Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Suggerimento
Microsoft Fabric Data Warehouse è un data warehouse relazionale su scala aziendale su una base data lake, con un'architettura futura, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con il data warehousing, iniziare con Fabric Data Warehouse. I carichi di lavoro esistenti del pool SQL dedicated possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Si applica a: Pool SQL dedicati di Azure Synapse Analytics
Quando gli utenti eseguono query su una tabella columnstore nel pool SQL dedicato, l'utilità di ottimizzazione controlla i valori minimi e massimi archiviati in ogni segmento. I segmenti esterni ai limiti del predicato di query non vengono letti dal disco alla memoria. Una query può essere completata più velocemente se il numero di segmenti da leggere e le dimensioni totali sono ridotte.
Nota
Questo articolo si applica ai pool SQL dedicati di Azure Synapse Analytics. Per informazioni sugli indici columnstore ordinati in SQL Server e altre piattaforme SQL, vedere Ottimizzazione delle prestazioni con indici columnstore cluster ordinati.
Indice columnstore con cluster ordinato e non ordinato
Per impostazione predefinita, per ogni tabella creata senza un'opzione di indice, un componente interno (generatore di indici) crea un indice columnstore cluster (CCI) non ordinato su di esso. I dati in ogni colonna vengono compressi in un segmento rowgroup CCI separato. Sono presenti metadati nell'intervallo di valori di ogni segmento, quindi i segmenti esterni ai limiti del predicato di query non vengono letti dal disco durante l'esecuzione della query. Il CCI offre il massimo livello di compressione dei dati e riduce le dimensioni dei segmenti da leggere in modo che le query possano essere eseguite più velocemente. Tuttavia, poiché il generatore di indici non ordina i dati prima di comprimerli in segmenti, possono verificarsi segmenti con intervalli di valori sovrapposti, causando la lettura di più segmenti dal disco e richiedere più tempo per il completamento.
Indici columnstore con cluster ordinato abilitando l'eliminazione efficiente dei segmenti di dati, con prestazioni significativamente più veloci saltando grandi quantità di dati ordinati non corrispondenti al predicato della query. Quando si crea un CCI ordinato, il motore del pool SQL dedicato ordina i dati esistenti in memoria in base alle chiavi dell'ordine prima che il generatore di indici li comprima in segmenti di indice. Con i dati ordinati, la sovrapposizione dei segmenti viene ridotta consentendo alle query di ottenere un'eliminazione dei segmenti più efficiente e quindi prestazioni più veloci perché il numero di segmenti da leggere dal disco è inferiore. Se tutti i dati possono essere ordinati in memoria contemporaneamente, è possibile evitare la sovrapposizione dei segmenti. A causa di tabelle di grandi dimensioni nei data warehouse, questo scenario non si verifica spesso.
Per controllare gli intervalli di segmenti per una colonna, eseguire il comando seguente con il nome della tabella e della colonna:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Nota
In una tabella con CCI ordinato, i nuovi dati risultanti dallo stesso batch di operazioni di caricamento dati o DML vengono ordinati all'interno di tale batch; non esiste un ordinamento globale tra tutti i dati nella tabella. Gli utenti possono ricostruire il CCI ordinato per riordinare tutti i dati nella tabella. Nel pool SQL dedicato, l'istruzione REBUILD sull'indice columnstore è un'operazione offline. Per una tabella partizionata, l'istruzione REBUILD viene eseguita una partizione alla volta. I dati nella partizione da ricompilare sono "offline" e non sono disponibili fino al completamento dell'istruzione REBUILD per tale partizione.
Prestazioni delle query
Il miglioramento delle prestazioni di una query da un CCI ordinato dipende dai modelli di query, dalle dimensioni dei dati, dal livello di ordinamento dei dati, dalla struttura fisica dei segmenti e dalla DWU e dalla classe di risorse scelta per l'esecuzione della query. Gli utenti devono esaminare tutti questi fattori prima di scegliere le colonne di ordinamento durante la progettazione di una tabella con CCI ordinato.
Le query con tutti questi modelli vengono in genere eseguite più velocemente con un CCI ordinato.
- Le interrogazioni hanno predicati di eguaglianza, disuguaglianza o di intervallo.
- Colonne del predicato e colonne CCI ordinate sono le stesse.
In questo esempio, la tabella T1 ha un indice columnstore ordinato con cluster nella sequenza di Col_C, Col_B e Col_A.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
Le prestazioni della query 1 e della query 2 possono trarre vantaggio da CCI ordinati rispetto alle altre query, perché fanno riferimento a tutte le colonne con CCI ordinato.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Prestazioni di caricamento dei dati
Le prestazioni del caricamento dei dati in una tabella con CCI ordinato sono simili a una tabella partizionata. Il caricamento dei dati in una tabella con CCI ordinato può richiedere più tempo rispetto a una tabella con CCI non ordinato a causa dell'operazione di ordinamento dei dati, tuttavia le query possono essere eseguite più velocemente in seguito con un CCI ordinato.
Di seguito è riportato un esempio di confronto delle prestazioni del caricamento dei dati in tabelle con schemi diversi.
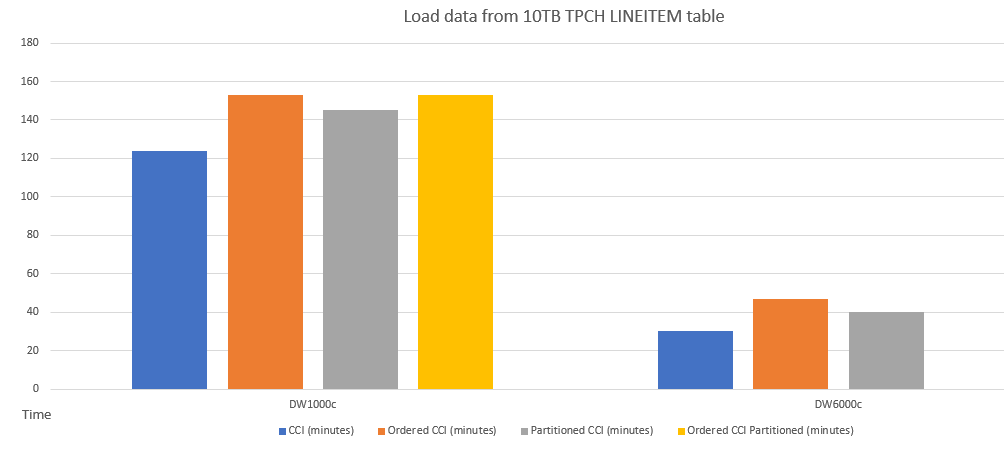
Di seguito è riportato un esempio di confronto delle prestazioni delle query tra CCI e CCI ordinato.
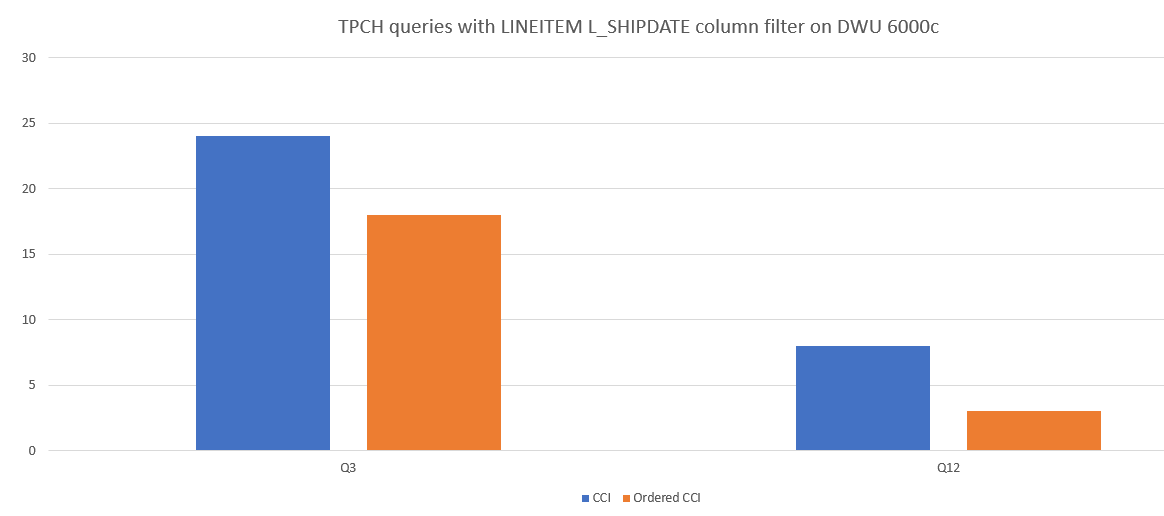
Ridurre la sovrapposizione dei segmenti
Il numero di segmenti sovrapposti dipende dalle dimensioni dei dati da ordinare, dalla memoria disponibile e dall'impostazione del massimo grado di parallelismo (MAXDOP) durante la creazione di CCI ordinati. Le strategie seguenti riducono la sovrapposizione dei segmenti durante la creazione di CCI ordinati.
Usare la classe di risorse
xlargercin una DWU superiore per consentire un maggior numero di memoria per l'ordinamento dei dati prima che il generatore di indici comprima i dati in segmenti. Una volta in un segmento indicizzato, non è possibile modificare la posizione fisica dei dati. Non esiste alcun ordinamento dei dati all'interno di un segmento o tra segmenti.Creare un CCI ordinato con
OPTION (MAXDOP = 1). Ogni thread usato per la creazione di un CCI ordinato funziona su un subset di dati e lo ordina localmente. Non esiste un ordinamento globale tra i dati ordinati in base a thread diversi. L'uso di thread paralleli può ridurre il tempo necessario per creare un CCI ordinato, ma genererà più segmenti sovrapposti rispetto all'uso di un singolo thread. L'uso di un'operazione a thread singolo offre la massima qualità di compressione. Ad esempio:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Nota
Attualmente, nei pool SQL dedicati in Azure Synapse Analytics, l'opzione MAXDOP è supportata solo per la creazione di una tabella con CCI ordinato usando il comando CREATE TABLE AS SELECT. La creazione di un CCI ordinato tramite i comandi CREATE INDEX o CREATE TABLE non supporta l'opzione MAXDOP. Questa limitazione non si applica a SQL Server 2022 e versioni successive, in cui è possibile specificare MAXDOP con i comandi CREATE INDEX o CREATE TABLE.
- Pre-ordinare i dati in base alle chiavi di ordinamento prima di caricarli nelle tabelle.
Di seguito è riportato un esempio di distribuzione di una tabella con CCI ordinato senza sovrapposizione dei segmenti seguendo le indicazioni precedenti. La tabella con CCI ordinato viene creata in un database DWU1000c tramite CTAS da una tabella heap da 20 GB usando MAXDOP 1 e xlargerc. Il CCI viene ordinato in una colonna BIGINT senza duplicati.
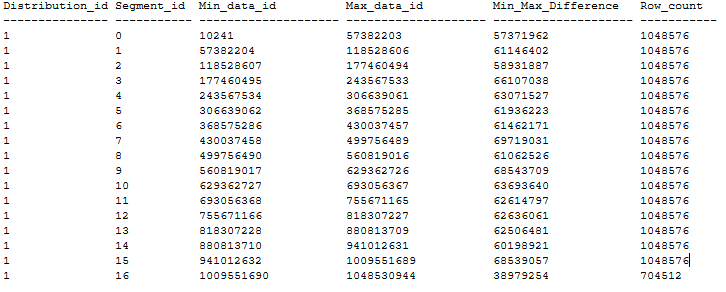
Creare CCI ordinati in tabelle grandi
La creazione di un CCI ordinato è un'operazione offline. Per le tabelle senza partizioni, i dati non saranno accessibili agli utenti fino al completamento del processo di creazione del CCI ordinato. Per le tabelle partizionate, anche se il motore crea il CCI ordinato partizione per partizione, gli utenti possono comunque accedere ai dati nelle partizioni in cui la creazione del CCI ordinato non è attualmente in corso. È possibile usare questa opzione per ridurre al minimo i tempi di inattività durante la creazione di CCI ordinati in tabelle di grandi dimensioni:
- Creare partizioni nella tabella di grandi dimensioni di destinazione (denominata
Table_A). - Creare una tabella vuota ordinata con CCI (denominata
Table_B) con lo stesso schema di tabella e partizione diTable_A. - Commutare una partizione da
Table_AaTable_B. - Eseguire
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>per ricompilare la partizione attivata suTable_B. - Ripetere i passaggi 3 e 4 per ogni partizione in
Table_A. - Dopo che tutte le partizioni sono passate da
Table_AaTable_Be sono state ricompilate, eliminareTable_Ae rinominareTable_BinTable_A.
Suggerimento
Per una tabella del pool SQL dedicato con un CCI ordinato, ALTER INDEX REBUILD riordina i dati usando tempdb. Monitorare tempdb durante le operazioni di ricompilazione. Se hai bisogno di più spazio tempdb, aumenta le dimensioni del pool. Tornare alle dimensioni precedenti al termine della ricompilazione dell'indice.
Per una tabella dedicata del pool SQL con un CCI ordinato, ALTER INDEX REORGANIZE non riordina i dati. Per riordinare i dati, usare ALTER INDEX REBUILD.
Per ulteriori informazioni sul mantenimento degli indici CCI ordinati, consultare Ottimizzazione degli indici columnstore raggruppati.
Differenze di funzionalità nelle caratteristiche di SQL Server 2022
SQL Server 2022 (16.x) ha introdotto indici columnstore cluster ordinati simili alla funzionalità nei pool SQL dedicati di Azure Synapse.
- Attualmente, solo SQL Server 2022 (16.x) e versioni successive supportano le funzionalità di eliminazione del segmento avanzate del columnstore cluster per i tipi di dati stringa, binari e GUID e il tipo di dati datetimeoffset con scala superiore a due. In precedenza, l'eliminazione dei segmenti si applica ai tipi di dati numerici, di data e ora e al tipo di dati datetimeoffset con scala inferiore o uguale a due.
- Attualmente, solo SQL Server 2022 (16.x) e versioni successive supportano l'eliminazione del gruppo di righe in columnstore con cluster per il prefisso dei predicati
LIKE, ad esempiocolumn LIKE 'string%'. L'eliminazione dei segmenti non è supportata per l'uso senza prefisso di LIKE, ad esempiocolumn LIKE '%string'.
Per altre informazioni, vedere Novità degli indici columnstore.
Esempi
A. Per verificare la presenza di colonne ordinate e ordinare i dati in modalità ordinale.
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Per modificare l'ordinale di colonna, aggiungere o rimuovere colonne dall'elenco degli ordini o per passare dal CCI al CCI ordinato:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Passaggi successivi
- Per altri suggerimenti sullo sviluppo, vedere la panoramica dello sviluppo.
- Indici columnstore: Panoramica
- Novità degli indici columnstore
- Indici columnstore - Linee guida per la progettazione
- Indici Columnstore - Prestazione delle query