il processo. Selezionare un file JAR dalla risorsa di archiviazione. È possibile selezionare Carica file per caricare il file in un account di archiviazione.
Esempio:abfss://…/path/to/wordcount.jarNome della classe principale Identificatore completo o classe principale inclusa nel file di definizione principale.
Esempio:WordCountArgomenti della riga di comando Argomenti facoltativi per il processo.
Campione:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Nota: due argomenti per la stessa definizione di processo di esempio sono separati da uno spazio.File di riferimento File aggiuntivi usati come riferimento nel file di definizione principale. È possibile selezionare Carica file per caricare il file in un account di archiviazione. Pool Spark Il processo verrà inviato al pool di Apache Spark selezionato. Versione di Spark Versione di Apache Spark in esecuzione nel pool di Apache Spark. Executors Numero di executor da assegnare al pool di Apache Spark specificato per il processo. Dimensioni executor Numero di core e memoria da usare per gli executor indicati nel pool di Apache Spark specificato per il processo. Dimensioni driver Numero di core e memoria da usare per il driver indicato nel pool di Apache Spark specificato per il processo. Configurazione di Apache Spark Personalizzare le configurazioni aggiungendo le proprietà seguenti. Se non si aggiunge una proprietà, Azure Synapse userà il valore predefinito, se applicabile. 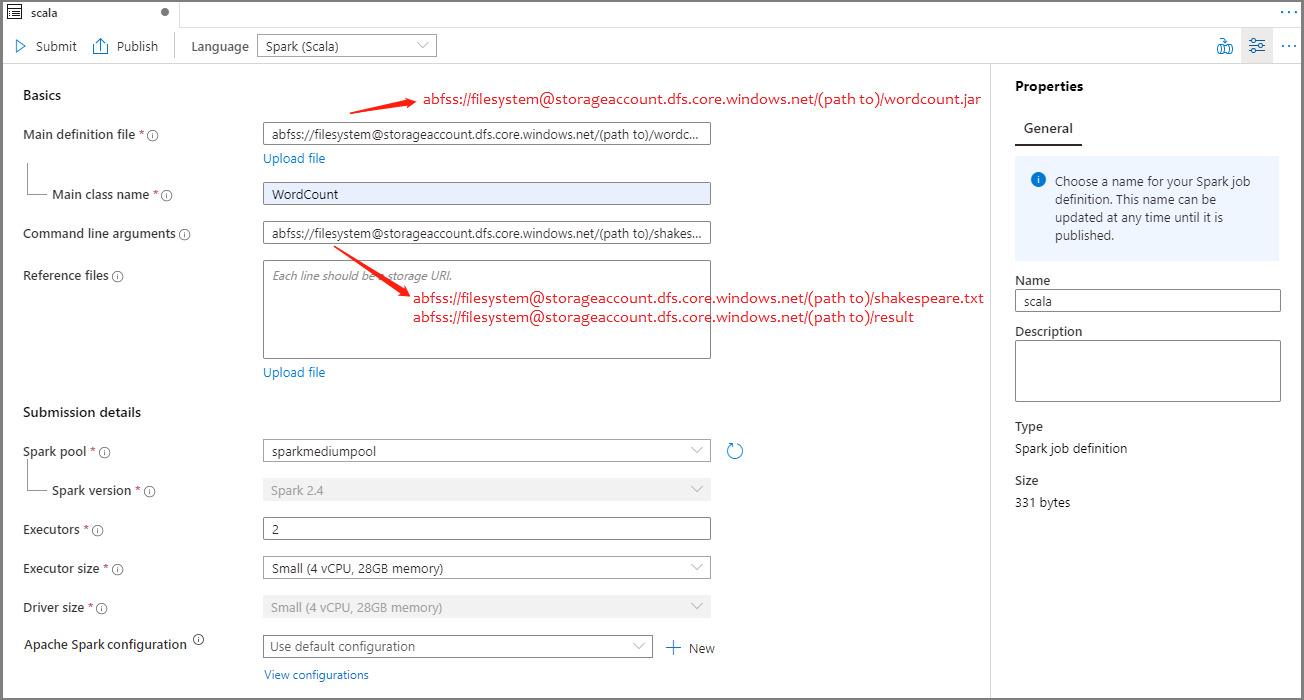
Selezionare Pubblica per salvare la definizione di processo Apache Spark.

Creare una definizione di processo Apache Spark per .NET Spark(C#/F#)
In questa sezione viene creata una definizione di processo Apache Spark per .NET Spark(C#/F#).
Aprire Azure Synapse Studio.
È possibile passare ai file di esempio per la creazione di definizioni di processo Apache Spark per scaricare i file di esempio per dotnet.zip, quindi decomprimere il pacchetto compresso ed estrarre i file wordcount.zip e shakespeare.txt.
Selezionare Dati ->Collegati ->Azure Data Lake Storage Gen2, quindi caricare wordcount.zip e shakespeare.txt nel file system di ADLS Gen2.
Selezionare l'hub Sviluppo, fare clic sull'icona '+' e selezionare Definizione di processo Spark per creare una nuova definizione di processo Spark. L'immagine di esempio è identica a quella del passaggio 4 di Creare una definizione di processo Apache Spark (Python) per PySpark.
Selezionare .NET Spark (C#/F#) nell'elenco a discesa del linguaggio nella finestra principale della definizione di processo Apache Spark.
Immettere le informazioni per la definizione di processo Apache Spark. È possibile copiare le informazioni di esempio.
Proprietà Descrizione Nome definizione processo Specificare un nome per la definizione di processo Apache Spark. Questo nome può essere aggiornato in qualsiasi momento fino a quando non viene pubblicato.
Esempio:dotnetFile di definizione principale File principale usato per il processo. Selezionare un file con estensione zip contenente l'applicazione .NET per Apache Spark (ovvero il file eseguibile principale, le DLL che includono le funzioni definite dall'utente e altri file necessari) dall'archivio. È possibile selezionare Carica file per caricare il file in un account di archiviazione.
Esempio:abfss://…/path/to/wordcount.zipFile eseguibile principale File eseguibile principale nel file ZIP della definizione principale.
Esempio:WordCountArgomenti della riga di comando Argomenti facoltativi per il processo.
Campione:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Nota: due argomenti per la stessa definizione di processo di esempio sono separati da uno spazio.File di riferimento Altri file necessari ai nodi di lavoro per l'esecuzione dell'applicazione .NET per Apache Spark non inclusi nel file con estensione zip della definizione principale (ovvero file con estensione jar dipendenti, DLL di funzioni definite dall'utente aggiuntive e altri file di configurazione). È possibile selezionare Carica file per caricare il file in un account di archiviazione. Pool Spark Il processo verrà inviato al pool di Apache Spark selezionato. Versione di Spark Versione di Apache Spark in esecuzione nel pool di Apache Spark. Executors Numero di executor da assegnare al pool di Apache Spark specificato per il processo. Dimensioni executor Numero di core e memoria da usare per gli executor indicati nel pool di Apache Spark specificato per il processo. Dimensioni driver Numero di core e memoria da usare per il driver indicato nel pool di Apache Spark specificato per il processo. Configurazione di Apache Spark Personalizzare le configurazioni aggiungendo le proprietà seguenti. Se non si aggiunge una proprietà, Azure Synapse userà il valore predefinito, se applicabile. 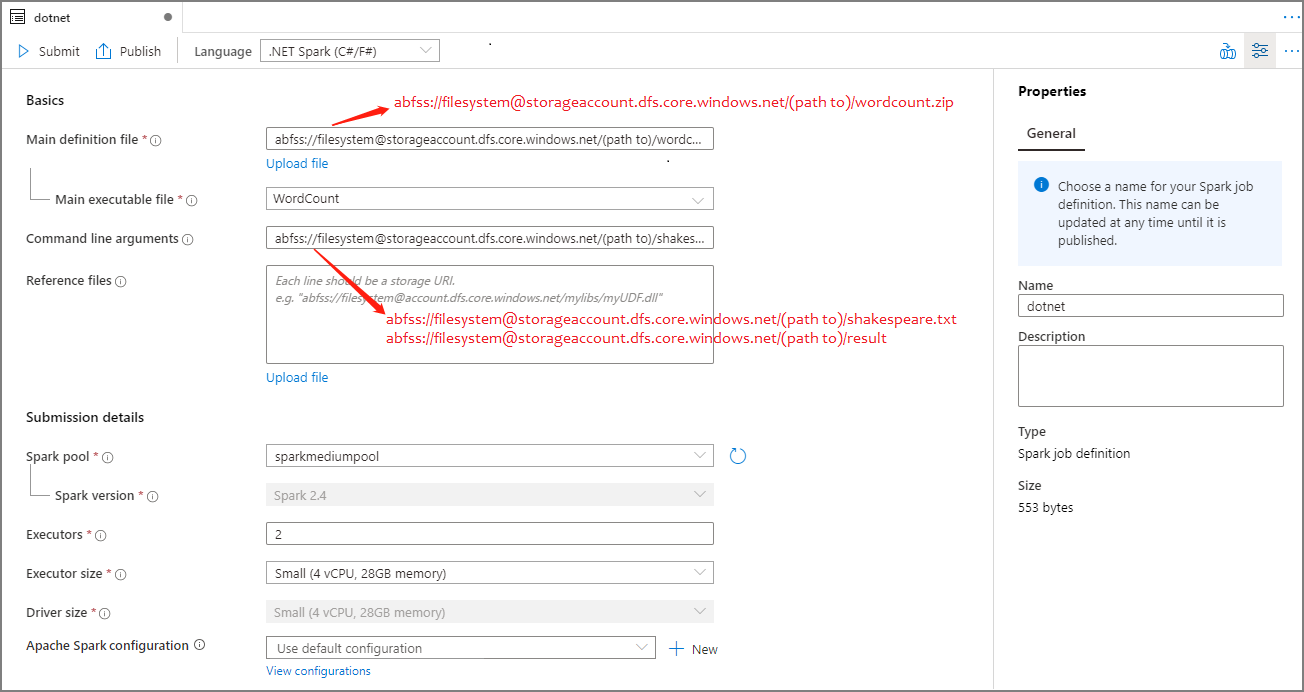
Selezionare Pubblica per salvare la definizione di processo Apache Spark.

Nota
Per la configurazione di Apache Spark, se la definizione del processo Apache Spark di configurazione Apache Spark non esegue operazioni speciali, durante l'esecuzione del processo verrà usata la configurazione predefinita.
Creare una definizione di processo Apache Spark importando un file JSON
È possibile importare un file JSON locale esistente nell'area di lavoro di Azure Synapse dal menu Azioni (...) di Esplora definizione di processo Apache Spark per creare una nuova definizione di processo Apache Spark.
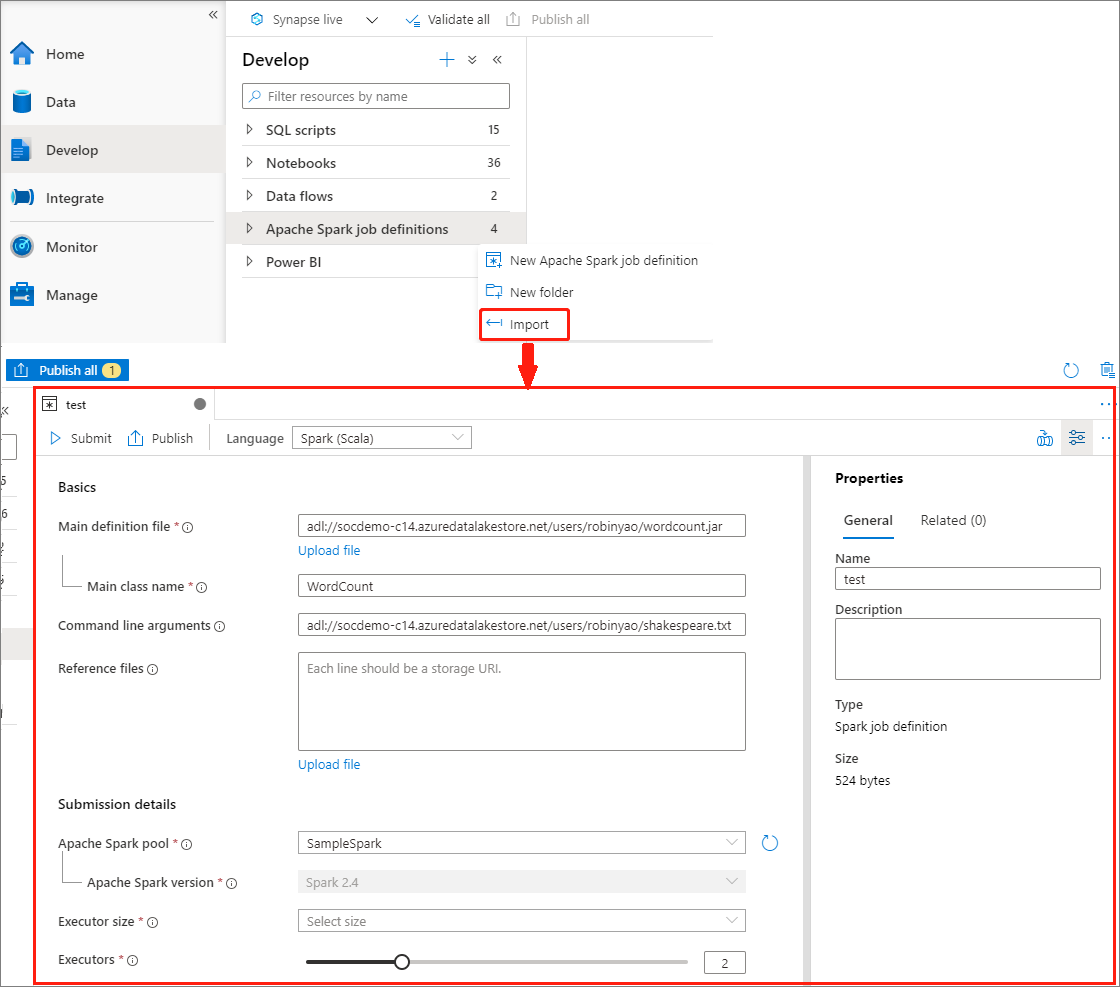
La definizione del processo Spark è pienamente compatibile con l'API Livy. È possibile aggiungere altri parametri per altre proprietà Livy (Livy Docs - API REST (apache.org) nel file JSON locale. È anche possibile specificare i parametri correlati alla configurazione di Spark nella proprietà config, come illustrato di seguito. È quindi possibile importare di nuovo il file JSON per creare una nuova definizione di processo Apache Spark per il processo batch. Esempio JSON per l'importazione della definizione Spark:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
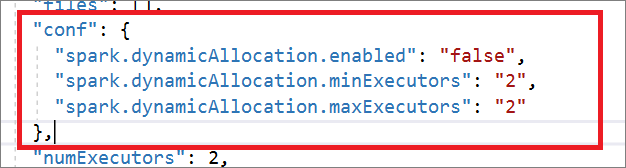
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
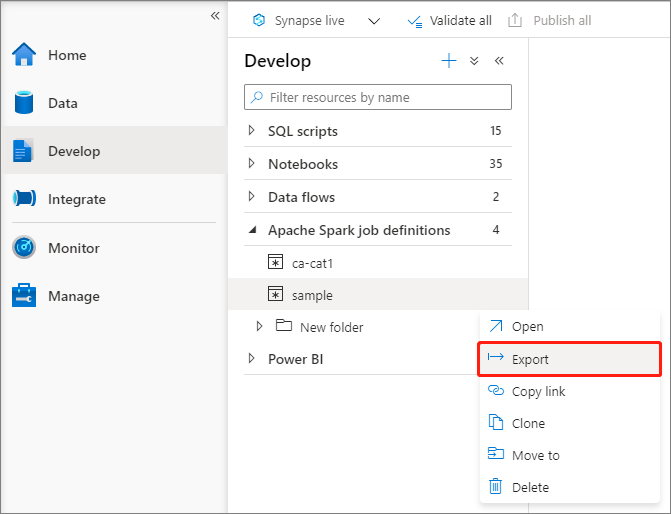
Esportare un file di definizione di processo Apache Spark esistente
È possibile esportare i file di definizione del processo Apache Spark esistenti in locale dal menu Azioni (...) di Esplora file. È possibile aggiornare ulteriormente il file JSON per altre proprietà Livy e importarlo nuovamente per creare una nuova definizione del processo, se necessario.
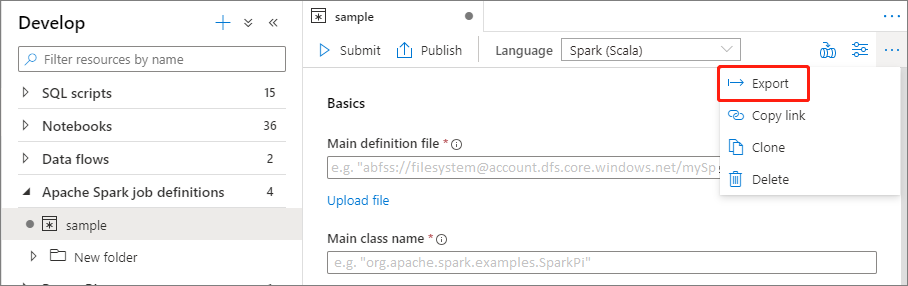
Inviare una definizione di processo Apache Spark come processo batch
Dopo aver creato una definizione di processo Apache Spark, è possibile inviarla a un pool di Apache Spark. Assicurarsi di essere il Collaboratore dei dati del BLOB di archiviazione del file system di ADLS Gen2 che si desidera usare. Se non lo si è, è necessario aggiungere l'autorizzazione manualmente.
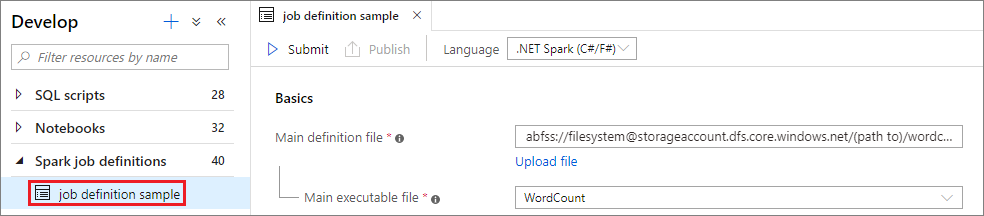
Scenario 1: inviare la definizione di processo Apache Spark
Aprire una finestra di definizione di processo Apache Spark selezionandola.
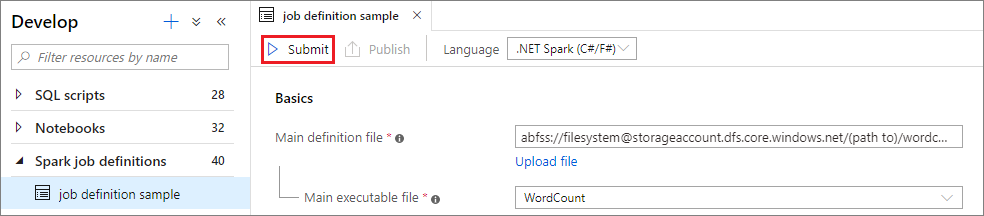
Selezionare il pulsante Invia per inviare il progetto al pool di Apache Spark. È possibile selezionare la scheda Spark monitoring URL (URL di monitoraggio Spark) per visualizzare la query su log dell'applicazione Apache Spark.
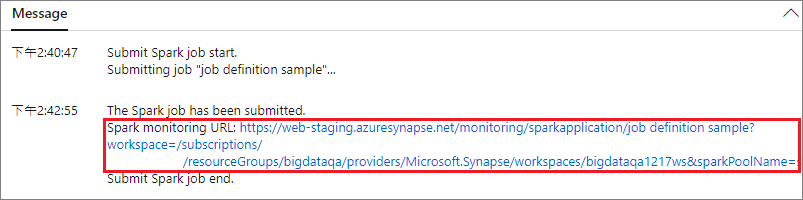
Scenario 2: visualizzare lo stato di esecuzione del processo Apache Spark
Selezionare Monitoraggio e quindi l'opzione relativa alle applicazioni Apache Spark. Verrà visualizzata l'applicazione Apache Spark inviata.
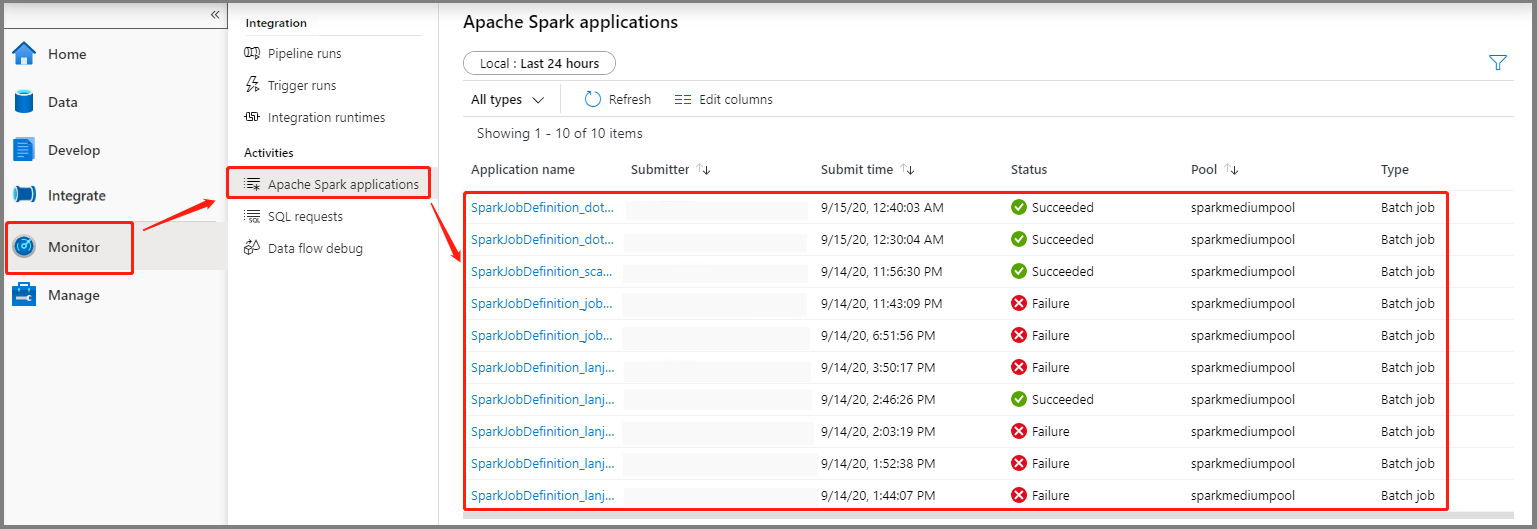
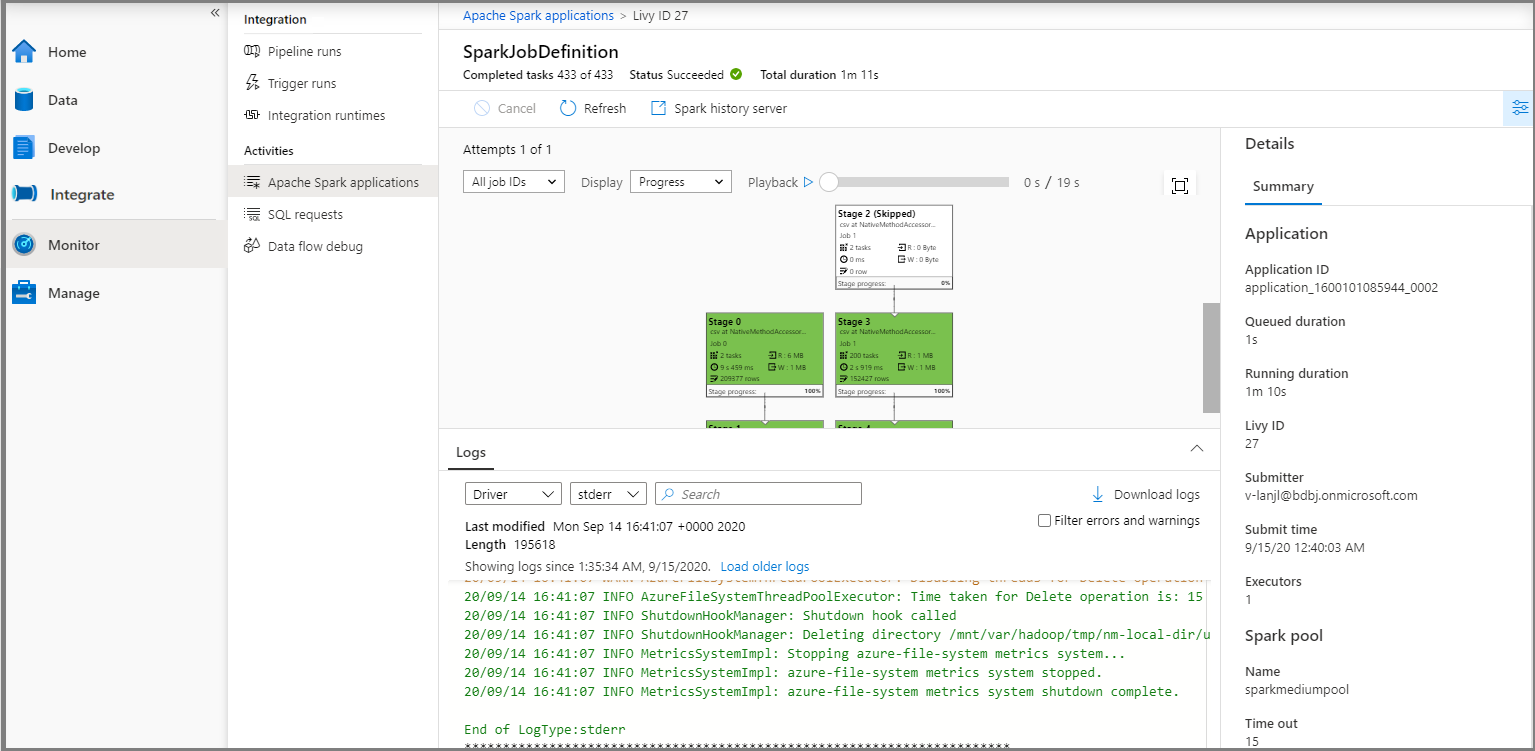
Selezionare quindi un'applicazione Apache Spark. Viene visualizzata la finestra del processo SparkJobDefinition. Qui è possibile visualizzare lo stato di esecuzione del processo.
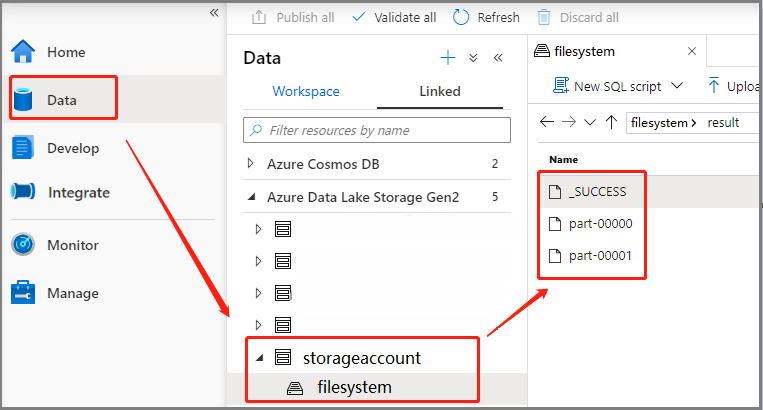
Scenario 3: verificare il file di output
Selezionare Dati ->Collegati ->Azure Data Lake Storage Gen2 (hozhaobdbj), aprire la cartella result creata in precedenza e verificare se l'output è stato generato.
Aggiungere una definizione di processo Apache Spark a una pipeline
In questa sezione viene aggiunta una definizione di processo Apache Spark a una pipeline.
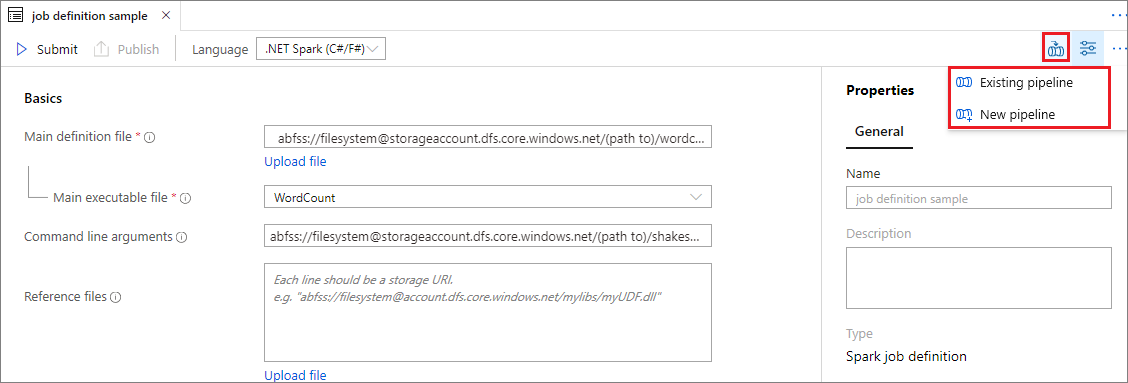
Aprire una definizione di processo Apache Spark esistente.
Selezionare l'icona nell'angolo in alto a destra della finestra della definizione di processo Apache Spark e selezionare Existing Pipeline (Pipeline esistente) o New pipeline (Nuova pipeline). Per altre informazioni, fare riferimento alla pagina Pipeline.
Passaggi successivi
Successivamente sarà possibile usare Azure Synapse Studio per creare set di dati di Power BI e gestire i dati di Power BI. Per altre informazioni, vedere l'articolo Collegamento di un'area di lavoro Power BI a un'area di lavoro di Synapse.