Criteri di rete di Azure Kubernetes
I criteri di rete consentono la micro-segmentazione per i pod, così come i gruppi di sicurezza di rete supportano la micro-segmentazione per le macchine virtuali. L'implementazione di Gestione criteri di rete di Azure supporta la specifica standard per i criteri di rete di Kubernetes. È possibile usare le etichette per selezionare un gruppo di pod e definire un elenco di regole in ingresso e in uscita per filtrare il traffico da e verso questi pod. Altre informazioni sui criteri di rete di Kubernetes sono disponibili nella documentazione di Kubernetes.
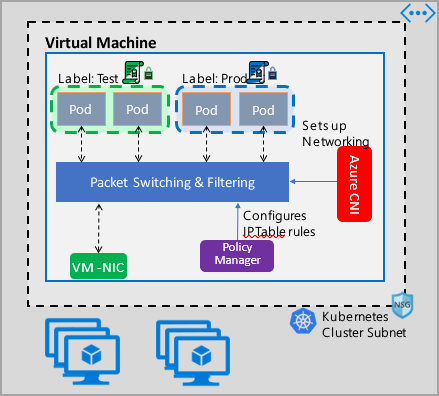
L'implementazione di Gestione criteri di rete di Azure è compatibile con Azure CNI, che fornisce l'integrazione della rete virtuale per i contenitori. Gestione criteri di rete è supportata in Linux e Windows Server. L'implementazione applica il filtro del traffico configurando regole di autorizzazione e negazione di IP in base ai criteri definiti in Linux IPTables o ACLPolicies del servizio di rete host (HNS) per Windows Server.
Pianificazione della sicurezza per il cluster Kubernetes
Quando si implementa la sicurezza per il cluster, usare gruppi di sicurezza di rete (NSG) per filtrare il traffico in ingresso e in uscita nella subnet del cluster (traffico nord-sud). Usare Gestione criteri di rete di Azure per il traffico tra pod nel cluster (traffico est-ovest).
Usare Gestione criteri di rete di Azure
Per implementare la micro-segmentazione per i pod, è possibile usare Gestione criteri di rete di Azure nei modi seguenti.
Servizio Azure Kubernetes (AKS)
Gestione criteri di rete è disponibile in modo nativo nel servizio Azure Kubernetes e può essere abilitata al momento della creazione del cluster.
Per altre informazioni, vedere Proteggere il traffico tra i pod usando criteri di rete nel servizio Azure Kubernetes.
Cluster Kubernetes eseguiti manualmente (DIY) in Azure
Per i cluster DIY, è prima di tutto necessario installare il plug-in CNI e abilitarlo in ogni macchina virtuale in un cluster. Per istruzioni dettagliate, vedere Distribuire il plug-in per un cluster Kubernetes.
Dopo aver distribuito il cluster, eseguire il comando kubectl seguente per scaricare e applicare il set di daemon di Gestione criteri di rete di Azure nel cluster.
Per Linux:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
Per Windows:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
La soluzione è anche open source e il codice è disponibile nel repository Azure Container Networking.
Monitorare e visualizzare le configurazioni di rete con Monitoraggio prestazioni rete di Azure
Gestione criteri di rete di Azure include metriche Prometheus informative che consentono di monitorare e comprendere meglio le configurazioni. Fornisce visualizzazioni predefinite sul portale di Azure o su Grafana Labs. È possibile iniziare a raccogliere queste metriche usando Monitoraggio di Azure o un server Prometheus.
Vantaggi delle metriche di Gestione criteri di rete di Azure
In precedenza, gli utenti potevano solo ottenere informazioni sulla configurazione di rete eseguendo i comandi iptables e ipset in un nodo del cluster, con conseguente produzione di un output dettagliato e difficile da comprendere.
Nel complesso, le metriche forniscono:
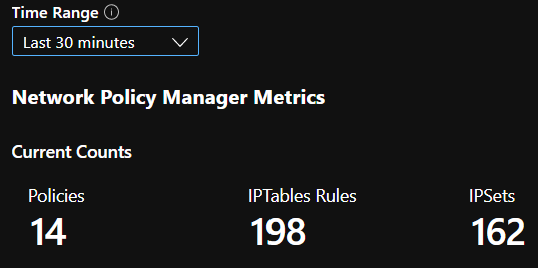
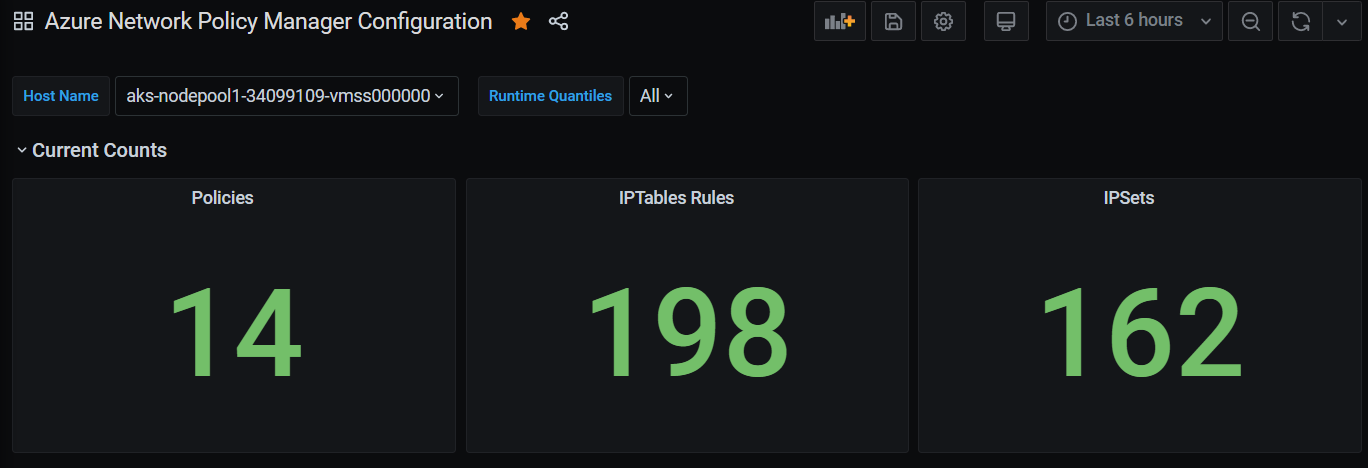
Numero di criteri, regole ACL, ipset, voci ipset e voci in qualsiasi ipset specificato
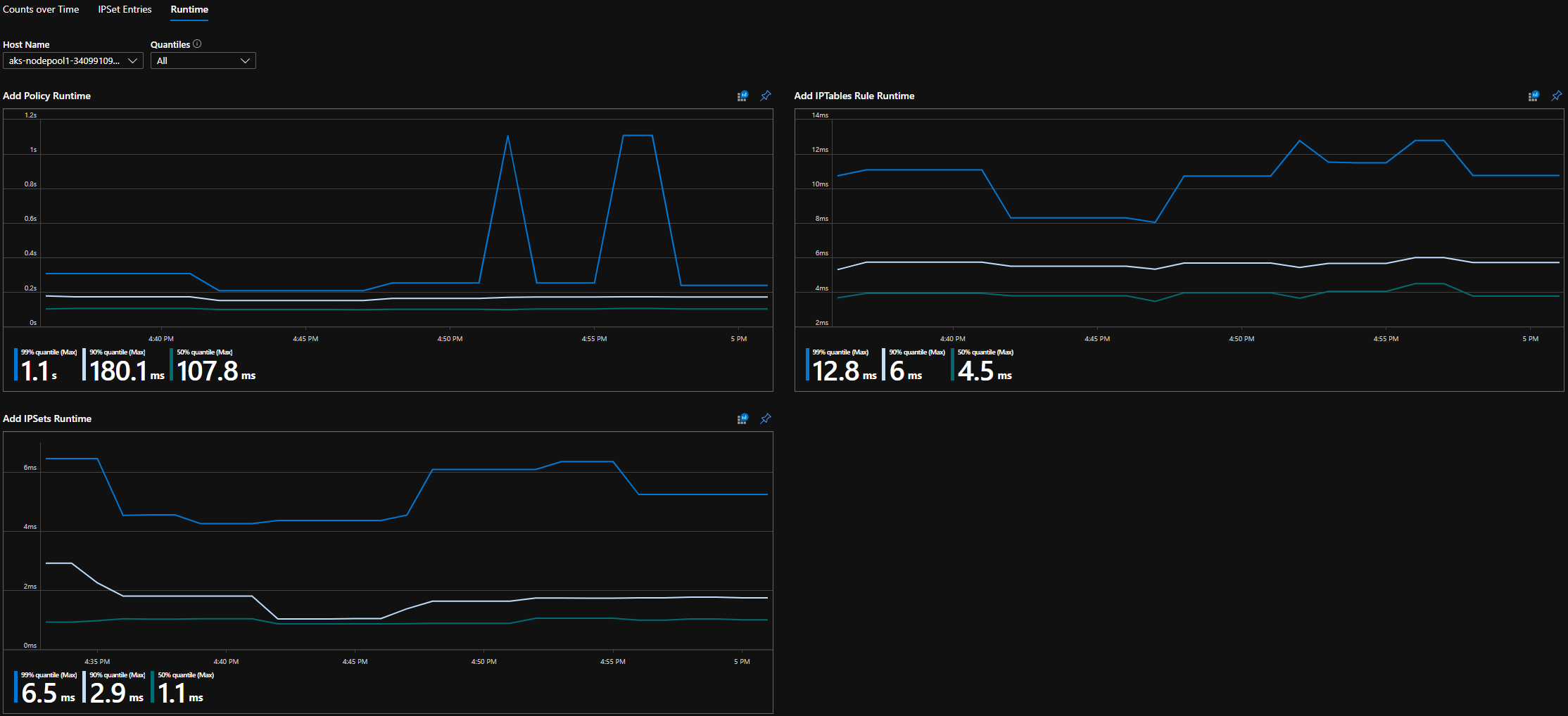
Tempi di esecuzione per le singole chiamate del sistema operativo e per la gestione degli eventi delle risorse Kubernetes (valore mediano, 90° percentile e 99° percentile)
Informazioni sugli errori per la gestione degli eventi delle risorse Kubernetes (questi eventi di risorse hanno esito negativo quando una chiamata del sistema operativo non viene eseguita correttamente)
Esempi di casi d'uso di metriche
Avvisi tramite Prometheus AlertManager
È possibile scegliere una configurazione di avvisi tra quelle elencate di seguito.
Avvisa quando Gestione criteri di rete riscontra un errore con una chiamata del sistema operativo o durante la conversione di un criterio di rete.
Avvisa quando il tempo di applicazione medio delle modifiche per un evento di creazione è superiore a 100 millisecondi.
Visualizzazioni e debug tramite il dashboard di Grafana o la cartella di lavoro di Monitoraggio di Azure
Verificare il numero di regole IPTables create dai criteri (un numero elevato di regole IPTables può aumentare leggermente la latenza).
Correlare il numero di cluster (ad esempio, ACL) ai tempi di esecuzione.
Ottenere il nome descrittivo di un ipset in una determinata regola IPTables (ad esempio,
azure-npm-487392rappresentapodlabel-role:database).
Tutte le metriche supportate
Di seguito viene fornito un elenco delle metriche supportate. Un'etichetta quantile può assumere i valori 0.5, 0.9e 0.99. Un'etichetta had_error può assumere i valori false e true, che indicano se l'operazione ha avuto esito positivo o negativo.
| Nome misurazione | Descrizione | Tipo di metriche di Prometheus | Etichette |
|---|---|---|---|
npm_num_policies |
numero di criteri di rete | Misuratore | - |
npm_num_iptables_rules |
numero di regole IPTables | Misuratore | - |
npm_num_ipsets |
numero di IPSets | Misuratore | - |
npm_num_ipset_entries |
numero di voci di indirizzi IP in tutti gli IPSets | Misuratore | - |
npm_add_iptables_rule_exec_time |
runtime per aggiungere una regola IPTables | Riepilogo | quantile |
npm_add_ipset_exec_time |
runtime per aggiungere un IPSet | Riepilogo | quantile |
npm_ipset_counts (avanzato) |
numero di voci in un singolo IPSet | GaugeVec |
set_name & set_hash |
npm_add_policy_exec_time |
runtime per aggiungere un criterio di rete | Riepilogo |
quantile & had_error |
npm_controller_policy_exec_time |
runtime per aggiornare/eliminare un criterio di rete | Riepilogo |
quantile e had_error e operation (con valori update o delete) |
npm_controller_namespace_exec_time |
runtime per creare/aggiornare/eliminare uno spazio dei nomi | Riepilogo |
quantile e had_error e operation (con valori create, update o delete) |
npm_controller_pod_exec_time |
runtime per creare/aggiornare/eliminare un pod | Riepilogo |
quantile e had_error e operation (con valori create, update o delete) |
Sono disponibili anche metriche "exec_time_count" e "exec_time_sum" per ogni metrica di riepilogo "exec_time".
Le metriche possono essere scorporate tramite Monitoraggio di Azure per contenitori o Prometheus.
Configurare Monitoraggio di Azure
Il primo passaggio consiste nell'abilitare Monitoraggio di Azure per contenitori nel cluster Kubernetes. La procedura è disponibile in Panoramica di Monitoraggio di Azure per contenitori. Dopo aver abilitato Monitoraggio di Azure per contenitori, configurare ConfigMap di Monitoraggio di Azure per contenitori per abilitare l'integrazione di Gestione criteri di rete e la raccolta delle relative metriche in Prometheus.
ConfigMap di Monitoraggio di Azure per contenitori include una sezione integrations con le impostazioni per raccogliere le metriche di Gestione criteri di rete.
Questa configurazione è disabilitata per impostazione predefinita in ConfigMap. Abilitare l'impostazione di base collect_basic_metrics = true per raccogliere le metriche di base di Gestione criteri di rete. Abilitare l'impostazione avanzata collect_advanced_metrics = true per raccogliere le metriche avanzate oltre a quelle di base.
Dopo aver modificato ConfigMap, salvarlo in locale e applicarlo al cluster come indicato di seguito.
kubectl apply -f container-azm-ms-agentconfig.yaml
Il frammento di codice seguente proviene da ConfigMap di Monitoraggio di Azure per contenitori e mostra l'integrazione di Gestione criteri di rete abilitata con la raccolta di metriche avanzate.
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
Le metriche avanzate sono facoltative e la loro abilitazione attiva automaticamente la raccolta di metriche di base. Attualmente, le metriche avanzate includono solo Network Policy Manager_ipset_counts.
Per altre informazioni sulle impostazioni di raccolta di Monitoraggio di Azure per contenitori, vedere il mapping di configurazione.
Opzioni di visualizzazione per Monitoraggio di Azure
Dopo aver abilitato la raccolta delle metriche di Gestione criteri di reti, è possibile visualizzare tali metriche nel portale di Azure, tramite le informazioni dettagliate sui contenitori, o in Grafana.
Visualizzazione nel portale di Azure nella sezione delle informazioni dettagliate del cluster
Aprire il portale di Azure. Dalla sezione delle informazioni dettagliate del cluster, passare a Cartelle di lavoro e aprire Configurazione di Gestione criteri di rete.
Oltre a visualizzare la cartella di lavoro, è anche possibile eseguire direttamente una query sulle metriche di Prometheus in "Log" nella sezione delle informazioni dettagliate. Ad esempio, questa query restituisce tutte le metriche raccolte.
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
È anche possibile eseguire una query sulle metriche direttamente in Log Analytics. Per altre informazioni, vedere Introduzione alle query di Log Analytics.
Visualizzazione nel dashboard di Grafana
Configurare il server Grafana e configurare un'origine dati di Log Analytics come descritto qui. Quindi, importare il dashboard di Grafana con un back-end di Log Analytics in Grafana Labs.
Il dashboard contiene oggetti visivi simili alla cartella di lavoro di Azure. È possibile aggiungere pannelli al grafico e visualizzare le metriche di Gestione criteri di rete dalla tabella InsightsMetrics.
Configurare il server Prometheus
Alcuni utenti possono scegliere di raccogliere metriche con un server Prometheus anziché con Monitoraggio di Azure per contenitori. Per raccogliere le metriche di Gestione criteri di rete, è sufficiente aggiungere due processi alla configurazione di scorporamento.
Per installare un server Prometheus, aggiungere questo repository Helm al cluster:
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
quindi aggiungere un server
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
dove prometheus-server-scrape-config.yaml è costituito da:
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
È anche possibile sostituire il processo azure-npm-node-metrics con il contenuto seguente o incorporarlo in un processo preesistente per i pod Kubernetes:
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Configurare gli avvisi per AlertManager
Se si usa un server Prometheus, è possibile configurare un AlertManager in questo modo. Ecco una configurazione di esempio per le due regole di avviso descritte in precedenza:
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
Opzioni di visualizzazione per Prometheus
Il server Prometheus supporta solo il dashboard di Grafana.
Se non è già stato fatto, configurare il server Grafana e un'origine dati di Prometheus. Quindi, importare il nostro dashboard di Grafana con un back-end di Prometheus in Grafana Labs.
Gli oggetti visivi per questo dashboard sono identici a quelli del dashboard con back-end di Informazioni dettagliate sui contenitori/Log Analytics.
Dashboard di esempio
Di seguito sono riportati alcuni dashboard di esempio per le metriche di Gestione criteri di rete in Informazioni dettagliate sui contenitori (CI) e Grafana.
Conteggi di riepilogo CI
Conteggi CI nel tempo

Voci IPSet CI

Quantili di runtime CI
Conteggi di riepilogo del dashboard di Grafana
Conteggi del dashboard di Grafana nel tempo

Voci IPSet del dashboard di Grafana

Quantili di runtime del dashboard di Grafana

Passaggi successivi
Informazioni sul servizio Azure Kubernetes.
Informazioni sulla rete dei contenitori.
Distribuire il plug-in per i cluster Kubernetes o i contenitori Docker.