Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Git rappresenta la cronologia in modo fondamentalmente diverso rispetto ai sistemi di controllo delle versioni centralizzati (CVCS), ad esempio Team Foundation Version Control, Perforce o Subversion. I sistemi centralizzati archiviano una cronologia separata per ogni file in un repository. Git archivia la cronologia come grafico degli snapshot dell'intero repository. Questi snapshot, denominati commit in Git, possono avere più elementi padre, creando una cronologia simile a un grafico anziché una linea retta. Questa differenza nella storia è incredibilmente importante ed è il motivo principale per cui gli utenti che hanno familiarità con CVCS trovano git confuso.
Nozioni di base sulla cronologia dei commit
Iniziare con un esempio di cronologia semplice: un repository con tre commit lineari.
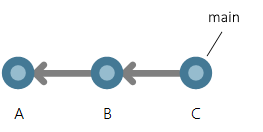
Il commit A è l'elemento padre del commit B e il commit B è l'elemento padre del commit C. Questa storia è molto simile a un CVCS. La freccia che punta al commit C è un ramo. I rami sono puntatori a commit specifici, motivo per cui la diramazione è così semplice e leggera in Git.
Una differenza fondamentale in Git rispetto a CVCS è che lo sviluppatore ha la propria copia completa del repository. È necessario mantenere sincronizzato il repository locale con il repository remoto ottenendo i commit più recenti dal repository remoto. A tale scopo, eseguono il pull del ramo principale con il comando seguente:
git pull origin main
Questa operazione unisce tutte le modifiche dal ramo principale nel repository remoto, che Git denomina origin per impostazione predefinita. Questa operazione di pull ha portato un nuovo commit e il main branch nel repository locale è stato aggiornato su quel commit.
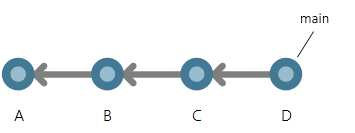
Comprendere la cronologia dei rami
È ora possibile apportare una modifica al codice. È comune avere più rami attivi quando si usano funzionalità diverse in parallelo. Questo è in contrasto con CVCS in cui i nuovi rami sono pesanti e raramente creati. Il primo passaggio consiste nel eseguire il checkout in un nuovo ramo usando il comando seguente:
git checkout -b cool-new-feature
Si tratta di un collegamento che combina due comandi:
-
git branch cool-new-featureper creare il ramo -
git checkout cool-new-featureper iniziare a lavorare nel ramo
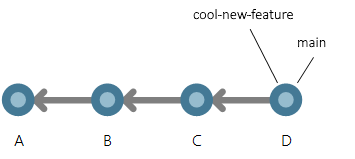
Due rami puntano ora allo stesso commit. Si supponga che ci siano alcune modifiche nel ramo cool-new-feature in due nuovi commit, E e F.
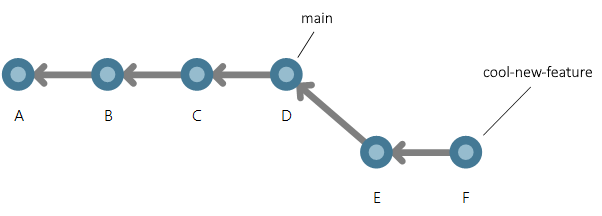
I commit sono raggiungibili dal cool-new-feature ramo poiché sono stati eseguiti su tale ramo.
Dopo aver completato la funzionalità, è necessario eseguirne il merge nel ramo principale. A tale scopo, usare il comando seguente:
git merge cool-new-feature main
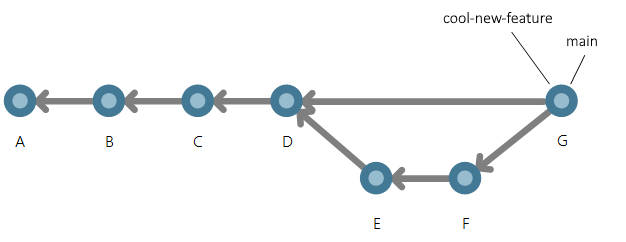
La struttura del grafo della cronologia diventa visibile quando è presente un'unione. Git crea un nuovo commit quando il ramo viene unito in un altro ramo. Si tratta di un commit di merge. Non sono state incluse modifiche al commit di merge perché non sono presenti conflitti. In caso di conflitti, il commit di merge include le modifiche necessarie per risolverle.
Storia nel mondo reale
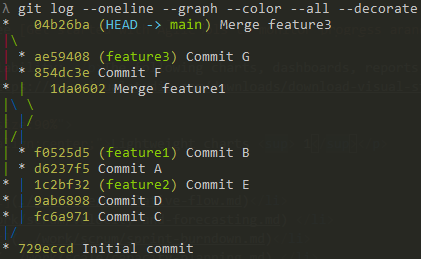
Di seguito è riportato un esempio di cronologia git che assomiglia più strettamente al codice nello sviluppo attivo in un team.
Ci sono tre persone che uniscono i commit dai propri rami al ramo main pressoché contemporaneamente.
Passaggi successivi
Altre informazioni sull'uso della cronologia Git in GitHub e azure Repos o sulla semplificazione della cronologia dei log Git.