Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a: ✔️ macchine virtuali Linux
Questo articolo illustra l'uso di Backup di Azure per acquisire gli snapshot dei dischi della macchina virtuale, inclusi i file di Oracle Database e l'area di recupero rapido di Oracle. Usando Backup di Azure, è possibile acquisire snapshot completi del disco adatti come backup e che vengono archiviati in un insieme di credenziali di Servizi di ripristino.
Backup di Azure offre anche backup coerenti con l'applicazione, che eliminano la necessità di correzioni aggiuntive per ripristinare i dati. I backup coerenti con l'applicazione funzionano sia con i database del file system che con quelli di Oracle Automatic Storage Management (ASM).
Il ripristino di dati coerenti con l'applicazione riduce il tempo di ripristino e consente quindi di tornare rapidamente allo stato operativo. Il recupero di Oracle Database è comunque necessario dopo il recupero. È possibile facilitare il recupero usando i file di log di rollforward archiviati da Oracle acquisiti e archiviati in una condivisione file di Azure separata.
L'articolo guida l'utente nell'esecuzione delle attività seguenti:
- Eseguire il backup del database con backup coerenti con l'applicazione.
- Recuperare e ripristinare il database da un punto di recupero.
- Ripristinare la macchina virtuale da un punto di recupero.
Prerequisiti
Usare l'ambiente Bash in Azure Cloud Shell. Per altre informazioni, vedere Introduzione ad Azure Cloud Shell.

Se si preferisce eseguire i comandi di riferimento dell'interfaccia della riga di comando in locale, installare l'interfaccia della riga di comando di Azure. Per l'esecuzione in Windows o macOS, è consigliabile eseguire l'interfaccia della riga di comando di Azure in un contenitore Docker. Per altre informazioni, vedere Come eseguire l'interfaccia della riga di comando di Azure in un contenitore Docker.
Se si usa un'installazione locale, accedere all'interfaccia della riga di comando di Azure con il comando az login. Per completare il processo di autenticazione, seguire la procedura visualizzata nel terminale. Per altre opzioni di accesso, vedere Eseguire l'autenticazione ad Azure con l'interfaccia della riga di comando di Azure.
Quando richiesto, al primo utilizzo installare l'estensione dell'interfaccia della riga di comando di Azure. Per altre informazioni sulle estensioni, vedere Usare e gestire le estensioni con l'interfaccia della riga di comando di Azure.
Eseguire az version per trovare la versione e le librerie dipendenti installate. Per eseguire l'aggiornamento alla versione più recente, eseguire az upgrade.
Per eseguire il processo di backup e recupero, è necessario innanzitutto creare una macchina virtuale Linux con un'istanza di Oracle Database 12.1 o una versione successiva installata.
Creare un'istanza di Oracle Database seguendo i passaggi descritti in Creare un'istanza di Oracle Database in una macchina virtuale di Azure.
Preparare l'ambiente
Per preparare l'ambiente, completare questi passaggi:
Connettersi alla macchina virtuale
Per creare una sessione Secure Shell, SSH con la macchina virtuale, usare il comando seguente. Sostituire
<publicIpAddress>con il valore dell'indirizzo pubblico per la macchina virtuale.ssh azureuser@<publicIpAddress>Passare all'utente radice:
sudo su -Aggiungere l'utente
oracleal file /etc/sudoers:echo "oracle ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
Configurare l'archiviazione di File di Azure per i file di log di rollforward archiviati in Oracle
I file di log di rollforward archiviati dell'istanza di Oracle Database svolgono un ruolo fondamentale nel recupero del database. Archiviano le transazioni di cui è stato eseguito il commit necessarie per eseguire il roll forward da uno snapshot del database acquisito in passato.
Quando il database è in modalità ARCHIVELOG, archivia il contenuto dei file di log di rollforward online quando sono pieni e cambiano. Insieme a un backup, sono necessari per ottenere un ripristino temporizzato quando il database viene perso.
Oracle offre la possibilità di archiviare i file di log di rollforward in posizioni diverse. La procedura consigliata del settore prevede che almeno una di queste destinazioni si trovi nell'archiviazione remota, quindi sia separata dall'archiviazione host e protetta con snapshot indipendenti. File di Azure soddisfa questi requisiti.
Una condivisione file di Azure è una risorsa di archiviazione che è possibile collegare a una macchina virtuale Linux o Windows come componente normale del file system, usando il protocollo SMB (Server Message Block) o NFS (Network File System). Per configurare una condivisione file di Azure in Linux (usando il protocollo SMB 3.0) da usare come risorsa di archiviazione dei log di archiviazione, vedere Montare una condivisione file di Azure SMB in Linux. Al termine dell'installazione, tornare a questa guida e completare tutti i passaggi rimanenti.
Preparare i database
Questa parte del processo presuppone che sia stata seguita la procedura per Creare un'istanza di Oracle Database in una macchina virtuale di Azure. Di conseguenza:
- Si dispone di un'istanza di Oracle denominata
oratest1in esecuzione in una macchina virtuale denominatavmoracle19c. - Si usa lo script di Oracle standard
oraenvcon la relativa dipendenza nel file di configurazione di Oracle standard /etc/oratab per configurare le variabili di ambiente in una sessione della shell.
Seguire questa procedura per ogni database nella macchina virtuale:
Passare all'utente
oracle:sudo su - oracleImpostare la variabile di ambiente
ORACLE_SIDeseguendo lo scriptoraenv. Richiede di immettere ilORACLE_SIDnome.. oraenvAggiungere la condivisione file di Azure come altra destinazione per i file di log di archiviazione del database.
Questo passaggio presuppone che nella macchina virtuale Linux sia stata configurata e montata una condivisione file di Azure. Per ogni database installato nella macchina virtuale, creare una sottodirectory denominata in base all'identificatore di sicurezza del database (SID).
In questo esempio il nome del punto di montaggio è
/backupe il SID èoratest1. Si crea quindi la sottodirectory/backup/oratest1e si modifica la proprietà impostando l'utenteoracle. Sostituire/backup/SIDper il nome del punto di montaggio e il SID del database.sudo mkdir /backup/oratest1 sudo chown oracle:oinstall /backup/oratest1Stabilire la connessione al database:
sqlplus / as sysdbaAvviare il database se non è già in esecuzione:
SQL> startupImpostare la prima destinazione del log di archiviazione del database sulla directory della condivisione file creata in precedenza:
SQL> alter system set log_archive_dest_1='LOCATION=/backup/oratest1' scope=both;Definire l'obiettivo del punto di ripristino (RPO) per il database.
Per ottenere un RPO coerente, prendere in considerazione la frequenza con cui i file di log di rollforward online vengono archiviati. Questi fattori controllano la frequenza:
- Dimensioni dei file di log di rollforward online. Quando un file di log online diventa pieno, viene cambiato e archiviato. Più grande è il file di log online, più tempo è necessario per riempirlo. Il tempo aggiunto riduce la frequenza di generazione dell'archivio.
- L'impostazione del parametro
ARCHIVE_LAG_TARGETcontrolla il numero massimo di secondi consentiti prima che il file di log online corrente debba essere cambiato e archiviato.
Per ridurre al minimo la frequenza di cambio e archiviazione, insieme all'operazione di checkpoint associata, i file di log di rollforward online di Oracle hanno in genere grandi dimensioni (ad esempio, 1.024M, 4.096M o 8.192M). In un ambiente di database occupato, è probabile che i log vengano cambiati e archiviati a distanza di pochi secondi o minuti. In un database meno attivo, potrebbero passare ore o giorni prima che le transazioni più recenti vengano archiviate, riducendo notevolmente la frequenza di archiviazione.
È consigliabile impostare
ARCHIVE_LAG_TARGETper garantire un RPO coerente. Un'impostazione di 5 minuti (300 secondi) è un valore opportuno perARCHIVE_LAG_TARGET. Garantisce che qualsiasi operazione di recupero del database possa essere eseguire il recupero entro 5 minuti dal momento dell'errore.Per impostare
ARCHIVE_LAG_TARGET, eseguire questo comando:SQL> alter system set archive_lag_target=300 scope=both;Per comprendere meglio come distribuire le istanze di Oracle Database a disponibilità elevata in Azure con un RPO pari a zero, vedere Architetture di riferimento per Oracle Database.
Assicurarsi che il database sia in modalità di log di archiviazione per abilitare i backup online.
Controllare prima lo stato di archiviazione dei log:
SQL> SELECT log_mode FROM v$database; LOG_MODE ------------ NOARCHIVELOGSe è in modalità
NOARCHIVELOG, eseguire i comandi seguenti:SQL> SHUTDOWN IMMEDIATE; SQL> STARTUP MOUNT; SQL> ALTER DATABASE ARCHIVELOG; SQL> ALTER DATABASE OPEN; SQL> ALTER SYSTEM SWITCH LOGFILE;Creare una tabella per testare le operazioni di backup e recupero:
SQL> create user scott identified by tiger quota 100M on users; SQL> grant create session, create table to scott; SQL> connect scott/tiger SQL> create table scott_table(col1 number, col2 varchar2(50)); SQL> insert into scott_table VALUES(1,'Line 1'); SQL> commit; SQL> quit
Eseguire il backup dei dati usando Backup di Azure
Il servizio Backup di Azure offre soluzioni per eseguire il backup dei dati e recuperarli dal cloud di Microsoft Azure. Backup di Azure fornisce backup indipendenti e isolati per salvaguardare dalla distruzione accidentale dei dati originali. I backup vengono archiviati in un insieme di credenziali di Servizi di ripristino con la gestione predefinita dei punti di recupero, così da poter eseguire il recupero in base alle necessità.
In questa sezione si usa Backup di Azure per acquisire snapshot coerenti con l'applicazione delle istanze in esecuzione della macchina virtuale e di Oracle Database. I database vengono inseriti in modalità di backup, consentendo così l'esecuzione di un backup online coerente in modo transazionale mentre Backup di Azure acquisisce uno snapshot dei dischi della macchina virtuale. Lo snapshot è una copia completa della risorsa di archiviazione e non uno snapshot incrementale o copy-on-write. È un mezzo efficace per ripristinare il database.
Il vantaggio di usare snapshot coerenti con l'applicazione di Backup di Azure è che vengono acquisiti rapidamente, indipendentemente dalle dimensioni del database. È possibile usare uno snapshot per le operazioni di recupero subito dopo averlo acquisito, senza dover attendere che venga trasferito nell'insieme di credenziali di Servizi di ripristino.
Per usare Backup di Azure per eseguire il backup del database, completare questa procedura:
- Informarsi sul framework di Backup di Azure.
- Preparare l'ambiente per un backup coerente con l'applicazione.
- Configurare backup coerenti con l'applicazione.
- Attivare un backup coerente con l'applicazione della macchina virtuale.
Informarsi sul framework di Backup di Azure
Il servizio Backup di Azure offre un framework per ottenere coerenza con l'applicazione durante i backup delle macchine virtuali Windows e Linux per varie applicazioni. Questo framework comporta la chiamata di un codice per disattivare le applicazioni prima di creare uno snapshot dei dischi. Chiama un postscript per sbloccare le applicazioni dopo il completamento dello snapshot.
Microsoft ha migliorato il framework in modo che il servizio Backup di Azure fornisca prescript e postscript in pacchetto per le applicazioni selezionate. Questi prescript e postscript sono già caricati nell'immagine Linux, quindi non c'è nulla da installare. È sufficiente assegnare un nome all'applicazione e successivamente Backup di Azure richiama automaticamente gli script pertinenti. Microsoft gestisce i prescritti e i postscript in pacchetto, in modo da poter essere certi del supporto, della proprietà e della validità di essi.
Attualmente, le applicazioni supportate per il framework avanzato sono Oracle 12.x o una versione successiva e MySQL. Per informazioni dettagliate, vedere Matrice di supporto per i backup della macchina virtuale di Azure gestita.
È possibile creare script personalizzati per Backup di Azure da usare con i database pre-12.x. Script di esempio sono disponibili in GitHub.
Ogni volta che si esegue un backup, il framework avanzato esegue i prescript e i postscript in tutte le istanze di Oracle Database installate nella macchina virtuale. Il parametro configuration_path nel file workload.conf punta al percorso del file /etc/oratab di Oracle (o a un file definito dall'utente che segue la sintassi oratab). Per informazioni dettagliate, vedere Configurare backup coerenti con l'applicazione.
Backup di Azure esegue i prescritti e i postscript per ogni database elencato nel file a cui configuration_path punta. Le eccezioni sono righe che iniziano con # (considerate come commento) o +ASM (un'istanza di Oracle ASM).
Il framework avanzato di Backup di Azure esegue backup online di istanze di Oracle Database che operano in modalità ARCHIVELOG. I prescript e i postscript usano i ALTER DATABASE BEGIN comandi e END BACKUP per ottenere la coerenza dell'applicazione.
Affinché il backup del database sia coerente, i database in modalità NOARCHIVELOG devono essere arrestati del tutto prima dell'avvio dello snapshot.
Preparare l'ambiente per un backup coerente con l'applicazione
Oracle Database usa la separazione dei ruoli di un processo per garantire la separazione dei compiti usando i privilegi minimi. Associa gruppi separati del sistema operativo a ruoli separati amministrativi del database. Agli utenti possono quindi essere concessi privilegi del database diversi, a seconda dell'appartenenza ai gruppi del sistema operativo.
Il ruolo del database SYSBACKUP (nome generico OSBACKUPDBA) fornisce privilegi limitati per eseguire operazioni di backup nel database. Backup di Azure lo richiede.
Durante l'installazione di Oracle, è consigliabile usare backupdba come nome del gruppo del sistema operativo da associare al ruolo SYSBACKUP. È tuttavia possibile usare qualsiasi nome, quindi è necessario determinare prima il nome del gruppo del sistema operativo che rappresenta il ruolo SYSBACKUP di Oracle.
Passare all'utente
oracle:sudo su - oracleImpostare l'ambiente Oracle:
export ORACLE_SID=oratest1 export ORAENV_ASK=NO . oraenvDeterminare il nome del gruppo del sistema operativo che rappresenta il ruolo
SYSBACKUPdi Oracle:grep "define SS_BKP" $ORACLE_HOME/rdbms/lib/config.cL'output è simile al seguente esempio:
#define SS_BKP_GRP "backupdba"Nell'output il valore racchiuso tra virgolette doppie è il nome del gruppo del sistema operativo Linux in cui viene autenticato esternamente il ruolo
SYSBACKUPOracle. In questo esempio èbackupdba. Annotare il valore effettivo.Verificare che il gruppo del sistema operativo esista eseguendo il comando seguente. Sostituire
<group name>con il valore restituito dal comando precedente (senza virgolette).grep <group name> /etc/groupL'output è simile al seguente esempio:
backupdba:x:54324:oracleImportante
Se l'output non corrisponde al valore del gruppo del sistema operativo Oracle recuperato nel passaggio 3, usare il comando seguente per creare il gruppo del sistema operativo che rappresenta il ruolo
SYSBACKUPdi Oracle. Sostituire<group name>con il nome del gruppo recuperato nel passaggio 3.sudo groupadd <group name>Creare un nuovo utente di backup denominato
azbackupappartenente al gruppo del sistema operativo verificato o creato nei passaggi precedenti. Sostituire<group name>con il nome del gruppo verificato. L'utente viene aggiunto anche al gruppooinstallper consentire l'apertura dei dischi ASM.sudo useradd -g <group name> -G oinstall azbackupConfigurare l'autenticazione esterna per il nuovo utente del backup.
L'utente di backup
azbackupdeve essere in grado di accedere al database usando l'autenticazione esterna, quindi non viene richiesta una password. Per abilitare l'accesso, è necessario creare un utente del database che esegua l'autenticazione esternamente tramiteazbackup. Il database usa un prefisso per il nome utente, che è necessario trovare.Seguire questa procedura per ogni database installato nella macchina virtuale:
Accedere al database usando SQL Plus e controllare le impostazioni predefinite per l'autenticazione esterna:
sqlplus / as sysdba SQL> show parameter os_authent_prefix SQL> show parameter remote_os_authentL'output dovrebbe essere simile a questo esempio, che mostra
ops$come prefisso del nome utente del database:NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ os_authent_prefix string ops$ remote_os_authent boolean FALSECreare un utente del database denominato
ops$azbackupper l'autenticazione esterna dell'utenteazbackupe concedere i privilegiSYSBACKUP:SQL> CREATE USER ops$azbackup IDENTIFIED EXTERNALLY; SQL> GRANT CREATE SESSION, ALTER SESSION, SYSBACKUP TO ops$azbackup;
Se viene visualizzato l'errore
ORA-46953: The password file is not in the 12.2 formatquando si esegue l'istruzioneGRANT, seguire questa procedura per eseguire la migrazione del file orapwd al formato 12.2. Eseguire questi passaggi per ogni istanza di Oracle Database nella macchina virtuale.Uscire da SQL Plus.
Spostare il file di password con il formato precedente in un nuovo nome.
Eseguire la migrazione del file di password.
Rimuovere il file precedente.
Eseguire i comandi seguenti:
mv $ORACLE_HOME/dbs/orapworatest1 $ORACLE_HOME/dbs/orapworatest1.tmp orapwd file=$ORACLE_HOME/dbs/orapworatest1 input_file=$ORACLE_HOME/dbs/orapworatest1.tmp rm $ORACLE_HOME/dbs/orapworatest1.tmpEseguire di nuovo l'operazione
GRANTin SQL Plus.
Creare una stored procedure per registrare i messaggi di backup nel log degli avvisi del database. Usare il codice seguente per ogni database installato nella macchina virtuale:
sqlplus / as sysdba SQL> GRANT EXECUTE ON DBMS_SYSTEM TO SYSBACKUP; SQL> CREATE PROCEDURE sysbackup.azmessage(in_msg IN VARCHAR2) AS v_timestamp VARCHAR2(32); BEGIN SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS') INTO v_timestamp FROM DUAL; DBMS_OUTPUT.PUT_LINE(v_timestamp || ' - ' || in_msg); SYS.DBMS_SYSTEM.KSDWRT(SYS.DBMS_SYSTEM.ALERT_FILE, in_msg); END azmessage; / SQL> SHOW ERRORS SQL> QUIT
Configurare backup coerenti con l'applicazione
Passare all'utente radice:
sudo su -Verificare che la cartella /etc/azure sia presente. Se non lo è, creare la directory di lavoro per il backup coerente con l'applicazione:
if [ ! -d "/etc/azure" ]; then mkdir /etc/azure fiCercare il file workload.conf all'interno della cartella. Se non è presente, crearlo nella directory /etc/azure e assegnargli il contenuto seguente. I commenti devono iniziare con
[workload]. Se il file è già presente, è sufficiente modificare i campi in modo che corrispondano al contenuto seguente. In caso contrario, il comando seguente crea il file e popola il contenuto:echo "[workload] workload_name = oracle configuration_path = /etc/oratab timeout = 90 linux_user = azbackup" > /etc/azure/workload.confIl file workload.conf usa il formato seguente:
- Il parametro
workload_nameindica il tipo di carico di lavoro del database. In questo caso, l'impostazione del parametro suOracleconsente di Backup di Azure di eseguire i prescript e i postscript corretti (comandi di coerenza) per le istanze di Oracle Database. - Il parametro
timeoutindica il tempo massimo, in secondi, in cui ogni database deve completare gli snapshot di archiviazione. - Il parametro
linux_userindica l'account utente Linux usato da Backup di Azure per eseguire operazioni di disattivazione del database. In precedenza è stato creato l'utenteazbackup. - Il parametro
configuration_pathindica il nome del percorso assoluto per un file di testo nella macchina virtuale. Ogni riga elenca un'istanza di database in esecuzione nella macchina virtuale. Si tratta in genere del file /etc/oratab generato da Oracle durante l'installazione del database, ma può essere qualsiasi file con qualsiasi nome scelto. Deve seguire queste regole di formato:- Il file è un file di testo. Ogni campo è delimitato dal carattere due punti (
:). - Il primo campo in ogni riga è il nome di un'istanza di
ORACLE_SID. - Il secondo campo in ogni riga è il nome del percorso assoluto per
ORACLE_HOMEper l'istanzaORACLE_SID. - Tutto il testo dopo i primi due campi viene ignorato.
- Se la riga inizia con un segno cancelletto (
#), l'intera riga viene ignorata come commento. - Se il primo campo ha il valore
+ASM, denotando un'istanza di Oracle ASM, viene ignorato.
- Il file è un file di testo. Ogni campo è delimitato dal carattere due punti (
- Il parametro
Attivare un backup coerente con l'applicazione della macchina virtuale
Nel portale di Azure passare al gruppo di risorse rg-oracle e selezionare la macchina virtuale vmoracle19c.
Nel riquadro Backup:
- In Insieme di credenziali di Servizi di ripristino selezionare Crea nuovo.
- Per il nome dell'insieme di credenziali, usare myVault.
- Per Gruppo di risorse selezionare rg-oracle.
- Per Scegliere i criteri di backup, usare (nuovo) DailyPolicy. Per modificare la frequenza di backup o il periodo di conservazione, selezionare invece Crea un nuovo criterio.
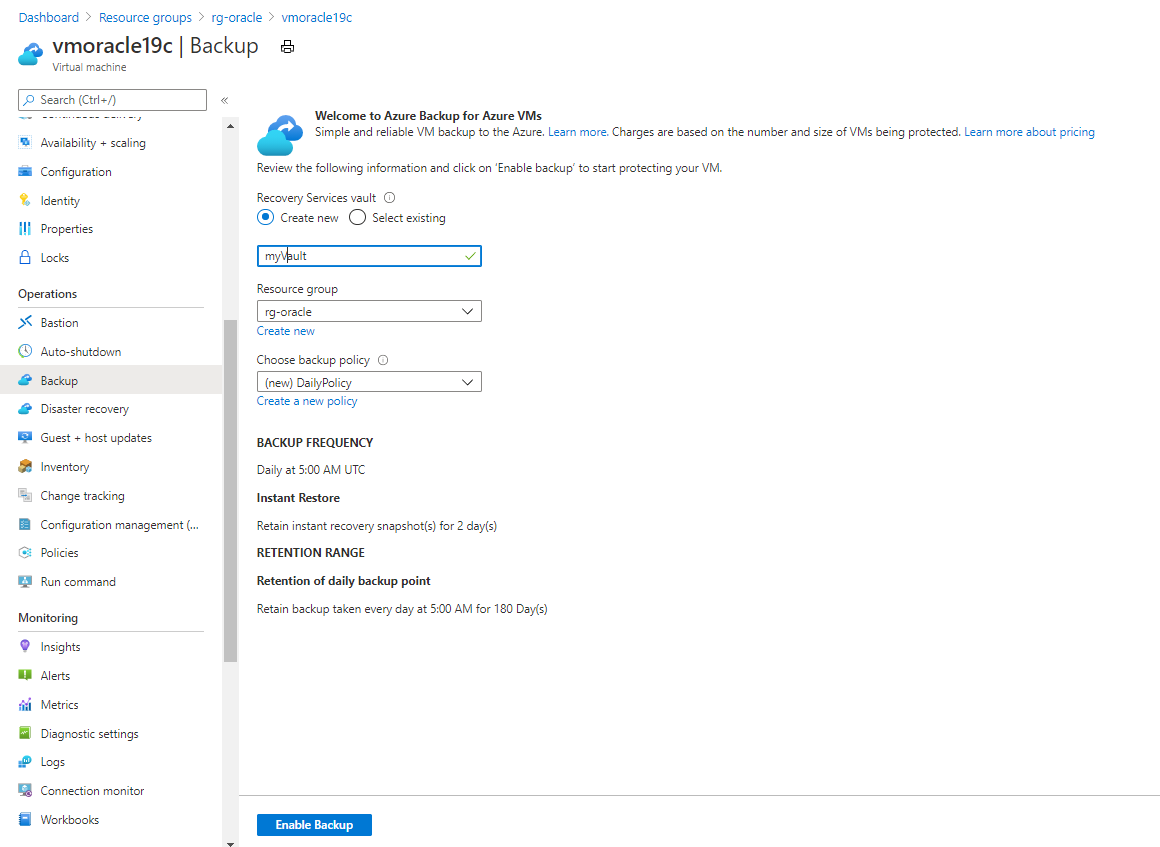 Screenshot che mostra il riquadro per la configurazione di un nuovo insieme di credenziali di Servizi di ripristino.
Screenshot che mostra il riquadro per la configurazione di un nuovo insieme di credenziali di Servizi di ripristino.Selezionare Abilita backup.
Il processo di backup non viene avviato fino alla scadenza dell'ora pianificata. Per configurare un backup immediato, completare il passaggio successivo.
Nel riquadro gruppo di risorse selezionare l'insieme di credenziali di Servizi di ripristino appena creato denominato myVault. Potrebbe essere necessario aggiornare la pagina per visualizzarlo.
Nel pannello myVault - Elementi di backup in NUMERO DI ELEMENTI DI BACKUP selezionare il numero di elementi di backup.
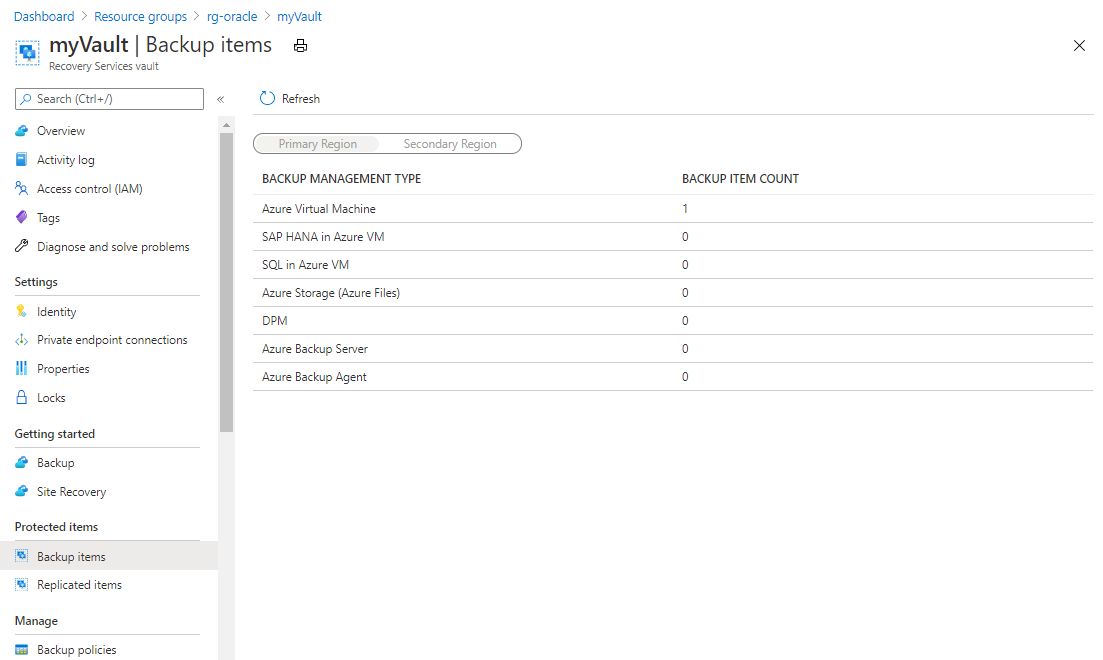 Screenshot che mostra i dettagli per un insieme di credenziali di Servizi di ripristino.
Screenshot che mostra i dettagli per un insieme di credenziali di Servizi di ripristino.Nel riquadro Elementi di backup (Macchina virtuale di Azure) selezionare il pulsante con i puntini di sospensione (...) e quindi selezionare Esegui backup ora.
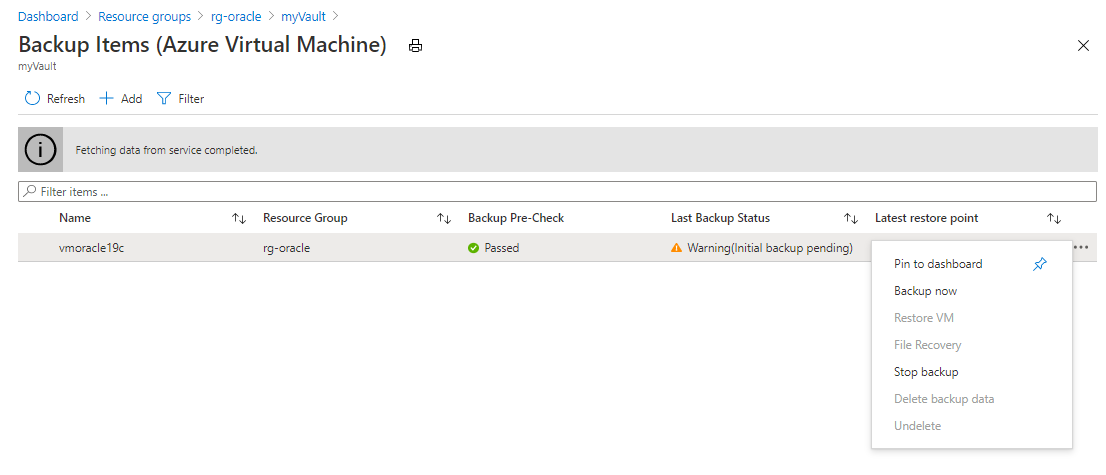 Screenshot che mostra il comando per il backup degli insiemi di credenziali di Servizi di ripristino ora.
Screenshot che mostra il comando per il backup degli insiemi di credenziali di Servizi di ripristino ora.Accettare il valore predefinito di Conserva backup fino a e quindi selezionare OK. Attendere il completamento del processo di backup.
Per visualizzare lo stato del processo di backup, selezionare Processi di backup.
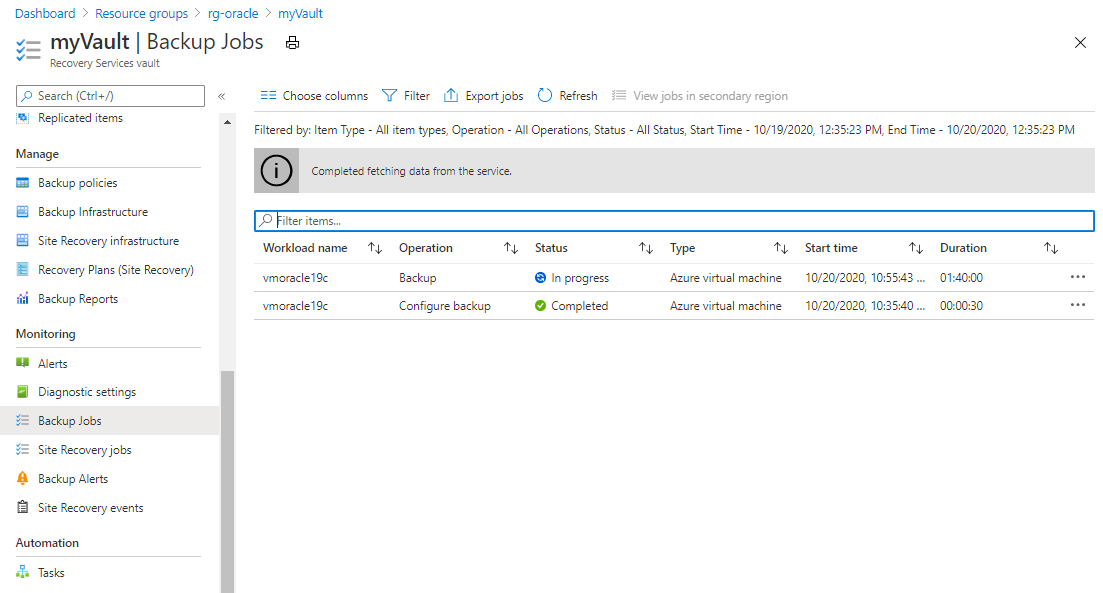 Screenshot che mostra il riquadro in cui sono elencati i processi di backup per un insieme di credenziali di Servizi di ripristino.
Screenshot che mostra il riquadro in cui sono elencati i processi di backup per un insieme di credenziali di Servizi di ripristino.Selezionare il processo di backup per visualizzare i relativi dettagli sullo stato.
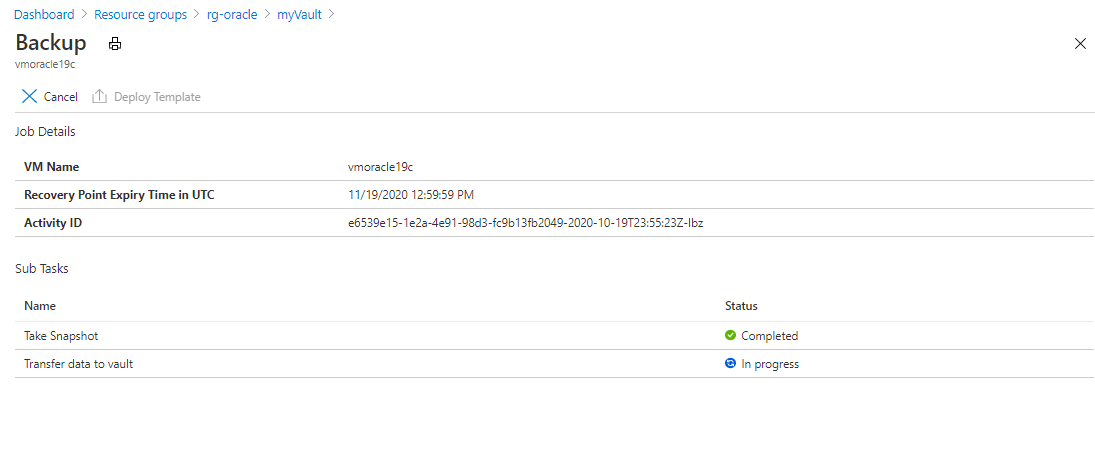 Screenshot che mostra informazioni dettagliate sullo stato per un processo di backup.
Screenshot che mostra informazioni dettagliate sullo stato per un processo di backup.Anche se sono necessari alcuni secondi per eseguire lo snapshot, può richiedere più tempo per trasferirlo nell'insieme di credenziali. Il processo di backup non viene completato fino al termine del trasferimento.
Per un backup coerente con l'applicazione, risolvere eventuali errori nel file di log in /var/log/azure/Microsoft.Azure.RecoveryServices.VMSnapshotLinux/extension.log.
Ripristinare la macchina virtuale
Il ripristino di un'intera macchina virtuale implica il ripristino della macchina virtuale e dei relativi dischi collegati a una nuova macchina virtuale da un punto di ripristino selezionato. Questa azione ripristina anche tutti i database eseguiti nella macchina virtuale. Successivamente, è necessario recuperare ciascun database.
Per ripristinare un'intera macchina virtuale, completare questa procedura:
- Arrestare ed eliminare la macchina virtuale.
- Recuperare la macchina virtuale.
- Impostare l'indirizzo IP pubblico.
- Recuperare il database.
Quando si esegue il ripristino di una macchina virtuale sono disponibili due opzioni principali:
- Ripristinare la macchina virtuale da cui sono stati originariamente eseguiti i backup.
- Ripristinare (clonare) una nuova macchina virtuale senza toccare la macchina virtuale da cui sono stati originariamente eseguiti i backup.
I primi passaggi di questo esercizio (arresto, eliminazione e recupero della macchina virtuale) simulano il primo caso d'uso.
Arrestare ed eliminare la macchina virtuale
Nel portale di Azure passare alla macchina virtuale vmoracle19c e quindi selezionare Arresta.
Quando la macchina virtuale non è più in esecuzione, selezionare Elimina e quindi Sì.
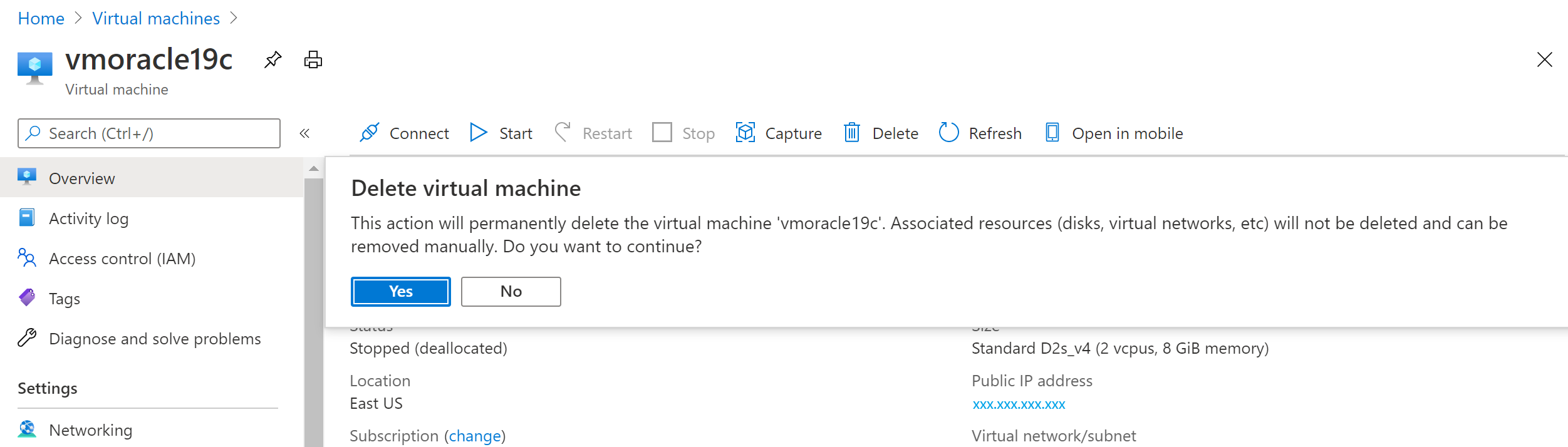 Screenshot che mostra il messaggio di conferma per l'eliminazione di una macchina virtuale.
Screenshot che mostra il messaggio di conferma per l'eliminazione di una macchina virtuale.
Recuperare la macchina virtuale
Creare un account di archiviazione per lo staging nel portale di Azure:
Nel portale di Azure, selezionare C+ rea una risorsa, quindi cercare e selezionare Account di archiviazione.
 Screenshot che mostra dove creare una risorsa.
Screenshot che mostra dove creare una risorsa.Nel riquadro Crea account di archiviazione:
- Per Gruppo di risorse, selezionare il gruppo di risorse esistente rg-oracle.
- Per Nome dell'account di archiviazione, immettere oracrestore.
- Assicurarsi che Posizione sia impostato sulla stessa area di tutte le altre risorse nel gruppo di risorse.
- Impostare Prestazioni su Standard.
- Per Tipologia account selezionare ArchiviazioneV2 (per utilizzo generico StorageV2).
- Per Replica selezionare Archiviazione con ridondanza locale.
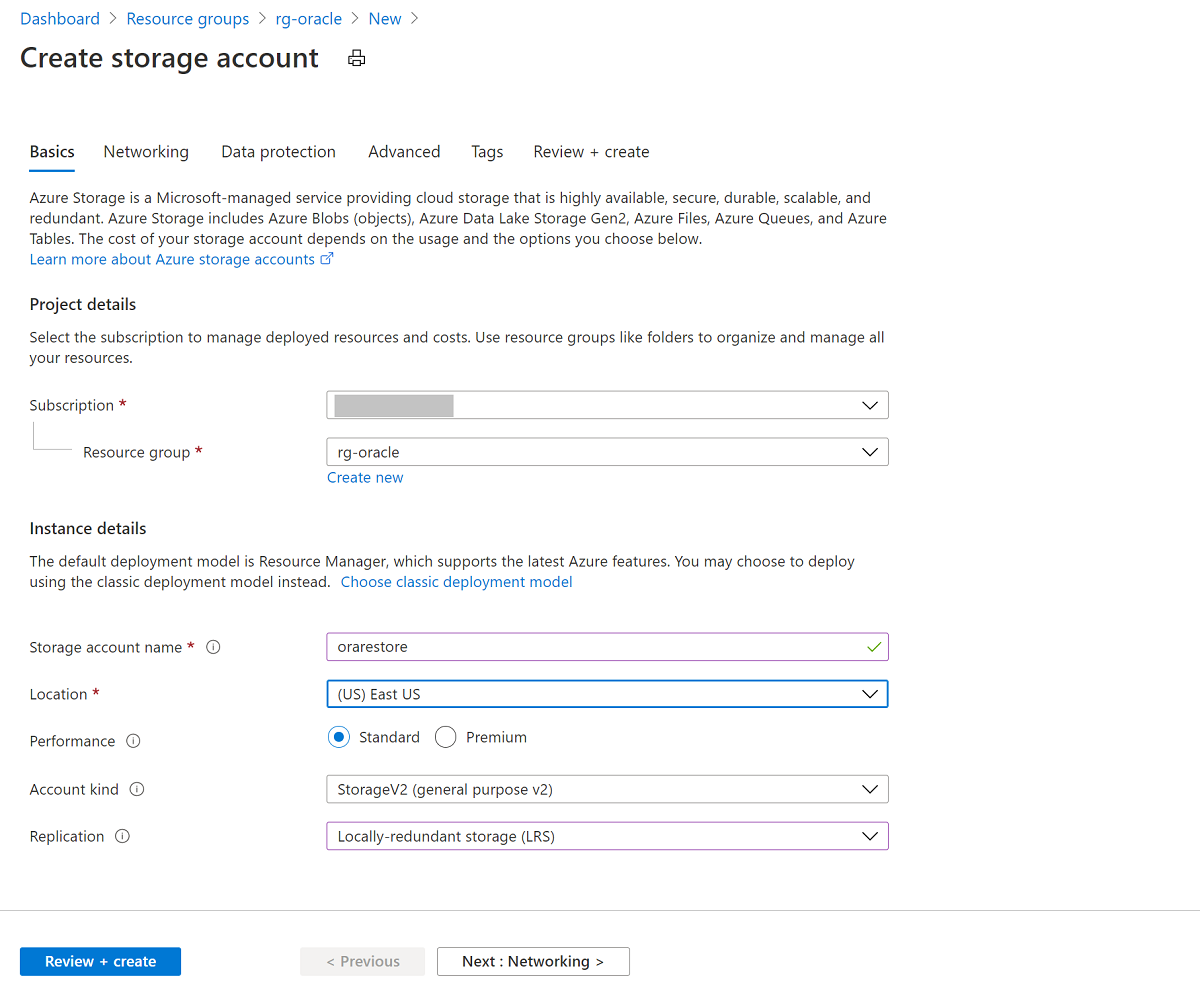 Screenshot che mostra le informazioni di base per la creazione di un account di archiviazione.
Screenshot che mostra le informazioni di base per la creazione di un account di archiviazione.Selezionare Rivedi e crea e quindi Crea.
Nel portale di Azure e cercare l'insieme di credenziali di Servizi di ripristino myVault e selezionarlo.
 Screenshot che mostra la selezione di un insieme di credenziali di Servizi di ripristino.
Screenshot che mostra la selezione di un insieme di credenziali di Servizi di ripristino.Nel riquadro Panoramica selezionare Elementi di backup. Selezionare quindi Macchina virtuale di Azure, che deve avere un valore diverso da zero per NUMERO DI ELEMENTI DI BACKUP.
 Screenshot che mostra le selezioni per un elemento di backup della macchina virtuale per un insieme di credenziali di Servizi di ripristino.
Screenshot che mostra le selezioni per un elemento di backup della macchina virtuale per un insieme di credenziali di Servizi di ripristino.Nel riquadro Elementi di backup (Macchina virtuale di Azure) selezionare la macchina virtuale vmoracle19c.
 Screenshot che mostra il riquadro per gli elementi di backup della macchina virtuale.
Screenshot che mostra il riquadro per gli elementi di backup della macchina virtuale.Nel riquadro vmoracle19c scegliere un punto di ripristino con un tipo di coerenza Coerenza applicazione. Selezionare i puntini di sospensione (...) e quindi selezionare Ripristina macchina virtuale.
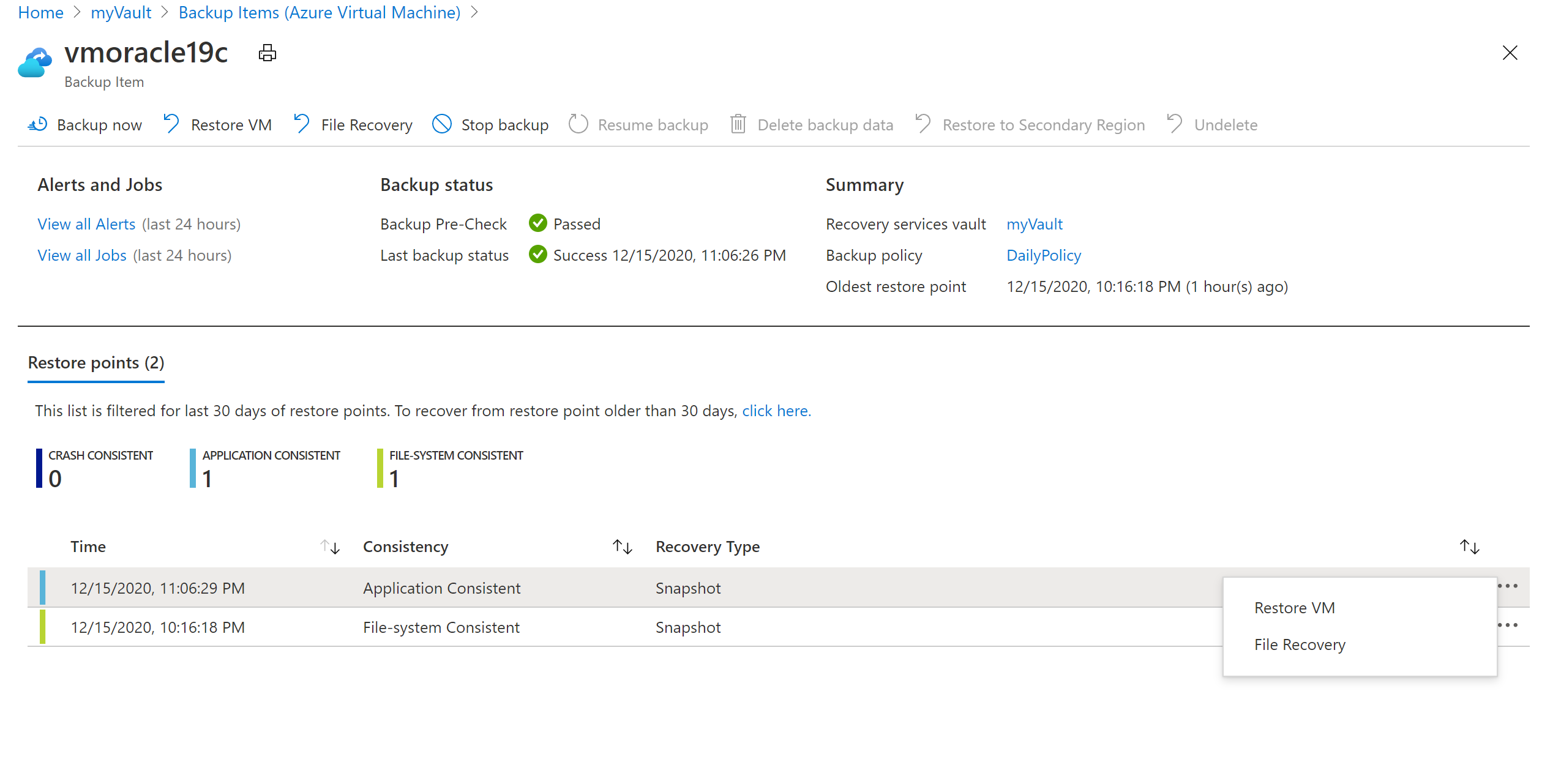 Screenshot che mostra il comando per il ripristino di una macchina virtuale.
Screenshot che mostra il comando per il ripristino di una macchina virtuale.Nel riquadro Ripristina macchina virtuale:
Selezionare Crea nuovo.
Per Tipo di ripristino selezionare Crea nuova macchina virtuale.
Per Nome macchina virtuale immettere vmoracle19c.
Per Rete virtuale selezionare vmoracle19cVNET.
La subnet viene popolata automaticamente in base alla selezione per la rete virtuale.
Per Percorso di gestione temporanea, il processo di ripristino di una macchina virtuale richiede un account di archiviazione di Azure nello stesso gruppo di risorse e nella stessa area. È possibile scegliere un account di archiviazione o un'attività di ripristino configurata in precedenza.
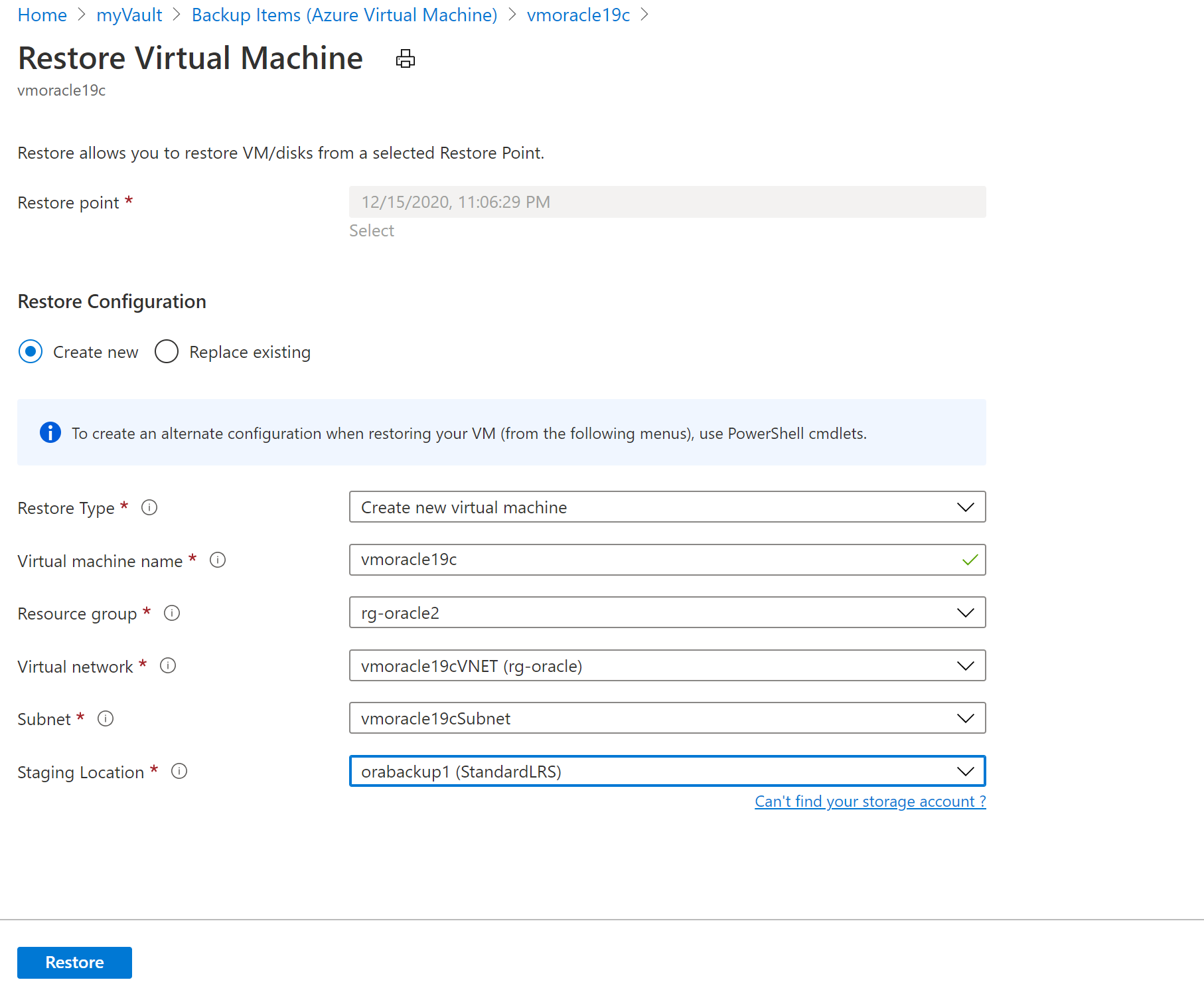 Screenshot che mostra i valori per il ripristino di una macchina virtuale.
Screenshot che mostra i valori per il ripristino di una macchina virtuale.Per ripristinare la macchina virtuale, selezionare il pulsante Ripristina.
Per visualizzare lo stato del processo di ripristino, fare clic su Processi e quindi selezionare Processi di backup.
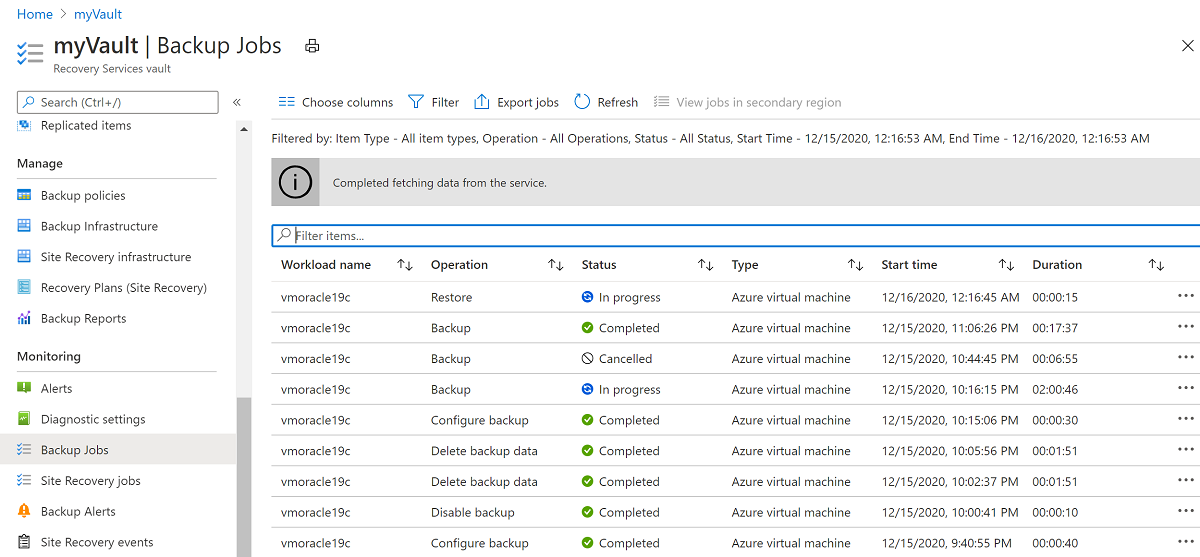 Screenshot che mostra un elenco di processi di backup.
Screenshot che mostra un elenco di processi di backup.Selezionare l'operazione di ripristino in corso per visualizzare i dettagli sullo stato del processo di ripristino.
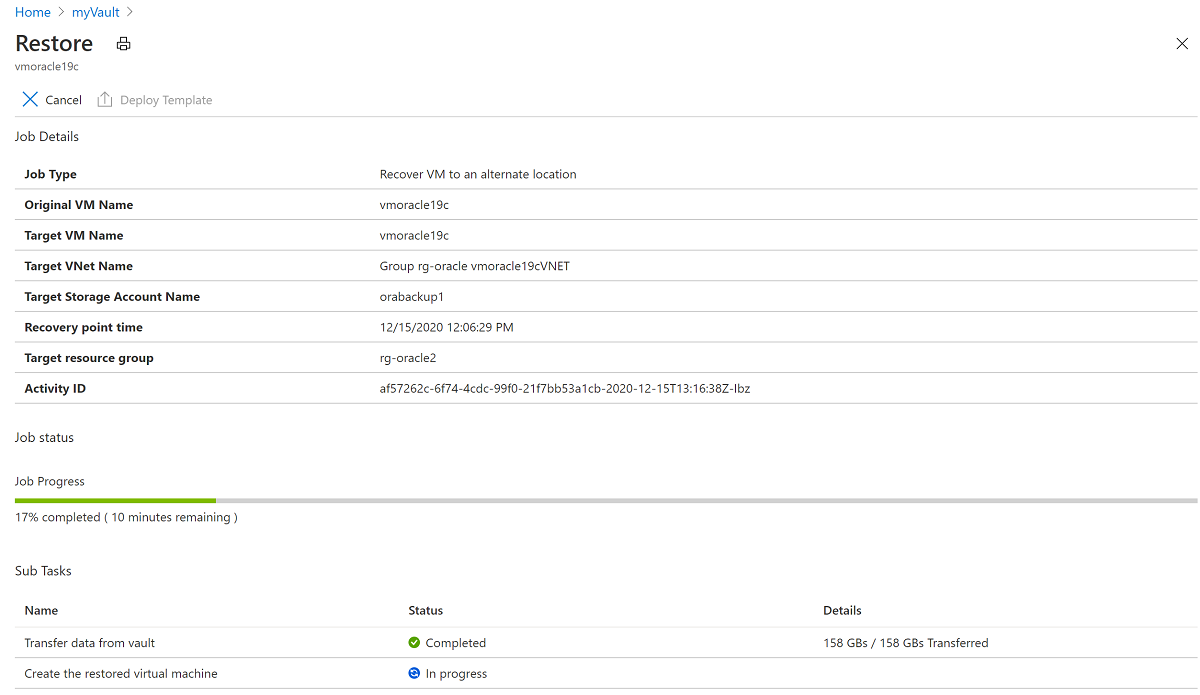 Screenshot che mostra informazioni dettagliate sullo stato di un processo di ripristino.
Screenshot che mostra informazioni dettagliate sullo stato di un processo di ripristino.
Impostare l'indirizzo IP pubblico
Dopo il ripristino della macchina virtuale, è necessario riassegnare l'indirizzo IP originale alla nuova macchina virtuale.
Nel portale di Azure passare alla macchina virtuale denominata vmoracle19c. Viene assegnato un nuovo indirizzo IP pubblico e una scheda di interfaccia di rete simile a vmoracle19c-nic-XXXXXXXXXXXX, ma non ha un indirizzo DNS. Quando la macchina virtuale originale è stata eliminata, sono stati conservati l'indirizzo IP pubblico e la scheda di interfaccia di rete. I passaggi successivi consentono di ricollegarli alla nuova macchina virtuale.
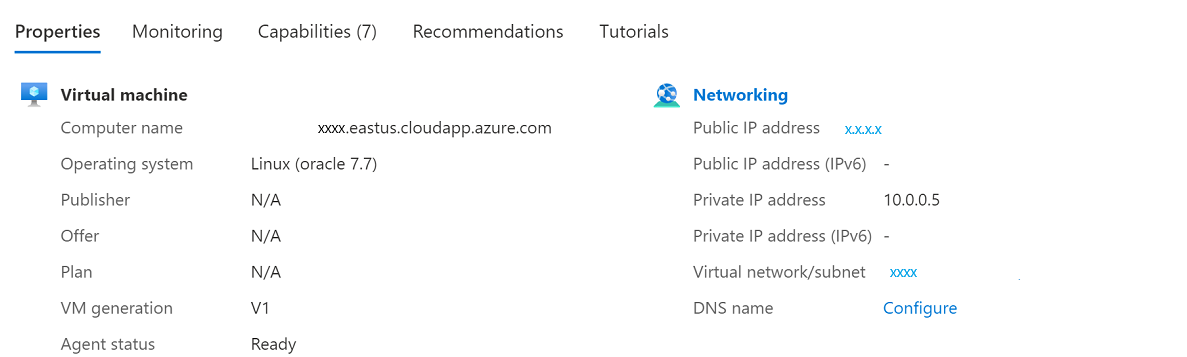 Screenshot che mostra un elenco di indirizzi IP pubblici.
Screenshot che mostra un elenco di indirizzi IP pubblici.Arrestare la VM.
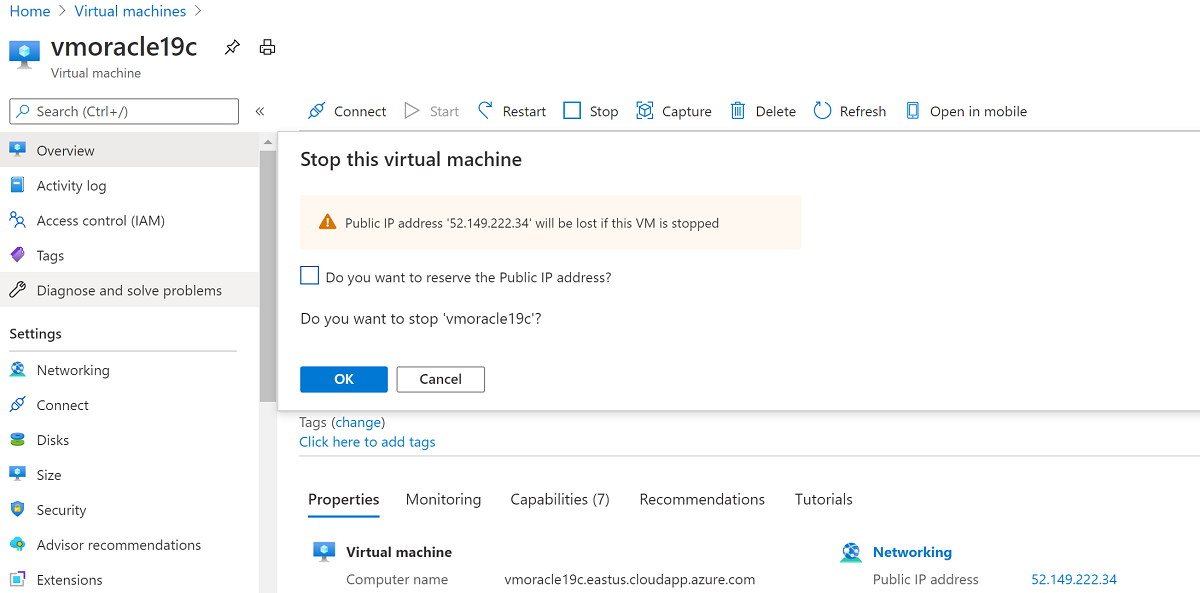 Screenshot che mostra le selezioni per l'arresto di una macchina virtuale.
Screenshot che mostra le selezioni per l'arresto di una macchina virtuale.Passare a Rete.
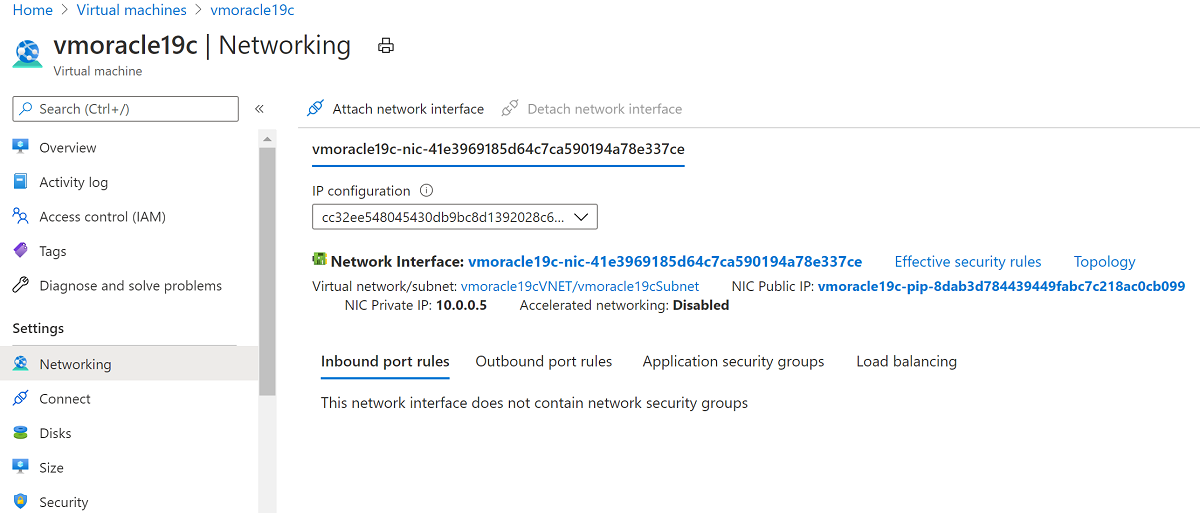 Screenshot che mostra le informazioni di rete.
Screenshot che mostra le informazioni di rete.Selezionare Collega interfaccia di rete. Selezionare la scheda di interfaccia di rete originale vmoracle19cVMNic, a cui l'indirizzo IP pubblico originale è ancora associato. Selezionare OK.
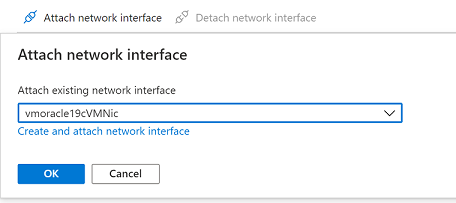 Screenshot che mostra la selezione dei valori del tipo di risorsa e della scheda di interfaccia di rete.
Screenshot che mostra la selezione dei valori del tipo di risorsa e della scheda di interfaccia di rete.Scollegare la scheda di interfaccia di rete creata con l'operazione di ripristino della macchina virtuale, perché è configurata come interfaccia primaria. Selezionare Scollega interfaccia di rete, scegliere la scheda di interfaccia di rete simile a vmoracle19c-nic-XXXXXXXXXXXXXXXe quindi selezionare OK.
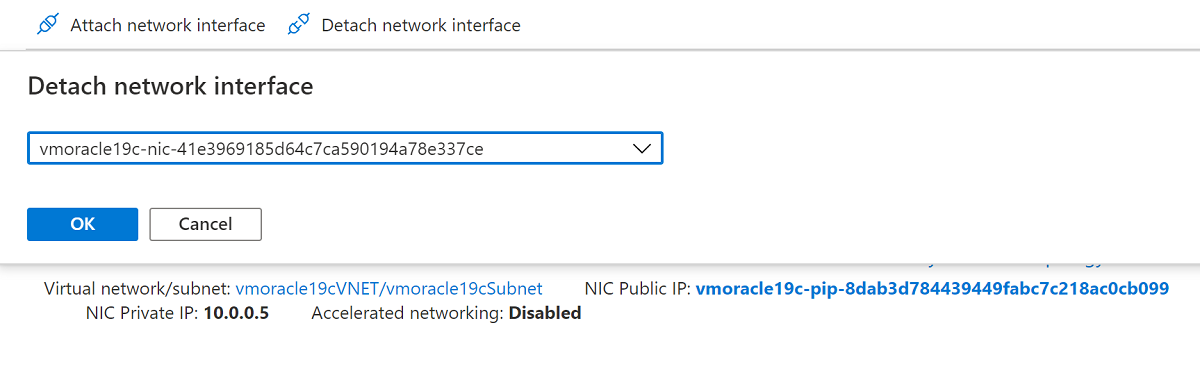 Screenshot che mostra il riquadro per scollegare un'interfaccia di rete.
Screenshot che mostra il riquadro per scollegare un'interfaccia di rete.La macchina virtuale ricreata ha ora la scheda di interfaccia di rete originale, associata alle regole originali dell'indirizzo IP e del gruppo di sicurezza di rete.
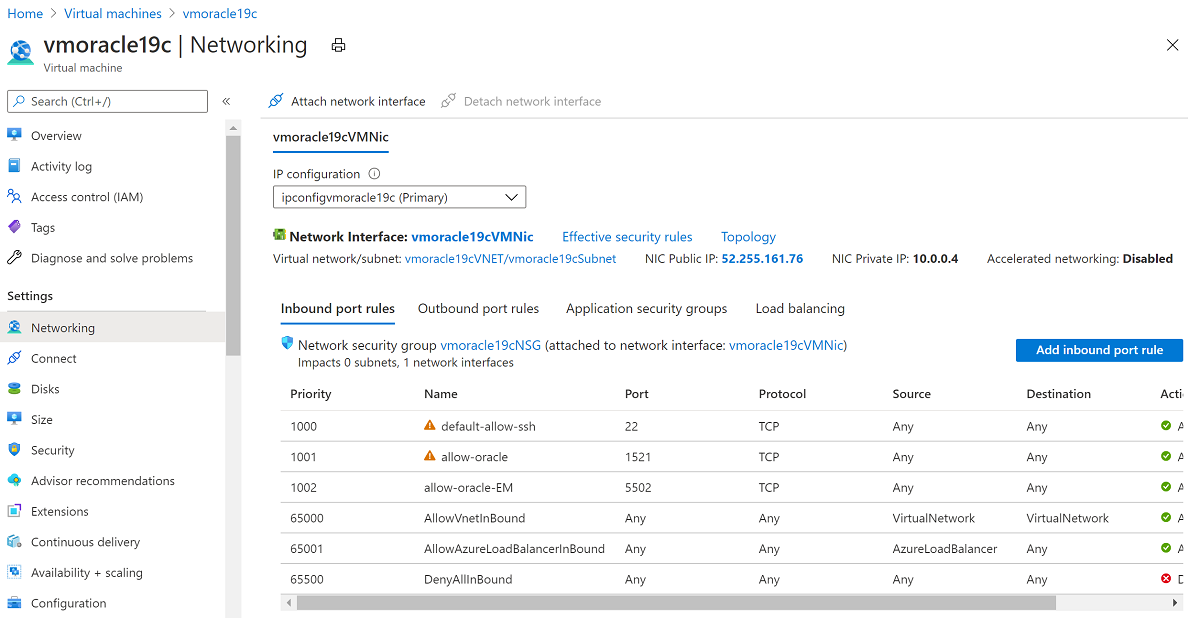 Screenshot che mostra un valore di indirizzo IP.
Screenshot che mostra un valore di indirizzo IP.Tornare al riquadro Panoramica e selezionare Avvia.
Ripristinare il database
Per recuperare un database dopo un ripristino completo della macchina virtuale:
Riconnettersi alla macchina virtuale:
ssh azureuser@<publicIpAddress>Quando l'intera macchina virtuale viene ripristinata, è importante ripristinare i database nella macchina virtuale eseguendo i passaggi seguenti in ogni database.
È possibile scoprire che l'istanza è in esecuzione, perché l'avvio automatico ha tentato di avviare il database all'avvio della macchina virtuale. Tuttavia, il database richiede il ripristino e probabilmente si trova esclusivamente nella fase di montaggio. Eseguire un arresto preparatorio prima di avviare la fase di montaggio:
sudo su - oracle sqlplus / as sysdba SQL> shutdown immediate SQL> startup mountEseguire il recupero del database.
È importante specificare la sintassi per informare il
USING BACKUP CONTROLFILEcomando che ilRECOVER AUTOMATIC DATABASEripristino non deve arrestarsi in corrispondenza del numero di modifica del sistema Oracle (SCN) registrato nel file di controllo del database ripristinato.Il file di controllo del database ripristinato era uno snapshot, insieme al resto del database. L'SCN archiviato al suo interno deriva dal punto nel tempo dello snapshot. Dopo questo punto potrebbero essere state registrare transazioni e si desidera eseguire il recupero nel punto dell'ultima transazione di cui è stato eseguito il commit nel database.
SQL> recover automatic database using backup controlfile until cancel;Quando viene applicato l'ultimo file di log di archivio disponibile, immettere
CANCELper terminare il ripristino.Al termine del recupero, viene visualizzato il messaggio
Media recovery complete.Tuttavia, quando si usa la clausola
BACKUP CONTROLFILE, il comando di recupero ignora i file di log online. È possibile che le modifiche nel log di rollforward online corrente siano necessarie per completare il recupero temporizzato. In questo caso, potrebbero essere visualizzati messaggi simili a questi esempi:SQL> recover automatic database until cancel using backup controlfile; ORA-00279: change 2172930 generated at 04/08/2021 12:27:06 needed for thread 1 ORA-00289: suggestion : /u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc ORA-00280: change 2172930 for thread 1 is in sequence #13 ORA-00278: log file '/u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc' no longer needed for this recovery ORA-00308: cannot open archived log '/u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc' ORA-27037: unable to obtain file status Linux-x86_64 Error: 2: No such file or directory Additional information: 7 Specify log: {<RET>=suggested | filename | AUTO | CANCEL}Importante
Se il log di rollforward online corrente viene perso o danneggiato e non è possibile usarlo, in questo punto è possibile annullare il recupero.
Per correggere questa situazione, è possibile identificare il log online non archiviato e fornire il nome completo del file quando richiesto.
Aprire il database.
L'opzione
RESETLOGSè necessaria quando il comandoRECOVERusa l'opzioneUSING BACKUP CONTROLFILE.RESETLOGScrea una nuova incarnazione del database reimpostando la cronologia all'inizio, perché non è possibile determinare la quantità di incarnazione del database precedente ignorata nel recupero.SQL> alter database open resetlogs;Verificare che il contenuto del database sia stato recuperato:
SQL> select * from scott.scott_table;
L'esecuzione di backup e recupero di Oracle Database su una macchina virtuale Linux di Azure è stata completata.
Per altre informazioni sui comandi e i concetti di Oracle, vedere la documentazione di Oracle, tra cui:
- Esecuzione di backup gestiti dall'utente Oracle dell'intero database
- Esecuzione di un recupero completo del database gestito dall'utente
- Comando STARTUP di Oracle
- Comando RECOVER di Oracle
- Comando ALTER DATABASE di Oracle
- Parametro LOG_ARCHIVE_DEST_n di Oracle
- Parametro ARCHIVE_LAG_TARGET di Oracle
Eliminare la macchina virtuale
Quando la macchina virtuale non è più necessaria, è possibile usare i comandi seguenti per rimuovere il gruppo di risorse, la macchina virtuale e tutte le risorse correlate:
Disabilitare l'eliminazione temporanea dei backup nell'insieme di credenziali:
az backup vault backup-properties set --name myVault --resource-group rg-oracle --soft-delete-feature-state disableArrestare la protezione per la macchina virtuale ed eliminare i backup:
az backup protection disable --resource-group rg-oracle --vault-name myVault --container-name vmoracle19c --item-name vmoracle19c --delete-backup-data true --yesRimuovere il gruppo di risorse, includendo tutte le risorse:
az group delete --name rg-oracle