Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Suggerimento
Microsoft Fabric Data Warehouse è un data warehouse relazionale su scala aziendale su una base data lake, con un'architettura futura, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con il data warehousing, iniziare con Fabric Data Warehouse. I carichi di lavoro esistenti del pool SQL dedicated possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
La funzione OPENROWSET(BULK...) consente di accedere ai file di Archiviazione di Azure. La funzione OPENROWSET legge il contenuto di un'origine dati remota, ad esempio un file, e lo restituisce come set di righe. All'interno della risorsa pool SQL serverless il provider bulk per set di righe OPENROWSET è accessibile chiamando la funzione OPENROWSET e specificando l'opzione BULK.
È possibile fare riferimento alla funzione OPENROWSET nella clausola FROM di una query come se fosse un nome di tabella OPENROWSET. Supporta le operazioni in blocco tramite un provider BULK predefinito che consente di leggere i dati da un file e restituirli come set di righe.
Nota
La funzione OPENROWSET non è supportata nel pool SQL dedicato.
Origine dati
La funzione OPENROWSET in Synapse SQL legge il contenuto dei file da un'origine dati. L'origine dati è un account di archiviazione di Azure a cui è possibile fare riferimento esplicitamente nella funzione OPENROWSET o che può essere dedotta dinamicamente dall'URL dei file da leggere.
La funzione OPENROWSET può facoltativamente contenere un parametro DATA_SOURCE per specificare l'origine dati che contiene i file.
È possibile usare
OPENROWSETsenzaDATA_SOURCEper leggere direttamente il contenuto dei file dal percorso URL specificato come opzioneBULK:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Si tratta di un modo semplice e rapido per leggere il contenuto dei file senza preconfigurazione. Questa opzione consente di usare l'opzione di autenticazione di base per accedere all'archiviazione (pass-through di Microsoft Entra per i logins di Microsoft Entra e token SAS per i logins SQL).
È possibile usare
OPENROWSETconDATA_SOURCEper accedere ai file nell'account di archiviazione specificato:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Questa opzione consente di configurare la posizione dell'account di archiviazione nell'origine dati e di specificare il metodo di autenticazione da usare per accedere all'archiviazione.
Importante
OPENROWSETsenzaDATA_SOURCEfornisce un metodo semplice e rapido per accedere ai file di archiviazione, ma offre opzioni di autenticazione limitate. Ad esempio, i principali Microsoft Entra possono accedere ai file solo utilizzando la loro identità di Microsoft Entra o i file disponibili pubblicamente. Se sono necessarie opzioni di autenticazione più avanzate, usare l'opzioneDATA_SOURCEe definire le credenziali da usare per accedere all'archiviazione.
Sicurezza
Per usare la funzione ADMINISTER BULK OPERATIONS, un utente di database deve avere l'autorizzazione OPENROWSET.
L'amministratore dell'archiviazione deve anche consentire a un utente di accedere ai file fornendo un SAS token valido o consentendo al principal di Microsoft Entra di accedere ai file di archiviazione dati. Per altre informazioni sul controllo di accesso all'archiviazione, vedere questo articolo.
OPENROWSET usa le regole seguenti per determinare la modalità di autenticazione per l'archiviazione:
- In
OPENROWSETsenzaDATA_SOURCEil meccanismo di autenticazione dipende dal tipo di chiamante.- Qualsiasi utente può usare
OPENROWSETsenzaDATA_SOURCEper leggere i file disponibili pubblicamente in Archiviazione di Azure. - Gli account di accesso di Microsoft Entra possono accedere ai file protetti usando la propria identità di Microsoft Entra se Archiviazione di Azure consente all'utente di Microsoft Entra di accedere ai file sottostanti, ad esempio, se il chiamante dispone dell'autorizzazione
Storage Readerper Archiviazione di Azure. - Gli account di accesso di SQL possono anche usare
OPENROWSETsenzaDATA_SOURCEper accedere ai file disponibili pubblicamente, ai file protetti tramite token SAS o all'identità gestita del workspace Synapse. È necessario creare credenziali con ambito server per consentire l'accesso ai file di archiviazione.
- Qualsiasi utente può usare
- In
OPENROWSETconDATA_SOURCEil meccanismo di autenticazione è definito nelle credenziali con ambito database assegnate all'origine dati a cui viene fatto riferimento. Questa opzione consente di accedere a uno spazio di archiviazione disponibile pubblicamente oppure di accedere all'archiviazione utilizzando un token SAS, l'Identità Gestita dell'area di lavoro o l'identità di Microsoft Entra del chiamante (se il chiamante è un'entità di Microsoft Entra). SeDATA_SOURCEfa riferimento all'archiviazione di Azure non pubblica, sarà necessario creare credenziali con ambito database e farvi riferimento inDATA SOURCEper consentire l'accesso ai file di archiviazione.
Il chiamante deve avere l'autorizzazione REFERENCES sulla credenziale per usarla per autenticarsi all'archiviazione.
Sintassi
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Argomenti
Sono disponibili tre opzioni per i file di input che contengono i dati di destinazione per le query. I valori validi sono:
'CSV': include qualsiasi file di testo delimitato con separatori di riga e colonna. Come separatore di campo è possibile usare qualsiasi carattere, ad esempio TSV: FIELDTERMINATOR = tab.
"PARQUET": file binario in formato Parquet.
"DELTA": un insieme di file Parquet organizzati nel formato Delta Lake (anteprima).
I valori con spazi vuoti non sono validi. Ad esempio, "CSV" non è un valore valido.
'unstructured_data_path'
L'elemento unstructured_data_path che stabilisce un percorso dei dati può essere un percorso assoluto o relativo:
- Il percorso assoluto nel formato
\<prefix>://\<storage_account_path>/\<storage_path>consente a un utente di leggere direttamente i file. - Il percorso relativo nel formato
<storage_path>deve essere usato con il parametroDATA_SOURCEe descrive il modello di file all'interno del percorso <storage_account_path> definito inEXTERNAL DATA SOURCE.
Di seguito sono indicati i valori del <percorso di account di archiviazione> pertinenti che verranno collegati a una specifica origine dati esterna.
| Origine dati esterna | Prefisso | Percorso dell'account di archiviazione |
|---|---|---|
| Archiviazione BLOB di Azure | http[s] | <storage_account>.blob.core.windows.net/path/file |
| Archiviazione BLOB di Azure | wasb[s] | <container>@<storage_account.blob.core.windows.net/path/file> |
| Azure Data Lake Store Gen1 | http[s] | < >storage_account.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store Gen2 | http[s] | <storage_account>.dfs.core.windows.net/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | <file_system>@<account_name.dfs.core.windows.net/path/file> |
"<storage_path>"
Specifica un percorso all'interno dell'archiviazione che punta alla cartella o al file da leggere. Se il percorso punta a un contenitore o a una cartella, tutti i file verranno letti da quel particolare contenitore o cartella. I file nelle sottocartelle non verranno inclusi.
È possibile usare i caratteri jolly per scegliere più file o cartelle come destinazione. È consentito l'utilizzo di più caratteri jolly non consecutivi.
Di seguito è riportato un esempio che legge tutti i file CSV che iniziano con population da tutte le cartelle che iniziano con /csv/population:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Se si specifica l'elemento unstructured_data_path come cartella, una query del pool SQL serverless recupererà i file da tale cartella.
È possibile impostare il pool SQL serverless in modo da attraversare le cartelle specificando /* alla fine del percorso, come nell'esempio seguente: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Nota
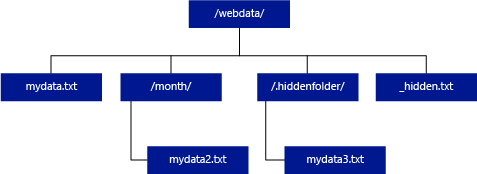
A differenza di Hadoop e PolyBase, il pool SQL serverless non restituisce le sottocartelle, a meno che non si specifichi /** alla fine del percorso. Proprio come in Hadoop e PolyBase, non restituisce file il cui nome inizia con un carattere di sottolineatura (_) o un punto (.).
Nell'esempio seguente, se unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/, una query del pool SQL serverless restituirà le righe di mydata.txt. Non restituirà mydata2.txt e mydata3.txt perché si trovano in una sottocartella.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
La clausola WITH consente di specificare le colonne da leggere nei file.
Nel caso di file di dati CSV, per leggere tutte le colonne specificare i relativi nomi e tipi di dati. Se si vuole specificare un sottoinsieme di colonne, selezionare le colonne dai file di dati di origine in base a numeri ordinali. Le colonne verranno associate in base alla designazione dell'ordinale. Se si usa HEADER_ROW = TRUE, l'associazione delle colonne viene eseguita per nome di colonna invece che in base alla posizione dell'ordinale.
Suggerimento
È possibile omettere la clausola WITH anche per i file CSV. I tipi di dati verranno dedotti automaticamente dal contenuto del file. È possibile usare l'argomento HEADER_ROW per specificare l'esistenza della riga di intestazione, nel qual caso i nomi delle colonne verranno letti dalla riga di intestazione. Per informazioni dettagliate, vedere Individuazione automatica dello schema.
Per i file di dati Parquet o Delta Lake, specificare i nomi di colonna che corrispondono a quelli dei file di dati di origine. Le colonne saranno associate in base al nome e con distinzione tra maiuscole e minuscole. Se la clausola WITH viene omessa, verranno restituite tutte le colonne dei file Parquet.
Importante
I nomi delle colonne nei file Parquet e Delta Lake fanno distinzione tra maiuscole e minuscole. Se si specifica il nome della colonna con una combinazione di maiuscole e minuscole diversa rispetto ai file, per tale colonna vengono restituiti valori
NULL.
column_name = nome della colonna di output. Se specificato, questo nome sostituisce il nome della colonna nel file di origine e il nome della colonna specificato nel percorso JSON, se presente. Se json_path non è specificato, viene aggiunto automaticamente come '$.column_name'. Per verificare il comportamento, controllare l'argomento json_path.
column_type = tipo di dati della colonna di output. Verrà eseguita la conversione implicita del tipo di dati.
column_ordinal = numero ordinale della colonna nel file o nei file di origine. Questo argomento viene ignorato per i file Parquet perché il binding viene eseguito per nome. Nell'esempio seguente viene restituita una seconda colonna solo da un file CSV:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = espressione di percorso JSON per una colonna o una proprietà annidata. La modalità percorso predefinita è lax.
Nota
In modalità rigorosa, la query fallirà con un errore se il percorso specificato non esiste. In modalità lax la query ha successo e l'espressione del percorso JSON verrà valutata a NULL.
<opzioni_di_massa>
FIELDTERMINATOR ='field_terminator'
Specifica il delimitatore del campo da usare. Il carattere di terminazione del campo predefinito è la virgola (",").
ROWTERMINATOR ="row_terminator"`
Specifica il terminatore di riga da usare. Se il carattere di terminazione della riga non è specificato, ne verrà usato uno predefinito. I caratteri di terminazione predefiniti per PARSER_VERSION = '1.0' sono \r\n, \n e \r. I caratteri di terminazione predefiniti per PARSER_VERSION ='2.0' sono \r\n e \n.
Nota
Se si usa PARSER_VERSION="1.0" e si specifica il carattere di nuova riga \n come carattere di terminazione della riga, verrà aggiunto automaticamente il carattere di ritorno a capo \r come prefisso, generando il carattere di terminazione della riga \r\n.
ESCAPE_CHAR = 'char'
Specifica il carattere nel file usato per l'escape di se stesso e di tutti i valori dei delimitatori del file. Se seguito da un valore diverso da se stesso o da uno qualsiasi dei valori dei delimitatori, il carattere di escape viene eliminato durante la lettura del valore.
Il parametro ESCAPECHAR verrà applicato indipendentemente dal fatto che FIELDQUOTE sia o meno abilitato. Non verrà usato per l'escape del carattere virgolette singole. Il carattere di virgolette deve essere impostato come escape con un altro carattere di virgolette. Il carattere di virgolette può essere visualizzato all'interno del valore della colonna solo se il valore è incapsulato con caratteri di virgolette.
FIRSTROW = 'first_row'
Specifica il numero della prima riga da caricare. Il valore predefinito è 1 e indica la prima riga nel file di dati specificato. I numeri di riga sono determinati dal conteggio dei caratteri di terminazione. FIRSTROW utilizza una numerazione basata su 1.
FIELDQUOTE = 'field_quote'
Specifica un carattere che verrà usato come carattere delle virgolette nel file CSV. Se non specificato, viene usato il carattere virgolette (").
DATA_COMPRESSION = 'metodo_di_compressione_dei_dati'
Specifica il metodo di compressione. Supportato solo in PARSER_VERSION='1.0'. È supportato il metodo di compressione seguente:
- GZIP
PARSER_VERSION = 'parser_version'
Specifica la versione del parser da usare per la lettura dei file. Le versioni del parser CSV attualmente supportate sono 1.0 e 2.0:
- PARSER_VERSION = '1,0'
- PARSER_VERSION = '2.0'
La versione 1.0 del parser CSV è l'impostazione predefinita ed è completa di tutte le funzionalità, La versione 2.0 è progettata per le prestazioni e non supporta tutte le opzioni e le codifiche.
Specifiche del parser CSV versione 1.0:
- Le opzioni seguenti non sono supportate: HEADER_ROW.
- I caratteri di terminazione predefiniti sono \r\n, \n e \r.
- Se si specifica \n (nuova riga) come terminatore di riga, verrà automaticamente aggiunto un prefisso con il carattere \r (ritorno a capo), generando un carattere di terminazione della riga \r\n.
Specifiche del parser CSV versione 2.0:
- Non sono supportati tutti i tipi di dati.
- La lunghezza massima della colonna di caratteri è 8000.
- Il limite massimo delle dimensioni di riga è 8 MB.
- Le opzioni seguenti non sono supportate: DATA_COMPRESSION.
- La stringa vuota racchiusa tra virgolette ("") viene interpretata come stringa vuota.
- L'opzione DATEFORMAT SET non viene rispettata.
- Formato supportato per il tipo di dati DATE: AAAA-MM-GG
- Formato supportato per il tipo di dati TIME: HH:MM:SS[.secondi frazionari]
- Formato supportato per il tipo di dati DATETIME2: HH:MM:SS[.secondi frazionari]
- I caratteri di terminazione predefiniti sono \r\n e \r.
HEADER_ROW = { TRUE | FALSO }
Specifica se il file CSV contiene o meno una riga di intestazione. Il valore predefinito è FALSE.. Supportato solo in PARSER_VERSION='2.0'. Se TRUE, i nomi delle colonne verranno letti dalla prima riga in base all'argomento FIRSTROW. Se TRUE e lo schema viene specificato usando WITH, l'associazione dei nomi di colonna verrà eseguita per nome di colonna e non in base alle posizioni degli ordinali.
DATAFILETYPE = { 'char' | 'widechar' }
Specifica la codifica: char viene usata per UTF8, widechar per i file UTF16.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
Specifica la pagina codice dei dati nel file di dati. Il valore predefinito è 65001 (codifica UTF-8). Per altri dettagli su questa opzione, vedere qui.
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
Questa opzione disabiliterà il controllo di modifica del file durante l'esecuzione della query e leggerà i file aggiornati durante l'esecuzione della query. Questa opzione è utile quando è necessario leggere file di solo accodamento aggiunti durante l'esecuzione della query. Nei file accodabili il contenuto esistente non viene aggiornato e vengono aggiunte solo le righe nuove. La probabilità di risultati errati è quindi minima rispetto ai file aggiornabili. Questa opzione potrebbe consentire di leggere i file accodati di frequente senza gestire gli errori. Per altre informazioni, vedere la sezione Esecuzione di query su file CSV accodabili.
Opzioni di rifiuto
Nota
La funzionalità Righe rifiutate è disponibile in anteprima pubblica. Si noti che la funzionalità Righe rifiutate funziona per i file di testo delimitati e PARSER_VERSION 1.0.
È possibile specificare i parametri di rifiuto che determinano in che modo il servizio gestirà i record dirty che recupera dall'origine dati esterna. Un record di dati è considerato 'dirty' se i tipi di dati effettivi non corrispondono alle definizioni di colonna della tabella esterna.
Se non si specificano o modificano i valori di rifiuto, il servizio usa i valori predefiniti. Il servizio userà le opzioni di rifiuto per determinare il numero di righe che possono essere rifiutate prima che la query effettiva abbia esito negativo. La query restituirà risultati (parziali) finché non viene superata la soglia di rifiuto, Fallisce quindi con il messaggio di errore appropriato.
MAXERRORS = reject_value
Specifica il numero di righe che possono essere rifiutate prima che la query abbia esito negativo. MAXERRORS deve essere un intero compreso tra 0 e 2.147.483.647.
ERRORFILE_DATA_SOURCE = origine dati
Specifica l'origine dati dove devono essere scritte le righe rifiutate e il file di errori corrispondente.
ERRORFILE_LOCATION = posizione della directory
Specifica la directory all'interno di DATA_SOURCE, o ERROR_FILE_DATASOURCE se specificata, in cui devono essere scritte le righe rifiutate e il file di errore corrispondente. Se il percorso specificato non esiste, il servizio ne crea uno automaticamente. Viene creata una directory figlio con nome "rejectedrows". Il carattere "" assicura che la directory venga ignorata da altre attività di elaborazione dati, a meno che non sia indicata in modo esplicito nel parametro del percorso. Questa directory include una cartella creata in base all'ora di inoltro del caricamento, con il formato AnnoMeseGiorno_OraMinutoSecondo_IDIstruzione, ad esempio 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891. È possibile usare l'ID istruzione per correlare la cartella con la query che l'ha generata. In questa cartella vengono scritti due file, il file error.json e il file di dati.
Il file error.json contiene una matrice JSON con gli errori riscontrati relativi alle righe rifiutate. Ogni elemento che rappresenta un errore contiene gli attributi seguenti:
| Attributo | Descrizione |
|---|---|
| Errore | Motivo per cui la riga viene rifiutata. |
| Riga | Numero ordinale della riga rifiutata nel file. |
| Colonna | Numero ordinale della colonna rifiutata. |
| Valore | Valore della colonna rifiutata. Se il valore è maggiore di 100 caratteri, verranno visualizzati solo i primi 100 caratteri. |
| file | Percorso del file a cui appartiene la riga. |
Analisi rapida del testo delimitato
È possibile usare due versioni del parser di testo delimitato. La versione 1.0 del parser CSV è l'impostazione predefinita ed è completa di tutte le funzionalità, mentre la versione 2.0 è progettata per le prestazioni. Le prestazioni più elevate del parser 2.0 sono attribuibili a tecniche di analisi avanzate e al multi-threading. La differenza di velocità sarà maggiore con l'aumento delle dimensioni dei file.
Individuazione automatica dello schema
È possibile eseguire facilmente query su file CSV e Parquet senza conoscere o specificare lo schema omettendo la clausola WITH. I nomi delle colonne e i tipi di dati verranno dedotti dai file.
I file Parquet contengono metadati di colonna che verranno letti. I mapping dei tipi sono disponibili in Mapping dei tipi per Parquet. Per alcuni esempi, vedere Leggere i file Parquet senza specificare lo schema.
Per i file CSV, i nomi delle colonne possono essere letti dalla riga di intestazione. È possibile specificare se la riga di intestazione esiste o meno con l'argomento HEADER_ROW. Se HEADER_ROW = FALSE, verranno usati nomi di colonne generici: C1, C2 e così via. Cn, in cui n è il numero di colonne del file. I tipi di dati verranno dedotti dalle prime 100 righe di dati. Per alcuni esempi, vedere Leggere i file CSV senza specificare lo schema.
Tenere presente che se si leggono numerosi file contemporaneamente, lo schema verrà dedotto dal primo file che il servizio recupera dall'archiviazione. Ciò può significare che alcune colonne previste vengono omesse, perché non sono contenute nel file usato dal servizio per definire lo schema. In tal caso, usare la clausola OPENROWSET WITH.
Importante
In alcuni casi non è possibile dedurre il tipo di dati appropriato a causa della mancanza di informazioni e verrà quindi usato un tipo di dati più grande. Questo comporta un sovraccarico delle prestazioni ed è particolarmente importante per le colonne di caratteri che verranno dedotte come varchar (8000). Per prestazioni ottimali, controllare i tipi di dati dedotti e usare i tipi di dati appropriati.
Mappatura dei tipi per Parquet
I file Parquet e Delta Lake contengono descrizioni dei tipi per ogni colonna. La tabella seguente descrive il mapping dei tipi Parquet ai tipi SQL nativi.
| Tipo Parquet | Tipo logico Parquet (annotazione) | Tipo di dati SQL |
|---|---|---|
| BOOLEAN | bit | |
| BINARY/BYTE_ARRAY | varbinary | |
| DOUBLE | float | |
| FLOAT | Real | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binario | |
| BINARY | UTF8 | varchar *(regole di confronto UTF8) |
| BINARY | STRING | varchar *(regole di confronto UTF8) |
| BINARY | ENUM | varchar *(regole di confronto UTF8) |
| FIXED_LEN_BYTE_ARRAY | UUID | uniqueidentifier |
| BINARY | DECIMAL | decimale |
| BINARY | JSON | varchar(8000) * (regole di confronto UTF8) |
| BINARY | BSON | Non supportato |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | decimale |
| BYTE_ARRAY | INTERVALLO | Non supportato |
| INT32 | INT(8, true) | smallint |
| INT32 | INT(16, true) | smallint |
| INT32 | INT(32, true) | int |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16, false) | int |
| INT32 | INT(32, false) | bigint |
| INT32 | DATA | data |
| INT32 | DECIMAL | decimale |
| INT32 | TEMPO (MILLIS) | tempo |
| INT64 | INT(64, true) | bigint |
| INT64 | INT(64, false) | decimal(20,0) |
| INT64 | DECIMAL | decimale |
| INT64 | TIME (MICROS) | tempo |
| INT64 | TEMPO (NANOSECONDI) | Non supportato |
| INT64 | TIMESTAMP (normalizzato in UTC) (MILLISECONDI/MICROSECONDI) | datetime2 |
| INT64 | TIMESTAMP (non normalizzato in UTC) (MILLISECONDI/MICROSECONDI) | bigint: assicurarsi di modificare in modo esplicito il valore bigint con l'offset del fuso orario prima di convertirlo in un valore datetime. |
| INT64 | TIMESTAMP (NANOSECONDI) | Non supportato |
| Tipo complesso | ELENCO | varchar(8000), serializzato in JSON |
| Tipo complesso | MAP | varchar(8000), serializzato in JSON |
Esempi
Leggere i file CSV senza specificare lo schema
Nell'esempio seguente viene letto un file CSV che contiene una riga di intestazione, senza specificare i nomi delle colonne e i tipi di dati:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
Nell'esempio seguente viene letto un file CSV che non contiene una riga di intestazione, senza specificare i nomi delle colonne e i tipi di dati:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Leggere i file Parquet senza specificare lo schema
L'esempio seguente restituisce tutte le colonne della prima riga del set di dati di censimento in formato Parquet, senza specificare nomi di colonna e tipi di dati:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Leggere i file Delta Lake senza specificare lo schema
L'esempio seguente restituisce tutte le colonne della prima riga del set di dati di censimento in formato Delta Lake, senza specificare nomi di colonna e tipi di dati:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Leggere specifiche colonne dal file CSV
L'esempio seguente restituisce solo due colonne con i numeri ordinali 1 e 4 dai file population*.csv. Poiché i file non includono una riga di intestazione, la lettura inizia dalla prima riga:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Leggere specifiche colonne dal file Parquet
L'esempio seguente restituisce solo due colonne della prima riga dal set di dati di censimento in formato Parquet:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Specificare le colonne usando percorsi JSON
L'esempio seguente mostra come usare le espressioni di percorso JSON in una clausola WITH e illustra la differenza tra le modalità di percorso strict e lax:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Specificare più file/cartelle nel percorso BULK
L'esempio seguente illustra come usare più percorsi di file/cartelle nel parametro BULK:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Passaggi successivi
Per altri esempi, vedere la guida introduttiva per l'esecuzione di query sui dati di archiviazione per informazioni su come usare OPENROWSET per leggere i file nei formati di file CSV, PARQUET, DELTA LAKE e JSON. Per informazioni su come ottenere prestazioni ottimali, vedere le procedure consigliate. È anche possibile acquisire informazioni su come salvare i risultati della query in Archiviazione di Azure con CETAS.