Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Dopo aver identificato i pacchetti Scala, Java, R (anteprima) o Python da usare o aggiornare per l'applicazione Spark, è possibile installarli o rimuoverli da un pool di Spark. Le librerie a livello di pool sono disponibili per tutti i notebook e i processi in esecuzione nel pool.
Esistono due modi principali per installare una libreria in un pool di Spark:
- Installare una libreria dell'area di lavoro caricata come pacchetto dell'area di lavoro.
- Per aggiornare le librerie Python, fornire un file di specifica dell'ambiente requirements.txt o Conda environment.yml per installare pacchetti da repository come PyPI o Conda-Forge. Per altre informazioni, vedere la sezione Formati delle specifiche dell'ambiente.
Dopo aver salvato le modifiche, un processo Spark esegue l'installazione e memorizza nella cache l'ambiente risultante per un riutilizzo successivo. Al termine del processo, i nuovi processi Spark o le sessioni di notebook usano le librerie del pool aggiornate.
Importante
- Se il pacchetto che si installa è di grandi dimensioni o richiede molto tempo per l'installazione, il tempo di avvio dell'istanza di Spark è interessato.
- La modifica della versione di PySpark, Python, Scala/Java, .NET, R o Spark non è supportata.
- L'installazione di pacchetti da repository esterni come PyPI, Conda-Forge o i canali Conda predefiniti non sono supportati nelle aree di lavoro abilitate per l'esfiltrazione dei dati.
Gestire i pacchetti da Synapse Studio o dal portale di Azure
Le librerie del pool di Spark possono essere gestite da Synapse Studio o dal portale di Azure.
Nella portale di Azure passare all'area di lavoro di Azure Synapse Analytics.
Nella sezione Pool di analisi selezionare la scheda Pool di Apache Spark e selezionare un pool di Spark dall'elenco.
Selezionare i pacchetti nella sezione Impostazioni del pool di Spark.
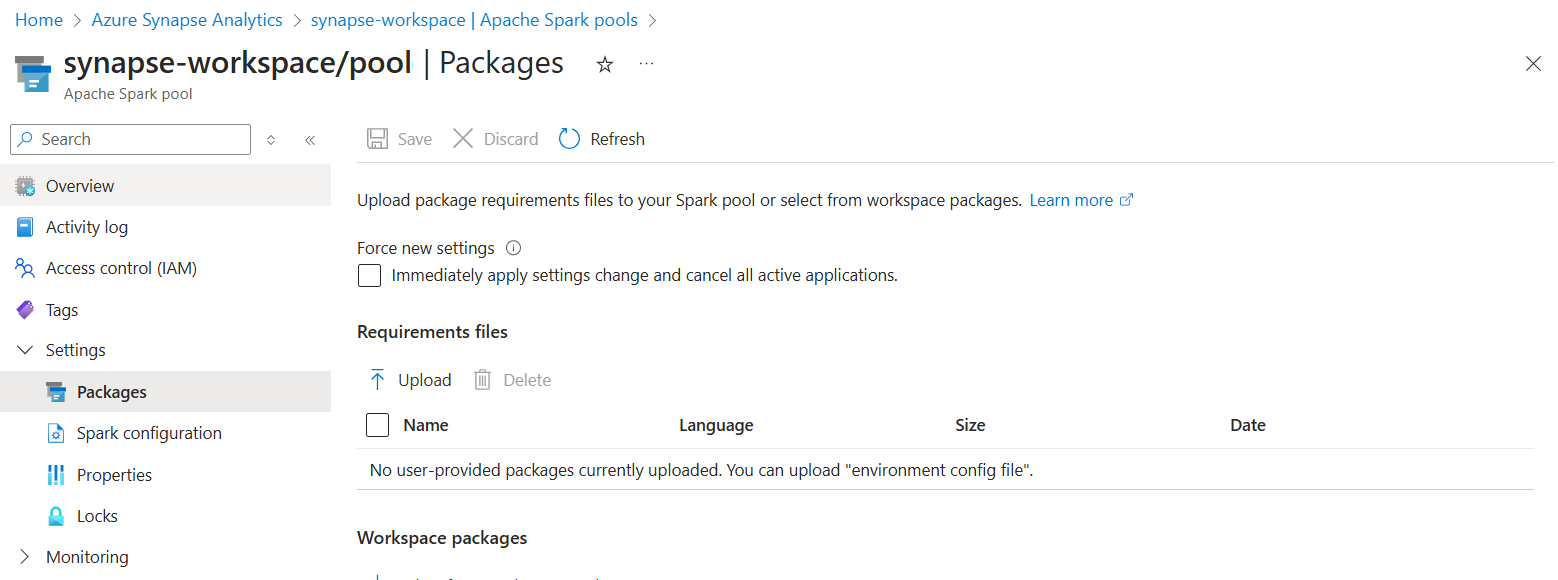
Per le librerie di feed Python, caricare il file di configurazione dell'ambiente usando il selettore di file nella sezione Pacchetti della pagina.
È anche possibile selezionare altri pacchetti dell'area di lavoro per aggiungere file Jar, Wheel o Tar.gz al pool.
È anche possibile rimuovere pacchetti deprecati dalla sezione Pacchetti dell'area di lavoro, quindi il pool non collega più questi pacchetti.
Dopo aver salvato le modifiche, viene attivato un processo di sistema per installare e memorizzare nella cache le librerie specificate. Questo processo consente di ridurre il tempo di avvio complessivo della sessione.
Al termine del processo, tutte le nuove sessioni recuperano le librerie del pool aggiornate.


Importante
Selezionando l'opzione Forza nuove impostazioni, si stanno terminando tutte le sessioni correnti per il pool di Spark selezionato. Al termine delle sessioni, è necessario attendere il riavvio del pool.
Se questa impostazione è deselezionata, è necessario attendere che la sessione Spark corrente venga terminata o arrestata manualmente. Al termine della sessione, è necessario consentire il riavvio del pool.
Tenere traccia dello stato dell'installazione
Viene avviato un processo Spark riservato per il sistema ogni volta che un pool viene aggiornato con un nuovo set di librerie. Questo processo Spark consente di monitorare lo stato dell'installazione della libreria. Se l'installazione non riesce a causa di conflitti di libreria o altri problemi, il pool di Spark ripristina lo stato precedente o predefinito.
Inoltre, gli utenti possono esaminare i log di installazione per identificare i conflitti di dipendenza o vedere quali librerie sono state installate durante l'aggiornamento del pool.
Per visualizzare questi log:
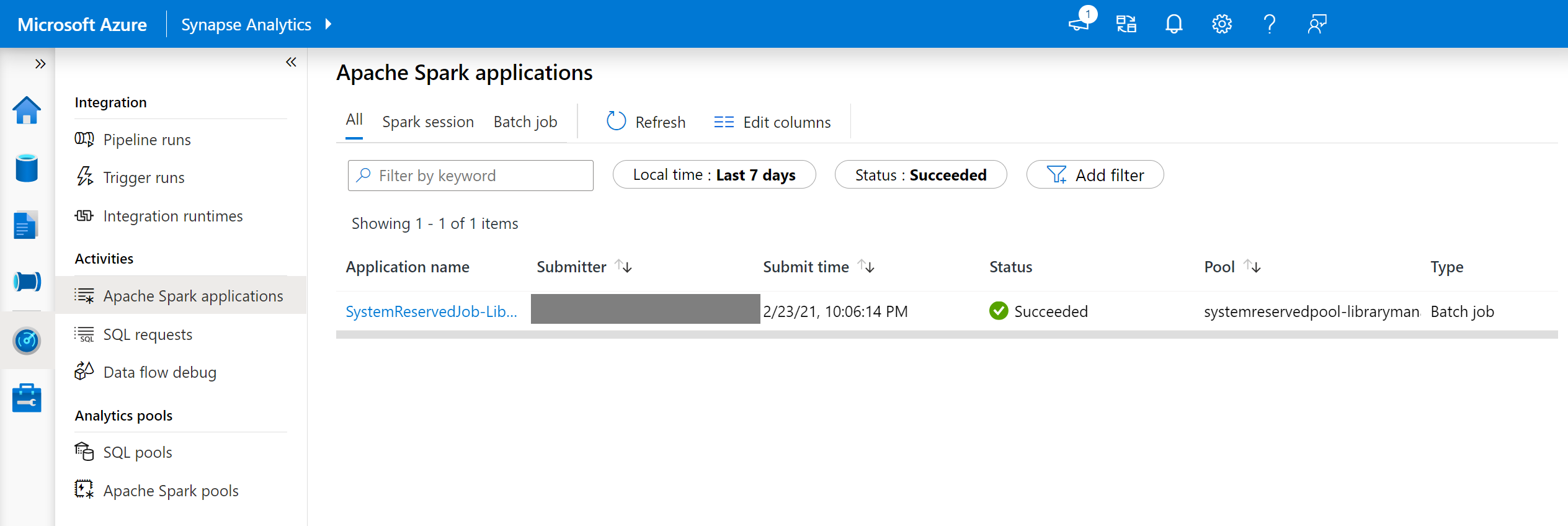
In Synapse Studio passare all'elenco delle applicazioni Spark nella scheda Monitoraggio .
Selezionare il processo dell'applicazione Spark di sistema corrispondente all'aggiornamento del pool. Questi processi di sistema vengono eseguiti con il titolo SystemReservedJob-LibraryManagement.
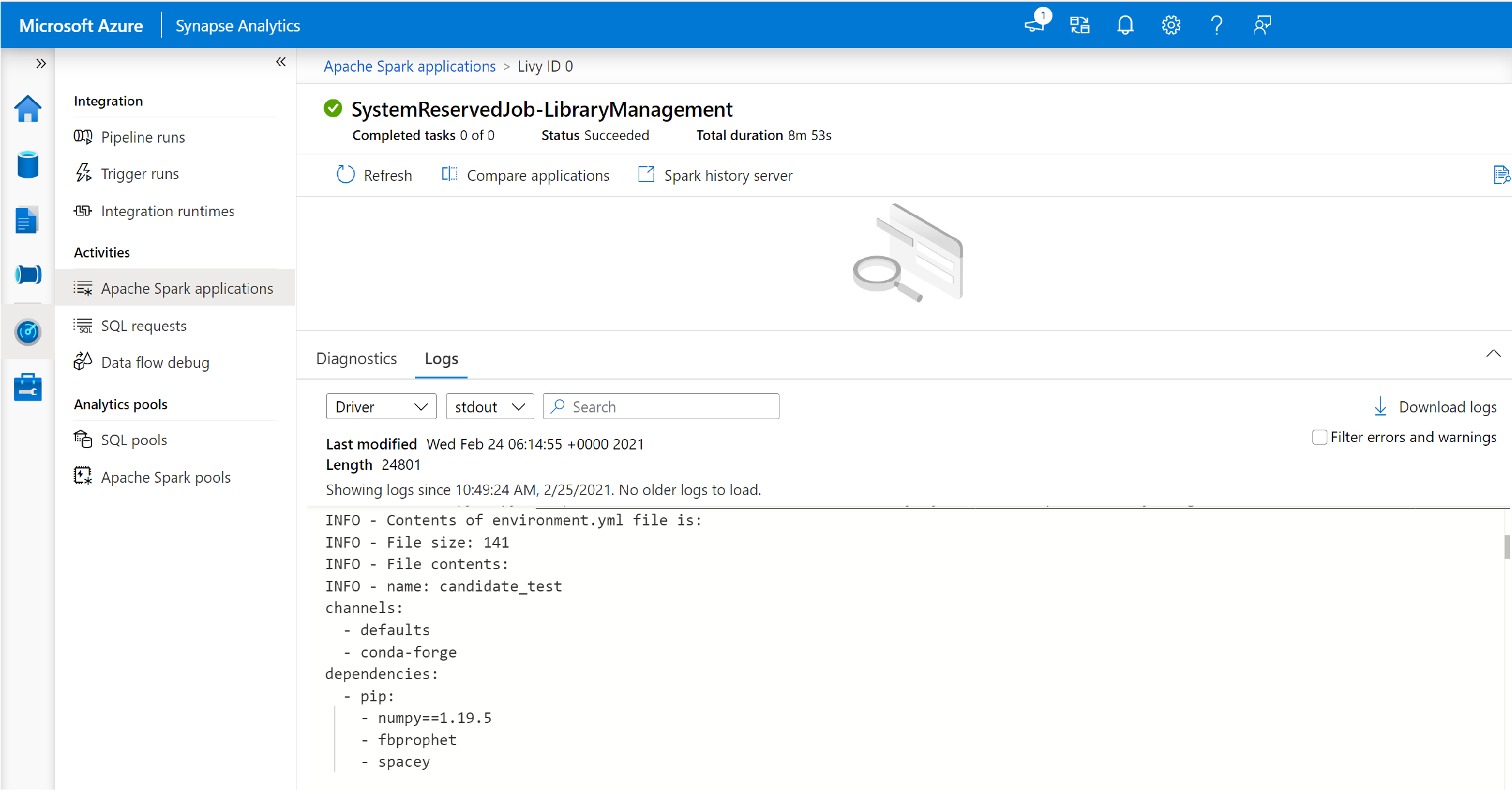
Passare alla vista dei log driver e stdout.
I risultati contengono i log correlati all'installazione delle dipendenze.


Formati di specifica dell'ambiente
PIP requirements.txt
È possibile usare un file requirements.txt (output del comando pip freeze) per aggiornare l'ambiente. Quando un pool viene aggiornato, i pacchetti elencati in questo file vengono scaricati da PyPI. Le dipendenze complete vengono quindi memorizzate nella cache e salvate per il riutilizzo successivo del pool.
Il frammento di codice seguente mostra il formato per il file dei requisiti. Il nome del pacchetto PyPI è elencato insieme a una versione esatta. Questo file segue il formato descritto nella documentazione di riferimento di blocco pip.
In questo esempio viene aggiunta una versione specifica.
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
Formato YML
Inoltre, è possibile fornire un file environment.yml per aggiornare l'ambiente del pool. I pacchetti elencati in questo file vengono scaricati dai canali Conda, Conda-Forge e PyPI predefiniti. È possibile specificare altri canali o rimuovere i canali predefiniti usando le opzioni di configurazione.
Questo esempio specifica i canali e le dipendenze Conda/PyPI.
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
Per informazioni dettagliate sulla creazione di un ambiente da questo file di environment.yml , vedere Attivazione di un ambiente.