Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Puoi usare la tiling per ottimizzare l'accelerazione della tua app. La suddivisione in tasselli divide i thread in sottoinsiemi rettangolari uguali, detti anche riquadri. Se si usano una dimensione del tassello e un algoritmo a tasselli appropriati, è possibile ottenere ancora più accelerazione dal codice AMP C++. I componenti di base della piastrellatura sono:
tile_staticvariabili. Il vantaggio principale della suddivisione è il miglioramento delle prestazioni grazie all'accessotile_static. L'accesso ai dati intile_staticmemoria può essere notevolmente più veloce rispetto all'accesso ai dati nello spazio globale (arrayoarray_viewoggetti ). Viene creata un'istanza di unatile_staticvariabile per ogni riquadro e tutti i thread nel riquadro hanno accesso alla variabile. In un tipico algoritmo a tile, i dati vengono copiati nellatile_staticmemoria una volta dalla memoria globale e poi accessibili molte volte dallatile_staticmemoria.Metodo tile_barrier::wait. Una chiamata a
tile_barrier::waitsospende l'esecuzione del thread corrente fino a quando tutti i thread nello stesso riquadro raggiungono la chiamata atile_barrier::wait. Non è possibile garantire l'ordine in cui verranno eseguiti i thread, ma solo che nessun thread nel riquadro eseguirà oltre la chiamata atile_barrier::waitfinché tutti i thread non hanno raggiunto la chiamata. Ciò significa che, usando il metodotile_barrier::wait, è possibile eseguire attività su base di riquadro anziché su base di thread. Un tipico algoritmo di tassellatura include codice per inizializzare latile_staticmemoria per l'intero tassello seguito da una chiamata atile_barrier::wait. Il codice seguentetile_barrier::waitcontiene calcoli che richiedono l'accesso a tutti itile_staticvalori.Indicizzazione locale e globale. Hai accesso all'indice del thread relativo all'intero oggetto
array_viewoarraye all'indice relativo al riquadro. L'uso dell'indice locale consente di semplificare la lettura e il debug del codice. In genere, si usa l'indicizzazione locale per accedere alletile_staticvariabili e l'indicizzazione globale per accedere allearrayearray_viewvariabili.classe tiled_extent e classe tiled_index. Si usa un
tiled_extentoggetto anziché unextentoggetto nellaparallel_for_eachchiamata. Si usa untiled_indexoggetto anziché unindexoggetto nellaparallel_for_eachchiamata.
Per sfruttare i vantaggi dell'associazione, l'algoritmo deve partizionare il dominio di calcolo in riquadri e quindi copiare i dati del riquadro in tile_static variabili per un accesso più rapido.
Esempio di indici globali, a piastrelle e locali
Annotazioni
Le intestazioni C++ AMP sono deprecate a partire da Visual Studio 2022 versione 17.0.
L'inclusione di eventuali intestazioni AMP genererà errori di compilazione. Definire _SILENCE_AMP_DEPRECATION_WARNINGS prima di includere eventuali intestazioni AMP per disattivare gli avvisi.
Il diagramma seguente rappresenta una matrice di dati 8x9 disposta in riquadri 2x3.
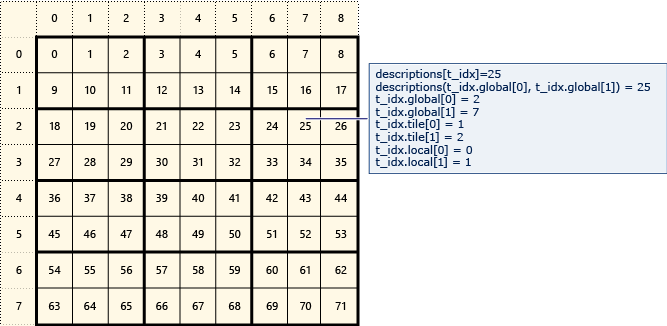
Nell'esempio seguente vengono visualizzati gli indici globali, affiancati e locali di questa matrice affiancata. Un array_view oggetto viene creato utilizzando elementi di tipo Description.
Description contiene gli indici globali, matriciali e locali dell'elemento nella matrice. Il codice nella chiamata a parallel_for_each imposta i valori degli indici globali, tile e locali di ogni elemento. L'output visualizza i valori delle strutture Description.
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
Il lavoro principale dell'esempio è nella definizione dell'oggetto array_view e nella chiamata a parallel_for_each.
Il vettore delle
Descriptionstrutture viene copiato in un oggetto 8x9array_view.Il
parallel_for_eachmetodo viene chiamato con untiled_extentoggetto come dominio di calcolo. L'oggettotiled_extentviene creato chiamando ilextent::tile()metodo delladescriptionsvariabile. I parametri di tipo della chiamata aextent::tile(),<2,3>, specificano che vengono creati riquadri 2x3. La matrice 8x9 viene quindi divisa in 12 tasselli, quattro righe e tre colonne.Il
parallel_for_eachmetodo viene chiamato utilizzando untiled_index<2,3>oggetto (t_idx) come indice. I parametri di tipo dell'indice (t_idx) devono corrispondere ai parametri di tipo del dominio di calcolo (descriptions.extent.tile< 2, 3>()).Quando ogni thread viene eseguito, l'indice
t_idxrestituisce informazioni sul riquadro in cui si trova il thread (tiled_index::tileproprietà) e sulla posizione del thread all'interno del riquadro (tiled_index::localproprietà ).
Sincronizzazione dei riquadri: tile_static e tile_barrier::wait
L'esempio precedente illustra il layout e gli indici dei riquadri, ma non è molto utile. La tassellatura diventa vantaggiosa quando le piastrelle sono parte integrale dell'algoritmo e sfruttano le variabili tile_static. Poiché tutti i thread in un riquadro hanno accesso alle tile_static variabili, le chiamate a tile_barrier::wait vengono usate per sincronizzare l'accesso alle tile_static variabili. Anche se tutti i thread in un riquadro hanno accesso alle tile_static variabili, non esiste un ordine di esecuzione garantito dei thread nel riquadro. Nell'esempio seguente viene illustrato come usare tile_static le variabili e il tile_barrier::wait metodo per calcolare il valore medio di ogni riquadro. Ecco le chiavi per comprendere l'esempio:
RawData viene archiviato in una matrice 8x8.
La dimensione del riquadro è 2x2. In questo modo viene creata una griglia 4x4 di riquadri e le medie possono essere archiviate in una matrice 4x4 usando un
arrayoggetto . Esistono solo un numero limitato di tipi che è possibile acquisire per riferimento in una funzione con restrizioni AMP. Laarrayclasse è una di esse.Le dimensioni della matrice e del campione vengono definite usando
#defineistruzioni, perché i parametri di tipo perarray,array_view,extentetiled_indexdevono essere valori costanti. È possibile usare anche le dichiarazioniconst int static. Come vantaggio aggiuntivo, è semplice modificare le dimensioni del campione per calcolare la media su 4x4 riquadri.Per ogni riquadro viene dichiarata una
tile_staticmatrice di valori float 2x2. Anche se la dichiarazione si trova nel percorso del codice per ogni thread, viene creata una sola matrice per ogni riquadro nella matrice.È presente una riga di codice per copiare i valori in ogni riquadro nella
tile_staticmatrice. Per ogni thread, dopo che il valore viene copiato nella matrice, l'esecuzione nel thread si arresta a causa della chiamata atile_barrier::wait.Quando tutti i thread in un riquadro hanno raggiunto la barriera, è possibile calcolare la media. Poiché il codice viene eseguito per ogni thread, è presente un'istruzione
ifper calcolare solo la media in un thread. La media viene archiviata nella variabile media. La barriera è essenzialmente il costrutto che controlla i calcoli per riquadro, molto simile all'uso di un ciclofor.I dati nella
averagesvariabile, perché si tratta di unarrayoggetto , devono essere copiati di nuovo nell'host. In questo esempio viene usato l'operatore di conversione vettoriale.Nell'esempio completo è possibile impostare SAMPLESIZE su 4 e il codice viene eseguito correttamente senza altre modifiche.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Problemi di concorrenza
Potrebbe essere possibile creare una tile_static variabile denominata total e incrementare tale variabile per ogni thread, come illustrato di seguito:
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
Il primo problema con questo approccio è che tile_static le variabili non possono avere inizializzatori. Il secondo problema è che esiste una race condition nell'assegnazione a total, perché tutti i thread nel tile hanno accesso alla variabile senza un ordine particolare. È possibile programmare un algoritmo per consentire a un solo thread di accedere al totale in ogni barriera, come illustrato di seguito. Tuttavia, questa soluzione non è estendibile.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Barriere di memoria
Esistono due tipi di accesso alla memoria che devono essere sincronizzati, ovvero l'accesso alla memoria globale e tile_static l'accesso alla memoria. Un concurrency::array oggetto alloca solo la memoria globale. Un concurrency::array_view oggetto può fare riferimento a memoria globale, tile_static memoria o entrambi, a seconda della modalità di costruzione. Esistono due tipi di memoria che devono essere sincronizzati:
memoria globale
tile_static
Un limite di memoria garantisce che gli accessi alla memoria siano disponibili per altri thread nel riquadro del thread e che gli accessi alla memoria vengano eseguiti in base all'ordine del programma. Per garantire ciò, i compilatori e i processori non riordinano le letture e le scritture attraverso la barriera. In C++ AMP, una recinzione di memoria viene creata da una chiamata a uno di questi metodi:
Metodo tile_barrier::wait: crea un recinto intorno alla memoria globale e
tile_static.Metodo tile_barrier::wait_with_all_memory_fence: crea una barriera attorno sia alla memoria globale che
tile_static.Metodo tile_barrier::wait_with_global_memory_fence: crea una barriera esclusivamente attorno alla memoria globale.
Metodo tile_barrier::wait_with_tile_static_memory_fence: crea un recinto solo intorno alla
tile_staticmemoria.
La chiamata al limite specifico necessario può migliorare le prestazioni dell'app. Il tipo di barriera influisce sul modo in cui il compilatore e l'hardware riordinano le istruzioni. Ad esempio, se si usa un limite di memoria globale, si applica solo agli accessi alla memoria globale e pertanto il compilatore e l'hardware potrebbero riordinare le letture e scrivere in tile_static variabili sui due lati del recinto.
Nell'esempio seguente, la barriera sincronizza le scritture su tileValues, tile_static una variabile. In questo esempio viene tile_barrier::wait_with_tile_static_memory_fence chiamato anziché tile_barrier::wait.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
Vedere anche
C++ AMP (parallelismo massivo accelerato C++)
Parola chiave tile_static