Gestire i pacchetti con ambito sessione
Oltre ai pacchetti a livello di pool, è anche possibile specificare librerie con ambito sessione all'inizio di una sessione del notebook. Le librerie con ambito sessione consentono di specificare e usare pacchetti Python, jar e R all'interno di una sessione del notebook.
Quando si usano librerie con ambito sessione, è importante tenere presenti i seguenti punti:
- Quando si installano librerie con ambito sessione, solo il notebook corrente ha accesso alle librerie specificate.
- Queste librerie non hanno alcun impatto su altre sessioni o processi che usano lo stesso pool di Spark.
- Queste librerie vengono installate sopra il runtime di base e le librerie a livello di pool e hanno la precedenza più alta.
- Le librerie con ambito sessione non vengono mantenute tra le sessioni.
Pacchetti Python con ambito sessione
Gestire i pacchetti Python con ambito sessione tramite il file environment.yml
Per specificare pacchetti Python con ambito sessione:
- Andare al pool di Spark selezionato e assicurarsi di avere abilitato le librerie a livello di sessione. È possibile abilitare questa impostazione passando alla scheda Gestisci>Pool di Apache Spark>Pacchetti.
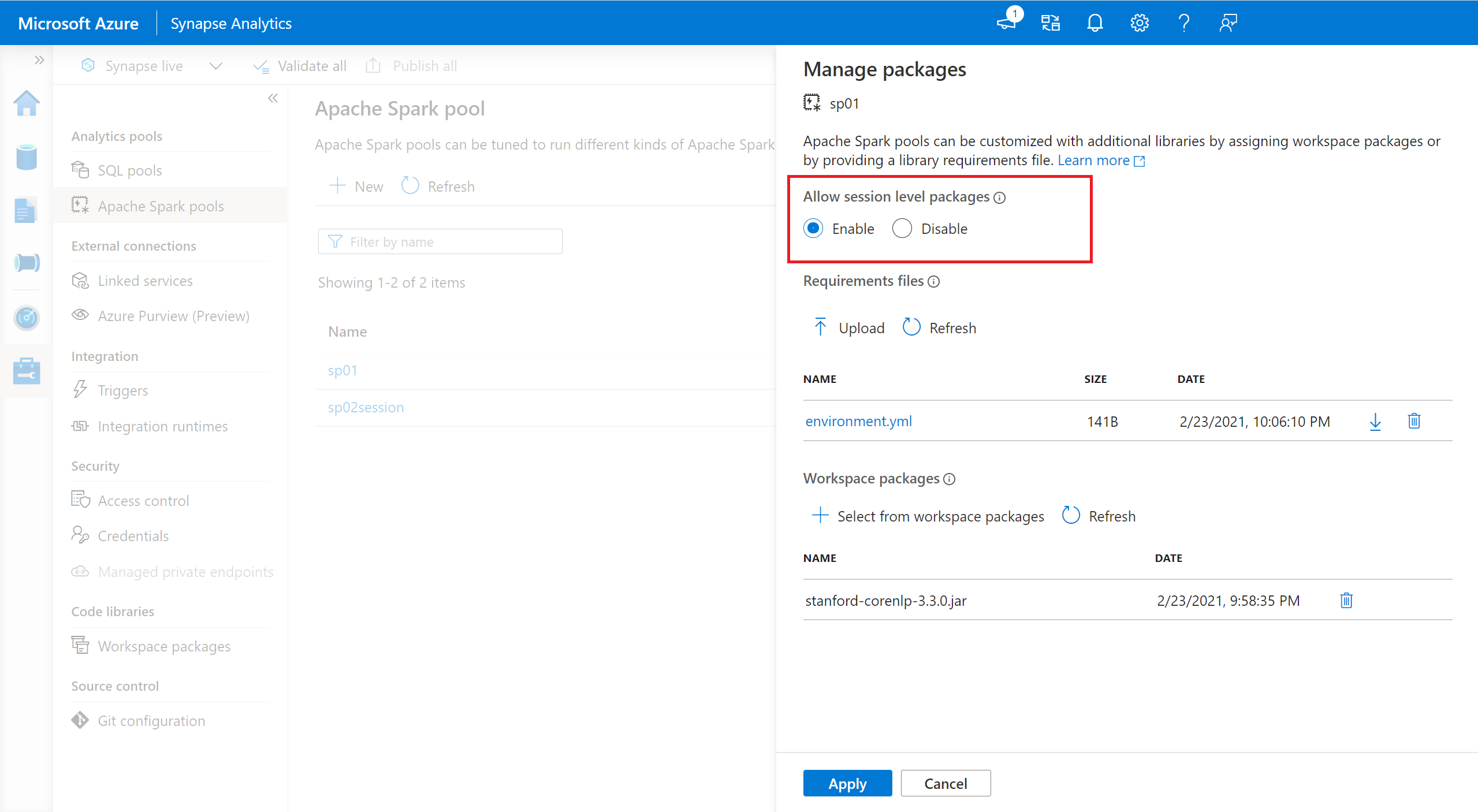
- Dopo aver applicato l'impostazione, è possibile aprire un notebook e selezionare Configura sessione>Pacchetti.

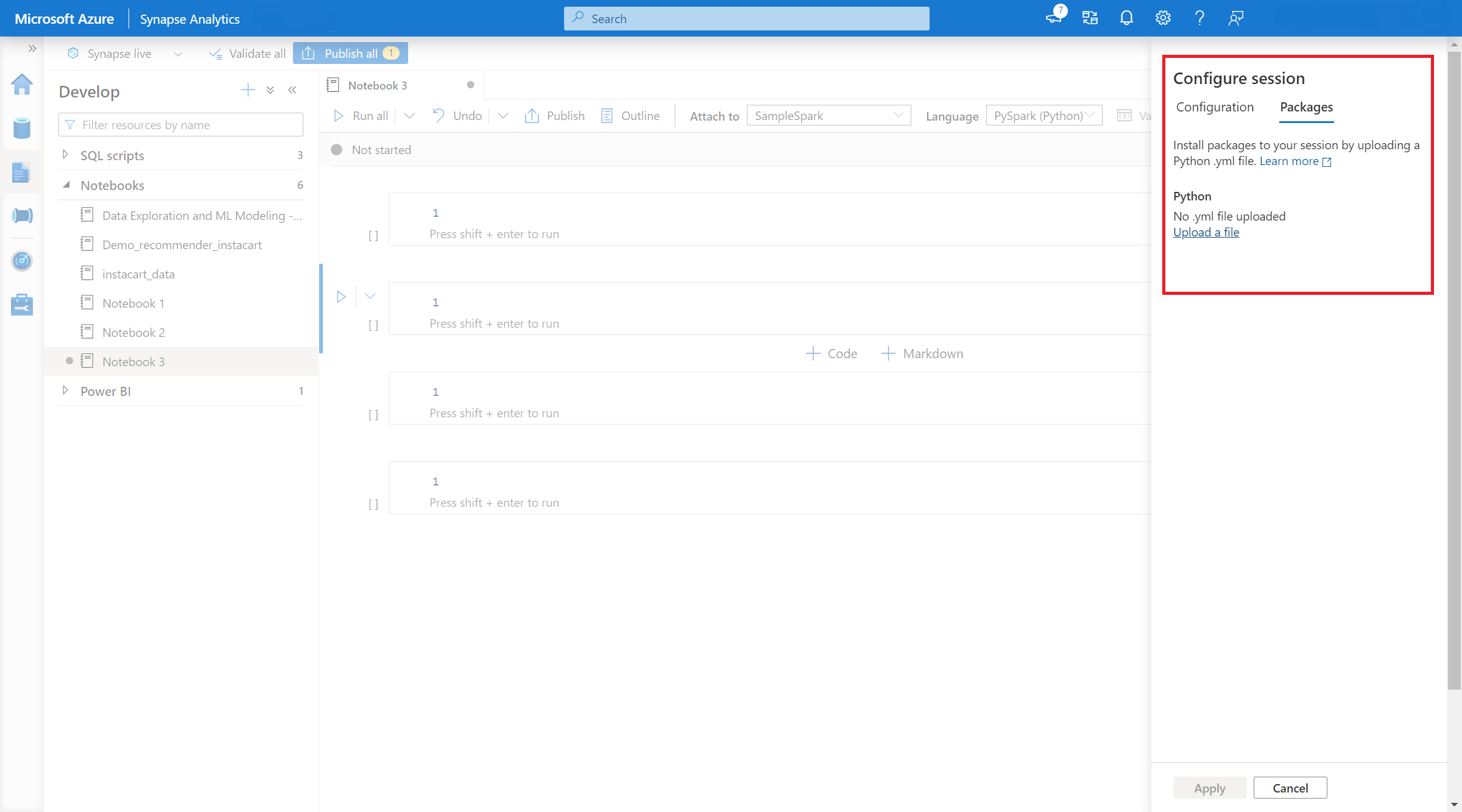
- Qui è possibile caricare un file Conda environment.yml per installare o aggiornare i pacchetti all'interno di una sessione. Le librerie specificate sono presenti all'avvio della sessione. Queste librerie non saranno più disponibili al termine della sessione.

Gestire pacchetti Python con ambito sessione tramite i comandi %pip e %conda
È possibile usare i comuni comandi %pip e %conda per installare librerie di terze parti aggiuntive o librerie personalizzate durante la sessione del notebook di Apache Spark. In questa sezione vengono usati i comandi %pip per illustrare vari scenari comuni.
Nota
- È consigliabile inserire i comandi %pip e %conda nella prima cella del notebook se si desidera installare nuove librerie. L'interprete Python verrà riavviato dopo la gestione della libreria a livello di sessione, per rendere effettive le modifiche.
- Questi comandi di gestione delle librerie Python verranno disabilitati durante l'esecuzione di processi della pipeline. Se si desidera installare un pacchetto all'interno di una pipeline, è necessario sfruttare le funzionalità di gestione della libreria a livello di pool.
- Le librerie Python con ambito sessione vengono installate automaticamente nei nodi driver e di lavoro.
- I seguenti comandi %conda non sono supportati: create, clean, compare, activate, deactivate, run, package.
- È possibile fare riferimento ai comandi %pip e ai comandi %conda per l'elenco completo dei comandi.
Installare un pacchetto di terze parti
È possibile installare facilmente una libreria Python da PyPI.
# Install vega_datasets
%pip install altair vega_datasets
Per verificare il risultato dell'installazione, è possibile eseguire il codice seguente per visualizzare vega_datasets
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
Installare un pacchetto wheel dall'account di archiviazione
Per installare la libreria dall'archiviazione, è necessario montare nell'account di archiviazione eseguendo i comandi seguenti.
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
È quindi possibile usare il comando %pip install per installare il pacchetto wheel richiesto
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
Installare un'altra versione della libreria predefinita
È possibile usare il comando seguente per vedere qual è la versione predefinita di un determinato pacchetto. Come esempio viene usato pandas
%pip show pandas
Il risultato è il log seguente:
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
È possibile usare il comando seguente per passare da pandas a un'altra versione, ad esempio 1.2.4
%pip install pandas==1.2.4
Disinstallare una libreria con ambito sessione
Se si desidera disinstallare un pacchetto installato in questa sessione del notebook, è possibile fare riferimento ai comandi seguenti. Tuttavia, non è possibile disinstallare i pacchetti predefiniti.
%pip uninstall altair vega_datasets --yes
Uso del comando %pip per installare librerie da un file requirement.txt
%pip install -r /<<path to requirement file>>/requirements.txt
Pacchetti Java o Scala con ambito sessione
Per specificare pacchetti Java o Scala con ambito sessione, è possibile usare l'opzione %%configure:
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
Nota
- È consigliabile eseguire %%configure all'inizio del notebook. È possibile fare riferimento a questo documento per l'elenco completo dei parametri validi.
Pacchetti R con ambito sessione (Anteprima)
I pool di Azure Synapse Analytics includono numerose librerie R comuni predefinite. È anche possibile installare librerie di terze parti aggiuntive durante la sessione del notebook di Apache Spark.
Nota
- Questi comandi di gestione delle librerie R verranno disabilitati durante l'esecuzione di processi della pipeline. Se si desidera installare un pacchetto all'interno di una pipeline, è necessario sfruttare le funzionalità di gestione della libreria a livello di pool.
- Le librerie R con ambito sessione vengono installate automaticamente nei nodi driver e di lavoro.
Installare un pacchetto
È possibile installare facilmente una libreria R da CRAN.
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
È anche possibile usare snapshot CRAN come repository per assicurarsi di scaricare ogni volta la stessa versione del pacchetto.
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Uso di devtools per installare i pacchetti
La libreria devtools semplifica lo sviluppo di pacchetti per accelerare le attività comuni. Questa libreria viene installata all'interno del runtime predefinito di Azure Synapse Analytics.
È possibile usare devtools per specificare una versione specifica di una libreria da installare. Queste librerie verranno installate in tutti i nodi all'interno del cluster.
# Install a specific version.
install_version("caesar", version = "1.0.0")
Analogamente, è possibile installare una libreria direttamente da GitHub.
# Install a GitHub library.
install_github("jtilly/matchingR")
Attualmente, le funzioni devtools seguenti sono supportate in Azure Synapse Analytics:
| Comando | Descrizione |
|---|---|
| install_github() | Installa un pacchetto R da GitHub |
| install_gitlab() | Installa un pacchetto R da GitLab |
| install_bitbucket() | Installa un pacchetto R da BitBucket |
| install_url() | Installa un pacchetto R da un URL arbitrario |
| install_git() | Installa da un repository Git arbitrario |
| install_local() | Installa da un file locale su disco |
| install_version() | Installa da una versione specifica in CRAN |
Visualizzare le librerie installate
È possibile eseguire query su tutte le librerie installate all'interno della sessione usando il comando library.
library()
È possibile usare la funzione packageVersion per controllare la versione della libreria:
packageVersion("caesar")
Rimuovere un pacchetto R da una sessione
È possibile usare la funzione detach per rimuovere una libreria dallo spazio dei nomi. Queste librerie rimangono su disco finché non vengono ricaricate.
# detach a library
detach("package: caesar")
Per rimuovere un pacchetto con ambito sessione da un notebook, usare il comando remove.packages(). Questa modifica della libreria non ha alcun impatto su altre sessioni nello stesso cluster. Gli utenti non possono disinstallare o rimuovere librerie integrate del runtime predefinito di Azure Synapse Analytics.
remove.packages("caesar")
Nota
Non è possibile rimuovere pacchetti di base come SparkR, SparklyR o R.
Librerie R con ambito sessione e SparkR
Le librerie con ambito notebook sono disponibili nei ruoli di lavoro SparkR.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Librerie R con ambito sessione e SparklyR
Con spark_apply() in SparklyR, è possibile usare qualsiasi pacchetto R all'interno di Spark. Per impostazione predefinita, in sparklyr::spark_apply(), l'argomento packages è impostato su FALSE. Questa operazione copia le librerie nei percorsi libPath correnti ai ruoli di lavoro, consentendo di importarle e usarle nei ruoli di lavoro. Ad esempio, è possibile eseguire quanto segue per generare un messaggio con crittografia Caesar con sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Passaggi successivi
- Visualizzare le librerie predefinite: supporto della versione di Apache Spark
- Gestire i pacchetti all'esterno del portale di Synapse Studio: gestire i pacchetti tramite i comandi Az e le API REST