Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Spostarsi a destra è la procedura di spostamento di alcuni test in un secondo momento nel processo DevOps per il test nell'ambiente di produzione. I test nell'ambiente di produzione usano distribuzioni reali per convalidare e misurare il comportamento e le prestazioni di un'applicazione nell'ambiente di produzione.
Un modo in cui i team DevOps possono migliorare la velocità consiste nell'usare una strategia di test di turno a sinistra . Maiusc a sinistra esegue il push della maggior parte dei test in precedenza nella pipeline DevOps, per ridurre la quantità di tempo per il raggiungimento della produzione e il funzionamento affidabile del nuovo codice.
Sebbene molti tipi di test, ad esempio gli unit test, possano spostarsi facilmente a sinistra, alcune classi di test non possono essere eseguite senza distribuire parte o tutte le soluzioni. La distribuzione in un servizio di controllo di qualità o staging può simulare un ambiente paragonabile, ma non esiste un sostituto completo per l'ambiente di produzione. I team rilevano che alcuni tipi di test devono essere eseguiti nell'ambiente di produzione.
Il test nell'ambiente di produzione offre:
- L'intera ampiezza e la diversità dell'ambiente di produzione.
- Carico di lavoro reale del traffico dei clienti.
- Profili e comportamenti man mano che la domanda di produzione si evolve nel tempo.
L'ambiente di produzione continua a cambiare. Anche se un'app non cambia, l'infrastruttura su cui si basa costantemente le modifiche. I test nell'ambiente di produzione convalidano l'integrità e la qualità di una distribuzione di produzione specifica e dell'ambiente di produzione in continua evoluzione.
Il passaggio da destra a test nell'ambiente di produzione è particolarmente importante per gli scenari seguenti:
Distribuzioni di microservizi
Le soluzioni basate su microservizi possono avere un numero elevato di microservizi sviluppati, distribuiti e gestiti in modo indipendente. Lo spostamento dei test a destra è particolarmente importante per questi progetti, perché versioni e configurazioni diverse possono raggiungere l'ambiente di produzione in molti modi. Indipendentemente dalla copertura dei test di pre-produzione, è necessario testare la compatibilità nell'ambiente di produzione.
Garantire la qualità della post-distribuzione
Il rilascio alla produzione è solo la metà della distribuzione di software. L'altra metà garantisce la qualità su larga scala con un carico di lavoro reale nell'ambiente di produzione. Poiché l'ambiente continua a cambiare, un team non viene mai eseguito con i test nell'ambiente di produzione.
I dati di test dall'ambiente di produzione sono letteralmente i risultati del test del carico di lavoro reale del cliente. I test nell'ambiente di produzione includono monitoraggio, test di failover e inserimento di errori. Questo test tiene traccia di errori, eccezioni, metriche delle prestazioni ed eventi di sicurezza. I dati di telemetria dei test consentono anche di rilevare anomalie.
Livelli di distribuzione
Per proteggere l'ambiente di produzione, i team possono implementare le modifiche in modo progressivo e controllato usando distribuzioni basate su livelli e flag di funzionalità. Ad esempio, è preferibile rilevare un bug che impedisce a un acquirente di completare l'acquisto quando meno di 1% di clienti si trovano su tale livello di distribuzione, rispetto al passaggio di tutti i clienti contemporaneamente. Il valore della funzionalità con errori rilevati deve superare le perdite nette di tali errori, misurate in modo significativo per l'azienda specificata.
Il primo livello deve essere la dimensione minima necessaria per eseguire la suite di integrazione standard. I test potrebbero essere simili a quelli già eseguiti in precedenza nella pipeline in altri ambienti, ma i test convalidano che il comportamento sia lo stesso nell'ambiente di produzione. Questo livello identifica gli errori evidenti, ad esempio errori di configurazione, prima che influiscano su qualsiasi cliente.
Dopo la convalida del livello iniziale, il livello successivo può essere ampliato per includere un subset di utenti reali per l'esecuzione del test. Se tutto sembra corretto, la distribuzione può progredisce attraverso altri livelli e test fino a quando tutti non lo usano. La distribuzione completa non significa che il test sia finito. Il rilevamento dei dati di telemetria è fondamentale per i test nell'ambiente di produzione.
Inserimento di errori
I team spesso usano l'inserimento degli errori e la progettazione del caos per verificare il comportamento di un sistema in condizioni di errore. Queste procedure consentono di:
- Verificare che i meccanismi di resilienza implementati funzionino effettivamente.
- Verificare che un errore in un sottosistema sia contenuto all'interno di tale sottosistema e non si a catena per produrre un'interruzione principale.
- Dimostrare che il lavoro di riparazione per un evento imprevisto precedente ha l'effetto desiderato, senza dover attendere che si verifichi un altro evento imprevisto.
- Creare esercitazioni di training più realistiche per i tecnici del sito live in modo che possano prepararsi meglio a gestire gli eventi imprevisti.
È consigliabile automatizzare gli esperimenti di inserimento degli errori, perché sono test costosi che devono essere eseguiti su sistemi in continua evoluzione.
La progettazione di Chaos può essere uno strumento efficace, ma deve essere limitata agli ambienti canary che hanno un impatto minimo o negativo sul cliente.
Test di failover
Una forma di inserimento degli errori è il test di failover per supportare la continuità aziendale e il ripristino di emergenza (BCDR). Teams deve avere piani di failover per tutti i servizi e i sottosistemi. I piani devono includere:
- Spiegazione chiara dell'impatto aziendale del servizio inattivo.
- Mappa di tutte le dipendenze in termini di piattaforma, tecnologia e persone che progettano i piani BCDR.
- Documentazione formale delle procedure di ripristino di emergenza.
- Cadenza per eseguire regolarmente esercitazioni sul ripristino di emergenza.
Test di errore dell'interruttore
Un meccanismo di interruttore taglia un determinato componente da un sistema più grande, in genere per evitare errori in tale componente di distribuirsi al di fuori dei limiti. È possibile attivare intenzionalmente interruttori di circuito per testare gli scenari seguenti:
Indica se un fallback funziona all'apertura dell'interruttore. Il fallback potrebbe funzionare con unit test, ma l'unico modo per sapere se si comporta come previsto nell'ambiente di produzione consiste nell'inserire un errore per attivarlo.
Indica se l'interruttore ha la soglia di riservatezza corretta da aprire quando è necessario. L'inserimento di errori può forzare la latenza o disconnettere le dipendenze per osservare la velocità di risposta del breaker. È importante verificare non solo che si verifichi il comportamento corretto, ma che si verifichi abbastanza rapidamente.
Esempio: Test di un interruttore di circuito della cache Redis
La cache Redis migliora le prestazioni del prodotto velocizzando l'accesso ai dati di uso comune. Si consideri uno scenario che accetta una dipendenza non critica da Redis. Se Redis diventa inattivo, il sistema deve continuare a funzionare, perché può eseguire il fallback all'uso dell'origine dati originale per le richieste. Per verificare che un errore redis attivi un interruttore e che il fallback funzioni nell'ambiente di produzione, eseguire periodicamente test su questi comportamenti.
Il diagramma seguente mostra i test per il comportamento di fallback dell'interruttore redis. L'obiettivo è assicurarsi che quando si apre il breaker, le chiamate alla fine passano a SQL.
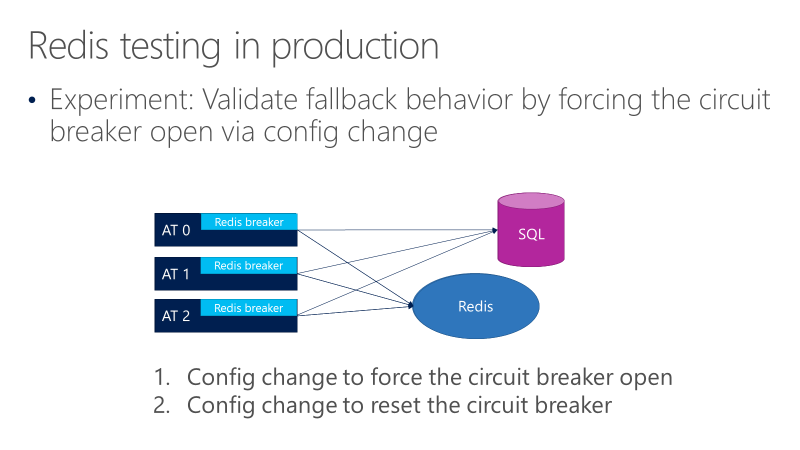
Il diagramma precedente mostra tre ATS, con i breaker davanti alle chiamate a Redis. Un test forza l'apertura dell'interruttore tramite una modifica della configurazione e quindi osserva se le chiamate passano a SQL. Un altro test controlla quindi la modifica di configurazione opposta chiudendo l'interruttore per confermare che le chiamate tornano a Redis.
Questo test verifica che il comportamento di fallback funzioni all'apertura del breaker, ma non convalida che la configurazione dell'interruttore apra l'interruttore quando necessario. Il test di questo comportamento richiede la simulazione di errori effettivi.
Un agente di errore può introdurre errori nelle chiamate che passano a Redis. Il diagramma seguente illustra i test con l'inserimento di errori.
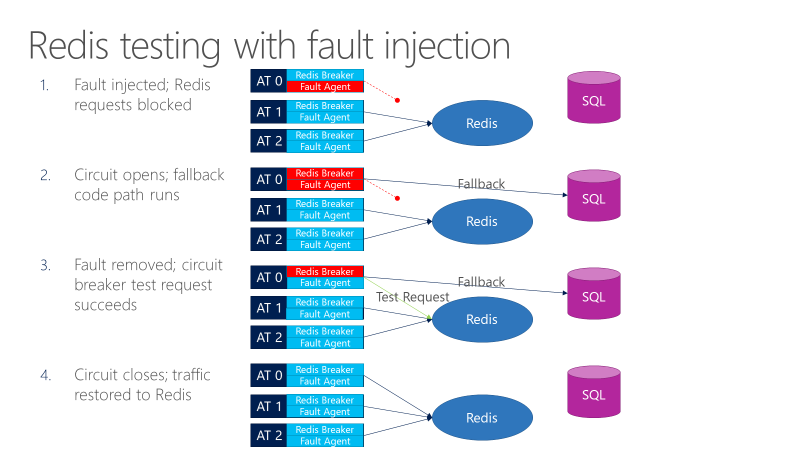
- L'iniettore di errore blocca le richieste Redis.
- Si apre l'interruttore e il test può osservare se il fallback funziona.
- L'errore viene rimosso e l'interruttore invia una richiesta di test a Redis.
- Se la richiesta ha esito positivo, richiama reverti a Redis.
Altri passaggi potrebbero testare la sensibilità del breaker, se la soglia è troppo elevata o troppo bassa e se altri timeout di sistema interferiscono con il comportamento dell'interruttore.
In questo esempio, se il breaker non si apre o si chiude come previsto, potrebbe causare un evento imprevisto del sito live (LSI). Senza il test di inserimento degli errori, il problema potrebbe non essere rilevato, perché è difficile eseguire questo tipo di test in un ambiente lab.